Personalizzare un modello con l'ottimizzazione
Il servizio Azure OpenAI consente di personalizzare i modelli in base ai set di dati personali usando il processo di ottimizzazione. Questa personalizzazione consente di ottenere di più dal servizio, fornendo:
- Risultati di qualità più elevati rispetto a ciò che è possibile ottenere solo dalla progettazione del prompt
- La possibilità di eseguire il training su più esempi di quanto possa rientrare nel limite massimo di contesto di richiesta di un modello.
- Risparmio di token dovuto a richieste più brevi
- Richieste a bassa latenza, in particolare quando si usano modelli più piccoli.
A differenza dell'apprendimento con pochi scatti, l'ottimizzazione migliora il modello eseguendo il training su molti più esempi rispetto a quanto possibile in un prompt, consentendo di ottenere risultati migliori su un numero elevato di attività. Poiché l'ottimizzazione regola i pesi del modello di base per migliorare le prestazioni per l'attività specifica, non sarà necessario includere tutti gli esempi o le istruzioni nel prompt. Verrà inviato meno testo e verranno elaborati meno token su ogni chiamata API, potenzialmente risparmiando costi e migliorando la latenza delle richieste.
Usiamo LoRA, o approssimazione con classificazione bassa, per ottimizzare i modelli in modo da ridurre la complessità senza influire significativamente sulle prestazioni. Questo metodo funziona approssimando la matrice originale di rango elevato con un rango inferiore, ottimizzando quindi solo un sottoinsieme più piccolo di parametri importanti durante la fase di training supervisionata, rendendo il modello più gestibile ed efficiente. Per gli utenti, questo processo rende il training più veloce e più conveniente rispetto ad altre tecniche.
Nel portale di Azure AI Foundry sono disponibili due esperienze di ottimizzazione univoche:
- Visualizzazione Hub/Project: supporta modelli di ottimizzazione da più provider, tra cui Azure OpenAI, Meta Llama, Microsoft Phi e così via.
- Visualizzazione incentrata su Azure OpenAI: supporta solo l'ottimizzazione dei modelli OpenAI di Azure, ma supporta funzionalità aggiuntive, ad esempio l'integrazione dell'anteprima di Weights & Biases (W&B).
Se si ottimizzano solo i modelli OpenAI di Azure, è consigliabile usare l'esperienza di ottimizzazione orientata ad Azure OpenAI disponibile passando a https://oai.azure.com.
Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Crearne una gratuitamente.
- Una risorsa Azure OpenAI che si trova in un'area che supporta l'ottimizzazione del modello Azure OpenAI. Controllare la tabella di riepilogo del modello e la disponibilità dell'area per l'elenco dei modelli disponibili in base all'area e alla funzionalità supportata. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Per ottimizzare l'accesso è necessario il Collaboratore OpenAI di Servizi cognitivi.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Azure AI Foundry, sono necessarie autorizzazioni aggiuntive.
Modelli
I modelli seguenti supportano l'ottimizzazione:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* L'ottimizzazione per questo modello è attualmente disponibile in anteprima pubblica.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
Esaminare il flusso di lavoro per Azure AI Foundry
Esaminare il flusso di lavoro di ottimizzazione per l'uso di Azure AI Foundry:
- Preparare i dati di training e convalida.
- Usare la procedura guidata Crea modello personalizzato nel portale di Azure AI Foundry per eseguire il training del modello personalizzato.
- Selezionare un modello di base.
- Scegliere i dati del training.
- Facoltativamente, scegliere i dati di convalida.
- Facoltativamente, configurare i parametri delle attività per il processo di ottimizzazione.
- Esaminare le scelte ed eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato ottimizzato.
- Distribuire il modello personalizzato da usare.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
Diversi tipi di modello richiedono un formato dei dati di training differente.
I dati di training e convalida usati devono essere formattati come documento JSON Lines (JSONL). Per gpt-35-turbo (tutte le versioni), gpt-4, gpt-4o e gpt-4o-mini, il set di dati di ottimizzazione deve avere il formato di conversazione usato dall'API Completamento chat.
Per una procedura dettagliata sull'ottimizzazione di un modello gpt-4o-mini (2024-07-18), vedere l'esercitazione sull'ottimizzazione di Azure OpenAI.
Formato file di esempio
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formato di file di chat a più turni in Azure OpenAI
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Creare i set di dati di training e convalida
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training, ma un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Usare la procedura guidata Crea modello personalizzato
Azure AI Foundry offre la procedura guidata Crea modello personalizzato, in modo da poter creare ed eseguire il training interattivo di un modello ottimizzato per la risorsa di Azure.
Aprire Azure AI Foundry all'indirizzo https://oai.azure.com/ e accedere con le credenziali che hanno accesso alla risorsa OpenAI di Azure. Durante il flusso di lavoro di accesso selezionare la directory appropriata, la sottoscrizione di Azure e la risorsa Azure OpenAI.
Nel portale di Azure AI Foundry passare al riquadro Strumenti > Ottimizzazione e selezionare Ottimizza modello.


Verrà visualizzata la procedura guidata Crea modello personalizzato.
Selezionare il modello di base
Il primo passaggio per la creazione di un modello personalizzato consiste nella scelta di un modello di base. Il riquadro modello di base consente di scegliere un modello di base da usare per il modello personalizzato. La scelta influisce sia sulle prestazioni che sul costo del modello.
Selezionare un modello di base dall'elenco a discesa Tipo di modello di base, quindi selezionare Avanti per continuare.
È possibile creare un modello personalizzato da uno dei modelli di base disponibili seguenti:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.

Per altre informazioni sui modelli di base che possono essere ottimizzati, vedere Modelli.
Scegliere i dati del training
Il passaggio successivo consiste nella scelta dei dati di training preparati esistenti o nel caricamento di nuovi dati di training preparati da usare durante la personalizzazione del modello. Il riquadro Dati di training visualizza tutti i set di dati esistenti caricati in precedenza e fornisce opzioni in base alle quali è possibile caricare nuovi dati di training.

