Mappages d’ombres en cascade (CSM)
Les cartes d’ombres en cascade (CSM) sont le meilleur moyen de lutter contre l’une des erreurs les plus répandues avec l’ombre : l’alias de perspective. Cet article technique, qui suppose que le lecteur est familiarisé avec le mappage de clichés instantanés, aborde le sujet des machines virtuelles cloud. Plus précisément, il :
- explique la complexité des CSM;
- fournit des détails sur les variantes possibles des algorithmes CSM ;
- décrit les deux techniques de filtrage les plus courantes : le filtrage plus rapproché en pourcentage (PCF) et le filtrage avec des mappages instantanés de variance (VSM) ;
- identifie et résout certains des pièges courants associés à l’ajout d’un filtrage aux CSM ; Et
- montre comment mapper des machines virtuelles à du matériel Direct3D 10 à Direct3D 11.
Le code utilisé dans cet article se trouve dans le Kit de développement logiciel (SDK) DirectX dans les exemples CascadedShadowMaps11 et VarianceShadows11. Cet article s’avérera plus utile après l’implémentation des techniques abordées dans l’article technique, Common Techniques to Improve Shadow Depth Maps, sont implémentées.
Mappages d’ombres en cascade et alias de perspective
L’alias de perspective dans une carte fantôme est l’un des problèmes les plus difficiles à surmonter. Dans l’article technique Techniques courantes pour améliorer les cartes de profondeur d’ombre, l’alias de perspective est décrit et certaines approches pour atténuer le problème sont identifiées. Dans la pratique, les CSM ont tendance à être la meilleure solution et sont couramment utilisés dans les jeux modernes.
Le concept de base des CSM est facile à comprendre. Différentes zones du frustum de la caméra nécessitent des cartes d’ombres avec des résolutions différentes. Les objets les plus proches de l’œil nécessitent une résolution plus élevée que les objets plus distants. En fait, lorsque l’œil se déplace très près de la géométrie, les pixels les plus proches de l’œil peuvent nécessiter une résolution telle que même une carte d’ombres 4096 × 4096 est insuffisante.
L’idée de base des CSM est de partitionner le frustum en plusieurs frustas. Une carte d’ombres est affichée pour chaque sous-objet ; le nuanceur de pixels échantillonne ensuite à partir de la carte qui correspond le plus étroitement à la résolution requise (Figure 2).
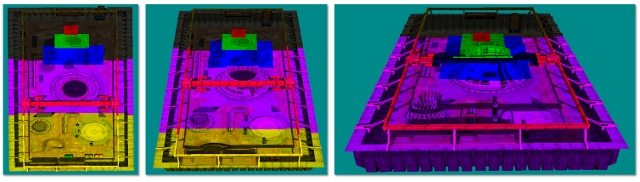
Figure 1. Couverture des clichés instantanés
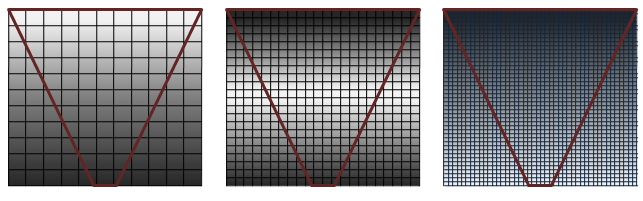
Dans la figure 1, la qualité est indiquée (de gauche à droite) de la plus élevée à la plus faible. La série de grilles représentant des cartes d’ombres avec un frustum d’affichage (cône inversé en rouge) montre comment la couverture en pixels est affectée avec différentes cartes d’ombres de résolution. Les ombres sont de la meilleure qualité (pixels blancs) lorsqu’il y a un rapport 1:1 qui mappe les pixels dans l’espace clair aux texels dans la carte d’ombres. L’alias de perspective se produit sous la forme de grandes cartes de textures bloquées (image de gauche) lorsque trop de pixels sont mappés au même texel d’ombre. Lorsque la carte fantôme est trop grande, elle est sous-échantillonnées. Dans ce cas, les texels sont ignorés, des artefacts chatoyants sont introduits et les performances sont affectées.
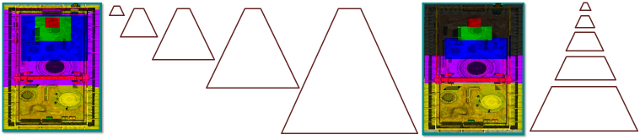
Figure 2 : Qualité de l’ombre CSM
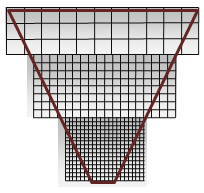
La figure 2 montre les découpes de la section de qualité la plus élevée dans chaque shadow map de la figure 1. La carte d’ombres avec les pixels les plus proches (à l’apex) est la plus proche de l’œil. Techniquement, il s’agit de cartes de même taille, avec le blanc et le gris utilisés pour illustrer le succès de la carte d’ombre en cascade. Le blanc est idéal, car il affiche une bonne couverture, un rapport de 1:1 pour les pixels d’espace oculaire et les texels de carte d’ombre.
