Generazione del recupero augmentata con Informazioni sui documenti di Azure AI
Questo contenuto si applica a: ![]() v4.0 (GA)
v4.0 (GA)
Introduzione
Generazione del recupero augmentata (RAG) è un schema progettuale che combina un modello linguistico di grandi dimensioni (LLM) con training preliminare come ChatGPT con un sistema di recupero dati esterno per generare una risposta avanzata che incorpora nuovi dati al di fuori dei dati di training originali. L’aggiunta di un sistema di recupero delle informazioni alle applicazioni consente di chattare con i documenti, generare contenuti accattivanti e accedere alla potenza dei modelli Azure OpenAI per i dati. Si dispone anche un maggiore controllo sui dati usati dal LLM durante la formulazione di una risposta.
Il modello di layout di Intelligence sui documenti è un’API avanzata di analisi dei documenti basata sull’apprendimento automatico. Il modello di layout offre una soluzione completa per estrazione di contenuti avanzata e funzionalità di analisi della struttura dei documenti. Con il modello di layout, è possibile estrarre facilmente testo ed elementi strutturali per dividere grandi corpi di testo in blocchi più piccoli e significativi in base al contenuto semantico anziché a divisioni arbitrarie. Le informazioni estratte possono essere facilmente restituite in formato Markdown, consentendo di definire la strategia di suddivisione in blocchi semantici in base a blocchi predefiniti forniti.
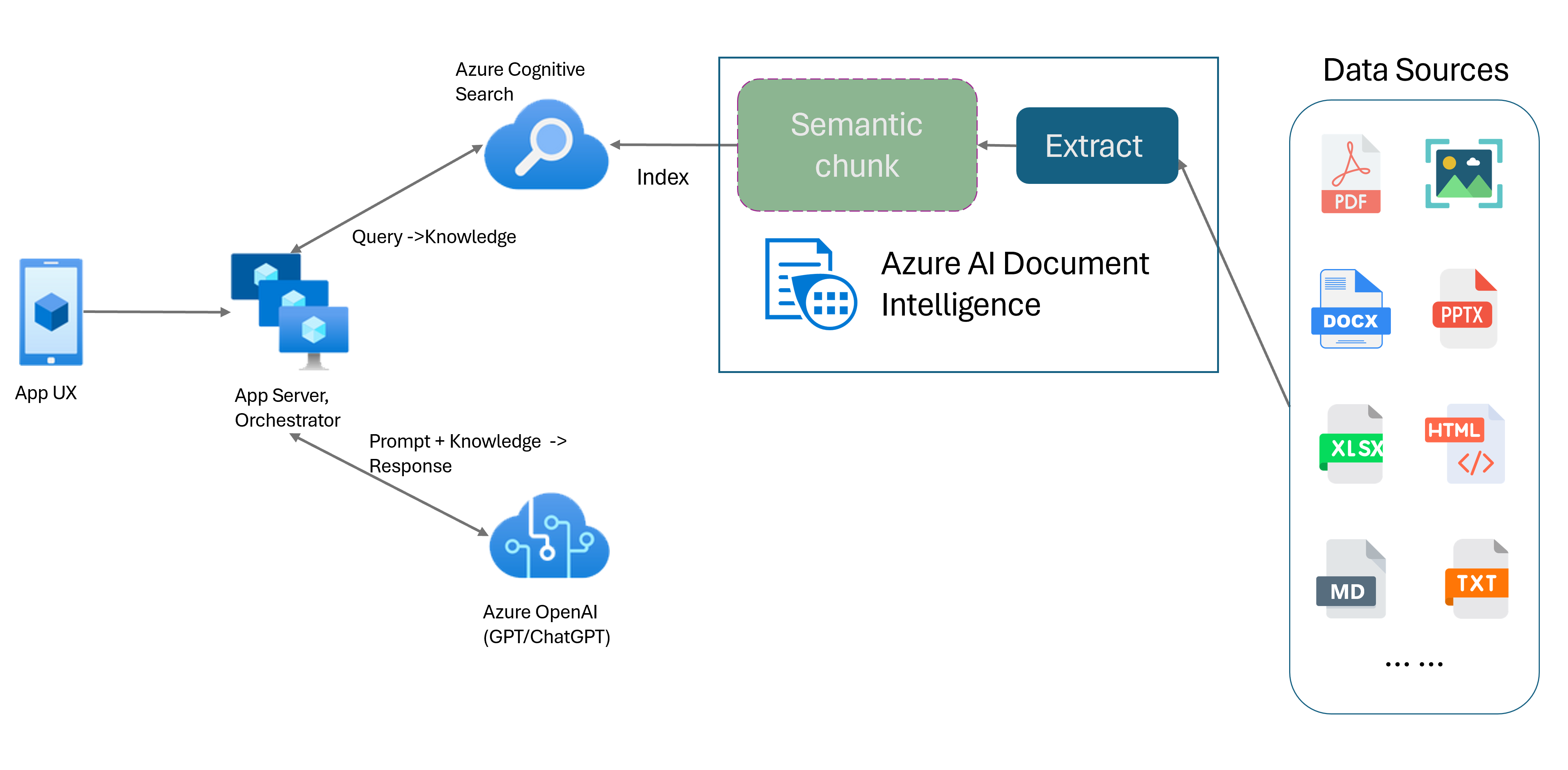
Suddivisione in blocchi semantici
Le frasi lunghe sono complesse per le applicazioni di elaborazione del linguaggio naturale (NLP). In particolare quando sono costituite da più frasi, gruppi nominali e sintagmi verbali complessi, preposizioni relative e raggruppamenti tra parentesi. Proprio come gli ascoltatori umani, un sistema NLP deve anche tenere traccia di tutte le dipendenze presentate. L’obiettivo della suddivisione in blocchi semantici è trovare frammenti semanticamente coerenti di una rappresentazione di frase. Questi frammenti possono quindi essere elaborati in modo indipendente e ricombinati come rappresentazioni semantiche senza perdita di informazioni, interpretazione o rilevanza semantica. Il significato intrinseco del testo viene usato come guida per il processo di suddivisione in blocchi.
