Strategie per lo sviluppo e la distribuzione del database (VB)
Quando si distribuisce un'applicazione guidata dai dati per la prima volta, è possibile copiare il database in modo cieco nell'ambiente di sviluppo nell'ambiente di produzione. Tuttavia, l'esecuzione di una copia non cieco nelle distribuzioni successive sovrascriverà tutti i dati immessi nel database di produzione. La distribuzione di un database comporta invece l'applicazione delle modifiche apportate al database di sviluppo dall'ultima distribuzione nel database di produzione. Questa esercitazione esamina queste sfide e offre diverse strategie per facilitare la croniciatura e l'applicazione delle modifiche apportate al database dall'ultima distribuzione.
Introduzione
Come illustrato nelle esercitazioni precedenti, la distribuzione di un'applicazione ASP.NET comporta la copia del contenuto pertinente dall'ambiente di sviluppo all'ambiente di produzione. La distribuzione non è un evento una tantum, ma piuttosto qualcosa che accade ogni volta che viene rilasciata una nuova versione del software o quando sono stati identificati e risolti bug o problemi di sicurezza. Quando si copiano pagine ASP.NET, immagini, file JavaScript e altri file di questo tipo nell'ambiente di produzione, non è necessario preoccuparsi del modo in cui questi file sono stati modificati dall'ultima distribuzione. È possibile copiare in modo cieco il file nell'ambiente di produzione, sovrascrivendo il contenuto esistente. Sfortunatamente, questa semplicità non si estende alla distribuzione del database.
Quando si distribuisce un'applicazione guidata dai dati per la prima volta, è possibile copiare il database in modo cieco nell'ambiente di sviluppo nell'ambiente di produzione. Tuttavia, l'esecuzione di una copia non cieco nelle distribuzioni successive sovrascriverà tutti i dati immessi nel database di produzione. La distribuzione di un database comporta invece l'applicazione delle modifiche apportate al database di sviluppo dall'ultima distribuzione nel database di produzione. Questa esercitazione esamina queste sfide e offre diverse strategie per facilitare la croniciatura e l'applicazione delle modifiche apportate al database dall'ultima distribuzione.
Problemi di distribuzione di un database
Prima che un'applicazione guidata dai dati sia stata distribuita per la prima volta, è presente un solo database, ovvero il database nell'ambiente di sviluppo, motivo per cui quando si distribuisce un'applicazione guidata dai dati per la prima volta è possibile copiare il database nell'ambiente di sviluppo nell'ambiente di produzione. Tuttavia, una volta distribuita l'applicazione, sono presenti due copie del database: una in fase di sviluppo e una nell'ambiente di produzione.
Tra le distribuzioni i database di sviluppo e di produzione possono diventare non sincronizzati. Anche se lo schema del database di produzione rimane invariato, lo schema del database di sviluppo può cambiare man mano che vengono aggiunte nuove funzionalità. È possibile aggiungere o rimuovere colonne, tabelle, viste o stored procedure. Potrebbero essere presenti anche dati importanti che vengono aggiunti al database di sviluppo. Molte applicazioni guidate dai dati includono tabelle di ricerca popolate con dati hardcoded specifici dell'applicazione che non sono modificabili dall'utente. Ad esempio, un sito Web dell'asta potrebbe avere un elenco a discesa con scelte che descrivono la condizione dell'elemento da mettere all'asta: Nuovo, Come Nuovo, Buono e Fiera. Anziché impostare come hardcoded queste opzioni direttamente nell'elenco a discesa, in genere è preferibile inserirle in una tabella di database. Se, durante lo sviluppo, alla tabella viene aggiunta una nuova condizione denominata Poor, quando si distribuisce l'applicazione lo stesso record deve essere aggiunta alla tabella di ricerca nel database di produzione.