Se i dati di training sono già caricati nel servizio, selezionare File da Connessione OpenAI di Azure.
- Selezionare il file dall'elenco a discesa visualizzato.
Per caricare nuovi dati di training, usare una delle opzioni seguenti:
Selezionare File locale per caricare i dati di training da un file locale.
Selezionare BLOB di Azure o altri percorsi Web condivisi per importare i dati di training dal BLOB di Azure o da un altro percorso Web condiviso.
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos'è l'archiviazione BLOB di Azure?
Nota
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Caricare i dati di training da un file locale
È possibile caricare un nuovo set di dati di training nel servizio da un file locale usando uno dei metodi seguenti:
Trascinare e rilasciare il file nell'area client del riquadro Dati di training, quindi selezionare Carica file.
Selezionare Sfoglia file nell'area client del riquadro Dati di training, scegliere il file da caricare nella finestra di dialogo Apri e quindi selezionare Carica file.
Dopo aver selezionato e caricato il set di dati di training, selezionare Avanti per continuare.

Importare dati di training da un archivio BLOB di Azure
È possibile importare un set di dati di training da BLOB di Azure o da un altro percorso Web condiviso specificando il nome e il percorso del file.
Immettere il nome file per il file.
Per il percorso del file specificare l'URL del BLOB di Azure, la firma di accesso condiviso di Archiviazione di Azure o un altro collegamento a un percorso Web condiviso accessibile.
Selezionare Importa per importare il set di dati di training nel servizio.
Dopo aver selezionato e caricato il set di dati di training, selezionare Avanti per continuare.

Scegliere i dati di convalida
Il passaggio successivo offre opzioni per configurare il modello in modo da usare i dati di convalida nel processo di training. Se non si desidera usare i dati di convalida, è possibile scegliere Avanti per andare alle opzioni avanzate per il modello. In caso contrario, se si dispone di un set di dati di convalida, è possibile scegliere i dati di convalida preparati esistenti o caricare nuovi dati di convalida preparati da usare durante la personalizzazione del modello.
Il riquadro Dati di convalida visualizza tutti i set di dati di training e convalida esistenti caricati in precedenza e fornisce opzioni in base alle quali è possibile caricare nuovi dati di convalida.

Se i dati di convalida sono già caricati nel servizio, selezionare Scegli set di dati.
- Selezionare il file nell'elenco visualizzato nel riquadro Dati di convalida.
Per caricare nuovi dati di convalida, usare una delle opzioni seguenti:
Selezionare File locale per caricare i dati di convalida da un file locale.
Selezionare BLOB di Azure o altri percorsi Web condivisi per importare i dati di convalida dal BLOB di Azure o da un altro percorso Web condiviso.
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese.
Nota
Come i file di dati di training, anche i file di dati di convalida devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM) e devono avere dimensioni inferiori a 200 MB. Il file deve avere dimensioni inferiori a 512 MB.
Caricare i dati di convalida da un file locale
È possibile caricare un nuovo set di dati di convalida nel servizio da un file locale usando uno dei metodi seguenti:
Trascinare e rilasciare il file nell'area client del riquadro Dati di convalida, quindi selezionare Carica file.
Selezionare Sfoglia file nell'area client del riquadro Dati di convalida, scegliere il file da caricare nella finestra di dialogo Apri e quindi selezionare Carica file.
Dopo aver selezionato e caricato il set di dati di convalida, selezionare Avanti per continuare.

Importare dati di convalida da un archivio BLOB di Azure
È possibile importare un set di dati di convalida da BLOB di Azure o da un altro percorso Web condiviso specificando il nome e il percorso del file.
Immettere il nome file per il file.
Per il percorso del file specificare l'URL del BLOB di Azure, la firma di accesso condiviso di Archiviazione di Azure o un altro collegamento a un percorso Web condiviso accessibile.
Selezionare Importa per importare il set di dati di training nel servizio.
Dopo aver selezionato e caricato il set di dati di convalida, selezionare Avanti per continuare.

Configurare i parametri dei task
La procedura guidata Crea modello personalizzato mostra i parametri per il training del modello ottimizzato nel riquadro Parametri attività. Sono disponibili i parametri seguenti:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
learning_rate_multiplier |
number | Il moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo tra 0,02 e 0,2 per vedere cosa produce i risultati migliori. Una frequenza di apprendimento più piccola può essere utile per evitare l'overfitting. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
seed |
integer | Il valore di inizializzazione controlla la riproducibilità del processo. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente |
Beta |
integer | Parametro temperature per la perdita di dpo, in genere compreso nell'intervallo da 0,1 a 0,5. Questo controlla la quantità di attenzione che viene prestata al modello di riferimento. Più piccola è la versione beta, più il modello consente di allontanarsi dal modello di riferimento. Man mano che la versione beta diventa più piccola, il modello di riferimento viene ignorato. |

Selezionare Predefinito per usare i valori predefiniti per il processo di ottimizzazione fine oppure selezionare Personalizzato per visualizzare e modificare i valori degli iperparametri. Quando si selezionano le impostazioni predefinite, viene determinato il valore corretto in modo algoritmico in base ai dati di training.
Dopo aver configurato le opzioni avanzate, selezionare Avanti per esaminare le scelte ed eseguire il training del modello ottimizzato.
Esaminare le scelte ed eseguire il training del modello
Nel riquadro Revisione della procedura guidata sono visualizzate informazioni sulle scelte di configurazione.

Se si è pronti per eseguire il training del modello, selezionare Avvia processo di training per avviare il processo di ottimizzazione e tornare al riquadro Modelli.
Controllare lo stato del modello personalizzato
Nel riquadro Modelli sono visualizzate informazioni sul modello personalizzato nella scheda Modelli personalizzati. La scheda include informazioni sullo stato e sull'ID processo del processo di ottimizzazione per il modello personalizzato. Al termine del processo, nella scheda viene visualizzato l'ID file del file di risultato. Potrebbe essere necessario selezionare Aggiorna per visualizzare uno stato aggiornato del processo di training del modello.