Les machines virtuelles cloud nécessitent les étapes suivantes par image.
Partitionnez le frustum en subfrusta.
Calculez une projection orthographique pour chaque sous-frustum.
Affiche une carte de clichés instantanés pour chaque sous-élément.
Restituer la scène.
Lier les clichés d’ombres et le rendu.
Le nuanceur de vertex effectue les opérations suivantes :
- Calcule les coordonnées de texture pour chaque sous-fragment clair (sauf si la coordonnée de texture nécessaire est calculée dans le nuanceur de pixels).
- Transforme et allume le sommet, et ainsi de suite.
Le nuanceur de pixels effectue les opérations suivantes :
- Détermine la carte de ombres appropriée.
- Transforme les coordonnées de texture si nécessaire.
- Échantillonne la cascade.
- Allume le pixel.
Partitionnement du frustum
Le partitionnement du frustum est l’acte de créer une sous-ressource. Une technique de fractionnement du frustum consiste à calculer des intervalles de zéro à cent pour cent dans la direction Z. Chaque intervalle représente ensuite un plan proche et un plan lointain sous la forme d’un pourcentage de l’axe Z.
Figure 3. Afficher les frustums partitionnés arbitrairement
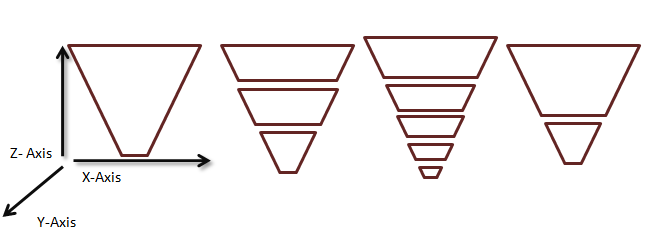
Dans la pratique, le recalcul des fractionnements de frustum par image fait scintiller les bords de l’ombre. La pratique généralement acceptée consiste à utiliser un ensemble statique d’intervalles en cascade par scénario. Dans ce scénario, l’intervalle le long de l’axe Z est utilisé pour décrire un sous-élément qui se produit lors du partitionnement du frustum. La détermination des intervalles de taille corrects pour une scène donnée dépend de plusieurs facteurs.
Orientation de la géométrie de la scène
En ce qui concerne la géométrie de la scène, l’orientation de la caméra affecte la sélection de l’intervalle en cascade. Par exemple, une caméra très près du sol, telle qu’une caméra au sol dans un match de football, a un ensemble statique d’intervalles en cascade différent de celui d’une caméra dans le ciel.
La figure 4 montre des caméras différentes et leurs partitions respectives. Lorsque la plage Z de la scène est très grande, davantage de plans fractionnés sont nécessaires. Par exemple, lorsque l’œil est très proche du plan de sol, mais que des objets distants sont toujours visibles, plusieurs cascades peuvent être nécessaires. Il est également utile de diviser le frustum afin que d’autres fractionnements soient près de l’œil (où l’alias de perspective change le plus rapidement). Lorsque la majeure partie de la géométrie est agglomrée dans une petite section (comme une vue aérienne ou un simulateur de vol) du frustum de vue, moins de cascades sont nécessaires.
Figure 4. Différentes configurations nécessitent des fractionnements de frustum différents
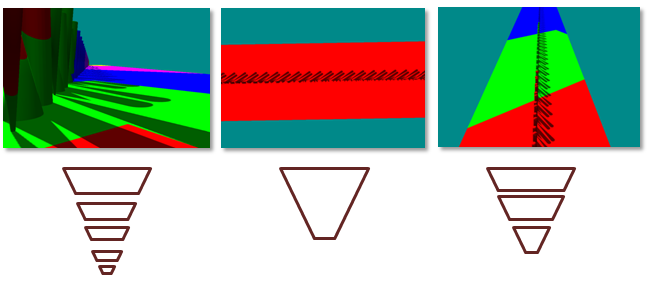
(Gauche) Lorsque geometry a une plage dynamique élevée en Z, de nombreuses cascades sont nécessaires. (Au centre) Lorsque la géométrie a une plage dynamique faible en Z, il n’y a que peu d’avantages de plusieurs frustums. (À droite) Seules trois partitions sont nécessaires lorsque la plage dynamique est moyenne.
