Configurer la haute disponibilité et la reprise d’activité après sinistre
Une partie importante de la configuration des solutions de reprise d’activité après sinistre et de haute disponibilité dans SQL Server reste la même dans SQL Server s’exécutant sur une machine virtuelle Azure. La solution de haute disponibilité est conçue pour garantir qu’aucune donnée validée n’est perdue à la suite de défaillances, que votre charge de travail n’est pas affectée par les opérations de maintenance et que la base de données ne devient pas un point de défaillance unique dans votre architecture logicielle.
La plupart des niveaux de service Azure SQL offrent toute une plage d’options de haute disponibilité, des modèles de redondance locale aux modèles de redondance de zone.
Nous allons explorer ensuite les solutions spécifiques de reprise d’activité après sinistre et de haute disponibilité pour les offres PaaS d’Azure.
Sauvegarde continue
Azure SQL Database garantit des sauvegardes continues et régulières des bases de données, qui sont ensuite répliquées sur un stockage géoredondant avec accès en lecture (RA-GRS).
Les sauvegardes complètes hebdomadaires, les sauvegardes différentielles toutes les 12 à 24 heures et les sauvegardes des journaux des transactions toutes les 5 à 10 minutes font partie de la stratégie de sauvegarde automatisée. Pour une disponibilité étendue des sauvegardes (jusqu’à 10 ans), la conservation à long terme (LTR) peut être configurée pour les bases de données uniques et les bases de données mises en pool.
Conservation à long terme (LTR)
Azure propose une stratégie de conservation que vous pouvez définir au-delà des limites habituelles, ce qui est utile pour les scénarios nécessitant une conservation à long terme. Vous pouvez définir une stratégie de conservation jusqu’à 10 ans, et cette option est désactivée par défaut.

L’image montre comment configurer des stratégies de conservation à long terme dans le portail Azure. Une fois que vous avez choisi la base de données, un panneau apparaît sur le côté droit de l’écran, où vous pouvez changer les paramètres par défaut.
Pour plus d’informations sur la conservation à long terme, consultez Conservation à long terme - Azure SQL Database et Azure SQL Managed Instance.
La géorestauration
Les sauvegardes de SQL Database et de SQL Managed Instance sont géoredondantes par défaut. Cela vous permet de restaurer facilement les bases de données dans une autre région géographique, fonctionnalité utile pour les scénarios de reprise d’activité après sinistre moins stricts.
Le stockage de sauvegarde est facturé à part du stockage normal des fichiers de base de données. Cependant, lors du provisionnement d’une base de données SQL Database, le stockage de sauvegarde est créé avec la taille maximale de la couche Données sélectionnée pour votre base de données sans coût supplémentaire.
La durée d’une opération de géorestauration peut être affectée par plusieurs composants sous-jacents, y compris la taille de la base de données, le nombre de journaux de transactions impliqués dans une opération de restauration et la quantité de demandes de restauration simultanées en cours de traitement dans la région cible.
Restauration à un point dans le temps
Vous pouvez restaurer vos bases de données à un instant dans le passé en fonction de la conservation définie. Toutefois, la restauration à un instant dans le passé est une fonctionnalité prise en charge uniquement si vous restaurez une base de données sur le serveur d’origine de la sauvegarde. Vous pouvez utiliser le portail Azure, Azure PowerShell, Azure CLI ou l’API REST pour restaurer une base de données SQL Database.
Géo-réplication active
Une méthode pour augmenter la disponibilité d’Azure SQL Database consiste à utiliser la géoréplication active. La géoréplication active crée un réplica de la base de données dans une autre région, celui-ci est maintenu à jour de façon asynchrone.
Ce réplica est accessible en lecture, semblable à un groupe de disponibilité AlwaysOn dans SQL Server. Sous la surface, Azure utilise des groupes de disponibilité pour gérer cette fonctionnalité. C’est la raison pour laquelle certaines terminologies sont similaires.
La géoréplication active offre une continuité d’activité en permettant aux clients de basculer par programmation ou manuellement des bases de données primaires vers des régions secondaires lors d’un sinistre majeur.
