Explorer l’architecture de la solution
Examinons l’architecture que vous avez choisi pour le workflow d’opérations Machine Learning (MLOps) afin de comprendre où et quand nous devons vérifier le code.
Notes
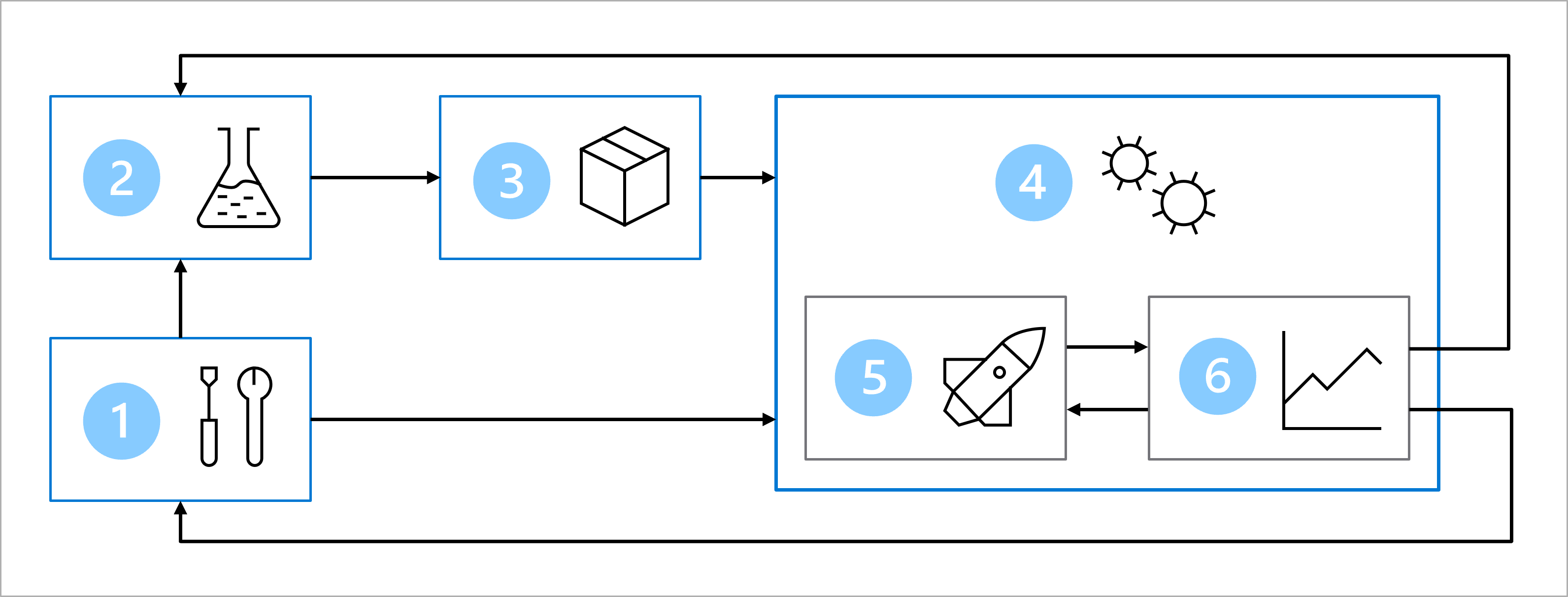
Le diagramme est une représentation simplifiée d’une architecture MLOps. Pour obtenir une architecture plus détaillée, explorez les différents cas d’usage dans l’accélérateur de solution MLOps (v2).
L’objectif principal de l’architecture MLOps est de créer une solution robuste et reproductible. Pour ce faire, l’architecture inclut les éléments suivants :
- Installation : créer toutes les ressources Azure nécessaires pour la solution.
- Développement de modèle (boucle interne) : explorer et traiter les données pour entraîner et évaluer le modèle.
- Intégration continue : empaqueter et inscrire le modèle.
- Déploiement de modèle (boucle externe) : déployer le modèle.
- Déploiement continu : tester le modèle et le promouvoir dans un environnement de production.
- Monitoring : superviser les performances du modèle et du point de terminaison.
