Modello di ricevuta di Intelligence sui documenti
Questo contenuto si applica a: ![]() v4.0 (GA) | Versioni precedenti:
v4.0 (GA) | Versioni precedenti: ![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)![]() v2.1 (GA)
v2.1 (GA)
Questo contenuto si applica a: ![]() v3.1 (GA) | Versione più recente:
v3.1 (GA) | Versione più recente: ![]() v4.0 (GA) | Versioni precedenti:
v4.0 (GA) | Versioni precedenti: ![]() v3.0
v3.0![]() v2.1
v2.1
Questo contenuto si applica a: ![]() v3.0 (GA) | Versioni più recenti:
v3.0 (GA) | Versioni più recenti: ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 | Versione precedente:
v3.1 | Versione precedente: ![]() v2.1
v2.1
Questo contenuto si applica a: ![]() versione 2.1 | più recente:
versione 2.1 | più recente: ![]() v4.0 (GA)
v4.0 (GA)
Il modello di ricevuta di Intelligence sui documenti combina potenti funzionalità di riconoscimento ottico dei caratteri (OCR) con modelli di Deep Learning per analizzare ed estrarre informazioni chiave dalle ricevute di vendita. Le ricevute possono essere di vari formati e qualità, tra cui ricevute stampate e scritte a mano. L'API estrae informazioni chiave come il nome del commerciante, il numero di telefono del commerciante, la data della transazione, l'imposta e il totale delle transazioni e restituisce dati JSON strutturati. Il modello di ricevuta v4.0 (GA) supporta anche altri campi, tra cui ReceiptType, TaxDetails.NetAmountTaxDetails.Description, TaxDetails.Rate e CountryRegion.
Tipi di ricevuta supportati nella versione più recente (4.0):
- Pasti
- Forniture
- Hotel
- Combustibile&energia
- Trasporto
- Comunicazione
- Sottoscrizioni
- Entertainment
- Formazione
- Settore sanitario
Estrazione dati delle ricevute
