Modello di documento di Informazioni sui documenti
Importante
A partire dalle versioni di anteprima di Document Intelligence v4.0 e in futuro, il modello di documento generale (precompilt-document) è deprecato. Per estrarre coppie chiave-valore, segni di selezione, testo, tabelle e struttura dai documenti, usare i modelli seguenti:
| Funzionalità | versione | Model ID |
|---|---|---|
Modello Layout con il parametro della stringa di query facoltativo features=keyValuePairs abilitato. |
• v4:29-02-2024-anteprima • v3.1:31-07-2023 (disponibilità generale) |
prebuilt-layout |
| Modello Documento generale | • v3.1:31-07-2023 (disponibilità generale) • v3.0:31-08-2022 (disponibilità generale) • v2.1 (disponibilità generale) |
prebuilt-document |
Questo contenuto si applica a: ![]() v3.1 (GA) | Versione più recente:
v3.1 (GA) | Versione più recente: ![]() v4.0 (GA) | Versione precedente:
v4.0 (GA) | Versione precedente: ![]() v3.0
v3.0
Il modello di documento generale combina potenti funzionalità di riconoscimento ottico dei caratteri (OCR) con modelli di Deep Learning per estrarre coppie chiave-valore, tabelle e segni di selezione dai documenti. Il documento generale è disponibile con le API v3.1 e v3.0. Per altre informazioni, vedere la Guida alla migrazione.
Funzionalità del documento generale
Il modello di documento generale è un modello già sottoposto a training che non richiede etichette o training.
Una singola API estrae coppie chiave/valore, segni di selezione, tabelle e struttura dai documenti.
Il modello di documento generale supporta documenti strutturati, semistrutturati e non strutturati.
I segni di selezione vengono identificati come campi con un valore
:selected:o:unselected:.
Documento di esempio elaborato con Studio di Informazioni sui documenti
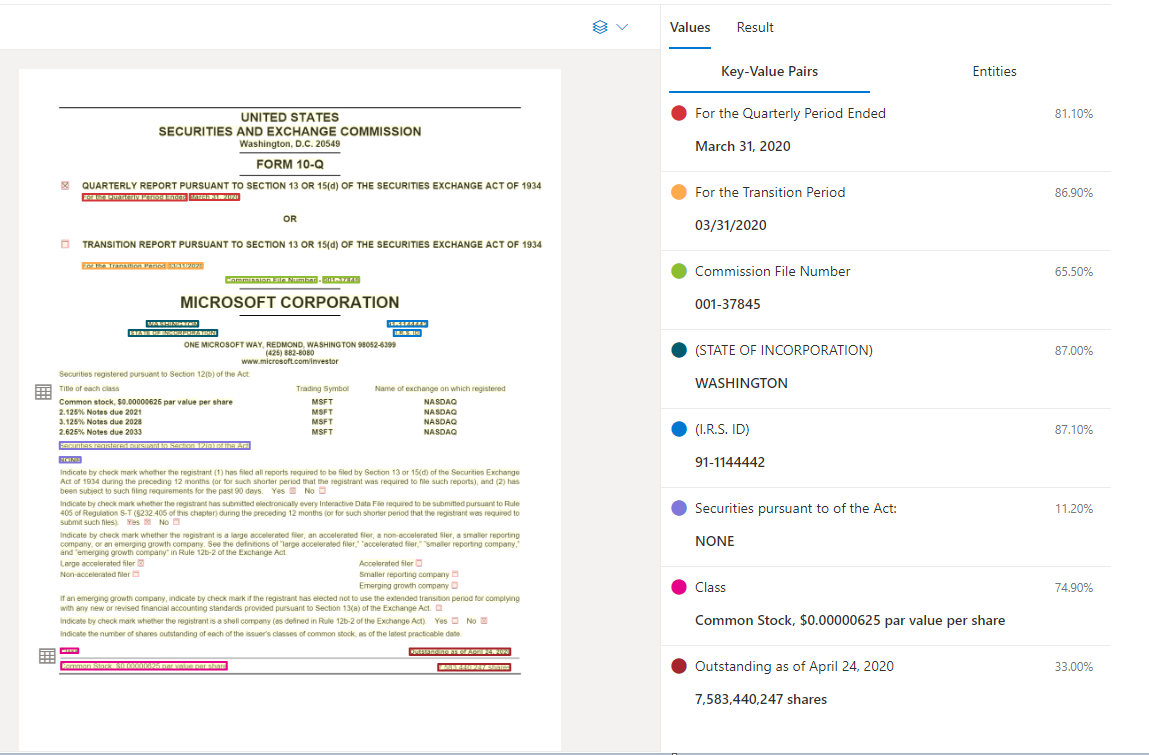
Estrazione di coppie chiave-valore
L'API del documento generale supporta la maggior parte dei tipi di modulo e analizza i documenti, quindi estrae le chiavi e i valori associati. È ideale per estrarre coppie chiave-valore comuni dai documenti. È possibile usare il modello di documento generale come alternativa al training di un modello personalizzato senza etichette.