Le strategie di suddivisione in blocchi dei dati di testo svolgono un ruolo fondamentale nell’ottimizzazione della risposta e delle prestazioni di generazione del recupero augmentata (RAG). Le dimensioni fisse e la semantica sono due metodi distinti di suddivisione in blocchi:
Suddivisione in blocchi secondo dimensioni fisse. La maggior parte delle strategie di suddivisione in blocchi usate in generazione del recupero augmentata (RAG) oggi si basa su segmenti di testo con dimensioni fisse note come blocchi. La suddivisione in blocchi secondo dimensioni fisse è rapida, semplice ed efficace con testo che non ha una struttura semantica avanzata, ad esempio log e dati. Tuttavia, non è consigliabile per il testo che richiede una comprensione semantica e un contesto preciso. La natura delle dimensioni fisse della finestra può comportare il troncamento di parole, frasi o paragrafi che impediscono la comprensione e interrompono il flusso di informazioni e la comprensione.
Suddivisione in blocchi semantici. Questo metodo divide il testo in blocchi in base alla comprensione semantica. I limiti di divisione sono incentrati sull’oggetto frase e usano risorse complesse di calcolo e algoritmiche significative. Tuttavia, questo metodo ha il vantaggio distinto di mantenere la coerenza semantica all’interno di ogni blocco. È utile per le attività di riepilogo testi, analisi del sentiment e classificazione dei documenti.
Suddivisione in blocchi semantici con il modello di layout di Intelligence sui documenti
Markdown è un linguaggio di markup strutturato e formattato e un input diffuso per abilitare la suddivisione in blocchi semantici secondo la generazione del recupero augmentata (RAG). È possibile usare il contenuto Markdown del modello di layout per suddividere documenti in base ai limiti dei paragrafi, creare blocchi specifici per le tabelle e ottimizzare la strategia di suddivisione in blocchi per migliorare la qualità delle risposte generate.
Vantaggi dell’uso del modello di layout
Elaborazione semplificata. È possibile analizzare diversi tipi di documenti, ad esempio PDF digitali e analizzati, immagini, file di office (docx, xlsx, pptx) e HTML, con una singola chiamata API.
Qualità di scalabilità e intelligenza artificiale. Il modello di layout è altamente scalabile in riconoscimento ottico dei caratteri (OCR), estrazione di tabelle e analisi della struttura dei documenti. Supporta 309 lingue stampate e 12 lingue scritte a mano, garantendo risultati di alta qualità basati sulle funzionalità di intelligenza artificiale.