Idealmente, la distribuzione del database comporta la copia del database dallo sviluppo all'ambiente di produzione. Tenere tuttavia presente che dopo aver distribuito l'applicazione e aver ripreso lo sviluppo, il database di produzione viene popolato con dati reali provenienti da utenti reali. Pertanto, se si dovesse semplicemente copiare il database dallo sviluppo all'ambiente di produzione alla successiva distribuzione, si sovrascriverà il database di produzione e si perderanno i dati esistenti. Il risultato netto è che la distribuzione del database si riduce all'applicazione delle modifiche apportate al database di sviluppo dall'ultima distribuzione.
Poiché la distribuzione di un database comporta l'applicazione delle modifiche nello schema e, possibilmente, i dati dall'ultima distribuzione, è necessario mantenere una cronologia delle modifiche (o determinare in fase di distribuzione) in modo che tali modifiche possano essere applicate all'ambiente di produzione. Esistono diverse tecniche per la gestione e l'applicazione delle modifiche al modello di dati.
Definizione della baseline
Per mantenere le modifiche apportate al database dell'applicazione, è necessario avere uno stato iniziale, una linea di base a cui vengono applicate le modifiche. Uno stato iniziale estremo potrebbe essere un database vuoto senza tabelle, viste o stored procedure. Una baseline di questo tipo genera un log delle modifiche di grandi dimensioni perché deve includere la creazione di tutte le tabelle, le viste e le stored procedure del database insieme alle eventuali modifiche apportate dopo la distribuzione iniziale. All'altra estremità dello spettro è possibile impostare la baseline come versione del database distribuita inizialmente nell'ambiente di produzione. Questa scelta comporta un log delle modifiche molto più piccolo perché include solo le modifiche apportate al database dopo la prima distribuzione. Questo è l'approccio che preferisco. E naturalmente è possibile scegliere un approccio più intermedio della strada, definendo la baseline come un punto tra la creazione iniziale del database e quando il database viene distribuito per la prima volta.
Dopo aver scelto una baseline, è consigliabile generare uno script SQL che può essere eseguito per ricreare la versione di base. Questo script consente di ricreare rapidamente la versione di base del database. Questa funzionalità è particolarmente utile nei progetti di grandi dimensioni, in cui possono essere presenti più sviluppatori che lavorano sul progetto o su altri ambienti, ad esempio test o gestione temporanea, che hanno bisogno della propria copia del database.
È disponibile un'ampia gamma di strumenti per generare uno script SQL della versione di base. Da SQL Server Management Studio (SSMS) è possibile fare clic con il pulsante destro del mouse sul database, passare al sottomenu Attività e scegliere l'opzione Genera script. Verrà avviata la Creazione guidata script, che è possibile indicare di generare un file contenente i comandi SQL per creare gli oggetti del database. Un'altra opzione è la Pubblicazione guidata database, che può generare i comandi SQL per creare non solo lo schema del database, ma anche i dati nelle tabelle di database. La Pubblicazione guidata database è stata esaminata in dettaglio nell'esercitazione Distribuzione di un database . Indipendentemente dallo strumento usato, alla fine dovrebbe essere presente un file di script che è possibile usare per ricreare la versione di base del database, se necessario.
