Optimiser le système source - avancé
Cette aide plus avancée peut être utile pour l’exportation source des systèmes VLDB :
Fractionnement de table d’ID de ligne Oracle
SAP a publié la Note SAP no 1043380, qui contient un script permettant de convertir la clause WHERE d’un fichier WHR en une valeur ROW ID. En guise d’alternative, les dernières versions de SAPInst génèrent automatiquement des fichiers WHR de fractionnement des ID de ligne, si SWPM est configuré pour la migration d’Oracle vers Oracle R3load. Les fichiers STR et WHR générés par SWPM sont indépendants du système d’exploitation et de la base de données (tout comme tous les aspects du processus de migration du système d’exploitation/base de données).
La note OSS contient l’instruction « le fractionnement de table ROWID ne peut pas être utilisé si la base de données cible est une base de données non-Oracle ». Techniquement, les fichiers d’image mémoire de R3load sont indépendants de la base de données et du système d’exploitation. Toutefois, il y a une restriction : vous ne pouvez pas redémarrer un package pendant l’importation sur SQL Server. Dans ce scénario, la table entière doit être supprimée et tous les packages de la table redémarrés. Il est toujours recommandé d’arrêter les tâches R3Load pour une table de fractionnement spécifique, de TRONQUER la table et de redémarrer l’ensemble du processus d’importation si une R3load de fractionnement est abandonnée. Cela est dû au fait que le processus de récupération intégré à R3load implique d’effectuer des instructions de suppression ligne par ligne uniques pour supprimer les enregistrements chargés par le processus R3load qui s’interrompt. Cette opération est lente et entraîne souvent des situations de blocage/verrouillage sur la base de données. L’expérience a montré qu’il est plus rapide de commencer l’importation de cette table à partir du début. Par conséquent, la limitation mentionnée dans la Note SAP no 1043380 n’en est pas une.
L’ID ROW présente l’inconvénient suivant : le calcul des fractionnements doit être effectué pendant les temps d’arrêt (cf. Note SAP no 1043380).
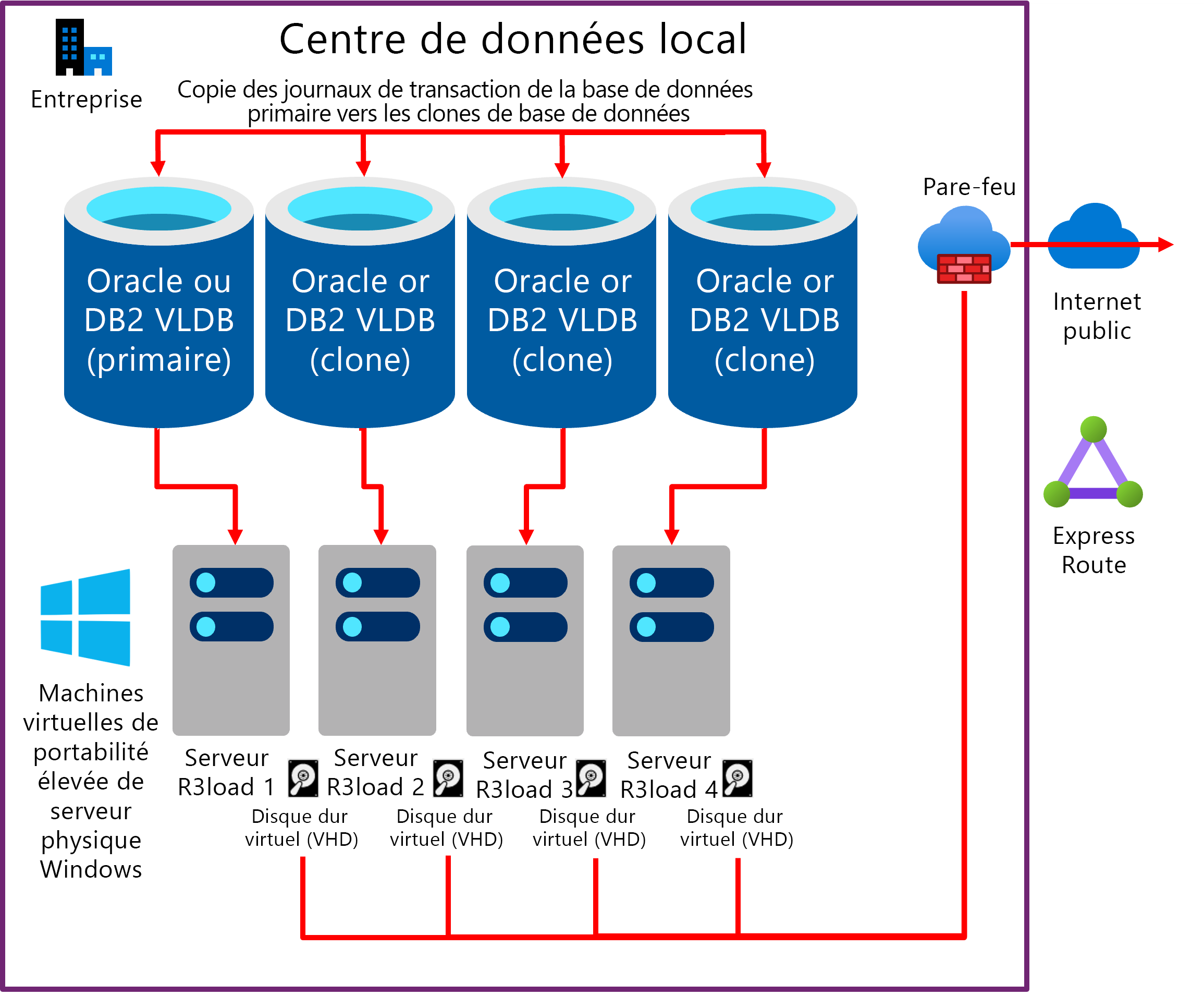
Créer plusieurs « clones » de la base de données source et exporter en parallèle
L’une des méthodes permettant d’augmenter le niveau de performance d’exportation consiste à exporter à partir de plusieurs copies de la même base de données. Si l’infrastructure sous-jacente, y compris les serveurs, le réseau et le stockage, est évolutive, cette approche a tendance à être évolutive de façon linéaire. L’exportation à partir de deux copies de la même base de données est deux fois plus rapide, avec quatre copies, quatre fois plus rapide. Le moniteur de migration est configuré pour l’exportation sur un nombre sélectionné de tables à partir de chaque « clone » de la base de données. Dans le cas suivant, la charge de travail d’exportation est distribuée à environ 25 % sur chacun des 4 serveurs de base de données.