Remarque
Azure SQL Managed Instance ne prend pas en charge la géoréplication active. À la place, vous devez utiliser des groupes de basculement automatique, une rubrique que nous allons explorer plus tard dans cette unité.
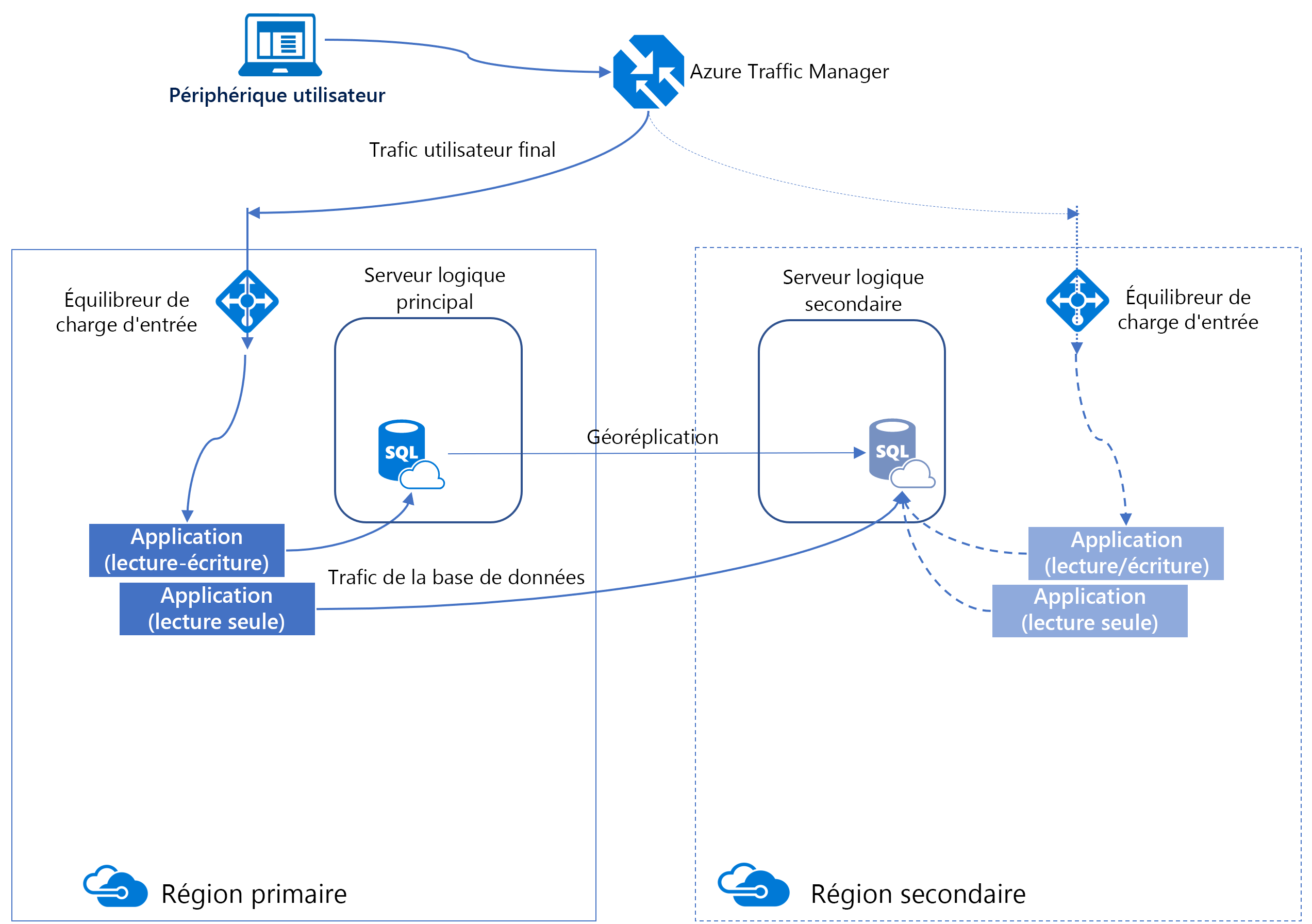
Toutes les bases de données impliquées dans une relation de géoréplication doivent avoir le même niveau de service. De plus, pour éviter les problèmes de performances de réplication dus à une charge de travail d’écriture importante, nous vous recommandons de configurer le réplica secondaire avec la même taille de calcul que le réplica principal.

