Résolution des problèmes de file d’attente d’envoi de journaux dans un groupe de disponibilité Always On
Cet article fournit des solutions aux problèmes liés à la file d’attente d’envoi de journaux.
Qu’est-ce que l’envoi de journaux en file d’attente ?
Les modifications apportées à une base de données de groupe de disponibilité sur le réplica principal (par INSERTexemple, et UPDATEDELETE) sont écrites dans le journal des transactions et envoyées aux réplicas secondaires du groupe de disponibilité. La file d’attente d’envoi du journal définit le nombre d’enregistrements de journal dans les fichiers journaux de la base de données primaire qui n’ont pas été envoyés aux réplicas secondaires.
Symptômes et effet de la file d’attente d’envoi du journal
La file d’attente d’envoi du journal stocke toutes les données vulnérables
Si le réplica principal est perdu en cas de sinistre soudain et que vous basculez vers le réplica secondaire où ces modifications ne sont pas encore arrivées, ces modifications n’apparaissent pas dans la nouvelle copie du réplica principal de la base de données. Cela exclut les modifications stockées lorsque des sauvegardes complètes de base de données et de journaux sont exécutées.
La croissance de la file d’attente d’envoi du journal des journaux provoque une croissance croissante du fichier journal des transactions
Pour une base de données définie dans un groupe de disponibilité, Microsoft SQL Server doit conserver au niveau du réplica principal toutes les transactions du journal des transactions qui n’ont pas encore été remises aux réplicas secondaires. La file d’attente d’envoi du journal représente la quantité de modifications journalisées sur le réplica principal qui ne peuvent pas être tronquées pendant les événements de troncation de journal normal (par exemple, lors d’une sauvegarde du journal de base de données). Une file d’attente d’envoi de journaux volumineuse et croissante peut épuiser l’espace libre sur le lecteur qui héberge le fichier journal de base de données ou peut dépasser la taille maximale configurée du fichier journal des transactions. Pour plus d’informations, consultez l’erreur 9002 lorsque le journal des transactions est volumineux.
Différentes fonctionnalités de diagnostic signalent le journal d’envoi du journal des groupes de disponibilité
Le tableau de bord Always On dans les rapports SQL Server Management Studio sur la file d’attente d’envoi de journaux. Il peut signaler que le groupe de disponibilité n’est pas sain.
Comment rechercher la file d’attente d’envoi de journaux
La file d’attente d’envoi du journal est une mesure par base de données. Vous pouvez vérifier cette valeur à l’aide du tableau de bord Always On sur le réplica principal ou à l’aide de l’sys.dm_hadr_database_replica_states vues de gestion dynamique (DMV) sur le réplica principal ou secondaire. Analyseur de performances compteurs sont utilisés pour rechercher la file d’attente d’envoi du journal sur le réplica secondaire.
Les sections suivantes fournissent des méthodes pour surveiller activement la file d’attente d’envoi du journal de votre groupe de disponibilité.
Interroger sys.dm_hadr_database_replica_state
Le sys.dm_hadr_database_replica_states DMV signale une ligne pour chaque base de données de groupe de disponibilité. Une colonne de ce rapport est log_send_queue_size. Cette valeur est la taille de file d’attente d’envoi du journal en kilo-octets (Ko). Vous pouvez configurer une requête telle que la requête suivante pour surveiller n’importe quelle tendance dans la taille de file d’attente d’envoi du journal. La requête est exécutée sur le réplica principal. Il utilise le is_local=0 prédicat pour signaler les données du réplica secondaire, où log_send_queue_size et log_send_rate sont pertinentes.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Voici à quoi ressemble la sortie.

Passez en revue la file d’attente d’envoi du journal dans le tableau de bord Always On
Pour passer en revue la file d’attente d’envoi du journal, procédez comme suit :
Ouvrez le tableau de bord Always On dans SQL Server Management Studio (SSMS) en cliquant avec le bouton droit sur un groupe de disponibilité dans l’Explorateur d’objets SSMS.
Sélectionnez Afficher le tableau de bord.
Les bases de données du groupe de disponibilité sont répertoriées en dernier, et certaines données sont signalées sur les bases de données. Bien que la taille de file d’attente d’envoi du journal (Ko) et le taux d’envoi du journal (Ko/s) ne soient pas répertoriés par défaut, vous pouvez les ajouter à cette vue, comme illustré dans la capture d’écran de l’étape suivante.
