Modello di contratto di Document Intelligence
Questo contenuto si applica a:![]() v4.0 (GA) | Versione precedente:
v4.0 (GA) | Versione precedente:![]() v3.1 (GA) :::moniker-end
v3.1 (GA) :::moniker-end
Questo contenuto si applica a: ![]() v3.1 (GA) | Versione più recente:
v3.1 (GA) | Versione più recente: ![]() v4.0 (GA)
v4.0 (GA)
Il modello di contratto di Document Intelligence usa potenti funzionalità di riconoscimento ottico dei caratteri (OCR) per analizzare ed estrarre campi chiave e voci da un gruppo selezionato di entità contrattuali. I contratti possono essere di vari formati e qualità, tra cui immagini acquisite dal telefono, documenti digitalizzati e PDF digitali. L'API analizza il testo del documento, estrae le informazioni chiave, come le parti, la giurisdizione, l'ID contratto e il titolo. Restituisce quindi una rappresentazione di dati JSON strutturati. Il modello al momento supporta i formati di documenti in lingua inglese.
Elaborazione automatica dei contratti
L'elaborazione automatica dei contratti è il processo di estrazione dei campi chiave del contratto dai documenti. Il processo di analisi dei contratti è stato sempre eseguito manualmente e, di conseguenza, risulta molto dispendioso in termini di tempo. L'estrazione accurata dei dati chiave del contratto è in genere il primo e uno dei passaggi più critici del processo di automazione dei contratti.
Opzioni di sviluppo
Document Intelligence v4.0: 2024-11-30 (GA) supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di contratto | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-contract |
Document Intelligence v3. 1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di contratto | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-contract |
Document Intelligence v3.0 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di contratto | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-contract |
Requisiti di input
Formati di file supportati:
Modello PDF Immagine: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLettura ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento generale ✔ ✔ Predefinito ✔ ✔ Estrazione personalizzata ✔ ✔ Classificazione personalizzata ✔ ✔ ✔ Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
Provare l'estrazione dei dati dei documenti del contratto
Vedere in che modo i dati, incluse le informazioni sul cliente, i dettagli del fornitore e le voci, vengono estratti dai contratti. Sono necessarie le risorse seguenti:
Sottoscrizione di Azure: è possibile crearne una gratuitamente.
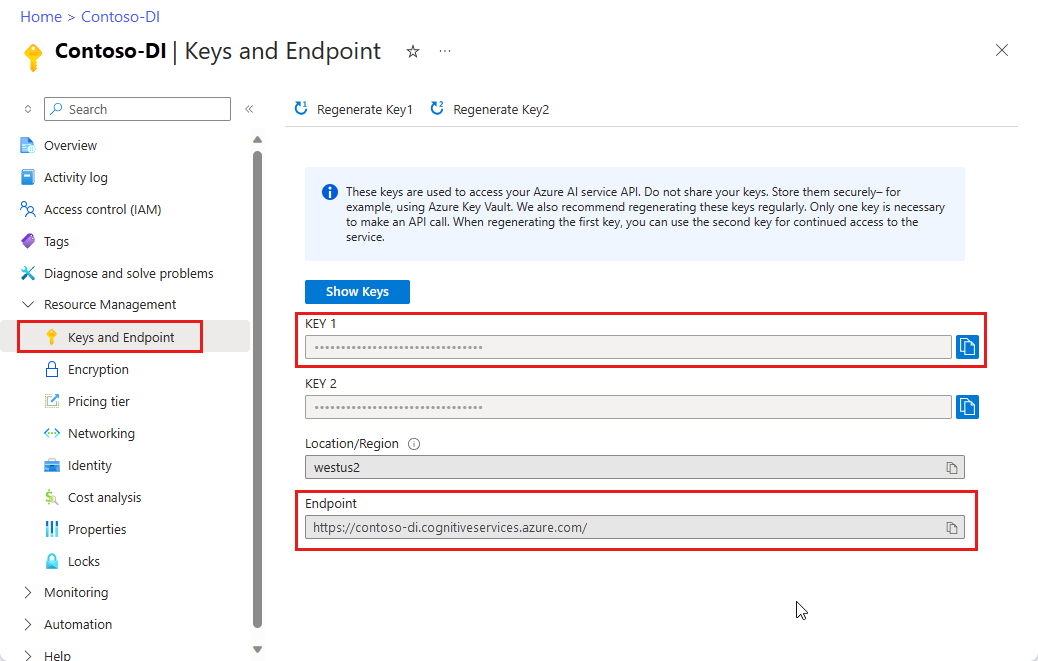
Istanza di Informazioni sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.
Document Intelligence Studio
Nella home page di Studio di Informazioni sui documenti selezionare Documenti fiscali.
È possibile analizzare documenti fiscali di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare Analizza opzioni:

Lingue e impostazioni locali supportate
Per un elenco completo delle lingue supportate, vedere la pagina Relativa al supporto linguistico- modelli predefiniti.
Estrazione di campi
Per i campi di estrazione dei documenti supportati, vedere la pagina relativa allo schema del modello di contratto nel repository di esempio GitHub.
Le coppie chiave-valore del contratto e le voci estratte si trovano nella sezione
documentResultsdell'output JSON.
Passaggi successivi
Provare a elaborare moduli e documenti personalizzati con Studio di Informazioni sui documenti.
Completare l'avvio rapido di Informazioni sui documenti e iniziare a creare un'app per l'elaborazione documenti nel linguaggio di sviluppo preferito.