Orientation de la lumière et de l’appareil photo
La matrice de projection de chaque cascade est étroitement ajustée autour de son sous-frustum correspondant. Dans les configurations où la caméra de vue et les directions de lumière sont orthogonales, les cascades peuvent être ajustées étroitement avec peu de chevauchement. Le chevauchement devient plus important à mesure que la lumière et la caméra de vue se déplacent dans l’alignement parallèle (Figure 5). Lorsque la lumière et la caméra de vue sont presque parallèles, il s’agit d’un « frusta du duc » et est un scénario très difficile pour la plupart des algorithmes d’ombre. Il n’est pas rare de limiter la lumière et la caméra afin que ce scénario ne se produise pas. Toutefois, les machines virtuelles cloud fonctionnent beaucoup mieux que de nombreux autres algorithmes dans ce scénario.
Figure 5. Le chevauchement en cascade augmente à mesure que la direction de la lumière devient parallèle à la direction de la caméra
De nombreuses implémentations CSM utilisent des frustas de taille fixe. Le nuanceur de pixels peut utiliser la profondeur Z pour indexer dans le tableau de cascades lorsque le frustum est fractionné dans des intervalles de taille fixe.
Calcul d’une View-Frustum liée
Une fois les intervalles de frustum sélectionnés, les sous-fruits sont créés à l’aide de l’un des deux suivants : ajuster à la scène et ajuster en cascade.
Ajuster à la scène
Tous les frustas peuvent être créés avec le même plan proche. Cela force les cascades à se chevaucher. L’exemple CascadedShadowMaps11 appelle cette technique adaptée à la scène.
Ajuster à cascade
Vous pouvez également créer des frustas avec l’intervalle de partition réel utilisé comme plans proches et lointains. Cela entraîne un ajustement plus serré, mais dégénère pour s’adapter à la scène dans le cas de frusta du. Les exemples CascadedShadowMaps11 appellent cette technique adaptée à la cascade.
Ces deux méthodes sont présentées à la figure 6. Ajuster en cascade gaspille moins de résolution. Le problème de l’ajustement en cascade est que la projection orthographique augmente et se réduit en fonction de l’orientation du frustum de vue. La technique d’ajustement à la scène coupe la projection orthographique par la taille maximale du frustum de la vue, en supprimant les artefacts qui apparaissent lorsque la vue-caméra se déplace. Common Techniques to Improve Shadow Depth Maps traite des artefacts qui apparaissent lorsque la lumière se déplace dans la section « Déplacement de la lumière en incréments de taille texel ».
Figure 6. Ajuster à la scène ou à la cascade
Afficher le shadow map
L’exemple CascadedShadowMaps11 restitue les clichés d’ombres dans une grande mémoire tampon. Cela est dû au fait que PCF sur les tableaux de textures est une fonctionnalité Direct3D 10.1. Pour chaque cascade, une fenêtre d’affichage qui couvre la section de la mémoire tampon de profondeur correspondant à cette cascade est créée. Un nuanceur de pixels Null est lié, car seule la profondeur est nécessaire. Enfin, la fenêtre d’affichage et la matrice d’ombre appropriées sont définies pour chaque cascade, car les cartes de profondeur sont rendues une par une dans la mémoire tampon d’ombre main.
Rendu de la scène
La mémoire tampon contenant les ombres est maintenant liée au nuanceur de pixels. Il existe deux méthodes pour sélectionner la cascade implémentée dans l’exemple CascadedShadowMaps11. Ces deux méthodes sont expliquées avec du code de nuanceur.
Interval-Based Cascade Selection
Figure 7. Sélection en cascade basée sur l’intervalle

Dans la sélection basée sur les intervalles (Figure 7), le nuanceur de vertex calcule la position dans l’espace universel du vertex.
Output.vDepth = mul( Input.vPosition, m_mWorldView ).z;
Le nuanceur de pixels reçoit la profondeur interpolée.
fCurrentPixelDepth = Input.vDepth;
La sélection en cascade basée sur l’intervalle utilise une comparaison vectorielle et un produit point pour déterminer la bonne cacade. Le CASCADE_COUNT_FLAG spécifie le nombre de cascades. La m_fCascadeFrustumsEyeSpaceDepths_data limite les partitions frustum de vue. Après la comparaison, fComparison contient une valeur de 1, où le pixel actuel est plus grand que la barrière, et une valeur de 0 lorsque la cascade actuelle est plus petite. Un produit dot additionne ces valeurs dans un index de tableau.
float4 vCurrentPixelDepth = Input.vDepth;
float4 fComparison = ( vCurrentPixelDepth > m_fCascadeFrustumsEyeSpaceDepths_data[0]);
float fIndex = dot(
float4( CASCADE_COUNT_FLAG > 0,
CASCADE_COUNT_FLAG > 1,
CASCADE_COUNT_FLAG > 2,
CASCADE_COUNT_FLAG > 3)
, fComparison );
fIndex = min( fIndex, CASCADE_COUNT_FLAG );
iCurrentCascadeIndex = (int)fIndex;
Une fois la cascade sélectionnée, la coordonnée de texture doit être transformée en cascade correcte.
vShadowTexCoord = mul( InterpolatedPosition, m_mShadow[iCascadeIndex] );
Cette coordonnée de texture est ensuite utilisée pour échantillonner la texture avec la coordonnée X et la coordonnée Y. La coordonnée Z est utilisée pour effectuer la comparaison de profondeur finale.