Dopo aver avviato un processo di ottimizzazione, il completamento può richiedere del tempo. Il processo potrebbe essere in coda dietro altri processi nel sistema. Il training del modello può richiedere minuti o ore, a seconda delle dimensioni del modello e del set di dati.
Di seguito sono elencate alcune delle attività disponibili nel riquadro Modelli:
Controllare lo stato del processo di ottimizzazione per il modello personalizzato nella colonna Stato della scheda Modelli personalizzati.
Nella colonna Nome modello selezionare il nome del modello per visualizzare altre informazioni sul modello personalizzato. È possibile visualizzare lo stato del processo di ottimizzazione, dei risultati del training, degli eventi di training e degli iperparametri usati nel processo.
Selezionare Scarica file di training per scaricare i dati di training usati per il modello.
Selezionare Scarica risultati per scaricare il file di risultato allegato al processo di ottimizzazione per il modello e analizzare il modello personalizzato per ottenere le prestazioni del training e della convalida.
Selezionare Aggiorna per aggiornare le informazioni sulla pagina.
Checkpoint
Al completamento di ogni epoca di training viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire uno snapshot del modello prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione.
Ottimizzazione della valutazione di sicurezza di GPT-4, GPT-4o e GPT-4o mini - Anteprima pubblica
GPT-4o, GPT-4o-mini e GPT-4 sono i nostri modelli più avanzati, che è possibile ottimizzare in base alle proprie esigenze. Come per i modelli OpenAI di Azure in generale, le funzionalità avanzate dei modelli ottimizzati presentano maggiori sfide in materia di intelligenza artificiale responsabile correlate a contenuto dannoso, manipolazione, comportamento simile a quello umano, problemi di privacy e altro ancora. Altre informazioni su rischi, funzionalità e limitazioni sono disponibili nella Panoramica delle procedure di IA responsabili e nella Nota sulla trasparenza. Per attenuare i rischi associati ai modelli ottimizzati avanzati abbiamo implementato ulteriori passaggi di valutazione per rilevare e prevenire contenuto dannoso nel training e negli output dei modelli ottimizzati. Questi passaggi sono basati sullo Standard di intelligenza artificiale responsabile di Microsoft e sul filtro del contenuto del Servizio OpenAI di Azure.
- Le valutazioni vengono eseguite in aree di lavoro private e dedicate, specifiche del cliente;
- Gli endpoint di valutazione si trovano nella stessa area geografica della risorsa OpenAI di Azure;
- I dati di training non vengono archiviati in relazione all'esecuzione di valutazioni; solo la valutazione finale del modello (distribuibile o non distribuibile) viene salvata; e
I filtri di valutazione dei modelli ottimizzati di GPT-4o, e GPT-4o-mini e GPT-4 sono impostati su soglie predefinite e non possono essere modificati dai clienti; non sono associati a alcuna configurazione di filtro del contenuto personalizzata creata.
Valutazione dei dati
Prima dell'inizio del training, i dati vengono valutati per individuare contenuto potenzialmente dannoso, ad esempio violenza, sesso, odio e equità, autolesionismo. Le definizioni delle categorie sono disponibili qui. Se viene rilevato contenuto dannoso con livello di gravità superiore a quello specificato, il processo di training avrà esito negativo e verrà visualizzato un messaggio che indica delle categorie di errore.
Messaggio di esempio:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
I dati di training vengono valutati automaticamente nell'ambito del processo di importazione dei dati come parte della funzionalità di ottimizzazione.
Se il processo di ottimizzazione non riesce a causa del rilevamento di contenuto dannoso nei dati di training, non verrà applicato alcun addebito.
Valutazione del modello
Al termine del training, ma prima che il modello ottimizzato sia disponibile per la distribuzione, il modello risultante viene valutato per rilevare le risposte potenzialmente dannose usando le metriche di rischio e di sicurezza predefinite di Azure. Usando lo stesso approccio ai test applicato ai modelli linguistici di grandi dimensioni di base, la funzionalità di valutazione simula una conversazione con il modello ottimizzato per valutare il potenziale output di contenuto dannoso, sempre usando le categorie di contenuto dannoso specificate (violenza, sesso, odio e equità, autolesionismo).
Se risulta che un modello genera output con contenuto dannoso oltre un livello accettabile, si verrà informati che il modello non è disponibile per la distribuzione, con indicazioni sulle specifiche categorie di danni rilevate:
Messaggio di esempio:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

Come per la valutazione dei dati, il modello viene valutato automaticamente nell'ambito del processo di ottimizzazione come parte della funzionalità di ottimizzazione. Solo la valutazione risultante (distribuibile o non distribuibile) viene registrata dal servizio. Se la distribuzione del modello ottimizzato non riesce a causa del rilevamento di contenuto dannoso negli output del modello, non verrà applicato alcun addebito per l'esecuzione del training.
Distribuire un modello ottimizzato
Quando il processo di ottimizzazione va a buon fine, è possibile distribuire il modello personalizzato dal riquadro Modelli. È necessario distribuire il modello personalizzato per renderlo disponibile per l'uso con le chiamate di completamento.
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi del servizio Azure OpenAI, ogni modello personalizzato (ottimizzato) distribuito comporta un costo di hosting orario, indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento delle chat al modello. Per ulteriori informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per il servizio Azure OpenAI.
Nota
Per un modello personalizzato è consentita una sola distribuzione. Se si seleziona un modello personalizzato già distribuito, viene visualizzato un messaggio di errore.
Per distribuire il modello personalizzato, selezionarlo, quindi selezionare Distribuisci modello.

Verrà visualizzata la finestra di dialogo Distribuisci modello. Nella finestra di dialogo, immettere un nome in Nome distribuzione, quindi selezionare Crea per avviare la distribuzione del modello personalizzato.