Opzioni di sviluppo
Informazioni sui documenti v3. 1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di documento generale | • Studio di Informazioni sui documenti • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
Informazioni sui documenti v3.0 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di documento generale | • Studio di Informazioni sui documenti • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
Requisiti di input
Formati di file supportati:
Modello PDF Immagine: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLettura ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento generale ✔ ✔ Predefinito ✔ ✔ Estrazione personalizzata ✔ ✔ Classificazione personalizzata ✔ ✔ ✔ Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
Estrazione dati del modello di documento generale
Provare a estrarre dati da moduli e documenti usando Studio di Informazioni sui documenti.
Sono necessarie le risorse seguenti:
Sottoscrizione di Azure: è possibile crearne una gratuitamente.
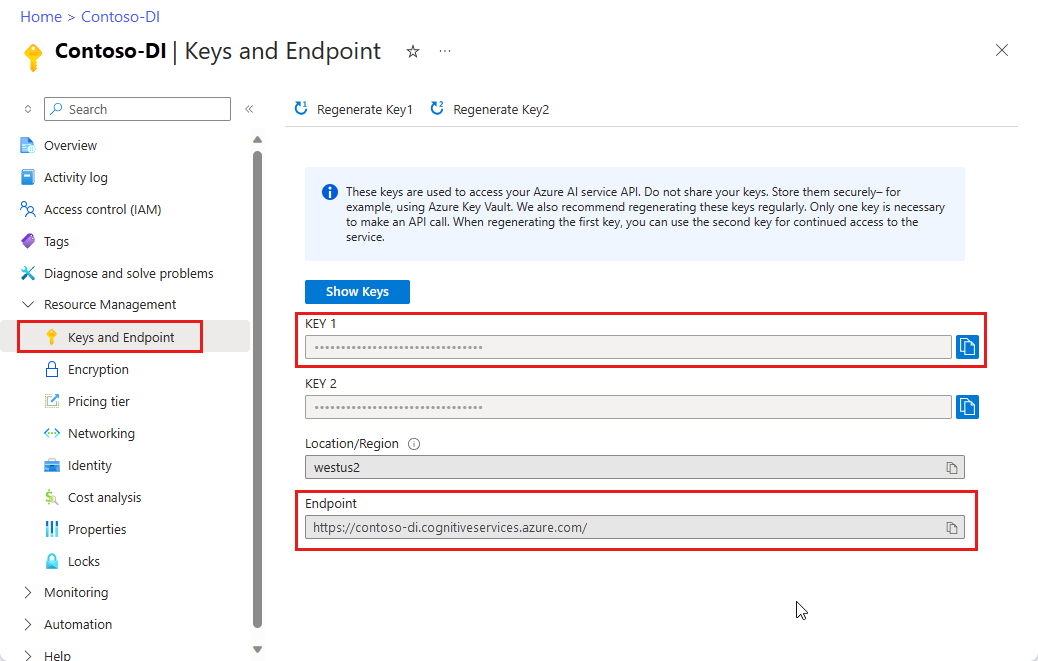
Istanza di Informazioni sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.
Nota
Studio di Informazioni sui documenti e il modello di documento generale sono disponibili con l'API v3.0.
Nella home page di Document Intelligence Studio selezionare Documenti generali.
È possibile analizzare il documento di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare Analizza opzioni:

Coppie chiave-valore
Le coppie chiave-valore sono intervalli specifici all'interno del documento che identificano un'etichetta o una chiave e la risposta o il valore associato. In un modulo strutturato, queste coppie possono essere l'etichetta e il valore immessi dall'utente per tale campo. In un documento non strutturato, possono essere la data di esecuzione di un contratto o possono essere basate sul testo di un paragrafo. Il modello di intelligenza artificiale viene sottoposto a training per estrarre chiavi e valori identificabili in base a un'ampia gamma di tipi, formati e strutture di documenti.
Le chiavi possono esistere anche in isolamento quando il modello rileva che esiste una chiave senza alcun valore associato o quando vengono elaborati campi facoltativi. Ad esempio, un campo del secondo nome può essere lasciato vuoto in un modulo in alcuni casi. Le coppie chiave-valore sono intervalli di testo contenuti nel documento. Per i documenti in cui lo stesso valore viene descritto in modi diversi, ad esempio cliente/utente, la chiave associata è cliente o utente (in base al contesto).
Estrazione dei dati
| Modello | Estrazione di testo | Coppie chiave-valore | Segni di selezione | Tabelle | Nomi comuni |
|---|---|---|---|---|---|
| Documento generale | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* - Disponibile solo nelle versioni API 2023-07-31 (versione 3.1 disponibilità generale) e versioni successive.
Lingue e impostazioni locali supportate
Vedere la pagina Lingue supportate - modelli di analisi dei documenti per un elenco completo delle lingue supportate.
Considerazioni
Poiché le chiavi sono intervalli di testo estratti dal documento; per i documenti semistrutturati, è necessario eseguire il mapping delle chiavi a un dizionario di chiavi esistente.
È possibile riscontrare coppie chiave-valore con una chiave, ma nessun valore. Ad esempio, se un utente ha scelto di non fornire un indirizzo di posta elettronica nel modulo.
Passaggi successivi
Seguire Guida alla migrazione di Informazioni sui documenti v3.1 per informazioni su come usare la versione v3.1 nelle applicazioni e nei flussi di lavoro.
Esplorare l'API REST.