Pour ajouter ces colonnes, cliquez avec le bouton droit sur l’en-tête de colonne de base de données du groupe de disponibilité, puis sélectionnez-la dans la liste des colonnes disponibles.
Pour ajouter la taille de file d’attente d’envoi du journal, cliquez avec le bouton droit sur l’en-tête affiché en rouge dans la capture d’écran suivante.

Par défaut, le tableau de bord Always On actualise automatiquement ces données toutes les 60 secondes.



Passez en revue la file d’attente d’envoi du journal dans Analyseur de performances
La file d’attente d’envoi du journal est spécifique à chaque base de données de réplica secondaire. Par conséquent, pour passer en revue la file d’attente d’envoi du journal d’une base de données de groupe de disponibilité, procédez comme suit :
Ouvrez Analyseur de performances sur le réplica secondaire.
Sélectionnez le bouton Ajouter (compteur).
Sous Compteurs disponibles, sélectionnez le réplica SQLServer :Database et les compteurs de file d’attente d’envoi de journaux.
Dans la zone de liste Instance , sélectionnez la base de données du groupe de disponibilité que vous souhaitez rechercher la file d’attente d’envoi du journal.
Sélectionnez Ajouter et OK.
Voici ce qui augmente la file d’attente d’envoi de journaux.
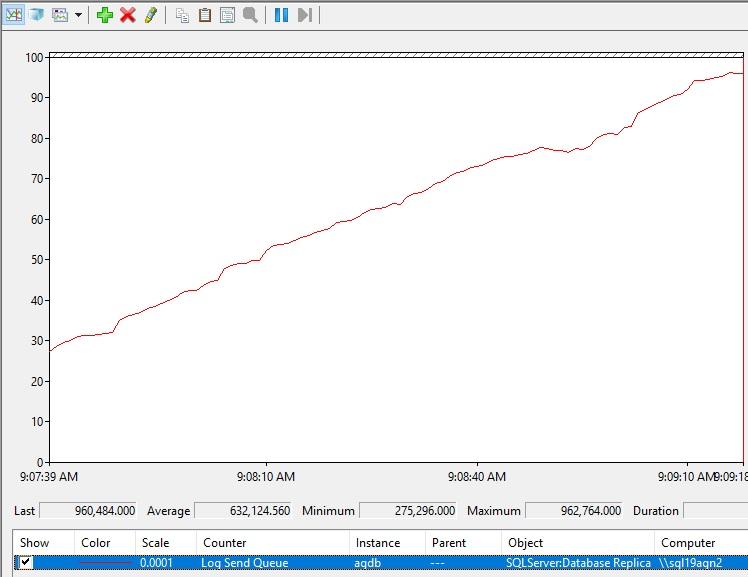

Interprétation des valeurs de mise en file d’attente d’envoi du journal
Cette section explique comment interpréter les valeurs de la taille de file d’attente d’envoi du journal.
Quand l’envoi du journal est-il incorrect ? Quelle quantité de mise en file d’attente d’envoi du journal doit-elle être tolérée ?
Vous pouvez supposer que si la file d’attente d’envoi du journal signale une valeur de 0, cela signifie qu’aucune mise en file d’attente d’envoi de journal ne se produit au moment de ce rapport. Toutefois, lorsque votre environnement de production est occupé, vous devez vous attendre à observer la file d’attente d’envoi du journal signalant fréquemment une valeur autre que zéro même dans un environnement AlwaysOn sain. Pendant la production classique, vous devez vous attendre à observer cette valeur varie entre 0 et une valeur non nulle.