È possibile monitorare lo stato di avanzamento della distribuzione nel riquadro Distribuzioni nel portale di Azure AI Foundry.
Distribuzione tra aree
L'ottimizzazione consente di distribuire un modello ottimizzato in un'area diversa da quella in cui il modello è stato originariamente ottimizzato. È anche possibile eseguire la distribuzione in una sottoscrizione o un'area diversa.
Le uniche limitazioni sono che la nuova area deve supportare anche l'ottimizzazione e quando si distribuisce una sottoscrizione incrociata, l'account che genera il token di autorizzazione per la distribuzione deve avere accesso sia alle sottoscrizioni di origine che a quella di destinazione.
La distribuzione tra sottoscrizioni/aree può essere eseguita tramite Python o REST.
Usare un modello personalizzato distribuito
Dopo la distribuzione del modello personalizzato, è possibile usarlo come qualsiasi altro modello distribuito. È possibile usare Playgrounds in Azure AI Foundry per sperimentare la nuova distribuzione. È possibile continuare a usare gli stessi parametri con il modello personalizzato, ad esempio temperature e max_tokens, come è possibile con altri modelli distribuiti. Per i modelli babbage-002 e davinci-002 ottimizzati si useranno il playground Completamenti e l'API Completamenti. Per i modelli ottimizzati gpt-35-turbo-0613 si useranno il playground Chat e l'API Completamento della chat.

Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file di risultato è elencato per ogni modello personalizzato nella colonna ID file risultato nel riquadro Modelli per Azure AI Foundry. È possibile usare l'ID file per identificare e scaricare il file di risultato dal riquadro File di dati di Azure AI Foundry.
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come tracciati nel portale di Azure AI Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Se viene visualizzata una divergenza tra i dati di training e di convalida, ciò potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi del servizio Azure OpenAI, ogni modello personalizzato (ottimizzato) distribuito comporta un costo di hosting orario, indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento delle chat al modello. Per ulteriori informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per il servizio Azure OpenAI.
È possibile eliminare la distribuzione per il modello personalizzato nel riquadro Distribuzioni nel portale di Azure AI Foundry. Selezionare la distribuzione da eliminare, quindi selezionare Elimina per eliminare la distribuzione.
Eliminare il modello personalizzato
È possibile eliminare un modello personalizzato nel riquadro Modelli nel portale di Azure AI Foundry. Selezionare il modello personalizzato da eliminare dalla scheda Modelli personalizzati, quindi selezionare Elimina per eliminare il modello personalizzato.
Nota
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training nel riquadro File di dati di gestione>nel portale di Azure AI Foundry. Selezionare il file da eliminare, quindi selezionare Elimina per eliminare il file.
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, è possibile continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto in Creare un modello personalizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare il modello già ottimizzato. Un modello personalizzato ottimizzato sarà simile al seguente gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7

È anche consigliabile includere il parametro suffix per semplificare la distinzione tra iterazioni differenti del modello ottimizzato. suffix accetta una stringa ed è impostato per identificare il modello ottimizzato. Con l'API Python OpenAI è supportata una stringa di un massimo di 18 caratteri che verrà aggiunta al nome del modello ottimizzato.







Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Crearne una gratuitamente.
- Risorsa Azure OpenAI. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Le librerie Python seguenti:
os,json,requests,openai. - La libreria Python OpenAI deve essere almeno della versione 0.28.1.
- Per ottimizzare l'accesso è necessario il Collaboratore OpenAI di Servizi cognitivi.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Azure AI Foundry, sono necessarie autorizzazioni aggiuntive.
Modelli
I modelli seguenti supportano l'ottimizzazione:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* L'ottimizzazione per questo modello è attualmente disponibile in anteprima pubblica.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
Esaminare il flusso di lavoro per Python SDK
Esaminare il flusso di lavoro di ottimizzazione per l'uso di Python SDK con Azure OpenAI:
- Preparare i dati di training e convalida.
- Selezionare un modello di base.
- Caricare i dati di training.
- Eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato.
- Distribuire il modello personalizzato per l'uso.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
Diversi tipi di modello richiedono un formato dei dati di training differente.
I dati di training e convalida usati devono essere formattati come documento JSON Lines (JSONL). Per gpt-35-turbo-0613 l'ottimizzazione il set di dati deve essere formattato nel formato di conversazione usato dall'API Completamento chat.
Per una procedura dettagliata sull'ottimizzazione, gpt-35-turbo-0613 vedere l'esercitazione sull'ottimizzazione di Azure OpenAI
Formato file di esempio
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formato di file chat multiturn
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Creare i set di dati di training e convalida
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training, ma un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Caricare i dati di training
Il passaggio successivo consiste nella scelta dei dati di training preparati esistenti o nel caricamento di nuovi dati di training preparati da usare durante la personalizzazione del modello. Dopo aver preparato i dati di training, è possibile caricare i file nel servizio. Sono disponibili due modi per caricare i dati di training:
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos’è l’archiviazione BLOB di Azure?
Nota
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
L'esempio Python seguente carica i file di training e convalida locali usando Python SDK e recupera gli ID file restituiti.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Creare un modello personalizzato
Dopo aver caricato i file di training e convalida, si è pronti per avviare il processo di ottimizzazione.
Il codice Python seguente illustra un esempio di come creare un nuovo processo di ottimizzazione con Python SDK:
In questo esempio viene passato anche il parametro per il inizializzazione. Il valore di inizializzazione controlla la riproducibilità del processo. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
È anche possibile passare parametri facoltativi aggiuntivi, ad esempio gli iperparametri, per assumere un maggiore controllo del processo di ottimizzazione. Per il training iniziale, è consigliabile usare le impostazioni predefinite automatiche presenti senza specificare questi parametri.
Gli iperparametri attualmente supportati per l'ottimizzazione sono:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
learning_rate_multiplier |
number | Il moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo tra 0,02 e 0,2 per vedere cosa produce i risultati migliori. Un tasso di apprendimento inferiore può essere utile per evitare l'overfitting. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
seed |
integer | Il valore di inizializzazione controlla la riproducibilità del processo. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente. |
Per impostare iperparametri personalizzati con la versione 1.x dell'API OpenAI Python:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required to access fine-tuning for turbo/babbage-002/davinci-002
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Controllare lo stato del processo di ottimizzazione
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Elencare gli eventi di ottimizzazione
Per esaminare i singoli eventi di ottimizzazione generati durante il training:
Per eseguire questo comando può essere necessario aggiornare la libreria client OpenAI all'ultima versione con pip install openai --upgrade.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Checkpoint
Al completamento di ogni epoca di training viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire uno snapshot del modello prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione. L'epoca finale sarà rappresentata dal modello ottimizzato, le due epoche precedenti saranno disponibili come checkpoint.
È possibile eseguire il comando list checkpoints per recuperare l'elenco dei checkpoint associati a un singolo processo di ottimizzazione:
Per eseguire questo comando può essere necessario aggiornare la libreria client OpenAI all'ultima versione con pip install openai --upgrade.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Ottimizzazione della valutazione di sicurezza di GPT-4, GPT-4o e GPT-4o-mini - Anteprima pubblica
GPT-4o, GPT-4o-mini e GPT-4 sono i nostri modelli più avanzati, che è possibile ottimizzare in base alle proprie esigenze. Come per i modelli OpenAI di Azure in generale, le funzionalità avanzate dei modelli ottimizzati presentano maggiori sfide in materia di intelligenza artificiale responsabile correlate a contenuto dannoso, manipolazione, comportamento simile a quello umano, problemi di privacy e altro ancora. Altre informazioni su rischi, funzionalità e limitazioni sono disponibili nella Panoramica delle procedure di IA responsabili e nella Nota sulla trasparenza. Per attenuare i rischi associati ai modelli ottimizzati avanzati abbiamo implementato ulteriori passaggi di valutazione per rilevare e prevenire contenuto dannoso nel training e negli output dei modelli ottimizzati. Questi passaggi sono basati sullo Standard di intelligenza artificiale responsabile di Microsoft e sul filtro del contenuto del Servizio OpenAI di Azure.
- Le valutazioni vengono eseguite in aree di lavoro private e dedicate, specifiche del cliente;
- Gli endpoint di valutazione si trovano nella stessa area geografica della risorsa OpenAI di Azure;
- I dati di training non vengono archiviati in relazione all'esecuzione di valutazioni; solo la valutazione finale del modello (distribuibile o non distribuibile) viene salvata; e
I filtri di valutazione dei modelli ottimizzati di GPT-4o, e GPT-4o-mini e GPT-4 sono impostati su soglie predefinite e non possono essere modificati dai clienti; non sono associati a alcuna configurazione di filtro del contenuto personalizzata creata.
Valutazione dei dati
Prima dell'inizio del training, i dati vengono valutati per individuare contenuto potenzialmente dannoso, ad esempio violenza, sesso, odio e equità, autolesionismo. Le definizioni delle categorie sono disponibili qui. Se viene rilevato contenuto dannoso con livello di gravità superiore a quello specificato, il processo di training avrà esito negativo e verrà visualizzato un messaggio che indica delle categorie di errore.
Messaggio di esempio:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
I dati di training vengono valutati automaticamente nell'ambito del processo di importazione dei dati come parte della funzionalità di ottimizzazione.
Se il processo di ottimizzazione non riesce a causa del rilevamento di contenuto dannoso nei dati di training, non verrà applicato alcun addebito.
Valutazione del modello
Al termine del training, ma prima che il modello ottimizzato sia disponibile per la distribuzione, il modello risultante viene valutato per rilevare le risposte potenzialmente dannose usando le metriche di rischio e di sicurezza predefinite di Azure. Usando lo stesso approccio ai test applicato ai modelli linguistici di grandi dimensioni di base, la funzionalità di valutazione simula una conversazione con il modello ottimizzato per valutare il potenziale output di contenuto dannoso, sempre usando le categorie di contenuto dannoso specificate (violenza, sesso, odio e equità, autolesionismo).
