Combiner et optimiser des données
Les organisations compilent souvent différents types d’informations provenant de nombreuses sources. Les informations sont stockées dans un grand nombre de tables. Parfois, vous pouvez avoir besoin de joindre les tables en fonction de leurs relations logiques, pour faire une analyse approfondie ou créer des rapports. Dans le scénario d’entreprise de distribution, vous utilisez des tables pour les informations des clients, des produits et des ventes.
Dans ce module, vous découvrez différentes façons de combiner des données dans des requêtes Kusto pour fournir aux membres de votre équipe les informations dont ils ont besoin pour accroître la notoriété des produits et augmenter les ventes.
Comprendre vos données
Avant de commencer à écrire des requêtes qui combinent des informations de vos tables, vous devez comprendre vos données. Quand vous travaillez avec des requêtes Kusto, vous allez considérer que les tables appartiennent à une des deux catégories suivantes :
- Tables de faits : tables dont les enregistrements sont des faits immuables, comme la table SalesFact dans le scénario d’entreprise de vente au détail. Dans ces tables, les enregistrements sont progressivement ajoutés en streaming ou sous forme de gros segments. Les enregistrements restent dans la table jusqu’à ce qu’ils soient supprimés et ils ne sont jamais mis à jour.
- Tables de dimension : tables dont les enregistrements sont des dimensions mutables, comme les tables Customers et Products dans le scénario d’entreprise de vente au détail. Ces tables contiennent des données de référence, comme des tables de choix entre un identificateur d’entité et ses propriétés. Les tables de dimension ne reçoivent pas régulièrement de mises à jour avec de nouvelles données.
Dans notre scénario d’entreprise de distribution, vous utilisez des tables de dimension pour enrichir la table SalesFact avec des informations supplémentaires ou pour fournir davantage d’options de filtrage des données pour les requêtes.
Vous devez également comprendre les volumes de données que vous utilisez et leur structure, appelée « schéma » (les noms et les types des colonnes). Vous pouvez exécuter les requêtes suivantes pour obtenir ces informations en remplaçant TABLE_NAME par le nom de la table que vous examinez :
Pour obtenir le nombre d’enregistrements dans une table, utilisez l’opérateur
count:TABLE_NAME | countPour obtenir le schéma d’une table, utilisez l’opérateur
getschema:TABLE_NAME | getschema
L’exécution de ces requêtes sur les tables de faits et de dimension dans le scénario d’entreprise de distribution vous donne des informations comme dans l’exemple suivant :
| Table | Enregistrements | schéma |
|---|---|---|
| SalesFact | 2 832 193 | - SalesAmount (real) - TotalCost (real) - DateKey (datetime) - ProductKey (long) - CustomerKey (long) |
| Clients | 18 484 | - CityName (string) - CompanyName (string) - ContinentName (string) - CustomerKey (long) - Education (string) - FirstName (string) - Gender (string) - LastName (string) - MaritalStatus (string) - Occupation (string) - RegionCountryName (string) - StateProvinceName (string) |
| Produits | 2 517 | - ProductName (string) - Manufacturer (string) - ColorName (string) - ClassName (string) - ProductCategoryName (string) - ProductSubcategoryName (string) - ProductKey (long) |
Dans la table, nous avons mis en évidence les identificateurs uniques CustomerKey et ProductKey qui sont utilisés pour combiner les enregistrements entre les tables.
Comprendre les requêtes multitables
Après avoir analysé vos données, vous devez comprendre comment combiner des tables pour fournir les informations dont vous avez besoin. Les requêtes Kusto fournissent plusieurs opérateurs pour combiner des données de plusieurs tables, notamment les opérateurs lookup, join et union.
L’opérateur join fusionne les lignes de deux tables en mettant en correspondance les valeurs des colonnes spécifiées de chaque table. La table résultante dépend du type de jointure que vous utilisez. Par exemple, si vous utilisez une jointure interne, la table a les mêmes colonnes que la table de gauche (parfois appelée table externe), plus les colonnes de la table de droite (parfois appelée table interne). Vous en apprendrez plus sur les types de jointures dans la section suivante. Pour de meilleures performances, si une table est toujours plus petite que l’autre, utilisez-la à gauche de l’opérateur join.
L’opérateur lookup est une implémentation spéciale de l’opérateur join qui optimise les performances des requêtes où une table de faits est enrichie avec les données d’une table de dimensions. Cela étend la table de faits avec des valeurs recherchées dans une table de dimension. Pour de meilleures performances, le système suppose par défaut que la table de gauche est la plus grande (fait) et que la table de droite est la plus petite (dimension). Cette supposition est exactement à l’opposé de celle utilisée par l’opérateur join.
L’opérateur union retourne toutes les lignes d’au moins deux tables. Il est utile pour combiner des données de plusieurs tables.
La fonction materialize() met en cache les résultats dans une exécution de requête pour pouvoir les réutiliser plus tard dans la requête. C’est comme si vous preniez un instantané des résultats d’une sous-requête et que vous l’utilisiez plusieurs fois dans la requête. Cette fonction est utile pour optimiser les requêtes dans des scénarios où les résultats :
- Sont chers à calculer
- Sont non déterministes
Vous en apprendrez bientôt davantage sur les différents opérateurs de fusion de tables et sur la fonction materialize(), et comment les utiliser.
Types de jointure
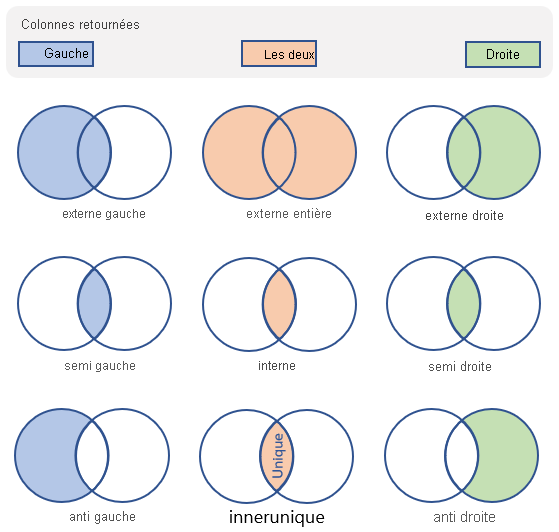
De nombreux types de jointure affectent le schéma et les lignes de la table résultante. Le tableau suivant indique les types de jointure pris en charge par le langage de requête Kusto, et le schéma et les lignes qu’ils retournent :
| Type de jointure | Description | Illustration |
|---|---|---|
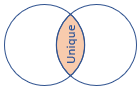
innerunique (valeur par défaut) |
Jointure interne avec déduplication du côté gauche Schéma : toutes les colonnes des deux tables, y compris les clés correspondantes Lignes : toutes les lignes dédupliquées de la table de gauche qui correspondent aux lignes de la table de droite |
|
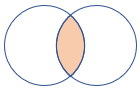
inner |
Jointure interne standard Schéma : toutes les colonnes des deux tables, y compris les clés correspondantes Lignes : seules les lignes correspondantes des deux tables |
|
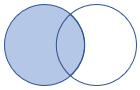
leftouter |
Jointure externe gauche Schéma : toutes les colonnes des deux tables, y compris les clés correspondantes Lignes : tous les enregistrements de la table de gauche et uniquement les lignes correspondantes de la table de droite |
|
rightouter |
Jointure externe droite Schéma : toutes les colonnes des deux tables, y compris les clés correspondantes Lignes : tous les enregistrements de la table de droite et uniquement les lignes correspondantes de la table de gauche |
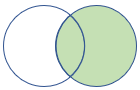
|
fullouter |
Jointure externe entière Schéma : toutes les colonnes des deux tables, y compris les clés correspondantes Lignes : tous les enregistrements des deux tables avec des cellules sans correspondance remplies avec null |

