Tutoriel sur l’API WebNN
Pour une présentation de WebNN, notamment des informations sur la prise en charge du système d’exploitation, la prise en charge du modèle et bien plus encore, consultez la vue d’ensemble de WebNN.
Ce tutoriel vous montre comment utiliser l’API WebNN pour créer un système de classification d’images sur le web qui est accéléré par le matériel à l’aide du GPU sur appareil. Nous allons tirer parti du modèle MobileNetv2, qui est un modèle open source sur Hugging Face utilisé pour classifier des images.
Si vous souhaitez afficher et exécuter le code final de ce tutoriel, vous pouvez le trouver sur notre GitHub de préversion du développeur WebNN.
Remarque
L’API WebNN est une recommandation de candidat W3C et se trouve dans les premières phases d’un aperçu pour les développeurs. Certaines fonctionnalités sont limitées. Nous disposons d’une liste de l’état actuel de la prise en charge et de la mise en œuvre.
Exigences et configuration :
Configuration de Windows
Vérifiez que vous disposez des versions correctes des pilotes Edge, Windows et matériels, comme indiqué dans la section Configuration requise pour WebNN.
Configuration de Edge
Téléchargez et installez Microsoft Edge Dev.
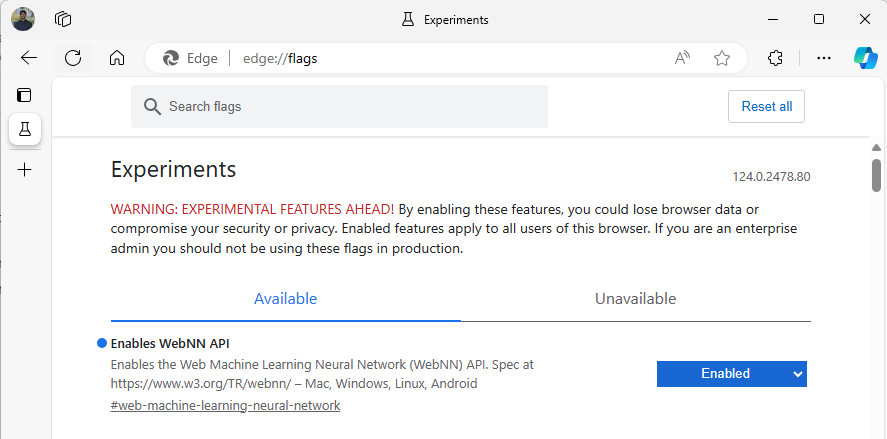
Lancez Edge Beta et accédez à
about:flagsdans la barre d’adresse.Recherchez « API WebNN », cliquez sur la liste déroulante, puis définissez sur « Activé ».
Redémarrez Edge, comme vous y êtes invité.
Configuration de l’environnement de développeur
Téléchargez et installez Visual Studio Code (VSCode).
Lancez VSCode.
Téléchargez et installez l’extension Live Server pour VSCode dans VSCode.
Sélectionnez
File --> Open Folder, puis créez un dossier vide à l’emplacement souhaité.
Étape 1 : initialiser l’application web
- Pour commencer, créez une page
index.html. Ajoutez le code réutilisable suivant à votre page :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Vérifiez que le code réutilisable et la configuration du développeur ont fonctionné en sélectionnant le bouton Démarrer en bas à droite de VSCode. Cela doit lancer un serveur local dans Edge Beta exécutant le code réutilisable.
- Maintenant, créez un fichier nommé
main.js. Ce fichier contient tout le code javascript de votre application. - Ensuite, créez un sous-dossier hors du répertoire racine nommé
images. Téléchargez et enregistrez une image dans le dossier. Pour cette démonstration, nous allons utiliser le nom par défaut deimage.jpg. - Téléchargez le modèle mobilenet depuis ONNX Model Zoo. Pour ce tutoriel, vous utiliserez le fichier mobilenet2-10.onnx. Enregistrez ce modèle dans le dossier racine de votre application web.
- Enfin, téléchargez et enregistrez ce fichier de classes d’images,
imagenetClasses.js. Il fournit 1000 classifications communes d’images que votre modèle peut utiliser.
Étape 2 : ajouter des éléments d’interface utilisateur et une fonction parente
- Dans le corps des balises html
<main>que vous avez ajoutées à l’étape précédente, remplacez le code existant par les éléments suivants. Celles-ci créent un bouton et affichent une image par défaut.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- Maintenant, vous allez ajouter ONNX Runtime Web à votre page, qui est une bibliothèque JavaScript que vous utiliserez pour accéder à l’API WebNN. Dans le corps des balises html
<head>, ajoutez les liens vers les sources javascript suivants.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
- Ouvrez votre fichier
main.jset ajoutez-y l’extrait de code suivant.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Étape 3 : pré-traiter les données
- La fonction que vous venez d’ajouter appelle
getImageTensorFromPath, une autre fonction que vous devez implémenter. Vous l’ajouterez ci-dessous, ainsi qu’une autre fonction asynchrone qu’elle appelle pour récupérer l’image elle-même.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- Vous devez également ajouter la fonction
imageDataToTensorréférencée ci-dessus, qui affiche l’image chargée dans un format de tenseur qui fonctionnera avec notre modèle ONNX. Il s’agit d’une fonction plus impliquée, même si elle peut sembler familière si vous avez déjà travaillé avec des applications de classification d’images similaires. Pour obtenir une explication étendue, vous pouvez consulter ce tutoriel ONNX.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Étape 4 : appeler WebNN
- Vous avez maintenant ajouté toutes les fonctions nécessaires pour récupérer votre image et l’aficher sous forme de tenseur. Maintenant, à l’aide de la bibliothèque web du runtime ONNX que vous avez chargée ci-dessus, vous allez exécuter votre modèle. Notez que pour utiliser WebNN ici, vous devez simplement spécifier
executionProvider = "webnn". La prise en charge d’ONNX Runtime rend l’activation de WebNN très simple.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
ort.env.wasm.proxy = true;
ort.env.logLevel = "verbose";
ort.env.debug = true;
// Configure WebNN.
const executionProvider = "webnn"; // Other options: webgpu
const modelPath = "./mobilenetv2-7.onnx"
const options = {
executionProviders: [{ name: executionProvider, deviceType: "gpu", powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Étape 5 : données post-traitement
- Enfin, vous allez ajouter une fonction
softmax, puis ajouter votre fonction finale pour retourner la classification d’images la plus probable.softmaxtransforme vos valeurs pour qu’elles soient comprises entre 0 et 1, ce qui est la forme de probabilité nécessaire pour cette classification finale.
Tout d’abord, ajoutez les fichiers sources suivants pour les bibliothèques d’assistance Jimp et Lodash dans la balise head de main.js.
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
À présent, ajoutez les fonctions suivantes à main.js.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- Vous avez maintenant ajouté tous les scripts dont vous avez besoin pour exécuter la classification d’images avec WebNN dans votre application web de base. À l’aide de l’extension Live Server pour VS Code, vous pouvez maintenant lancer votre page web de base dans l’application pour voir les résultats de la classification.