Clustered columnstore Index: Data Load Optimization - Parallel Bulk Import
In the previous blog https://blogs.msdn.microsoft.com/sqlserverstorageengine/2016/01/10/clustered-columnstore-index-data-load-optimizations-minimal-logging/ , we looked at minimal-logging when bulk importing data into a table with clustered columnstore index. In this blog, we will look at parallel bulk import.
Recall that on rowstore tables (i.e. the tables organized as rows not as columnstore), SQL Server requires you to specify TABLOCK for parallel bulk import to get minimal logging and locking optimizations. One key difference for tables with clustered columnstore index is that you don’t need TABLOCK for getting locking/logging optimizations for bulk import. The reasons for this difference in behavior is that each bulk import thread can load data exclusively into a columnstore rowgroup. If the batch size < 102400, then the data is imported into a delta rowgroup otherwise a new compressed rowgroup is created and the data is loaded into it. Let us take two following interesting cases to show this bulk import behavior. Assume you are importing 4 data files, each with one bulk import thread, concurrently into a table with clustered columnstore index
- If the batchsize < 102400, each thread will create a new delta rowgroup and import the data. After the first batch for each thread, there will be 4 delta rowgroups. The next set of batches will use the existing delta rowgroup
- If the batchsize is = 102400, each thread will create a new compressed rowgroup with X lock and import the data into it with locking optimizations as well as with minimal logging. In this case, there will be 4 new compressed rowgroups. The next batch will create 4 additional compressed rowgroups. You may wonder why did we not use existing compressed rowgroup? Well the reason is that once a rowgroup is compressed, it is marked read-only. If you want larger number of rows in each of the compressed rowgroups, you can either choose a much larger batchsize (e.g. 1048576) or run ALTER INDEX REORGANIZE to merge these smaller compressed rowgroups.
Let us now look at three examples with bulk import with the focus on locking behavior as this will determine if we can bulk import in parallel or not.
begin tran
-- this loads the data in 1 batch
bulk insert t_bulkload
FROM 'c:\temp\t_bulkoad-1.dat'
Example-1: Assume data file has 110000 rows (i.e. > 102400), the data will be directly imported into a compressed rowgroup 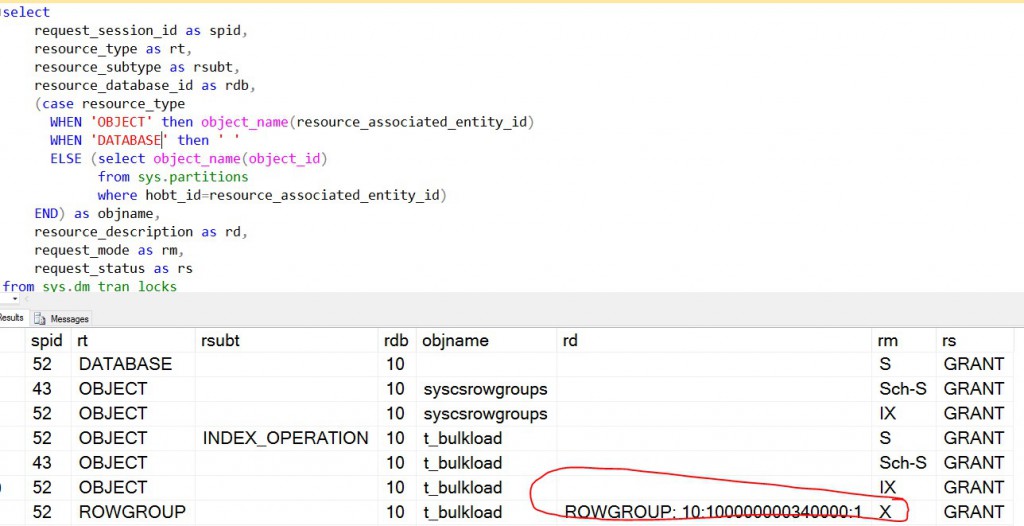
Example-2: Load the data same as in example-1 but use TABLOCK as follows. Key thing to note here is that this bulk import gets X lock on the table which means all other concurrent bulk import threads will get blocked! Unlike rowstore where TABLOCK hints leads to BU lock which allows parallel bulk import threads, there is no such lock supported or needed for clustered columnstore index.
begin tran
bulk insert t_bulkload
FROM 'c:\temp\t_bulkoad-1.dat'
WITH (TABLOCK)

Example-3: If the data file has 10000 rows (i.e. < 102400), the data will be directly imported into a compressed rowgroup. After the bulk import, you see one delta rowgroup with 10000 rows 
Here are the locks. Note, that it gets X lock on PAGE(s) and EXTENT(s) as well. Given that X lock delta rowgroups was acquired, there is actually no need to have locks on PAGE/EXTENT. We will look into this in future as the recommended case is to load the data directly into compressed rowgroup 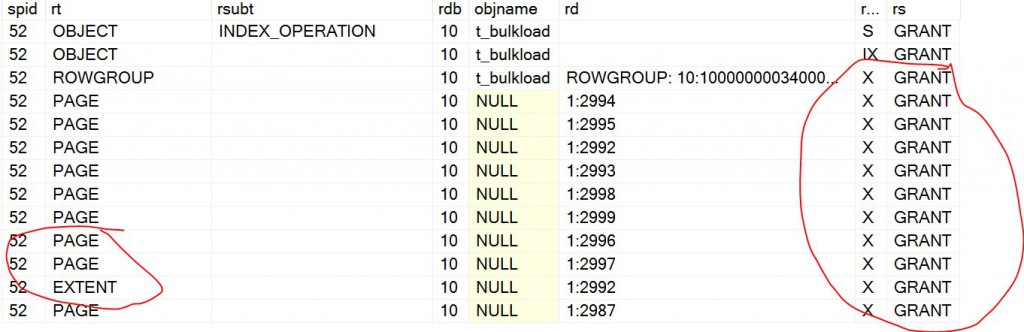
In summary, when bulk importing data into clustered columnstore index, choose a batchsize > 102400 and donot use TABLOCK hint
Happy Bulk Loading
Thanks
Sunil
Comments
- Anonymous
February 29, 2016
I believe the batch size limit which determines if data is placed in delta store or creates a new RowGroup is 102400. Near the beginning of the article it's written as 10240 instead.- Anonymous
March 01, 2016
correct! I fixed it thanks!!
- Anonymous
- Anonymous
April 18, 2016
Hi,When using SSIS what's the best config? setting up a batch size of 0? 102400? Today with SQL 2012 and no clustered columnstore indexes, I'm using values between 10 000 and 100 000 rows in the configuration of my destination. but not sure if this is still good or if I have to plan to change it when upgrading to 2016.