Modello di documento Document Intelligence ID
Questo contenuto si applica a: ![]() v4.0 (GA) | Versioni precedenti:
v4.0 (GA) | Versioni precedenti: ![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Questo contenuto si applica a: ![]() v3.1 (GA) | Versione più recente:
v3.1 (GA) | Versione più recente: ![]() v4.0 (GA) | Versioni precedenti:
v4.0 (GA) | Versioni precedenti: ![]() v3.0
v3.0![]() v2.1
v2.1
Questo contenuto si applica a: ![]() v3.0 (GA) | Versioni più recenti:
v3.0 (GA) | Versioni più recenti: ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 | Versione precedente:
v3.1 | Versione precedente: ![]() v2.1
v2.1
Questo contenuto si applica a: ![]() versione 2.1 | più recente:
versione 2.1 | più recente: ![]() v4.0 (GA)
v4.0 (GA)
Il modello di documento di identità (ID) di Document intelligence combina il riconoscimento ottico dei caratteri (OCR) con i modelli di Deep Learning per analizzare ed estrarre informazioni chiave dai documenti di identità. L'API analizza i documenti di identità (inclusi i seguenti) e restituisce una rappresentazione di dati JSON strutturata.
| Paese | Tipi di documento |
|---|---|
| Tutto il mondo | Passaporto (a libretto e a tessera) |
| Stati Uniti | Patente di guida, tessera di identificazione, permesso di residenza (Green Card), tessera di previdenza sociale, ID militare |