Map-Based Cascade Selection
La sélection basée sur la carte (Figure 8) effectue des tests sur les quatre côtés des cascades pour trouver la carte la plus étroite qui couvre le pixel spécifique. Au lieu de calculer la position dans l’espace mondial, le nuanceur de vertex calcule la position de l’espace d’affichage pour chaque cascade. Le nuanceur de pixels itère sur les cascades afin de mettre à l’échelle et de décaler les coordonnées de texture afin qu’elles indexent la cascade actuelle. La coordonnée de texture est ensuite testée par rapport aux limites de texture. Lorsque les valeurs X et Y de la coordonnée de texture tombent à l’intérieur d’une cascade, elles sont utilisées pour échantillonner la texture. La coordonnée Z est utilisée pour effectuer la comparaison de profondeur finale.
Figure 8. Sélection en cascade basée sur la carte

sélection Interval-Based et sélection Map-Based
La sélection basée sur les intervalles est légèrement plus rapide que la sélection basée sur une carte, car la sélection en cascade peut être effectuée directement. La sélection basée sur une carte doit croiser la coordonnée de texture avec les limites de cascade.
La sélection basée sur une carte utilise la cascade plus efficacement lorsque les cartes d’ombres ne s’alignent pas parfaitement (voir la figure 8).
Fondre entre cascades
Les machines virtuelles virtuelles (décrites plus loin dans cet article) et les techniques de filtrage telles que PCF peuvent être utilisées avec des CSM basse résolution pour produire des ombres douces. Malheureusement, cela entraîne une séparation visible (Figure 9) entre les couches en cascade, car la résolution ne correspond pas. La solution consiste à créer une bande entre les cartes d’ombres où le test d’ombre est effectué pour les deux cascades. Le nuanceur effectue ensuite une interpolation linéaire entre les deux valeurs en fonction de l’emplacement du pixel dans la bande de fusion. Les exemples CascadedShadowMaps11 et VarianceShadows11 fournissent un curseur d’interface utilisateur graphique qui peut être utilisé pour augmenter et diminuer cette bande de flou. Le nuanceur effectue une branche dynamique afin que la grande majorité des pixels lisent uniquement à partir de la cascade actuelle.
Figure 9. Coutures en cascade

(Gauche) On peut voir une couture visible où les cascades se chevauchent. (À droite) Lorsque les cascades sont mélangées entre elles, aucune couture ne se produit.
Filtrage des clichés d’ombres
PCF
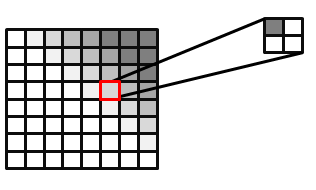
Le filtrage des cartes d’ombres ordinaires ne produit pas d’ombres douces et floues. Le matériel de filtrage brouille les valeurs de profondeur, puis compare ces valeurs floues au texel de l’espace lumineux. Le bord dur résultant du test de réussite/échec existe toujours. Les cartes d’ombres floues ne servent qu’à déplacer par erreur le bord dur. PCF active le filtrage sur les shadow maps. L’idée générale de PCF est de calculer un pourcentage du pixel dans l’ombre en fonction du nombre de sous-échantillons qui réussissent le test de profondeur sur le nombre total de sous-échantillons.
Les matériels Direct3D 10 et Direct3D 11 peuvent exécuter PCF. L’entrée d’un échantillonneur PCF se compose de la coordonnée de texture et d’une valeur de profondeur de comparaison. Par souci de simplicité, PCF est expliqué avec un filtre à quatre appuis. L’échantillonneur de texture lit la texture quatre fois, comme un filtre standard. Toutefois, le résultat retourné est un pourcentage des pixels qui ont réussi le test de profondeur. La figure 10 montre comment un pixel qui réussit l’un des quatre tests de profondeur est de 25 % dans l’ombre. La valeur réelle retournée est une interpolation linéaire basée sur les coordonnées de sous-texel de la texture lue pour produire un dégradé lisse. Sans cette interpolation linéaire, le PCF à quatre appuis ne serait en mesure de retourner que cinq valeurs : { 0.0, 0.25, 0.5, 0.75, 1.0 }.
