Clustered Column Store Index: Bulk Loading the Data
Clustered Column Store: Bulk Load
As described in the blog https://blogs.msdn.com/b/sqlserverstorageengine/archive/2014/07/27/clustered-column-store-index-concurrency-and-isolation-level.aspx, the clustered column store index has been optimized for typical DW scenario supporting nightly or trickle data load with fast query performance. Multiple inserts can load the data in parallel concurrently while DW queries are being run in read uncommitted transaction isolation level.
This blog describes locking behavior when data is inserted through Bulk Load command. Here is the table we will use in the example
Create table t_bulkload (
accountkey int not null,
accountdescription nvarchar (50),
accounttype nvarchar(50),
AccountCodeAlternatekey int)
Bulk loading into CCI
A more common scenario is to bulk import data into CCI. The bulk import loads the data into delta store if the batch size is < 100K rows otherwise the rows are directly loaded into a compressed row group. Let us walk through an example of illustrate Bulk Load
-- Let us prepare the data
-- insert 110K rows into a regular table
begin tran
declare @i int = 0
while (@i < 110000)
begin
insert into t_bulkload values (@i, 'description', 'dummy-accounttype', @i*2)
set @i = @i + 1
end
commit
-- bcp out the data... run the following command in command window
bcp adventureworksDW2012..t_bulkload out c:\temp\t_bulkoad.dat -c -T
As the next step, let us truncate the table t_bulkload and create a clustered columnstore index on it. At this time, there are no rowgroups as the table has no rows
--truncate the table
Truncate table t_bulkload
-- convert row clustered index into clustered columnstore index
CREATE CLUSTERED COLUMNSTORE index t_bulkload_cci on t_bulkload
Now, we will bulk import the data with a batchsize > 102400 as follows. Notice, I am running this command under a transaction. This will help us identify us to see what locks are taken
-- now bulkload the data
begin tran
bulk insert t_bulkload
FROM 'c:\temp\t_bulkoad.dat'
WITH
(
BATCHSIZE = 103000
)
-- show rowgroups
select * from sys.column_store_row_groups where object_id = object_id('t_bulkload')

The output below shows that there are two row groups created. . First row group with row_group_id=0 is ‘compressed’ with 103000 rows. This is because the batchsize >= 102400, the SQL Server will directly compress this row group. This is a useful because Bulk Load is a common scenario to load the data into a Data Warehouse. With directly compressing the rows, SQL Server can minimize logging (details https://blogs.msdn.com/b/sqlserverstorageengine/archive/2016/01/11/clustered-columnstore-index-data-load-optimizations-minimal-logging.aspx ) as the rows do not go through delta row group. Also, there is no need for tuple mover to move the data. The second batch had only 7000 row because we ran out of rows in the data file (remember, we the data file had only 110000 rows) and this set of rows are inserted into delta row group ‘1’. Note, that the row group is still marked ‘OPEN’ meaning that it is not closed. It will eventually get closed and eventually compressed by the background ‘tuple mover’ when the number of rows hit 1 million row mark.
Let us now look at the locks. Here is the output. Note that for we have X lock on both the delta row group and compressed row group. Taking lock at row group level minimizes the locking overhead.
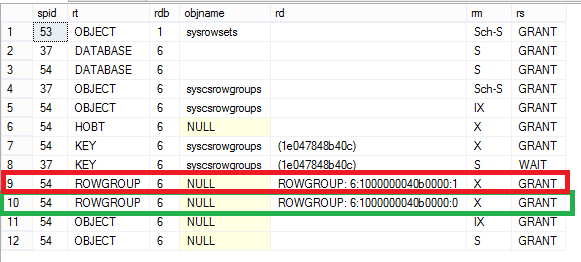
You may wonder what will happen if we insert a row from another session. Let us just do that
begin tran
insert into t_bulkload values (-1, 'single row', 'single row', -1)
Now let us look the row groups. You will note that the new row actually was inserted into new delta row group as hi-lighted below because the Bulk Insert transaction holds an X lock on row group = 1. SQL Server allows the INSERT operation to succeed instead of blocking it because INSERT is a common operation for DW therefore maximum concurrency is needed. The down side is that now you have two open delta row groups. The future inserts can go into any of these row groups so in the worst case you may have 2 million rows in the delta row groups before they get compressed. This will impact the DW query performance because part of the query accessing rows from delta row group is not as efficient.

Hope this blog clarifies how data is bulk imported into clustered columnstore index. In most case, there are no issues if you are loading large amount of data. In the worst case, I expect the number of delta row groups will be same as degree of concurrency for Bulk Import Operations.
Thanks
Sunil Agarwal
Comments
Anonymous
July 30, 2014
thanksAnonymous
August 27, 2014
I am little confuse. You mentioned that . . First row group with row_group_id=0 is ‘compressed’ with 103000 rows. This is because the batchsize >= 102400. The second batch had only 7000 row because we ran out of rows in the data file (remember, we the data file had only 110000 rows) and this set of rows are inserted into delta row group ‘1’. Note, that the row group is still marked ‘OPEN’ meaning that it is not closed. It will eventually get closed and eventually compressed by the background ‘tuple mover’ when the number of rows hit 1 million row mark. my question is batchsize >= 102400 gets compressed & doesn't have to wait to hit 1 million row mark. Whereas on other hand for rows 7000 it has to wait for 1 million row mark. Can you please share any underline working of it. Doing so is greatly appreciated. ThanksAnonymous
August 28, 2014
Jay: thanks for your question/interest Bulkload is dealt a bit differently. In our experiments, we found that we get decent compressions with 100K+ rows. We balanced that with explosion of row groups. So we settled for 1 million rows for a rowgroup. Now, in bulkload, the batchsize of 1 million may not be as common, so we lowered it to 100k. ANy batch >100K rows is directly compressed but for non-bulk load (i.e. trickle insert) we wait for 1 million rows. so in the example below, you will 893K more rows for it to compressAnonymous
October 21, 2014
Hello its really wonderful knowledgeable..Give more good things. we are providing these type of services tuo carro attrezzi Roma Opera nella ripartizione e ha la conoscenza del territorio e, rimorchio e rottamazione di veicoli in panne, veicoli incidentati o sequestrati. If you want to know more about this services please click here carroattrezzi.roma.it/soccorso-stradale-con-carroattrezzi-h24