- Serveur de base de données 1 et serveur d’exportation 1 : dédié aux plus grandes tables 1 à 4 (en fonction de l’asymétrie de la distribution des données sur la base de données source)
- Serveur de base de données 2 et serveur d’exportation 2 : dédié aux tables avec fractionnements de table
- Serveur de base de données 3 et serveur d’exportation 3 : dédié aux tables avec fractionnements de table
- Serveur de base de données 4 et serveur d’exportation 4 : toutes les tables restantes
Vous devez vérifier que les bases de données sont synchronisées avec précision, sinon une perte de données ou des incohérences de données peuvent se produire. Si les étapes fournies sont suivies précisément, l’intégrité des données est préservée.
Cette technique est simple et peu coûteuse avec le matériel Intel standard, mais elle est également accessible pour les clients qui exécutent le matériel UNIX propriétaire. Des ressources matérielles substantielles sont gratuites vers le milieu d’un projet de migration de système d’exploitation/base de passe lorsque les systèmes Bac à sable, de développement, de assurance qualité, de formation et de récupération d’urgence ont déjà été déplacés vers Azure. Il n’est pas obligatoire que les serveurs de « clone » aient des ressources matérielles identiques. Avec le niveau de performance de processeur, de RAM, de disque et de réseau adéquates, l’ajout de chaque clone augmente le niveau de performance.
Si une meilleure performance de l’exportation reste une nécessité, ouvrez un incident SAP dans BC-DB-MSS pour obtenir des étapes supplémentaires afin d’accélérer les performances de l’exportation (consultants avancés uniquement).
Les étapes à suivre pour implémenter une exportation parallèle multiple sont les suivantes :
- Sauvegardez la base de données primaire et restaurez sur « n » nombre de serveurs (où n = nombre de clones). Pour cet exemple, supposons que n = 3 serveurs, pour un total de quatre serveurs de base de données.
- Restaurez la sauvegarde sur 3 serveurs.
- Établissez la copie des journaux de transaction du serveur de base de données source principal sur 3 serveurs « clones » cibles.
- Analysez la copie des journaux de transaction depuis plusieurs jours et assurez-vous que la copie des journaux de transaction fonctionne de façon fiable.
- Au début du temps d’arrêt, arrêtez tous les serveurs d’application SAP, sauf le PAS. Assurez-vous que tous les traitements par lots sont arrêtés et que tout le trafic RFC est arrêté.
- Dans la transaction SM02, entrez le texte « point de contrôle PAS en cours d’exécution ». Cette table met à jour la table TEMSG.
- Arrêtez le serveur d’applications principal. SAP est maintenant arrêté. Aucune autre activité d’écriture ne peut se produire dans la base de données source. Assurez-vous qu’aucune application non-SAP n’est connectée à la base de données source (il n’y en a jamais, mais recherchez les sessions non SAP au niveau de la base de données).
- Exécutez cette requête sur le serveur de base de connaissances principal :
SELECT EMTEXT FROM [schema].TEMSG; - Exécutez l’instruction Native SGBD Level :
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(la syntaxe exacte dépend du SGBD source. INSERT into EMTEXT) - Arrêtez les sauvegardes automatiques du journal des transactions. Exécutez manuellement une sauvegarde finale de la sauvegarde de fichier journal sur le serveur de base de données principal. Assurez-vous que la sauvegarde de fichier journal est copiée sur les serveurs clones.
- Restaurez la sauvegarde finale de fichier journal sur les 3 nœuds.
- Récupérez la base de données sur les 3 nœuds « clones ».
- Exécutez l’instruction SELECT suivante sur les quatre nœuds :
SELECT EMTEXT FROM [schema].TEMSG; - Capturez les résultats à l’écran de l’instruction SELECT de chacun des 4 serveurs de base de données (principal et les 3 clones). Veillez à ajouter soigneusement chaque nom d’hôte. C’est la preuve que la base de données clone et la base de données primaire sont identiques, et qu’elles contiennent les mêmes données du même point dans le temps.
- Démarrez export_monitor.bat sur chacun des serveurs d’exportation Intel R3load.
- Démarrez la copie du fichier de copie de sauvegarde dans le processus Azure (AzCopy ou Robocopy).
- Démarrez import_monitor.bat sur les machines virtuelles Azure R3load.
Le diagramme suivant illustre une copie des journaux de transaction du serveur de base de données de production existant vers des bases de données « clones ». Chaque serveur de base de données possède un ou plusieurs serveurs Intel R3load.