Figure 10. Image filtrée PCF, avec 25 % du pixel sélectionné couvert
Il est également possible d’effectuer un PCF sans prise en charge matérielle ou d’étendre PCF à des noyaux plus grands. Certaines techniques échantillonneraient même avec un noyau pondéré. Pour ce faire, créez un noyau (par exemple, un gaussien) pour une grille N × N. Les poids doivent ajouter jusqu’à 1. La texture est ensuite échantillonné N2 fois. Chaque échantillon est mis à l’échelle selon les pondérations correspondantes dans le noyau. L’exemple CascadedShadowMaps11 utilise cette approche.
Biais de profondeur
Le biais de profondeur devient encore plus important lorsque des noyaux PCF volumineux sont utilisés. Il est uniquement valide de comparer la profondeur de l’espace lumineux d’un pixel à celui auquel il est mappé dans la carte de profondeur. Les voisins du texel de la carte de profondeur font référence à une position différente. Cette profondeur est susceptible d’être similaire, mais peut être très différente selon la scène. La figure 11 met en évidence les artefacts qui se produisent. Une seule profondeur est comparée à trois texels voisins dans la carte d’ombres. L’un des tests de profondeur échoue par erreur, car sa profondeur n’est pas corrélée à la profondeur calculée de l’espace lumineux de la géométrie actuelle. La solution recommandée à ce problème consiste à utiliser un décalage plus grand. Un décalage trop important, cependant, peut entraîner peter panning. Le calcul d’un plan proche serré et d’un plan lointain permet de réduire les effets de l’utilisation d’un décalage.
Figure 11. Auto-ombre erronée
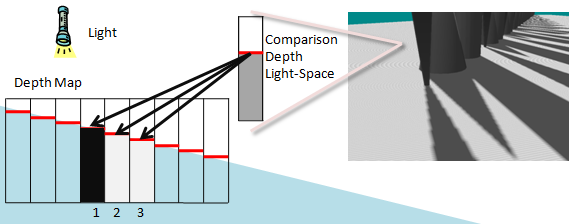
L’auto-ombrage erroné résulte de la comparaison des pixels de la profondeur de l’espace lumineux aux texels de la carte d’ombres qui ne sont pas corrélés. La profondeur dans l’espace lumineux est corrélée au texel d’ombre 2 dans la carte de profondeur. Texel 1 est supérieur à la profondeur de l’espace lumineux tandis que 2 est égal et 3 est inférieur. Texels 2 et 3 réussissent le test de profondeur, tandis que Texel 1 échoue.
Calcul d’un biais de profondeur Per-Texel avec DDX et DDY pour les pcFs volumineux
Le calcul d’un biais de profondeur par texel avec ddx et ddy pour les pcFs volumineux est une technique qui calcule le biais de profondeur correct (en supposant que la surface est planaire) pour le texel de carte d’ombres adjacent.
Cette technique permet d’adapter la profondeur de comparaison à un plan à l’aide des informations dérivées. Étant donné que cette technique est complexe sur le point de vue du calcul, elle ne doit être utilisée que lorsqu’un GPU a des cycles de calcul à épargner. Lorsque des noyaux très volumineux sont utilisés, il peut s’agir de la seule technique qui fonctionne pour supprimer les artefacts d’ombre automatique sans provoquer peter panning.
La figure 12 met en évidence le problème. La profondeur dans l’espace lumineux est connue pour le seul texel qui est comparé. Les profondeurs d’espace lumineux qui correspondent aux texels voisins dans la carte de profondeur sont inconnues.
Figure 12 : Carte de scène et de profondeur

La scène rendue s’affiche à gauche, et la carte de profondeur avec un exemple de bloc de texel s’affiche à droite. Le texel d’espace oculaire est mappé au pixel étiqueté D au centre du bloc. Cette comparaison est exacte. Profondeur correcte dans l’espace oculaire correspondant aux pixels dont le voisin D est inconnu. Le mappage des texels voisins à l’espace visuel n’est possible que si nous supposons que le pixel se rapporte au même triangle que D.
La profondeur est connue pour le texel qui correspond à la position de l’espace clair. La profondeur est inconnue pour les texels voisins dans la carte de profondeur.
À un niveau élevé, cette technique utilise les opérations HLSL ddx et ddy pour trouver le dérivé de la position de l’espace clair. Cela n’est pas dérivé, car les opérations dérivées retournent le dégradé de la profondeur de l’espace lumineux par rapport à l’espace d’écran. Pour convertir cela en dégradé de la profondeur de l’espace lumineux par rapport à l’espace lumineux, une matrice de conversion doit être calculée.
Explication avec le code de nuanceur
Les détails du reste de l’algorithme sont donnés en tant qu’explication du code de nuanceur qui effectue cette opération. Ce code se trouve dans l’exemple CascadedShadowMaps11. La figure 13 montre comment les coordonnées de texture d’espace clair sont mappées à la carte de profondeur et comment les dérivés en X et Y peuvent être utilisés pour créer une matrice de transformation.