Documentazione delle modifiche del database in prosa
Il modo più semplice per gestire un log delle modifiche apportate al modello di dati durante la fase di sviluppo consiste nel registrare le modifiche nella prosa. Ad esempio, se durante lo sviluppo di un'applicazione già distribuita si aggiunge una nuova colonna alla Employees tabella, si rimuove una colonna dalla Orders tabella e si aggiunge una nuova tabella (ProductCategories), si mantiene un file di testo o microsoft Word documento con la cronologia seguente:
| Data di modifica | Modifica dettagli |
|---|---|
| 2009-02-03: | Aggiunta della colonna DepartmentID (int, NOT NULL) alla Employees tabella. Aggiunta di un vincolo di chiave esterna da Departments.DepartmentID a Employees.DepartmentID. |
| 2009-02-05: | Colonna rimossa TotalWeight dalla Orders tabella. Dati già acquisiti nei record associati OrderDetails . |
| 2009-02-12: | Creazione della ProductCategories tabella. Sono disponibili tre colonne: ProductCategoryID (int, IDENTITY, NOT NULL), CategoryName (nvarchar(50), NOT NULL) e Active (bit, NOT NULL). Aggiunto un vincolo di chiave primaria a ProductCategoryIDe un valore predefinito pari a 1 a Active. |
Questo approccio presenta alcuni svantaggi. Per iniziare, non c'è speranza per l'automazione. Ogni volta che queste modifiche devono essere applicate a un database, ad esempio quando l'applicazione viene distribuita, uno sviluppatore deve implementare manualmente ogni modifica, una alla volta. Inoltre, se è necessario ricostruire una determinata versione del database dalla baseline usando il log delle modifiche, questa operazione richiederà più tempo man mano che le dimensioni del log aumentano. Un altro svantaggio di questo metodo è che la chiarezza e il livello di dettaglio di ogni voce del log delle modifiche vengono lasciati alla persona che registra la modifica. In un team con più sviluppatori alcuni possono rendere più dettagliate, leggibili o più precise voci di altre. Inoltre, sono possibili errori di digitazioni e altri errori di immissione dei dati correlati all'uomo.
Il vantaggio principale della documentazione delle modifiche del database nella prosa è la semplicità. Non è necessaria familiarità con la sintassi SQL per la creazione e la modifica di oggetti di database. È invece possibile registrare le modifiche nella prosa e implementarle tramite SQL Server Management Studio'interfaccia utente grafica.
La gestione del log delle modifiche nel prosa è, ammesso, non molto sofisticata e non funziona bene con determinati progetti, ad esempio quelli di grandi dimensioni nell'ambito, hanno modifiche frequenti al modello di dati o coinvolgono più sviluppatori. Ma ho visto questo approccio funziona abbastanza bene in piccoli progetti one-man che hanno solo modifiche occasionali al modello di dati e in cui lo sviluppatore solo non ha uno sfondo forte nella sintassi SQL per la creazione e la modifica di oggetti di database.
Nota
Anche se le informazioni nel log delle modifiche sono tecnicamente necessarie solo fino alla fase di distribuzione, è consigliabile mantenere una cronologia delle modifiche. Invece di mantenere un singolo file di log delle modifiche in continua crescita, è consigliabile avere un file di log delle modifiche diverso per ogni versione del database. In genere si vuole modificare la versione del database ogni volta che viene distribuita. Mantenendo un log dei log delle modifiche è possibile, a partire dalla baseline, ricreare qualsiasi versione del database eseguendo gli script del log delle modifiche a partire dalla versione 1 e continuando fino a raggiungere la versione da ricreare.
Registrazione delle istruzioni di modifica SQL
Lo svantaggio principale della gestione del log delle modifiche nella prosa è la mancanza di automazione. Idealmente, l'implementazione delle modifiche al database di produzione in fase di distribuzione sarebbe semplice come fare clic su un pulsante per eseguire uno script invece di dover eseguire manualmente un elenco di istruzioni. Tale automazione è possibile mantenendo un log delle modifiche che contiene i comandi SQL usati per modificare il modello di dati.
La sintassi SQL include diverse istruzioni per la creazione e la modifica di vari oggetti di database. Ad esempio, l'istruzione CREATE TABLE, quando eseguita, crea una nuova tabella con le colonne e i vincoli specificati. L'istruzione ALTER TABLE modifica una tabella esistente, aggiungendo, rimuovendo o modificando le colonne o i vincoli. Sono inoltre disponibili istruzioni per creare, modificare ed eliminare indici, viste, funzioni definite dall'utente, stored procedure, trigger e altri oggetti di database.