Pour déplacer un modèle du développement au déploiement, vous aurez besoin d’une intégration continue. Pendant l’intégration continue, vous empaquetterez et inscrirez le modèle. Avant d’empaqueter un modèle, vous devez toutefois vérifier le code utilisé pour entraîner le modèle.
Avec l’équipe de science des données, vous avez convenu d’utiliser le développement basé sur le tronc. Non seulement les branches protégeront le code de production, mais cela vous permettra également de vérifier automatiquement les modifications proposées avant de les fusionner avec le code de production.
Examinons le workflow pour un scientifique des données :
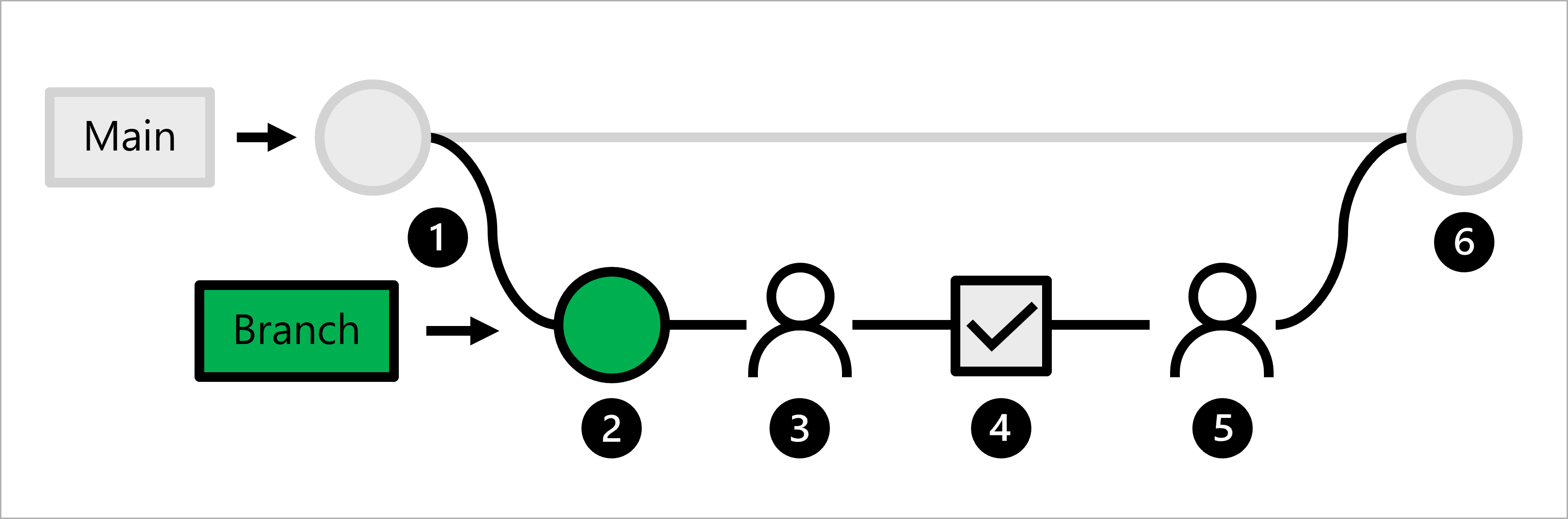
- Le code de production est hébergé dans la branche main.
- Un scientifique des données crée une branche de fonctionnalité pour le développement de modèle.
- Le scientifique des données crée une demande de tirage pour proposer des modifications à la branche principale.
- Lorsqu’une demande de tirage est créée, un workflow GitHub Actions est déclenché pour vérifier le code.
- Lorsque le code satisfait au linting et aux tests unitaires, le scientifique des données en chef doit approuver les modifications proposées.
- Une fois les modifications approuvées, la demande de tirage est fusionnée et la branche principale est mise à jour en conséquence.
En tant qu’ingénieur Machine Learning, vous devez créer un workflow GitHub Actions qui vérifie le code en exécutant un linter et des tests unitaires chaque fois qu’une demande de tirage est créée.
Conseil
Apprenez-en davantage sur l’utilisation du contrôle de code source pour les projets Machine Learning, notamment le développement basé sur le tronc et la vérification locale de votre code.