Figure 13 : Espace d’écran à matrice d’espace clair
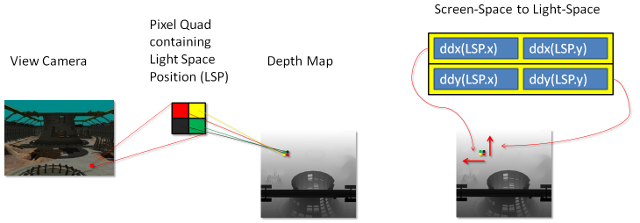
Les dérivés de la position de l’espace lumineux dans X et Y sont utilisés pour créer cette matrice.
La première étape consiste à calculer la dérivée de la position lumière-vue-espace.
float3 vShadowTexDDX = ddx (vShadowMapTextureCoordViewSpace);
float3 vShadowTexDDY = ddy (vShadowMapTextureCoordViewSpace);
Les GPU de classe Direct3D 11 calculent ces dérivés en exécutant 2 × 2 quads de pixels en parallèle et en soustrayant les coordonnées de texture du voisin dans X pour ddx et du voisin dans Y pour ddy. Ces deux dérivées constituent les lignes d’une matrice 2 × 2. Dans sa forme actuelle, cette matrice pourrait être utilisée pour convertir les pixels voisins de l’espace d’écran en pentes d’espace clair. Toutefois, l’inverse de cette matrice est nécessaire. Une matrice qui transforme les pixels voisins de l’espace lumineux en pentes d’espace d’écran est nécessaire.
float2x2 matScreentoShadow = float2x2( vShadowTexDDX.xy, vShadowTexDDY.xy );
float fInvDeterminant = 1.0f / fDeterminant;
float2x2 matShadowToScreen = float2x2 (
matScreentoShadow._22 * fInvDeterminant,
matScreentoShadow._12 * -fInvDeterminant,
matScreentoShadow._21 * -fInvDeterminant,
matScreentoShadow._11 * fInvDeterminant );
Figure 14. Espace clair à espace d’écran

Cette matrice est ensuite utilisée pour transformer les deux texels au-dessus et à droite du texel actuel. Ces voisins sont représentés sous forme de décalage par rapport au texel actuel.
float2 vRightShadowTexelLocation = float2( m_fTexelSize, 0.0f );
float2 vUpShadowTexelLocation = float2( 0.0f, m_fTexelSize );
float2 vRightTexelDepthRatio = mul( vRightShadowTexelLocation,
matShadowToScreen );
float2 vUpTexelDepthRatio = mul( vUpShadowTexelLocation,
matShadowToScreen );
Le rapport créé par la matrice est finalement multiplié par les dérivés de profondeur pour calculer les décalages de profondeur pour les pixels voisins.
float fUpTexelDepthDelta =
vUpTexelDepthRatio.x * vShadowTexDDX.z
+ vUpTexelDepthRatio.y * vShadowTexDDY.z;
float fRightTexelDepthDelta =
vRightTexelDepthRatio.x * vShadowTexDDX.z
+ vRightTexelDepthRatio.y * vShadowTexDDY.z;
Ces pondérations peuvent désormais être utilisées dans une boucle PCF pour ajouter un décalage à la position.
for( int x = m_iPCFBlurForLoopStart; x < m_iPCFBlurForLoopEnd; ++x )
{
for( int y = m_iPCFBlurForLoopStart; y < m_iPCFBlurForLoopEnd; ++y )
{
if ( USE_DERIVATIVES_FOR_DEPTH_OFFSET_FLAG )
{
depthcompare += fRightTexelDepthDelta * ( (float) x ) +
fUpTexelDepthDelta * ( (float) y );
}
// Compare the transformed pixel depth to the depth read
// from the map.
fPercentLit += g_txShadow.SampleCmpLevelZero( g_samShadow,
float2(
vShadowTexCoord.x + ( ( (float) x ) * m_fNativeTexelSizeInX ) ,
vShadowTexCoord.y + ( ( (float) y ) * m_fTexelSize )
),
depthcompare
);
}
}
PCF et CSM
PCF ne fonctionne pas sur les tableaux de textures dans Direct3D 10. Pour utiliser PCF, toutes les cascades sont stockées dans un grand atlas de textures.
décalage Derivative-Based
L’ajout des décalages basés sur les dérivés pour les modules de sécurité partagés présente certains défis. Cela est dû à un calcul dérivé dans un contrôle de flux divergent. Le problème se produit en raison d’une façon fondamentale de fonctionnement des GPU. Les GPU Direct3D11 fonctionnent sur 2 × 2 quads de pixels. Pour effectuer un dérivé, les GPU soustraient généralement la copie du pixel actuel d’une variable de la copie de cette même variable par le pixel voisin. La façon dont cela se produit varie d’un GPU à l’autre. Les coordonnées de texture sont déterminées par la sélection en cascade basée sur une carte ou un intervalle. Certains pixels d’un quad de pixels choisissent une cascade différente de celle des autres pixels. Cela se traduit par des coutures visibles entre les cartes d’ombres, car les décalages basés sur les dérivés sont maintenant complètement incorrects. La solution consiste à effectuer la dérivée sur les coordonnées de texture d’espace d’affichage lumineux. Ces coordonnées sont les mêmes pour chaque cascade.