Tornare all'esempio precedente, immagine che durante lo sviluppo di un'applicazione già distribuita si aggiunge una nuova colonna alla Employees tabella, si rimuove una colonna dalla Orders tabella e si aggiunge una nuova tabella (ProductCategories). Tali azioni generano un file di log delle modifiche con i comandi SQL seguenti:
-- Add the DepartmentID column
ALTER TABLE [Employees] ADD [DepartmentID]
int NOT NULL
-- Add a foreign key constraint between Departments.DepartmentID and Employees.DepartmentID
ALTER TABLE [Employees] ADD
CONSTRAINT [FK_Departments_DepartmentID]
FOREIGN
KEY ([DepartmentID])
REFERENCES
[Departments] ([DepartmentID])
-- Remove TotalWeight column from Orders
ALTER TABLE [Orders] DROP COLUMN
[TotalWeight]
-- Create the ProductCategories table
CREATE TABLE [ProductCategories]
(
[ProductCategoryID]
int IDENTITY(1,1) NOT NULL,
[CategoryName]
nvarchar(50) NOT NULL,
[Active]
bit NOT NULL CONSTRAINT [DF_ProductCategories_Active] DEFAULT
((1)),
CONSTRAINT
[PK_ProductCategories] PRIMARY KEY CLUSTERED ( [ProductCategoryID])
)
Il push di queste modifiche al database di produzione in fase di distribuzione è un'operazione con un clic: aprire SQL Server Management Studio, connettersi al database di produzione, aprire una finestra Nuova query, incollare il contenuto del log delle modifiche e fare clic su Esegui per eseguire lo script.
Uso di uno strumento di confronto per sincronizzare i modelli di dati
Documentare le modifiche apportate al database in prosa è semplice, ma l'implementazione delle modifiche richiede a uno sviluppatore di apportare ogni modifica al database di produzione uno alla volta; documentando i comandi di modifica SQL, l'implementazione di tali modifiche nel database di produzione risulta semplice e veloce quando si fa clic su un pulsante, ma richiede l'apprendimento e la gestione delle istruzioni SQL e della sintassi per la creazione e la modifica di oggetti di database. Gli strumenti di confronto dei database sfruttano al meglio entrambi gli approcci e ignorano il peggio.
Uno strumento di confronto di database confronta lo schema o i dati di due database e visualizza un report di riepilogo che mostra le differenze tra i database. Quindi, con il clic di un pulsante, è possibile generare i comandi SQL per la sincronizzazione di uno o più oggetti di database. In breve, è possibile usare uno strumento di confronto di database per confrontare i database di sviluppo e di produzione in fase di distribuzione, generando un file contenente i comandi SQL che, in fase di esecuzione, applicheranno le modifiche allo schema del database di produzione in modo che rispecchi lo schema del database di sviluppo.
Sono disponibili numerosi strumenti di confronto di database di terze parti offerti da molti fornitori diversi. Uno di questi esempi è Confronto SQL, di Red Gate Software. È possibile esaminare il processo di utilizzo di SQL Compare per confrontare e sincronizzare gli schemi dei database di sviluppo e produzione.
Nota
Al momento della stesura di questo articolo la versione corrente di SQL Compare era la versione 7.1, con l'edizione Standard che costava $395. È possibile seguire la procedura scaricando una versione di valutazione gratuita di 14 giorni.
Quando SQL Compare avvia la finestra di dialogo Progetti di confronto, che mostra i progetti DI confronto SQL salvati. Creare un nuovo progetto. Verrà avviata la Configurazione guidata progetto, che richiede informazioni sui database da confrontare (vedere la figura 1). Immettere le informazioni per i database dell'ambiente di sviluppo e di produzione.

Figura 1: Confrontare i database di sviluppo e produzione (fare clic per visualizzare l'immagine a dimensione intera)
{kind=link}
Nota
Se il database dell'ambiente di sviluppo è un file di database SQL Express Edition nella App_Data cartella del sito Web, sarà necessario registrare il database nel server di database SQL Server Express per selezionarlo dalla finestra di dialogo illustrata nella figura 1. Il modo più semplice per eseguire questa operazione consiste nell'aprire SQL Server Management Studio (SSMS), connettersi al server di database SQL Server Express e collegare il database. Se SSMS non è installato nel computer, è possibile scaricare e installare il SQL Server Management Studio gratuito.