Vous pouvez configurer manuellement la géoréplication pour Azure SQL Database en accédant au panneau de la base de données, dans la section Gestion des données, en sélectionnant Réplicas, puis + Créer un réplica.

Une fois le réplica secondaire établi, vous pouvez lancer manuellement un basculement. Au cours de ce processus, les rôles sont inversés : le réplica secondaire joue le rôle du réplica principal, tandis que le réplica principal d’origine devient le réplica secondaire.
Géoréplication entre abonnements
Dans certains scénarios, vous devrez peut-être configurer un réplica secondaire sur un autre abonnement que celui de la base de données primaire. C’est ici qu’entre en jeu la fonctionnalité de géoréplication entre abonnements.
Remarque
La géoréplication entre abonnements est disponible uniquement par programmation.
Pour en savoir plus sur les étapes nécessaires à la configuration d’une géoréplication entre abonnements, consultez Géoréplication entre abonnements.
Groupes de basculement automatique
Un groupe de basculement automatique est une fonctionnalité de haute disponibilité prise en charge par Azure SQL Database et Azure SQL Managed Instance. Les groupes de basculement automatique vous permettent de gérer la façon dont les bases de données sont répliquées sur une autre région ainsi que la façon dont le basculement peut se produire. Le nom affecté au groupe de basculement automatique doit être unique dans le domaine *.database.windows.net.
Un groupe de basculement automatique peut inclure plusieurs bases de données. Le réplica principal et le réplica secondaire ont la même taille de base de données.
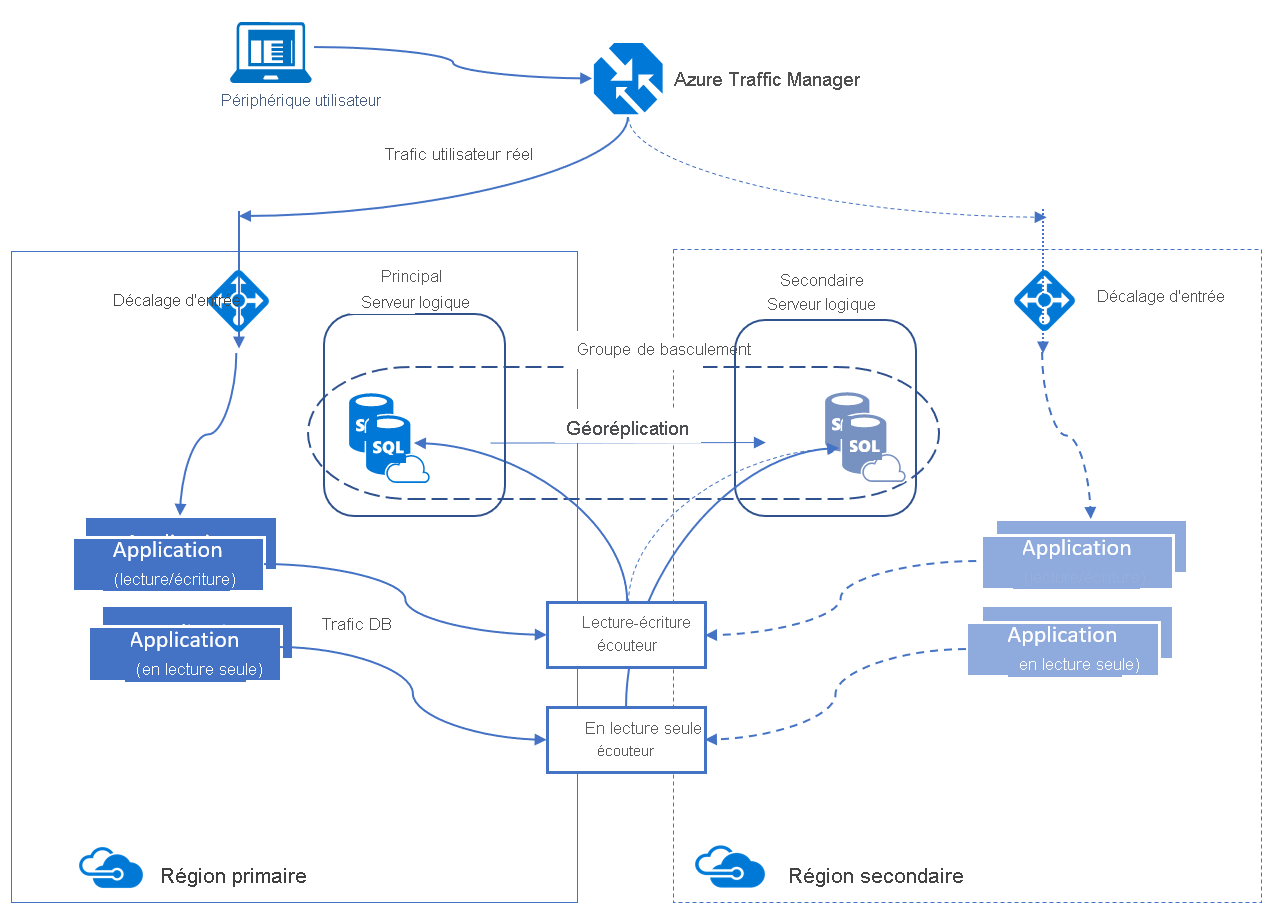
Les groupes de basculement automatique fournissent une fonctionnalité de type AG, appelée écouteur, qui permet à la fois les activités en lecture-écriture et en lecture seule. Il existe deux types d’écouteurs distincts : un pour le trafic en lecture/écriture et l’autre pour le trafic en lecture seule. Dans les coulisses d’un basculement, le DNS est mis à jour pour que les clients puissent pointer vers le nom d’écouteur abstrait sans avoir à en savoir plus. Le serveur de base de données contenant les copies en lecture-écriture est le serveur principal, et le serveur qui reçoit les transactions de ce principal est un serveur secondaire.