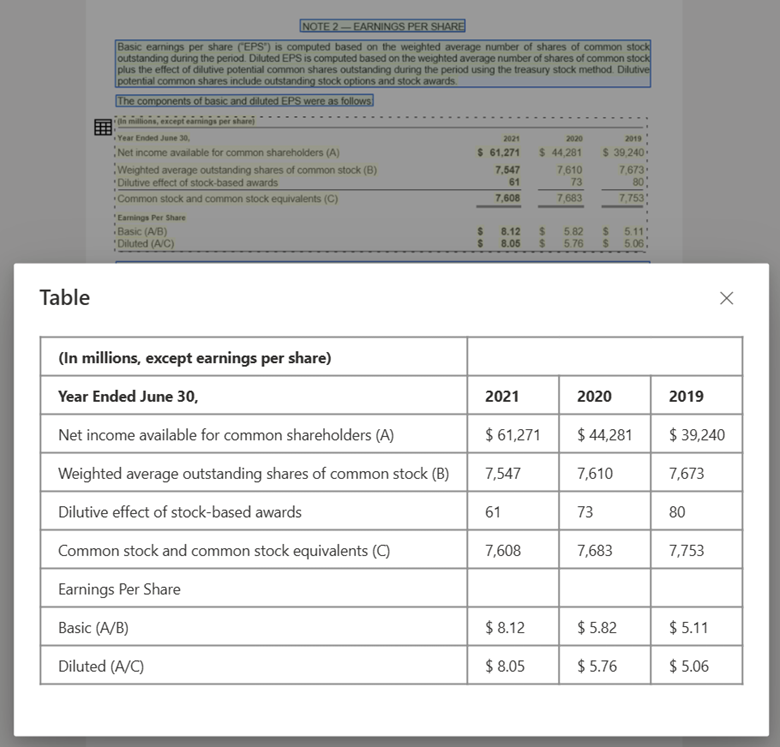
Compatibilità LLM (modello linguistico di grandi dimensioni). L’output formattato in Markdown del modello di layout è semplice e facilita l’integrazione nei flussi di lavoro. È possibile trasformare qualsiasi tabella in un documento in formato Markdown ed evitare un lavoro di analisi approfondita dei documenti per una maggiore comprensione LLM.
Immagine di testo elaborata con Document Intelligence Studio e output in Markdown usando il modello di layout

Immagine della tabella elaborata con Document Intelligence Studio usando il modello di layout
Operazioni preliminari
Il modello Document Intelligence Layout 2024-11-30 (GA) supporta le opzioni di sviluppo seguenti:
Pronti per iniziare?
Document Intelligence Studio
Per iniziare, è possibile seguire l’avvio rapido di Document Intelligence Studio. È quindi possibile integrare le funzionalità di Intelligence sui documenti con la propria applicazione usando il codice di esempio fornito.
Iniziare con il modello di layout. È necessario selezionare le opzioni di analisi seguenti per usare la generazione del recupero augmentata (RAG) in studio:
**Required**- Eseguire l’intervallo di analisi → Documento corrente.
- Intervallo di pagine → Tutte le pagine.
- Stile del formato di output → Markdown.
**Optional**- È anche possibile selezionare i parametri di rilevamento facoltativi pertinenti.
Seleziona Salva.
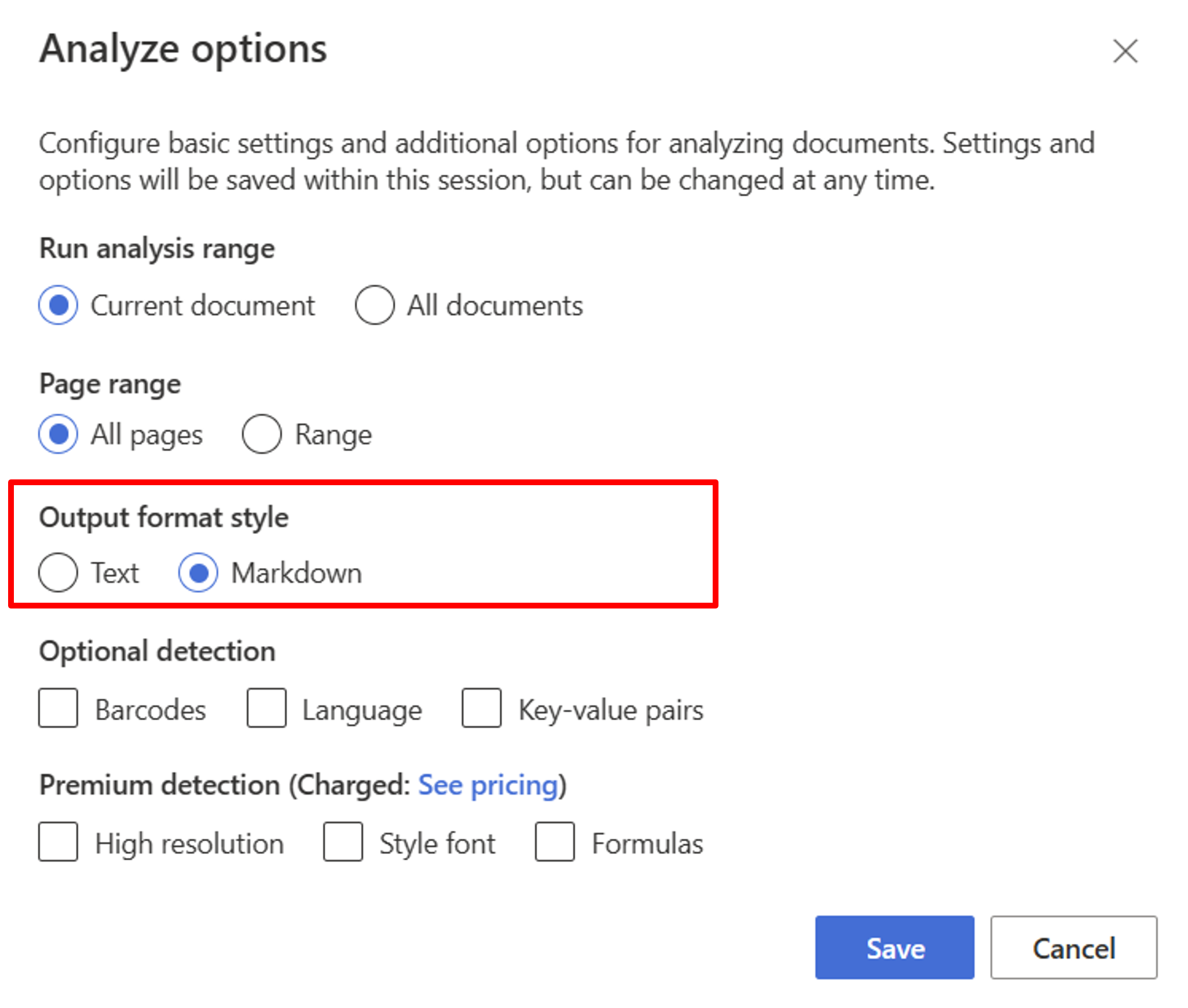
Selezionare il pulsante Esegui analisi per visualizzare l’output.

SDK o API REST
È possibile seguire l’avvio rapido di Intelligence sui documenti per l’SDK del linguaggio di programmazione preferito o l’API REST. Usare il modello di layout per estrarre contenuti e struttura dai documenti.
È anche possibile consultare i repository GitHub per esempi di codice e suggerimenti per l’analisi di un documento in formato di output Markdown.
Creare chat di documenti con suddivisione in blocchi semantici