Oltre a selezionare i database da confrontare, è anche possibile specificare un'ampia gamma di impostazioni di confronto nella scheda Opzioni. Un'opzione che può essere utile attivare è "Ignora vincoli e nomi di indice". Tenere presente che nell'esercitazione precedente sono stati aggiunti gli oggetti di database dei servizi applicazione ai database di sviluppo e produzione. Se è stato usato lo aspnet_regsql.exe strumento per creare questi oggetti nel database di produzione, si scoprirà che la chiave primaria e i nomi dei vincoli univoci differiscono tra i database di sviluppo e di produzione. Di conseguenza, SQL Compare contrassegnerà tutte le tabelle dei servizi dell'applicazione come diverse. È possibile lasciare deselezionato l'opzione "Ignora vincoli e nomi di indice" e sincronizzare i nomi dei vincoli oppure indicare a SQL Compare di ignorare queste differenze.
Dopo aver selezionato i database da confrontare e aver esaminato le opzioni di confronto, fare clic sul pulsante Confronta ora per avviare il confronto. Nel corso dei successivi secondi, SQL Compare esamina gli schemi dei due database e genera un report sulle differenze. Sono state apportate alcune modifiche al database di sviluppo per mostrare in che modo tali discrepanze sono indicate nell'interfaccia di confronto SQL. Come illustrato nella Books figura 2, ho aggiunto una BirthDate colonna alla Authors tabella, rimosso la ISBN colonna dalla tabella e aggiunto una nuova tabella, Ratings, che è destinata a consentire agli utenti di visitare il sito valutano i libri esaminati.
Nota
Le modifiche apportate al modello di dati in questa esercitazione sono state eseguite per illustrare l'uso di uno strumento di confronto del database. Queste modifiche non verranno trovate nel database nelle esercitazioni future.
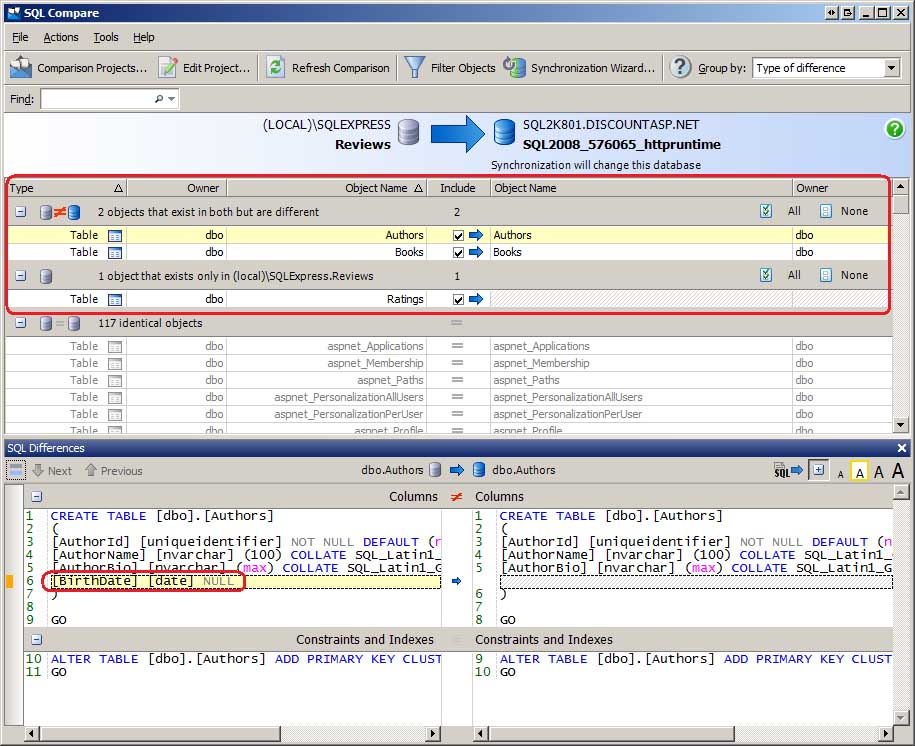
Figura 2: Confronto SQL Elenchi differenze tra i database di sviluppo e produzione (fare clic per visualizzare l'immagine a dimensione intera)
{kind=link}
Confronto SQL suddivide gli oggetti di database in gruppi, mostrando rapidamente quali oggetti esistono in entrambi i database, ma sono diversi, quali oggetti esistono in un database ma non in un altro e quali oggetti sono identici. Come si può notare, esistono due oggetti presenti in entrambi i database, ma sono diversi: la Authors tabella, che include una colonna aggiunta, e la Books tabella, che ne aveva una rimossa. Esiste un oggetto che esiste solo nel database di sviluppo, vale a dire la tabella appena creata Ratings . Sono inoltre presenti 117 oggetti identici in entrambi i database.