La digitalizzazione delle ricevute comprende la trasformazione di vari tipi di ricevute, tra cui copie analizzate, fotografate e stampate, in un formato digitale per un’elaborazione downstream semplificata. Alcuni esempi sono: Gestione spese, analisi del comportamento dei consumatori, automazione delle imposte e così via. L’uso di Intelligence sui documenti con la tecnologia di riconoscimento ottico dei caratteri (OCR) può estrarre e interpretare i dati da questi diversi formati di ricevuta. L’elaborazione di Intelligence sui documenti semplifica il processo di conversione ma riduce notevolmente il tempo e il lavoro richiesti, facilitando così recupero e gestione dei dati efficienti.
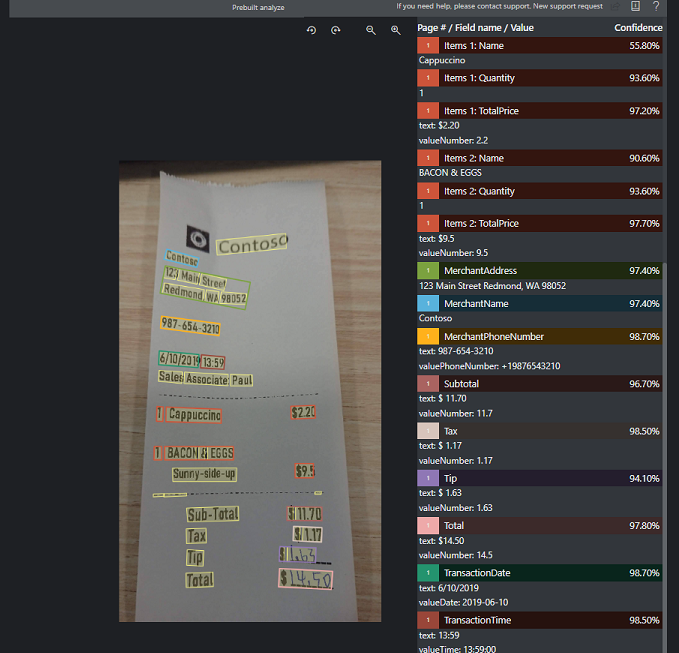
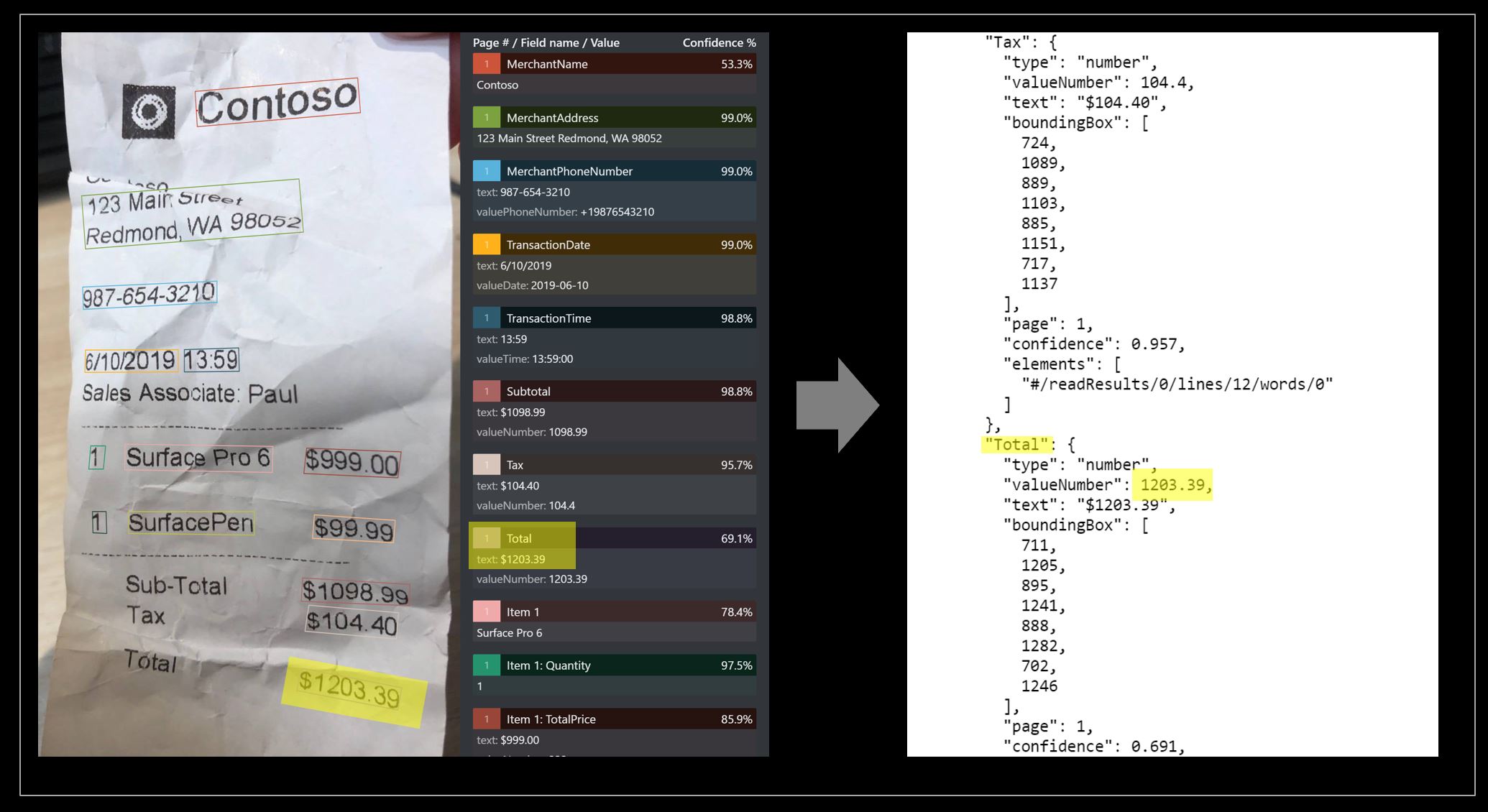
Ricevuta di esempio elaborata con Document Intelligence Studio:

Ricevuta di esempio elaborata con lo strumento di etichettatura di Intelligence sui documenti:
Opzioni di sviluppo
Document Intelligence v4.0: 2024-11-30 (GA) supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di ricevuta | • Document Intelligence Studio • API REST • SDK C# • SDK Python • SDK Java • SDK JavaScript |
prebuilt-receipt |
Intelligence sui documenti v3.1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di ricevuta | • Document Intelligence Studio • API REST • SDK C# • SDK Python • SDK Java • SDK JavaScript |
prebuilt-receipt |
Intelligence sui documenti v3.0 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di ricevuta | • Document Intelligence Studio • API REST • SDK C# • SDK Python • SDK Java • SDK JavaScript |
prebuilt-receipt |
Intelligence sui documenti v2.1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse |
|---|---|
| Modello di ricevuta | • Strumento di etichettatura di Intelligence sui documenti • API REST • SDK Client-library • Contenitore Docker di Intelligence sui documenti |
Requisiti di input
Formati di file supportati:
Modello PDF Immagine: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLettura ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento generale ✔ ✔ Predefinito ✔ ✔ Estrazione personalizzata ✔ ✔ Classificazione personalizzata ✔ ✔ ✔ Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
- Formati di file supportati: JPEG, PNG, PDF e TIFF.