Se risulta che un modello genera output con contenuto dannoso oltre un livello accettabile, si verrà informati che il modello non è disponibile per la distribuzione, con indicazioni sulle specifiche categorie di danni rilevate:
Messaggio di esempio:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Come per la valutazione dei dati, il modello viene valutato automaticamente nell'ambito del processo di ottimizzazione come parte della funzionalità di ottimizzazione. Solo la valutazione risultante (distribuibile o non distribuibile) viene registrata dal servizio. Se la distribuzione del modello ottimizzato non riesce a causa del rilevamento di contenuto dannoso negli output del modello, non verrà applicato alcun addebito per l'esecuzione del training.
Distribuire un modello ottimizzato
Quando il processo di ottimizzazione ha esito positivo, il valore della variabilefine_tuned_model nel corpo della risposta viene impostato sul nome del modello personalizzato. Il modello è ora disponibile anche per l'individuazione dall'API Modelli di elenco. Tuttavia, non è possibile eseguire chiamate di completamento al modello personalizzato finché non viene distribuito il modello personalizzato. È necessario distribuire il modello personalizzato per renderlo disponibile per l'uso con le chiamate di completamento.
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi del servizio Azure OpenAI, ogni modello personalizzato (ottimizzato) distribuito comporta un costo di hosting orario, indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento delle chat al modello. Per ulteriori informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per il servizio Azure OpenAI.
È anche possibile usare Azure AI Foundry o l'interfaccia della riga di comando di Azure per distribuire il modello personalizzato.
Nota
Per un modello personalizzato è consentita una sola distribuzione. Se si seleziona un modello personalizzato già distribuito, si verifica un errore.
A differenza dei comandi SDK precedenti, la distribuzione deve essere eseguita usando l'API del piano di controllo che richiede un'autorizzazione separata, un percorso API diverso e una versione differente dell'API.
| Variabile | Definizione |
|---|---|
| token | Esistono diversi modi per generare un token di autorizzazione. Il metodo più semplice per i test iniziali consiste nell'avviare Cloud Shell dal portale di Azure. Quindi eseguire az account get-access-token. È possibile usare questo token come token di autorizzazione temporaneo per il test dell'API. È consigliabile archiviare questo valore in una nuova variabile di ambiente. |
| sottoscrizione | ID sottoscrizione per la risorsa Azure OpenAI associata. |
| resource_group | Nome del gruppo di risorse per la risorsa Azure OpenAI. |
| resource_name | Nome della risorsa di OpenAI di Azure. |
| model_deployment_name | Nome personalizzato per la nuova distribuzione del modello ottimizzata. Questo è il nome a cui verrà fatto riferimento nel codice quando si effettuano chiamate di completamento della chat. |
| fine_tuned_model | Recuperare questo valore dai risultati del processo di ottimizzazione nel passaggio precedente. Sarà simile a gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Sarà necessario aggiungere tale valore al deploy_data json. In alternativa, è anche possibile distribuire un checkpoint passando l'ID del checkpoint, che verrà visualizzato nel formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Distribuzione tra aree
L'ottimizzazione consente di distribuire un modello ottimizzato in un'area diversa da quella in cui il modello è stato originariamente ottimizzato. È anche possibile eseguire la distribuzione in una sottoscrizione o un'area diversa.
Le uniche limitazioni sono che la nuova area deve supportare anche l'ottimizzazione e quando si distribuisce una sottoscrizione incrociata, l'account che genera il token di autorizzazione per la distribuzione deve avere accesso sia alle sottoscrizioni di origine che a quella di destinazione.
Di seguito è riportato un esempio di distribuzione di un modello ottimizzato in una sottoscrizione/area in un'altra.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Per eseguire la distribuzione tra la stessa sottoscrizione ma aree differenti, basta che i gruppi di sottoscrizioni e risorse siano identici per le variabili di origine e di destinazione e che solo i nomi delle risorse di origine e di destinazione siano univoci.
Distribuire un modello con l’interfaccia della riga di comando di Azure
L'esempio seguente illustra come usare l'interfaccia della riga di comando di Azure per distribuire il modello personalizzato. Con l'interfaccia della riga di comando di Azure è necessario specificare un nome per la distribuzione del modello personalizzato. Per altre informazioni su come usare l'interfaccia della riga di comando di Azure per distribuire modelli personalizzati, vedere az cognitiveservices account deployment.
Per eseguire questo comando dell'interfaccia della riga di comando di Azure in una finestra della console, è necessario sostituire i <segnaposto> seguenti con i valori corrispondenti per il modello personalizzato:
| Segnaposto | Valore |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Nome o ID della propria sottoscrizione di Azure. |
| <YOUR_RESOURCE_GROUP> | Nome del gruppo di risorse di Azure. |
| <YOUR_RESOURCE_NAME> | Nome della risorsa OpenAI di Azure. |
| <YOUR_DEPLOYMENT_NAME> | Nome da usare per la distribuzione del modello. |
| <YOUR_FINE_TUNED_MODEL_ID> | Nome del modello personalizzato. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Usare un modello personalizzato distribuito
Dopo la distribuzione del modello personalizzato, è possibile usarlo come qualsiasi altro modello distribuito. È possibile usare Playgrounds in Azure AI Foundry per sperimentare la nuova distribuzione. È possibile continuare a usare gli stessi parametri con il modello personalizzato, ad esempio temperature e max_tokens, come è possibile con altri modelli distribuiti. Per i modelli babbage-002 e davinci-002 ottimizzati si useranno il playground Completamenti e l'API Completamenti. Per i modelli ottimizzati gpt-35-turbo-0613 si useranno il playground Chat e l'API Completamento della chat.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file dei risultati è elencato per ogni modello personalizzato ed è possibile usare Python SDK per recuperare l'ID file e scaricare il file di risultato per l'analisi.
L'esempio Python seguente recupera l'ID file del primo file dei risultati allegato al processo di ottimizzazione per il modello personalizzato, quindi usa Python SDK per scaricare il file nella directory di lavoro per l'analisi.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come tracciati nel portale di Azure AI Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Una divergenza tra i dati di training e i dati di convalida potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi del servizio Azure OpenAI, ogni modello personalizzato (ottimizzato) distribuito comporta un costo di hosting orario, indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento delle chat al modello. Per ulteriori informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per il servizio Azure OpenAI.
È possibile usare vari metodi per eliminare la distribuzione per il modello personalizzato:
Eliminare il modello personalizzato
Analogamente, è possibile usare vari metodi per eliminare il modello personalizzato:
Nota
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training dall'abbonamento a Azure OpenAI. È possibile usare i metodi seguenti per eliminare i file di training, convalida e risultato:
- Azure AI Foundry
- Le API REST
- Python SDK
L'esempio Python seguente usa Python SDK per eliminare i file di training, convalida e risultato per il modello personalizzato:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, si può desiderare di continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto in Creare un modello personalizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare l'ID del modello già ottimizzato. L'ID modello ottimizzato è simile al seguente gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