| Europa | Patente di guida, carta d'identità, permesso di soggiorno |
| India | Patente di guida, tessera PAN, tessera Aadhaar |
| Canada | Patente di guida, tessera di identificazione, permesso di residenza (Maple Card) |
| Australia | Patente di guida, tessera fotografica, ID scheda foto, ID Keypass (inclusa la versione digitale) |
Document Intelligence può analizzare ed estrarre informazioni da documenti di identificazione rilasciati da enti pubblici (ID) usando il proprio modello di ID predefinito. Combina potenti funzionalità di riconoscimento ottico dei caratteri (OCR) con funzionalità di riconoscimento di documenti di identità per estrarre le informazioni chiave da passaporti internazionali e USA. Patenti di guida (tutti i 50 stati e D.C.). L'API ID estrae le informazioni chiave da questi documenti di identità, ad esempio nome, cognome, data di nascita, numero del documento e altro ancora. Questa API è disponibile in Document Intelligence v2.1 come servizio cloud.
Elaborazione dei documenti di identità
L'elaborazione dei documenti di identità comporta l'estrazione dei dati dai documenti di identità manualmente o tramite la tecnologia basata su OCR. L'elaborazione dei documenti d'identità è un passaggio importante in qualsiasi operazione aziendale che richieda una prova di identità. Gli esempi