- Autorizzazione della pagina di supporto per PDF e TIFF: Intelligence sui documenti può elaborare fino a 2.000 pagine per sottoscrittori del livello standard o solo le prime due pagine per i sottoscrittori del livello gratuito.
- Dimensioni del file supportate: meno di 50 MB; pixel minimi 50 x 50 px; pixel massimi 10.000 x 10.000 px.
Estrazione dei dati del modello di ricevuta
Vedere in che modo Intelligence sui documenti estrae dati, inclusi ora e data delle transazioni, le informazioni sui commercianti e i totali degli importi delle ricevute. Sono necessarie le risorse seguenti:
Sottoscrizione di Azure: è possibile crearne una gratuitamente.
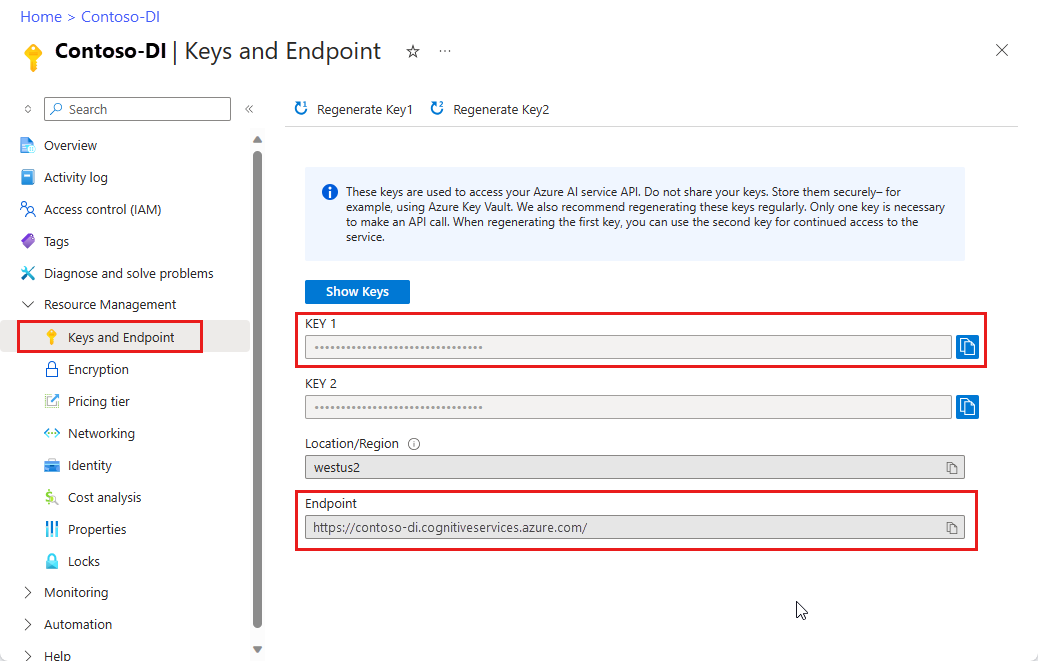
Istanza di Informazioni sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.
Nota
Document Intelligence Studio è disponibile con le API v3.1 e v3.0 e versioni successive.
Nella home page di Studio di Informazioni sui documenti selezionare Ricevute.