È anche consigliabile includere il parametro suffix per semplificare la distinzione tra iterazioni differenti del modello ottimizzato. suffix accetta una stringa ed è impostato per identificare il modello ottimizzato. Con l'API Python OpenAI è supportata una stringa di un massimo di 18 caratteri che verrà aggiunta al nome del modello ottimizzato.
Se non si è certi dell'ID del modello ottimizzato esistente, queste informazioni sono disponibili nella pagina Modelli di Azure AI Foundry oppure è possibile generare un elenco di modelli per una determinata risorsa OpenAI di Azure usando l'API REST.
Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Crearne una gratuitamente.
- Risorsa Azure OpenAI. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Per ottimizzare l'accesso è necessario il Collaboratore OpenAI di Servizi cognitivi.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Azure AI Foundry, sono necessarie autorizzazioni aggiuntive.
Modelli
I modelli seguenti supportano l'ottimizzazione:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* L'ottimizzazione per questo modello è attualmente disponibile in anteprima pubblica.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
Esaminare il flusso di lavoro per l'API REST
Esaminare il flusso di lavoro di ottimizzazione per l'uso delle API REST e Python con Azure OpenAI:
- Preparare i dati di training e convalida.
- Selezionare un modello di base.
- Caricare i dati di training.
- Eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato.
- Distribuire il modello personalizzato per l'uso.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
Diversi tipi di modello richiedono un formato dei dati di training differente.
I dati di training e convalida usati devono essere formattati come documento JSON Lines (JSONL). Per gpt-35-turbo-0613 e altri modelli correlati, il set di dati di ottimizzazione deve essere formattato nel formato di conversazione usato dall'API Completamento chat.
Per una procedura dettagliata sull'ottimizzazione di un modello gpt-35-turbo-0613, vedere l'esercitazione sull'ottimizzazione di OpenAI di Azure.
Formato file di esempio
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formato di file chat multiturn
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Creare i set di dati di training e convalida
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training, ma un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Selezionare il modello di base
Il primo passaggio per la creazione di un modello personalizzato consiste nella scelta di un modello di base. Il riquadro modello di base consente di scegliere un modello di base da usare per il modello personalizzato. La scelta influisce sia sulle prestazioni che sul costo del modello.
Selezionare un modello di base dall'elenco a discesa Tipo di modello di base, quindi selezionare Avanti per continuare.
È possibile creare un modello personalizzato da uno dei modelli di base disponibili seguenti:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)gpt-4o(2024-08-06)gpt-4o-mini(2023-07-18)
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Per altre informazioni sui modelli di base che possono essere ottimizzati, vedere Modelli.
Caricare i dati di training
Il passaggio successivo consiste nella scelta dei dati di training preparati esistenti o nel caricamento di nuovi dati di training preparati da usare durante l'ottimizzazione del modello. Dopo aver preparato i dati di training, è possibile caricare i file nel servizio. Sono disponibili due modi per caricare i dati di training:
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos’è l’archiviazione BLOB di Azure?
Nota
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Carica dati di training
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Caricare i dati di convalida
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Creare un modello personalizzato
Dopo aver caricato i file di training e convalida, si è pronti per avviare il processo di ottimizzazione. Il codice seguente mostra un esempio di come creare un nuovo processo di ottimizzazione con l'API REST.
In questo esempio viene passato anche il parametro per il inizializzazione. Il valore di inizializzazione controlla la riproducibilità del processo. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
È anche possibile passare parametri facoltativi aggiuntivi, ad esempio gli iperparametri, per assumere un maggiore controllo del processo di ottimizzazione. Per il training iniziale, è consigliabile usare le impostazioni predefinite automatiche presenti senza specificare questi parametri.
Gli iperparametri attualmente supportati per l'ottimizzazione sono:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
learning_rate_multiplier |
number | Il moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo tra 0,02 e 0,2 per vedere cosa produce i risultati migliori. Un tasso di apprendimento inferiore può essere utile per evitare l'overfitting. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
seed |
integer | Il valore di inizializzazione controlla la riproducibilità del processo. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente. |
Controllare lo stato del modello personalizzato
Dopo aver avviato un processo di ottimizzazione, il completamento può richiedere del tempo. Il processo potrebbe essere in coda dietro altri processi nel sistema. Il training del modello può richiedere minuti o ore, a seconda delle dimensioni del modello e del set di dati. L'esempio seguente usa l'API REST per controllare lo stato del processo di ottimizzazione. L'esempio recupera informazioni sul processo usando l'ID processo restituito dall'esempio precedente:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Elencare gli eventi di ottimizzazione
Per esaminare i singoli eventi di ottimizzazione generati durante il training:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Checkpoint
Al completamento di ogni epoca di training viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire uno snapshot del modello prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione. L'epoca finale sarà rappresentata dal modello ottimizzato, le due epoche precedenti saranno disponibili come checkpoint.
È possibile eseguire il comando list checkpoints per recuperare l'elenco dei checkpoint associati a un singolo processo di ottimizzazione:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Ottimizzazione della valutazione di sicurezza di GPT-4, GPT-4o e GPT-4o-mini - Anteprima pubblica
GPT-4o, GPT-4o-mini e GPT-4 sono i nostri modelli più avanzati, che è possibile ottimizzare in base alle proprie esigenze. Come per i modelli OpenAI di Azure in generale, le funzionalità avanzate dei modelli ottimizzati presentano maggiori sfide in materia di intelligenza artificiale responsabile correlate a contenuto dannoso, manipolazione, comportamento simile a quello umano, problemi di privacy e altro ancora. Altre informazioni su rischi, funzionalità e limitazioni sono disponibili nella Panoramica delle procedure di IA responsabili e nella Nota sulla trasparenza. Per attenuare i rischi associati ai modelli ottimizzati avanzati abbiamo implementato ulteriori passaggi di valutazione per rilevare e prevenire contenuto dannoso nel training e negli output dei modelli ottimizzati. Questi passaggi sono basati sullo Standard di intelligenza artificiale responsabile di Microsoft e sul filtro del contenuto del Servizio OpenAI di Azure.
- Le valutazioni vengono eseguite in aree di lavoro private e dedicate, specifiche del cliente;
- Gli endpoint di valutazione si trovano nella stessa area geografica della risorsa OpenAI di Azure;
- I dati di training non vengono archiviati in relazione all'esecuzione di valutazioni; solo la valutazione finale del modello (distribuibile o non distribuibile) viene salvata; e
I filtri di valutazione dei modelli ottimizzati di GPT-4o, e GPT-4o-mini e GPT-4 sono impostati su soglie predefinite e non possono essere modificati dai clienti; non sono associati a alcuna configurazione di filtro del contenuto personalizzata creata.