Azure OpenAI sui dati consente di eseguire chat supportate nei documenti. Azure OpenAI sui dati applica il modello di layout di Intelligence sui documenti per estrarre e analizzare i dati dei documenti suddividendo in blocchi un testo lungo in base a tabelle e paragrafi. È anche possibile personalizzare la strategia di suddivisione in blocchi usando script di esempio di Azure OpenAI disponibili nel repository GitHub.
Informazioni sui documenti di Azure AI è ora integrato con LangChain come uno dei relativi caricatori di documenti. È possibile usarlo per caricare facilmente i dati e l’output in formato Markdown. Per altre informazioni, vedere il codice di esempio che mostra una semplice demo per il modello di generazione del recupero augmentata (RAG) con Informazioni sui documenti di Azure AI come caricatore di documenti e Ricerca di Azure come funzione di recupero in LangChain.
La chat con l’acceleratore di soluzioni dati di esempio di codice illustra un esempio di modello di generazione del recupero augmentata di base end-to-end. Usa Azure AI Search come funzione di recupero e Informazioni sui documenti di Azure AI per il caricamento di documenti e la suddivisione in blocchi semantici.
Caso d'uso
Se si sta cercando una sezione specifica in un documento, è possibile usare la suddivisione in blocchi semantici per dividere il documento in blocchi più piccoli in base alle intestazioni di sezione che consentono di trovare la sezione che si sta cercando in modo rapido e semplice:
# Using SDK targeting 2024-11-30 (GA), make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Passaggi successivi
Altre informazioni su Informazioni sui documenti di Azure AI.
Informazioni su come elaborare moduli e documenti personalizzati con Document Intelligence Studio.
Completare un avvio rapido di Intelligence sui documenti e iniziare a creare un’app per l’elaborazione di documenti nel linguaggio di sviluppo preferito.