Si vous observez l’augmentation de la file d’attente d’envoi de journaux au fil du temps, une investigation supplémentaire est justifiée. Cette activité supplémentaire indique que quelque chose a changé. Si vous observez une croissance soudaine dans la file d’attente d’envoi du journal, les mesures suivantes sont utiles pour résoudre les problèmes :
- Taux d’envoi du journal (Ko/s) (tableau de bord AlwaysOn)
- sys.dm_hadr_database_replica_states (DMV)
- Réplica de base de données ::Transactions mises en miroir/s (Analyseur de performances)
Obtenir les taux de référence pour le taux d’envoi des journaux et les transactions mises en miroir/s
Pendant des performances AlwaysOn saines, surveillez le taux d’envoi du journal et les valeurs de transactions mises en miroir/s pour vos bases de données de groupe de disponibilité occupées. Qu’est-ce qu’ils ressemblent pendant les heures de bureau généralement occupées ? À quoi ressemblent-ils pendant les périodes de maintenance, quand les transactions volumineuses entraînent un débit de transaction plus élevé sur le système ? Vous pouvez comparer ces valeurs lorsque vous observez la croissance de la file d’attente d’envoi de journaux pour déterminer ce qui a changé. La charge de travail peut être supérieure à la normale. Si le taux d’envoi du journal est inférieur à l’habitude, une enquête supplémentaire peut être nécessaire pour déterminer pourquoi.
Volume de charge de travail important
Lorsque vous avez des charges de travail volumineuses (par exemple, une UPDATE instruction sur 1 million de lignes, une reconstruction d’index sur une table de 1 téraoctets ou même un lot ETL qui insère des millions de lignes), vous devez vous attendre à voir une croissance de file d’attente d’envoi de journaux, immédiatement ou au fil du temps. Cela est attendu lorsqu’un grand nombre de modifications sont apportées soudainement dans la base de données du groupe de disponibilité.
Guide pratique pour diagnostiquer la file d’attente d’envoi de journaux
Une fois que vous avez identifié la file d’attente d’envoi du journal pour une base de données de groupe de disponibilité spécifique, vous devez rechercher plusieurs causes racines possibles du problème, comme indiqué dans les sections suivantes.
Important
Pour obtenir une sortie significative du type d’attente, recherchez une augmentation de la file d’attente d’envoi du journal à l’aide de l’une des méthodes décrites dans les sections précédentes lorsque vous surveillez les conditions suivantes.
Le système est trop occupé
Vérifiez si la charge de travail sur le réplica principal surcharge les processeurs du système. Si vous voyez une augmentation de la file d’attente d’envoi du journal, interrogez la sys.dm_os_schedulers vue DMV et surveillez high runnable_tasks_count. Ce nombre indique les tâches en attente qui ont été exécutées à ce moment-là.
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
Le tableau suivant contient des exemples de résultats. Une augmentation de la runnable_tasks_count valeur indique qu’un grand nombre de tâches attendent le temps processeur.
| scheduler_address | scheduler_id | cpu_id | statut | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | VISIBLE HORS CONNEXION | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | VISIBLE EN LIGNE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | VISIBLE EN LIGNE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | VISIBLE EN LIGNE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | VISIBLE EN LIGNE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | VISIBLE EN LIGNE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | VISIBLE EN LIGNE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | VISIBLE | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | VISIBLE EN LIGNE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | VISIBLE EN LIGNE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | VISIBLE EN LIGNE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | VISIBLE EN LIGNE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | VISIBLE EN LIGNE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | VISIBLE EN LIGNE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | VISIBLE EN LIGNE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | VISIBLE EN LIGNE | 104 | 16 | 116 | 103 |
Solution : si vous détectez une charge de travail élevée runnable_task_count, réduisez la charge de travail sur le système ou augmentez le nombre de processeurs disponibles pour le système.
Latence du réseau
Cette condition est particulièrement courante si le réplica secondaire est physiquement distant du réplica principal. Les groupes de disponibilité multis sites permettent aux clients de déployer des copies de données métiers sur plusieurs sites pour la récupération d’urgence et la création de rapports. Cela rend les modifications quasi-en temps réel disponibles pour les copies des données de production à des emplacements distants.
Si un réplica secondaire est hébergé loin du réplica principal, la file d’attente d’envoi des journaux peut être causée par la latence du réseau et une incapacité à envoyer des modifications à la base de données secondaire distante aussi rapidement qu’elles sont produites dans la base de données du réplica principal.
Important
SQL Server utilise une connexion unique pour synchroniser les modifications du réplica principal vers les réplicas secondaires. Par conséquent, si un réplica secondaire est distant, la largeur du canal n’affecte pas la quantité de données que SQL Server peut envoyer. Au lieu de cela, cette quantité dépend davantage de la latence du réseau dans le canal (vitesse de connexion).