includono la verifica dei clienti in banche e altri istituti finanziari, le richieste di mutuo, le visite mediche, l'elaborazione di reclami, il settore dell'ospitalità e altro ancora. Gli individui forniscono una prova della loro identità tramite patenti di guida, passaporti e altri documenti simili in modo che l'azienda possa verificarli in modo efficiente prima di fornire servizi e vantaggi.
di esempio degli Stati Uniti. Patente di guida elaborata con Document Intelligence Studio
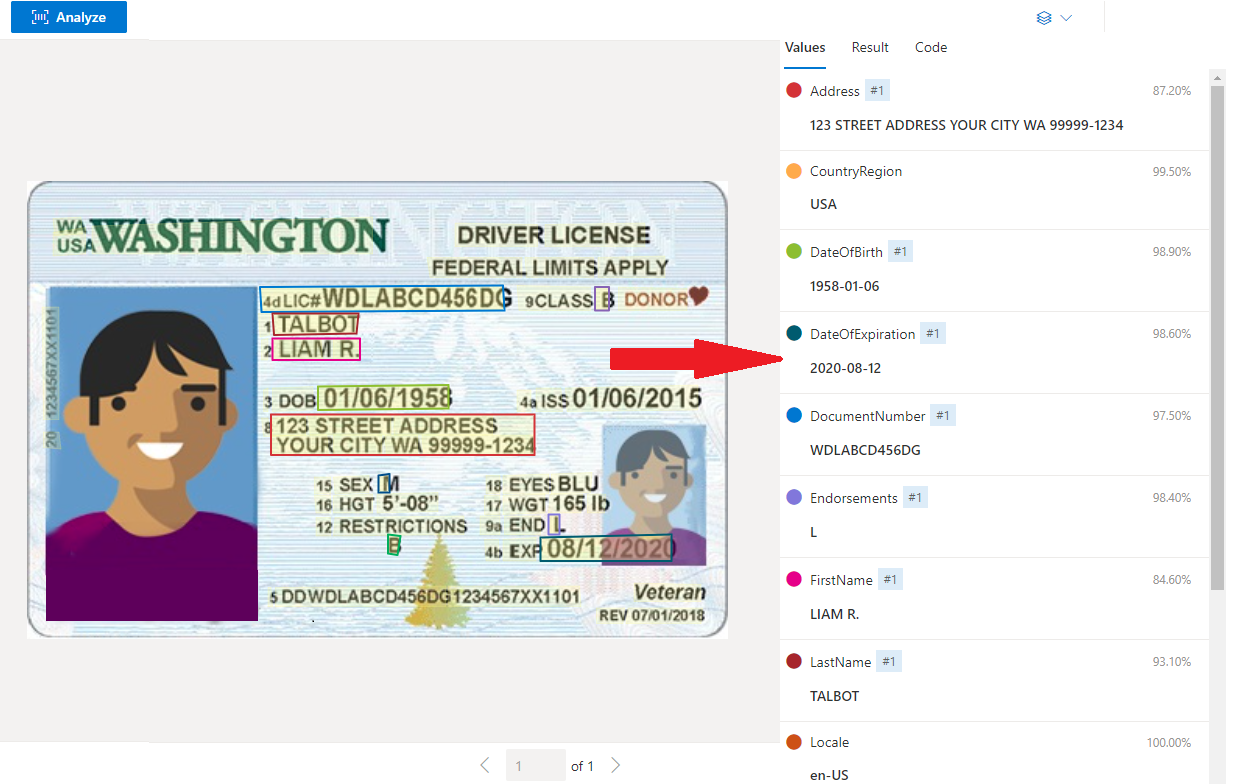
Estrazione dei dati
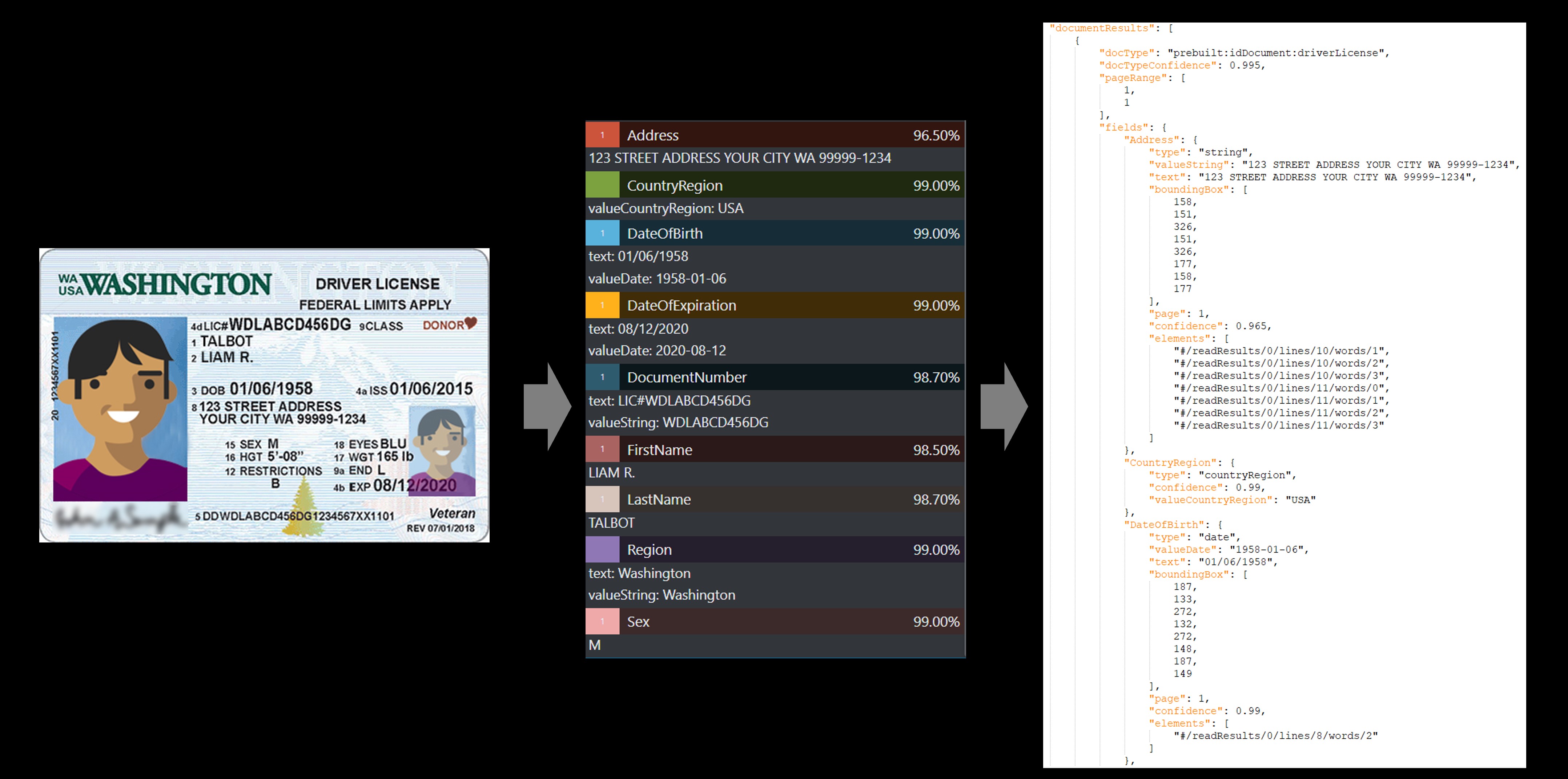
Il servizio ID predefinito estrae i valori chiave dai passaporti internazionali e patenti di guida USA e li restituisce in una risposta JSON strutturata e organizzata.
Esempio di patente di guida
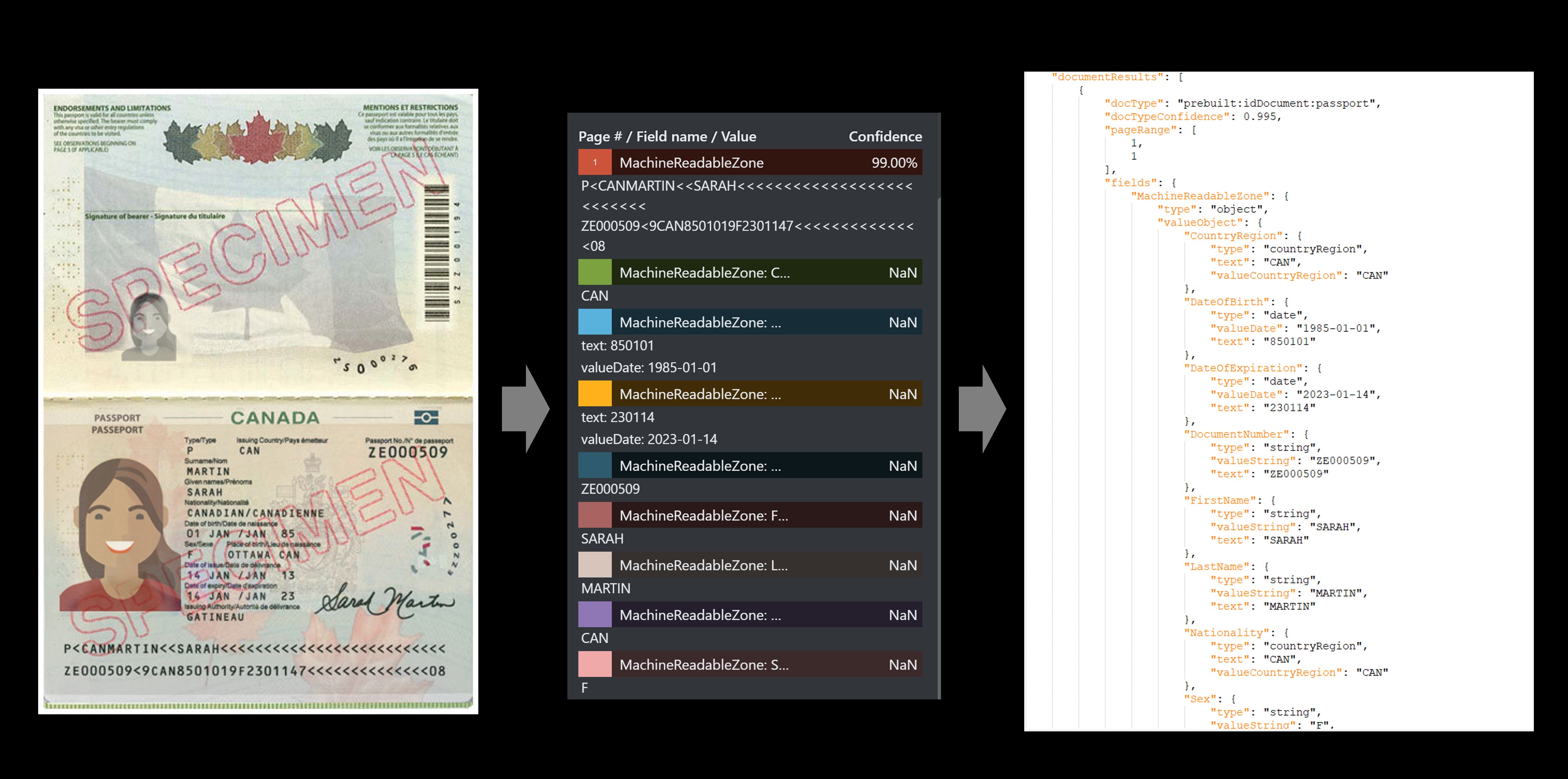
Esempio di passaporto
Opzioni di sviluppo
Document Intelligence v4.0: 2024-11-30 (GA) supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di documento di identità | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3. 1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di documento di identità | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.0 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di documento di identità | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v2.1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse |
|---|---|
| Modello di documento di identità | • Strumento di etichettatura di Document Intelligence • API REST • Client-library SDK • Contenitore Docker di Document Intelligence |
Requisiti di input
Formati di file supportati:
Modello PDF Immagine: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLettura ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento generale ✔ ✔ Predefinito ✔ ✔ Estrazione personalizzata ✔ ✔ Classificazione personalizzata ✔ ✔ ✔ Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
Formati di file supportati: JPEG, PNG, PDF e TIFF.
Numero di pagine supportato per file PDF e TIFF: fino a 2.000 pagine o solo le prime due pagine per gli abbonati del livello gratuito.
Dimensioni del file supportate: meno di 50 MB TOTALI; pixel minimi: 50 x 50 px; pixel massimi 10.000 x 10.000 px.
Estrazione dati del modello di documento ID
Estrarre i dati, inclusi il nome, la data di nascita e la data di scadenza, dai documenti di identità. Sono necessarie le risorse seguenti:
Sottoscrizione di Azure: è possibile crearne una gratuitamente.
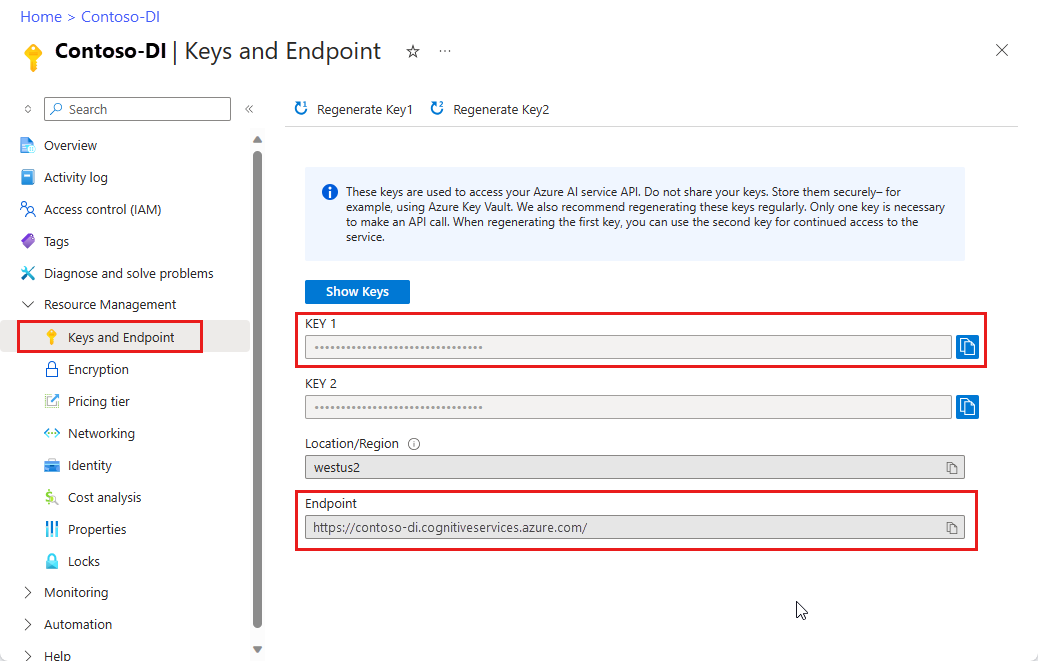
Istanza di Informazioni sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.
Nota
Document Intelligence Studio è disponibile con le API v3.1 e v3.0 e versioni successive.