È possibile analizzare la ricevuta di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare le Opzioni di analisi:

Strumento di etichettatura di esempio di Informazioni sui documenti
Passare allo strumento di esempio di Informazioni sui documenti.
Nella home page dello strumento di esempio selezionare il riquadro Usa modello predefinito per ottenere i dati.
Selezionare il Tipo di modulo da analizzare nel menu a discesa.
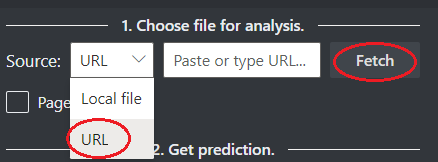
Scegliere un URL per il file da analizzare dalle opzioni seguenti:
Nel campo Origine selezionare URL nel menu a discesa, incollare l'URL selezionato e selezionare il pulsante Recupera.
Nel campo dell'endpoint del servizio Informazioni sui documenti, incollare l'endpoint ottenuto con la sottoscrizione di Informazioni sui documenti.
Nel campo chiave, incollare la chiave ottenuta dalla risorsa di Intelligence sui documenti.

Selezionare Esegui analisi. Lo strumento di etichettatura di esempio di Informazioni sui documenti chiama l'API Analyze Prebuilt e analizza il documento.
Visualizzare i risultati: vedere le coppie chiave-valore estratte, voci, testo evidenziato estratto e tabelle rilevate.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nota
Lo strumento di etichettatura di esempio non supporta il formato di file BMP. Si tratta di una limitazione dello strumento, non del servizio Informazioni sui documenti.
Lingue e impostazioni locali supportate
Per un elenco completo delle lingue supportate, vedere la pagina di supporto per i modelli predefiniti.
Estrazione di campi
Per i campi di estrazione dei documenti supportati, vedere la pagina dello schema del modello di ricevuta nel repository di esempio GitHub
| Nome | Tipo | Descrizione | Output standardizzato |
|---|---|---|---|
| ReceiptType | String | Tipo di ricevuta di vendita | Dettagliata |
| MerchantName | String | Nome del commerciante che emette la ricevuta | |
| MerchantPhoneNumber | phoneNumber | Numero di telefono nell'elenco del commerciante | +1 xxx xxx xxxx |
| MerchantAddress | String | Indirizzo nell'elenco del commerciante | |
| TransactionDate | Data | Data di emissione della ricevuta | aaaa-mm-gg |
| TransactionTime | Ora | Ora di emissione della ricevuta | hh-mm-ss (24 ore) |
| Totali | Numero (USD) | Totale di transazioni complete della ricevuta | Due decimali con virgola mobile |
| Subtotale | Numero (USD) | Subtotale della ricevuta, spesso prima dell'applicazione delle imposte | Due decimali con virgola mobile |
| Imposta | Numero (USD) | Imposta totale sulla ricevuta (spesso IVA o equivalente). Rinominato in "TotalTax" nella versione 2022-06-30. | Due decimali con virgola mobile |
| Suggerimento | Numero (USD) | Suggerimento incluso dall'acquirente | Due decimali con virgola mobile |
| Articoli | Matrice di oggetti | Voci estratte, con nome, quantità, prezzo unitario e prezzo totale estratto | |
| Nome | string | Descrizione dell'articolo. Rinominato in "Description" nella versione 2022-06-30. | |
| Quantità | Numero | Quantità di ogni articolo | Due decimali con virgola mobile |
| Price | Numero | Prezzo singolo di ogni unità articolo | Due decimali con virgola mobile |
| TotalPrice | Numero | Prezzo totale della voce | Due decimali con virgola mobile |
Guida alla migrazione e API REST v3.1
- Seguire la Guida alla migrazione di Intelligence sui documenti v3.1 per informazioni su come usare la versione v3.1 nelle applicazioni e nei flussi di lavoro.
Passaggi successivi
Provare a elaborare moduli e documenti personalizzati con Studio di Informazioni sui documenti.
Completare la Guida introduttiva di Informazioni sui documenti e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.
Provare a elaborare moduli e documenti personalizzati con lo strumento di etichettatura di esempio di Informazioni sui documenti.
Completare un avvio rapido di Informazioni sui documenti e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.