Il existe deux stratégies différentes pour les groupes de basculement automatique.
| Type de stratégie | Description |
|---|---|
| Automatique | Quand une défaillance est détectée, le système déclenche automatiquement un basculement par défaut. Toutefois, si nécessaire, vous pouvez désactiver le basculement automatique. |
| Lecture seule | Durant un basculement, le moteur désactive l’écouteur en lecture seule par défaut pour maintenir les performances du nouveau réplica principal quand le réplica secondaire est en panne. Toutefois, vous pouvez changer ce comportement pour autoriser les deux types de trafics après un basculement. |
Le basculement est un processus qui peut être lancé manuellement, même quand le basculement automatique est activé. Toutefois, selon le type de basculement choisi, il peut exister un risque de perte de données. Par exemple, un basculement non planifié peut entraîner une perte de données s’il est forcé, et s’il existe une synchronisation entre la base de données secondaire et la base de données principale.
GracePeriodWithDataLossHours détermine le délai d’attente d’Azure avant le lancement d’un basculement, la valeur par défaut étant d’une heure. Si votre objectif RPO (objectif de point de récupération) est strict, et si la perte de données n’est pas une option, vous pouvez augmenter cette valeur. Bien que cela signifie qu’Azure doit attendre plus longtemps avant de lancer un basculement, cela peut réduire les pertes de données, car la base de données secondaire dispose de plus de temps pour se synchroniser complètement avec la base de données principale.
Remarque
La base de données secondaire est créée automatiquement via un processus appelé amorçage, qui peut prendre du temps en fonction de la taille de la base de données. Il est donc important de planifier à l’avance, en prenant en compte de facteurs tels que la vitesse du réseau.
Pour en savoir plus sur la haute disponibilité et la reprise d’activité après sinistre d’Azure SQL Database, consultez la check-list de la haute disponibilité et de la reprise d’activité après sinistre d’Azure SQL Database.