Tester la latence du réseau
Vérifier si les paramètres de contrôle de flux contribuent à la latence du réseau
Les groupes de disponibilité Microsoft SQL Server utilisent des portes de contrôle de flux pour éviter une consommation excessive des ressources réseau, de la mémoire et d’autres ressources sur tous les réplicas de disponibilité. Ces portes de contrôle de flux n’affectent pas l’état d’intégrité de synchronisation des réplicas de disponibilité. Toutefois, ils peuvent affecter les performances globales de vos bases de données de disponibilité, y compris le RPO.
Les versions ultérieures de SQL Server modifient les seuils auxquels le contrôle de flux est entré. Cela peut aider à soulager l’effet que le contrôle de flux a sur les symptômes tels que la file d’attente d’envoi de journaux. Pour plus d’informations sur le contrôle de flux et l’historique des modifications apportées aux seuils de contrôle de flux, consultez portes de contrôle de flux.
Vous pouvez surveiller le contrôle de flux à l’aide de Analyseur de performances pour capturer des données sur le réplica principal. Pour surveiller le contrôle de flux de base de données, ajoutez des compteurs de réplica SQLServer :Database, puis sélectionnez le délai de contrôle de flux de base de données et les compteurs de flux de base de données/s . Dans la boîte de dialogue Instance , sélectionnez la base de données du groupe de disponibilité que vous souhaitez vérifier pour le contrôle de flux de base de données. Pour détecter et surveiller le contrôle de flux de réplica de disponibilité, ajoutez des compteurs de réplica SQLServer :Availability, puis sélectionnez les compteurs temps de contrôle de flux (ms/s) et Contrôle de flux/s .
Vérifier si le redémarrage de Congestion Windows contribue à la latence du réseau
Les problèmes de performances réseau qui provoquent le déclenchement d’une file d’attente d’envoi de journaux peuvent être déclenchés en utilisant le paramètre TCP de redémarrage de Congestion Windows défini sur True. Il s’agissait du paramètre par défaut dans Windows Server 2016. Assurez-vous que le redémarrage de la fenêtre congestion a la valeur False sur les serveurs Windows sur lesquels les réplicas de groupe de disponibilité hébergent les files d’attente d’envoi du journal sont observés.
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart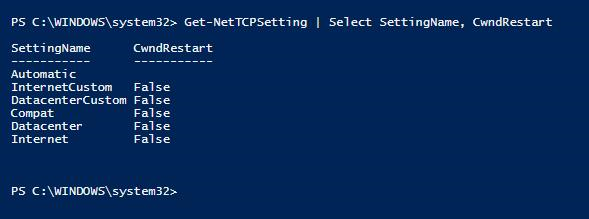
Pour plus d’informations sur la définition de la propriété TCP Congestion Windows Restart sur False, consultez Set-NetTCPSetting (NetTCPIP) .
Consultez également Surveiller les performances des groupes de disponibilité Always On pour plus d’informations sur le processus de synchronisation. Cet article vous montre également comment calculer certaines des métriques clés et fournit des liens vers certains des scénarios courants de résolution des problèmes de performances.
Utiliser ping pour obtenir un exemple de latence
Sur une ligne de commande sur node1 (réplica principal), ping node2 (réplica secondaire) :
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101msTester le débit réseau du serveur principal au secondaire à l’aide d’un outil indépendant
Utilisez un outil tel que NTttcp pour détecter indépendamment le débit réseau entre les réplicas principaux et secondaires à l’aide d’une seule connexion. La latence du réseau est une cause courante de la file d’attente d’envoi des journaux. Les étapes suivantes montrent comment utiliser un outil indépendant tel que NTttcp pour mesurer le débit réseau.
Important
SQL Server envoie les modifications du réplica principal au réplica secondaire à l’aide d’une seule connexion. Dans la section suivante, nous configurons et exécutons NTttcp pour utiliser une connexion unique (de la même manière que SQL Server) pour comparer le débit avec précision.
Vous pouvez télécharger NTttcp à partir de Github - microsoft/ntttcp.
Pour exécuter NTttcp, procédez comme suit :
Téléchargez et copiez l’outil sur les serveurs SQL Server principaux et secondaires.