Remplissage pour les noyaux PCF
Les noyaux PCF indexent en dehors d’une partition en cascade si la mémoire tampon d’ombre n’est pas rembourrée. La solution consiste à remplir le bord externe de la cascade de la moitié de la taille du noyau PCF. Cela doit être implémenté dans le nuanceur qui sélectionne la cascade et dans la matrice de projection qui doit rendre la cascade suffisamment grande pour que la bordure soit conservée.
Mappages d’ombres de variance
Les machines virtuelles virtuelles (voir Variance shadow maps de Donnelly et Lauritzen pour plus d’informations) permettent le filtrage direct des shadow map. Lorsque vous utilisez des machines virtuelles, toute la puissance du matériel de filtrage de texture peut être utilisée. Le filtrage trilinéaire et anisotrope (Figure 15) peut être utilisé. En outre, les machines virtuelles peuvent être floues directement par le biais de la convolution. Les machines virtuelles présentent certains inconvénients ; deux canaux de données de profondeur doivent être stockés (profondeur et profondeur au carré). Lorsque les ombres se chevauchent, la saignée de lumière est courante. Ils fonctionnent bien, cependant, avec des résolutions inférieures et peuvent être combinés avec des CSM.
Figure 15. Filtrage anisotropique

Détails des algorithmes
Les machines virtuelles fonctionnent en rendant la profondeur et la profondeur au carré sur une carte d’ombres à deux canaux. Cette carte d’ombres à deux canaux peut ensuite être floue et filtrée comme une texture normale. L’algorithme utilise ensuite l’inégalité de Chebychev dans le nuanceur de pixels pour estimer la fraction de la zone de pixels qui réussirait le test de profondeur.
Le nuanceur de pixels extrait les valeurs de profondeur et de profondeur carrées.
float fAvgZ = mapDepth.x; // Filtered z
float fAvgZ2 = mapDepth.y; // Filtered z-squared
La comparaison de profondeur est effectuée.
if ( fDepth <= fAvgZ )
{
fPercentLit = 1;
}
Si la comparaison de profondeur échoue, le pourcentage du pixel allumé est estimé. La variance est calculée en moyenne des carrés moins le carré de la moyenne.
float variance = ( fAvgZ2 ) − ( fAvgZ * fAvgZ );
variance = min( 1.0f, max( 0.0f, variance + 0.00001f ) );
La valeur fPercentLit est estimée avec l’inégalité de Tchébychev.
float mean = fAvgZ;
float d = fDepth - mean;
float fPercentLit = variance / ( variance + d*d );
Saignement léger
Le principal inconvénient des machines virtuelles est le saignement léger (Figure 16). Le saignement de lumière se produit lorsque plusieurs roulettes d’ombres s’obstruent l’un l’autre le long des bords. Les machines virtuelles ombrent les bords des ombres en fonction des disparités de profondeur. Lorsque les ombres se chevauchent, une disparité de profondeur existe au centre d’une région qui doit être ombrée. Il s’agit d’un problème avec l’utilisation de l’algorithme VSM.
Figure 16. VSM léger saignement

Une solution partielle au problème consiste à élever le fPercentLit à une alimentation. Cela a pour effet d’atténuer le flou, ce qui peut provoquer des artefacts où la disparité de profondeur est faible. Il existe parfois une valeur magique qui atténue le problème.
fPercentLit = pow( p_max, MAGIC_NUMBER );
Une alternative à l’élévation du pourcentage allumé à une puissance consiste à éviter les configurations où les ombres se chevauchent. Même les configurations d’ombre très ajustées ont plusieurs contraintes sur la lumière, l’appareil photo et la géométrie. Le saignement léger est également atténué en utilisant des textures de résolution plus élevée.
Les cartes d’ombres de variance en couches (LVSM) résolvent le problème au détriment de la rupture du frustum en couches perpendiculaires à la lumière. Le nombre de cartes requises serait assez important lorsque les modules de sécurité partagés sont également utilisés.
En outre, Andrew Lauritzen, co-auteur de l’article sur les machines virtuelles et auteur d’un article sur les LVSM, a parlé de la combinaison de cartes d’ombres exponentielles (ESM) avec des machines virtuelles pour contrer la fusion de la lumière dans un forum Beyond3D.