|
leftsemi |
Semi-jointure gauche Schéma : toutes les colonnes de la table de gauche Lignes : tous les enregistrements de la table de gauche qui correspondent aux enregistrements de la table de droite |
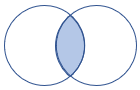
|
leftanti, anti, leftantisemi |
Jointure anti gauche et semi-variante Schéma : toutes les colonnes de la table de gauche Lignes : tous les enregistrements de la table de gauche qui ne correspondent pas aux enregistrements de la table de droite |

|
rightsemi |
Semi-jointure droite Schéma : toutes les colonnes de la table de droite Lignes : tous les enregistrements de la table de droite qui correspondent aux enregistrements de la table de gauche |

|
rightanti, rightantisemi |
Jointure anti droite et semi-variante Schéma : toutes les colonnes de la table de droite Lignes : tous les enregistrements de la table de droite qui ne correspondent pas aux enregistrements de la table de gauche |
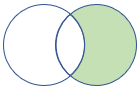
|
Notez que le type de jointure par défaut est innerunique et n’a pas besoin d’être spécifié. Néanmoins, une bonne pratique est de toujours spécifier explicitement le type de jointure pour plus de clarté.
Au fil de ce module, vous découvrez également les fonctions d’agrégation arg_min() et arg_max(), l’opérateur as comme alternative à l’instruction let, et la fonction startofmonth() pour faciliter le regroupement des données par mois.