Sur le serveur réplica secondaire, ouvrez une fenêtre d’invite de commandes avec élévation de privilèges, remplacez le répertoire par le dossier de l’outil NTttcp , puis exécutez la commande suivante :
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60Note
Dans cette commande,
<secondaryipaddress>il s’agit d’un espace réservé pour l’adresse IP réelle du serveur de réplica secondaire.Sur le serveur réplica principal, ouvrez une fenêtre d’invite de commandes avec élévation de privilèges, remplacez le répertoire par le dossier de l’outil NTttcp, puis exécutez à nouveau la commande suivante en spécifiant à nouveau l’adresse IP réelle du serveur de réplica secondaire :
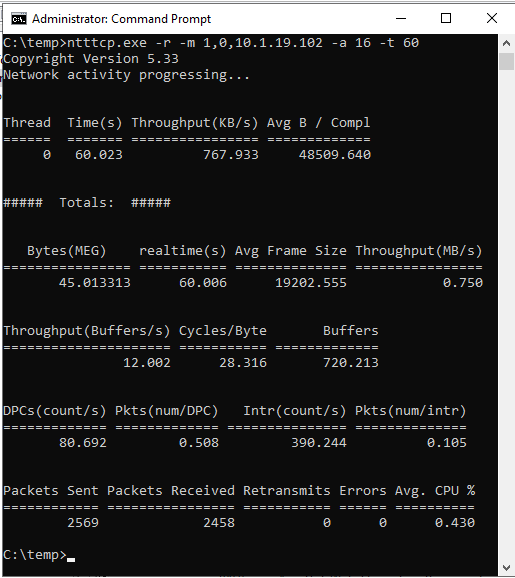
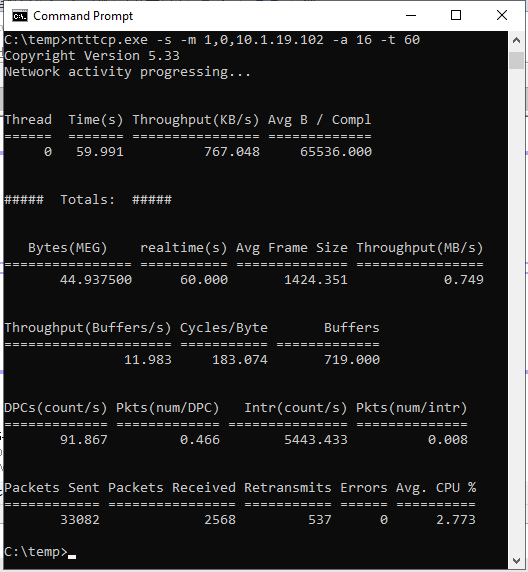
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60Les captures d’écran suivantes montrent que NTttcp s’exécute sur les réplicas secondaires et principaux. En raison de la latence réseau, l’outil peut envoyer seulement 739 Ko/s de données. C’est ce que vous pouvez vous attendre à ce que SQL Server puisse envoyer.
NTttcp sur le réplica secondaire
NTttcp sur le réplica principal
Passer en revue les compteurs Analyseur de performances
Vérifiez les rapports NTttcp. Une transaction volumineuse est exécutée dans SQL Server sur le réplica principal. Une fois que vous avez démarré Analyseur de performances sur le réplica principal, ajoutez le compteur d’interface réseau ::Bytes envoyés/s. Ce compteur confirme que le réplica principal peut envoyer environ 777 Ko/s de données. Cela est similaire à la valeur de 739 Ko/s signalée par le test NTttcp.

Il est également utile de comparer la valeur SQL Server ::D atabases ::Log Bytes Flushed/sec sur le réplica principal à SQL Server ::D atabase Replica ::Log Bytes Received/sec pour la même base de données sur le réplica secondaire. En moyenne, nous observons environ 20 Mo/s de modifications créées dans la base de données « agdb ». Toutefois, le réplica secondaire reçoit en moyenne seulement 5,4 Mo de modifications. Cela entraîne l’envoi du journal en file d’attente sur le réplica principal des modifications en attente dans le journal des transactions de base de données qui n’ont pas encore été envoyées au réplica secondaire.
Octets du journal du réplica principal vidés/s pour la base de données « agdb »

Octets du journal du réplica secondaire reçus/s pour la base de données agdb