Machines virtuelles avec CSM
L’exemple VarianceShadow11 combine des machines virtuelles et des CSM. La combinaison est assez simple. L’exemple suit les mêmes étapes que l’exemple CascadedShadowMaps11. Étant donné que PCF n’est pas utilisé, les ombres sont floues dans une convolution séparable à deux pas. Le fait de ne pas utiliser PCF permet également à l’exemple d’utiliser des tableaux de textures au lieu d’un atlas de textures. PCF sur les tableaux de textures est une fonctionnalité Direct3D 10.1.
Dégradés avec des CSM
L’utilisation de dégradés avec des CSM peut produire une jointure le long de la frontière entre deux cascades, comme le montre la figure 17. L’exemple d’instruction utilise des dérivés entre pixels pour calculer les informations, telles que le niveau mipmap, nécessaires au filtre. Cela provoque un problème en particulier pour la sélection de mipmap ou le filtrage anisotrope. Lorsque les pixels d’un quad prennent différentes branches dans le nuanceur, les dérivés calculés par le matériel GPU ne sont pas valides. Il en résulte une couture déchiquetée le long de la carte d’ombres.
Figure 17. Coutures sur les bordures en cascade en raison d’un filtrage anisotrope avec un contrôle de flux divergent

Ce problème est résolu en calculant les dérivés sur la position dans l’espace de vue de la lumière; la coordonnée d’espace d’affichage de la lumière n’est pas spécifique à la cascade sélectionnée. Les dérivés calculés peuvent être mis à l’échelle par la partie d’échelle de la matrice projection-texture au niveau mipmap correct.
float3 vShadowTexCoordDDX = ddx( vShadowMapTextureCoordViewSpace );
vShadowTexCoordDDX *= m_vCascadeScale[iCascade].xyz;
float3 vShadowTexCoordDDY = ddy( vShadowMapTextureCoordViewSpace );
vShadowTexCoordDDY *= m_vCascadeScale[iCascade].xyz;
mapDepth += g_txShadow.SampleGrad( g_samShadow, vShadowTexCoord.xyz,
vShadowTexCoordDDX, vShadowTexCoordDDY );
VsMs comparés aux ombres standard avec PCF
Les machines virtuelles virtuelles et PCF tentent d’approcher la fraction de la zone de pixels qui réussirait le test de profondeur. Les machines virtuelles fonctionnent avec du matériel de filtrage et peuvent être floues avec des noyaux séparables. Les noyaux de convolution séparables sont considérablement moins coûteux à implémenter qu’un noyau complet. En outre, les machines virtuelles comparent une profondeur d’espace lumineux à une valeur dans la carte de profondeur de l’espace lumineux. Cela signifie que les machines virtuelles n’ont pas les mêmes problèmes de décalage que les PCF. Techniquement, les machines virtuelles effectuent un échantillonnage de profondeur sur une plus grande zone et effectuent une analyse statistique. C’est moins précis que le PCF. Dans la pratique, les machines virtuelles effectuent un très bon travail de fusion, ce qui entraîne moins de décalage nécessaire. Comme décrit ci-dessus, le principal inconvénient des machines virtuelles est le saignement léger.
Les machines virtuelles et PCF représentent un compromis entre la puissance de calcul GPU et la bande passante de texture GPU. Les machines virtuelles nécessitent plus de mathématiques pour calculer la variance. PCF nécessite plus de bande passante de mémoire de texture. Les noyaux PCF volumineux peuvent rapidement devenir goulots d’étranglement par la bande passante de texture. Avec la puissance de calcul gpu augmentant plus rapidement que la bande passante GPU, les machines virtuelles deviennent les plus pratiques des deux algorithmes. Les machines virtuelles sont également plus performantes avec des mappages d’ombres de résolution inférieure en raison de la fusion et du filtrage.
Résumé
Les CSM offrent une solution au problème d’alias de perspective. Il existe plusieurs configurations possibles pour obtenir la fidélité visuelle nécessaire pour un titre. PcF et vsMs sont largement utilisés et doivent être combinés avec des CSM pour réduire l’aliasing.
Références
Donnelly, W. et Lauritzen, A. Variance shadow maps. In SI3D '06: Actes du symposium 2006 sur les graphiques et jeux interactifs 3D. 2006. p. 161 à 165. New York, NY, États-Unis: ACM Press.
Lauritzen, Andrew et McCool, Michael. Mappages d’ombres de variance en couches. Actes de l’interface graphique 2008, 28-30 mai 2008, Windsor, Ontario, Canada.
Engel, Woflgang F. Section 4. Cartes d’ombres en cascade. ShaderX5 , Advanced Rendering Techniques, Wolfgang F. Engel, Ed. Charles River Media, Boston, Massachusetts. 2006. p. 197-206.