Se si seleziona un oggetto di database viene visualizzata la finestra Differenze SQL, che mostra le differenze tra questi oggetti. La finestra Differenze SQL, visualizzata nella parte inferiore della figura 2, evidenzia che la Authors tabella nel database di sviluppo contiene la BirthDate colonna , che non viene trovata nella Authors tabella nel database di produzione.
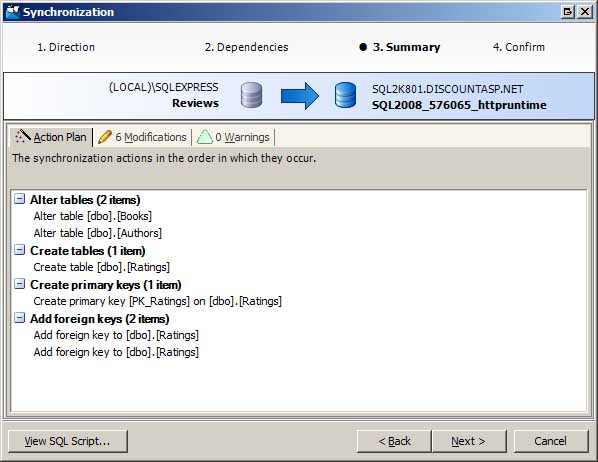
Dopo aver esaminato le differenze e aver selezionato gli oggetti da sincronizzare, il passaggio successivo consiste nel generare i comandi SQL necessari per aggiornare lo schema del database di produzione in modo che corrisponda al database di sviluppo. Questa operazione viene eseguita tramite la Sincronizzazione guidata. La Sincronizzazione guidata conferma gli oggetti da sincronizzare e riepiloga il piano di azione (vedere la figura 3). È possibile sincronizzare immediatamente i database o generare uno script con i comandi SQL che possono essere eseguiti nel tempo libero.
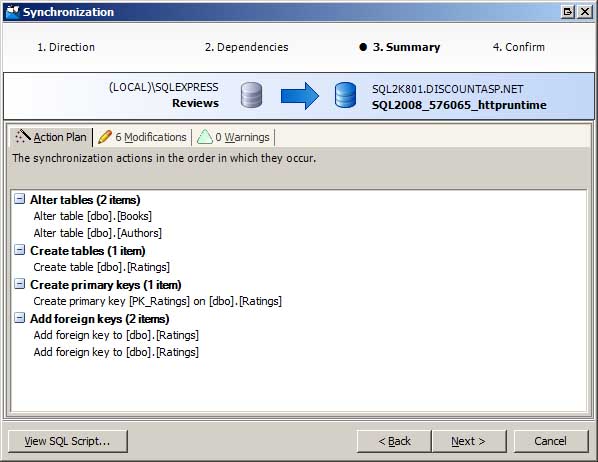
Figura 3: Usare la sincronizzazione guidata per sincronizzare gli schemi dei database (fare clic per visualizzare l'immagine a dimensione intera)
{kind=link}
Gli strumenti di confronto dei database, ad esempio il confronto SQL di Red Gate Software, applicano le modifiche allo schema del database di sviluppo al database di produzione con facilità e facendo clic.