Nella home page di Studio di Informazioni sui documenti selezionare Documenti di identità.
È possibile analizzare la fattura di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare le Opzioni di analisi:

Strumento di etichettatura di esempio di Informazioni sui documenti
Passare allo strumento di esempio di Informazioni sui documenti.
Nella home page dello strumento di esempio selezionare il riquadro Usa modello predefinito per ottenere i dati.
Selezionare il Tipo di modulo da analizzare nel menu a discesa.
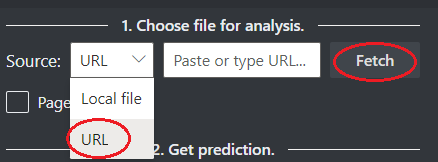
Scegliere un URL per il file da analizzare dalle opzioni seguenti:
Nel campo Origine selezionare URL nel menu a discesa, incollare l'URL selezionato e selezionare il pulsante Recupera.
Nel campo dell'endpoint del servizio Informazioni sui documenti, incollare l'endpoint ottenuto con la sottoscrizione di Informazioni sui documenti.
Nel campo chiave incollare la chiave ottenuta dalla risorsa di Document Intelligence.

Selezionare Esegui analisi. Lo Strumento di etichettatura campioni di Document Intelligence chiama l'API Analyze Prebuilt e analizza il documento.
Visualizzare i risultati: esaminare le coppie chiave-valore estratte, le voci, il testo evidenziato estratto e le tabelle rilevate.
Scaricare il file di output JSON per visualizzare i risultati dettagliati.
- Il nodo "readResults" contiene ogni riga di testo con il rispettivo posizionamento del rettangolo di selezione nella pagina.
- Il nodo "selectionMarks" mostra ogni indicatore di selezione (casella di controllo, indicatore di opzione) e se il relativo stato è selezionato o deselezionato.
- La sezione "pageResults" include le tabelle estratte. Per ogni tabella, Document Intelligence estrae il testo, la riga e l'indice di colonna, la riga e la colonna che si estende, il rettangolo delimitatore e altro ancora.
- Il campo "documentResults" contiene informazioni sulle coppie chiave-valore e informazioni sulle voci per le parti più pertinenti del documento.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nota
Lo strumento di etichettatura di esempio non supporta il formato di file BMP. Si tratta di una limitazione dello strumento, non del servizio Informazioni sui documenti.
Estrazione dei campi
Per i campi di estrazione dei documenti supportati, vedere la pagina dello schema del modello di documento ID nel repository di esempio gitHub.
Tipi di documenti supportati
Il modello di documento d'identità supporta attualmente le patenti di guida statunitensi e la pagina biografica dei passaporti internazionali (esclusi i visti e altri documenti di viaggio).
Campi estratti
| Nome | Tipo | Descrizione | Valore |
|---|---|---|---|
| Country | country | Codice paese conforme allo standard ISO 3166 | "USA" |
| DateOfBirth | data | DOB in formato AAAA-MM-GG | "1980-01-01" |
| DateOfExpiration | data | Data di scadenza nel formato AAAA-MM-GG | "2019-05-05" |
| DocumentNumber | string | Numero di passaporto pertinente, numero di patente di guida e così via. | "340020013" |
| Nome | string | Nome proprio e iniziale del secondo nome estratti, se applicabile | "JENNIFER" |
| Cognome | string | Cognome estratto | "BROOKS" |
| Nazionalità | country | Codice paese conforme allo standard ISO 3166 | "USA" |
| Sex | sesso | I possibili valori estratti includono "M" "F" "X" | "F" |
| MachineReadableZone | oggetto | Passaporto estratto MRZ , incluse due righe di 44 caratteri ciascuno |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | string | Tipo di documento, ad esempio passaporto, patente di guida | "passport" |
| Address | string | Indirizzo estratto (solo patente di guida) | "123 INDIRIZZO CITTÀ WA 99999-1234" |
| Area | string | Area, stato, provincia e così via estratti. (solo patente di guida) | "Washington" |
Guida alla migrazione
- Seguire le indicazioni della Guida alla migrazione di Informazioni sui documenti v3.1 per informazioni su come usare la versione v3.0 nelle applicazioni e nei flussi di lavoro.
Passaggi successivi
Provare a elaborare moduli e documenti personalizzati con Studio di Informazioni sui documenti.
Completare la Guida introduttiva di Informazioni sui documenti e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.
Provare a elaborare moduli e documenti personalizzati con lo strumento di etichettatura di esempio di Informazioni sui documenti.
Completare un avvio rapido di Informazioni sui documenti e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.