Nota
Sql Compare confronta e sincronizza due schemi di database. Sfortunatamente, non confronta e sincronizza i dati all'interno di due tabelle di database. Red Gate Software offre un prodotto denominato SQL Data Compare che confronta e sincronizza i dati tra due database, ma è un prodotto separato da SQL Compare e costa un altro $395.
Portare l'applicazione offline durante la distribuzione
Come abbiamo visto in queste esercitazioni, la distribuzione è un processo che prevede più passaggi: copiare le pagine ASP.NET, le pagine master, i file CSS, i file JavaScript, le immagini e altri contenuti necessari dall'ambiente di sviluppo all'ambiente di produzione; copia delle informazioni di configurazione specifiche dell'ambiente di produzione, se necessario; e applicando le modifiche apportate al modello di dati dall'ultima distribuzione. A seconda del numero di file e della complessità delle modifiche apportate al database, il completamento di questi passaggi può richiedere da pochi secondi a diversi minuti. Durante questa finestra l'applicazione Web è in flusso e gli utenti che visitano il sito potrebbero riscontrare errori o comportamenti imprevisti.
Quando si distribuisce un sito Web, è consigliabile portare l'applicazione Web "offline" fino al completamento della distribuzione. Portare l'applicazione offline (e riportare il backup al termine del processo di distribuzione) è altrettanto semplice quanto caricare un file e quindi eliminarlo. A partire da ASP.NET 2.0, la semplice presenza di un file denominato app_offline.htm nella directory radice dell'applicazione porta l'intero sito Web "offline". Qualsiasi richiesta a una pagina di ASP.NET in tale sito viene automaticamente restituita con il contenuto del app_offline.htm file. Una volta rimosso il file, l'applicazione torna online.
Portare un'applicazione offline durante la distribuzione, quindi, è semplice come caricare un app_offline.htm file nella directory radice dell'ambiente di produzione prima di iniziare il processo di distribuzione e quindi eliminarlo (o rinominarlo in un altro elemento) al termine della distribuzione. Per altre informazioni su questa tecnica, vedere l'articolo di John Peterson, Acquisizione di un'applicazione ASP.NET offline.
Riepilogo
La sfida principale nella distribuzione di un'applicazione basata sui dati è incentrata sulla distribuzione del database. Poiché sono disponibili due versioni del database, una nell'ambiente di sviluppo e una nell'ambiente di produzione, questi due schemi di database possono diventare non sincronizzati man mano che vengono aggiunte nuove funzionalità nello sviluppo. Inoltre, poiché il database di produzione viene popolato con dati reali provenienti da utenti reali, non è possibile sovrascrivere il database di produzione con il database di sviluppo modificato, come è possibile distribuire i file che costituiscono l'applicazione (le pagine ASP.NET, i file di immagine e così via). La distribuzione di un database comporta invece l'implementazione del set preciso di modifiche apportate al database di sviluppo nel database di produzione dall'ultima distribuzione.
Questa esercitazione ha esaminato tre tecniche per la gestione e l'applicazione di un log delle modifiche al database. L'approccio più semplice consiste nel registrare le modifiche apportate alla prosa. Anche se questa tattica rende l'implementazione di queste modifiche nel database di produzione un processo manuale, non richiede la conoscenza dei comandi SQL per la creazione e la modifica di oggetti di database. Un approccio più sofisticato e uno molto più appetibile in progetti o progetti di grandi dimensioni con più sviluppatori consiste nel registrare le modifiche come una serie di comandi SQL. Questa operazione aumenta notevolmente l'implementazione di queste modifiche al database di destinazione. Il meglio di entrambi gli approcci può essere ottenuto usando uno strumento di confronto di database, ad esempio Il confronto SQL di Red Gate Software.
Questa esercitazione conclude l'attenzione sulla distribuzione di un'applicazione guidata dai dati. Il set successivo di esercitazioni illustra come rispondere agli errori nell'ambiente di produzione. Si esaminerà come visualizzare una pagina di errore descrittiva piuttosto che la schermata gialla della morte. Verrà inoltre illustrato come registrare i dettagli dell'errore e come avvisare l'utente quando si verificano tali errori.
Buon programmatori!