Valutazione dei dati
Prima dell'inizio del training, i dati vengono valutati per individuare contenuto potenzialmente dannoso, ad esempio violenza, sesso, odio e equità, autolesionismo. Le definizioni delle categorie sono disponibili qui. Se viene rilevato contenuto dannoso con livello di gravità superiore a quello specificato, il processo di training avrà esito negativo e verrà visualizzato un messaggio che indica delle categorie di errore.
Messaggio di esempio:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
I dati di training vengono valutati automaticamente nell'ambito del processo di importazione dei dati come parte della funzionalità di ottimizzazione.
Se il processo di ottimizzazione non riesce a causa del rilevamento di contenuto dannoso nei dati di training, non verrà applicato alcun addebito.
Valutazione del modello
Al termine del training, ma prima che il modello ottimizzato sia disponibile per la distribuzione, il modello risultante viene valutato per rilevare le risposte potenzialmente dannose usando le metriche di rischio e di sicurezza predefinite di Azure. Usando lo stesso approccio ai test applicato ai modelli linguistici di grandi dimensioni di base, la funzionalità di valutazione simula una conversazione con il modello ottimizzato per valutare il potenziale output di contenuto dannoso, sempre usando le categorie di contenuto dannoso specificate (violenza, sesso, odio e equità, autolesionismo).
Se risulta che un modello genera output con contenuto dannoso oltre un livello accettabile, si verrà informati che il modello non è disponibile per la distribuzione, con indicazioni sulle specifiche categorie di danni rilevate:
Messaggio di esempio:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Come per la valutazione dei dati, il modello viene valutato automaticamente nell'ambito del processo di ottimizzazione come parte della funzionalità di ottimizzazione. Solo la valutazione risultante (distribuibile o non distribuibile) viene registrata dal servizio. Se la distribuzione del modello ottimizzato non riesce a causa del rilevamento di contenuto dannoso negli output del modello, non verrà applicato alcun addebito per l'esecuzione del training.
Distribuire un modello ottimizzato
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi del servizio Azure OpenAI, ogni modello personalizzato (ottimizzato) distribuito comporta un costo di hosting orario, indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento delle chat al modello. Per ulteriori informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per il servizio Azure OpenAI.
L'esempio Python seguente illustra come usare l'API REST per creare una distribuzione del modello per il modello personalizzato. L'API REST genera un nome per la distribuzione del modello personalizzato.
| Variabile | Definizione |
|---|---|
| token | Esistono diversi modi per generare un token di autorizzazione. Il metodo più semplice per i test iniziali consiste nell'avviare Cloud Shell dal portale di Azure. Quindi eseguire az account get-access-token. È possibile usare questo token come token di autorizzazione temporaneo per il test dell'API. È consigliabile archiviare questo valore in una nuova variabile di ambiente. |
| sottoscrizione | ID sottoscrizione per la risorsa Azure OpenAI associata. |
| resource_group | Nome del gruppo di risorse per la risorsa Azure OpenAI. |
| resource_name | Nome della risorsa di OpenAI di Azure. |
| model_deployment_name | Nome personalizzato per la nuova distribuzione del modello ottimizzata. Questo è il nome a cui verrà fatto riferimento nel codice quando si effettuano chiamate di completamento della chat. |
| fine_tuned_model | Recuperare questo valore dai risultati del processo di ottimizzazione nel passaggio precedente. Sarà simile a gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Sarà necessario aggiungere tale valore al deploy_data json. In alternativa, è anche possibile distribuire un checkpoint passando l'ID del checkpoint, che verrà visualizzato nel formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Distribuzione tra aree
L'ottimizzazione consente di distribuire un modello ottimizzato in un'area diversa da quella in cui il modello è stato originariamente ottimizzato. È anche possibile eseguire la distribuzione in una sottoscrizione o un'area diversa.
Le uniche limitazioni sono che la nuova area deve supportare anche l'ottimizzazione e quando si distribuisce una sottoscrizione incrociata, l'account che genera il token di autorizzazione per la distribuzione deve avere accesso sia alle sottoscrizioni di origine che a quella di destinazione.
Di seguito è riportato un esempio di distribuzione di un modello ottimizzato in una sottoscrizione/area in un'altra.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Per eseguire la distribuzione tra la stessa sottoscrizione ma aree differenti, basta che i gruppi di sottoscrizioni e risorse siano identici per le variabili di origine e di destinazione e che solo i nomi delle risorse di origine e di destinazione siano univoci.
Distribuire un modello con l’interfaccia della riga di comando di Azure
L'esempio seguente illustra come usare l'interfaccia della riga di comando di Azure per distribuire il modello personalizzato. Con l'interfaccia della riga di comando di Azure è necessario specificare un nome per la distribuzione del modello personalizzato. Per altre informazioni su come usare l'interfaccia della riga di comando di Azure per distribuire modelli personalizzati, vedere az cognitiveservices account deployment.
Per eseguire questo comando dell'interfaccia della riga di comando di Azure in una finestra della console, è necessario sostituire i <segnaposto> seguenti con i valori corrispondenti per il modello personalizzato:
| Segnaposto | Valore |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Nome o ID della propria sottoscrizione di Azure. |
| <YOUR_RESOURCE_GROUP> | Nome del gruppo di risorse di Azure. |
| <YOUR_RESOURCE_NAME> | Nome della risorsa OpenAI di Azure. |
| <YOUR_DEPLOYMENT_NAME> | Nome da usare per la distribuzione del modello. |
| <YOUR_FINE_TUNED_MODEL_ID> | Nome del modello personalizzato. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Usare un modello personalizzato distribuito
Dopo la distribuzione del modello personalizzato, è possibile usarlo come qualsiasi altro modello distribuito. È possibile usare Playgrounds in Azure AI Foundry per sperimentare la nuova distribuzione. È possibile continuare a usare gli stessi parametri con il modello personalizzato, ad esempio temperature e max_tokens, come è possibile con altri modelli distribuiti. Per i modelli babbage-002 e davinci-002 ottimizzati si useranno il playground Completamenti e l'API Completamenti. Per i modelli ottimizzati gpt-35-turbo-0613 si useranno il playground Chat e l'API Completamento della chat.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file dei risultati è elencato per ogni modello personalizzato ed è possibile usare l’API REST per recuperare l'ID file e scaricare il file di risultato per l'analisi.
L'esempio Python seguente usa l'API REST per recuperare l'ID file del primo file dei risultati allegato al processo di ottimizzazione per il modello personalizzato e quindi scaricare il file nella directory di lavoro per l'analisi.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come tracciati nel portale di Azure AI Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Se viene visualizzata una divergenza tra i dati di training e di convalida, ciò potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
È possibile usare vari metodi per eliminare la distribuzione per il modello personalizzato:
Eliminare il modello personalizzato
Analogamente, è possibile usare vari metodi per eliminare il modello personalizzato:
Nota
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training dall'abbonamento a Azure OpenAI. È possibile usare i metodi seguenti per eliminare i file di training, convalida e risultato:
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, si può desiderare di continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto in Creare un modello personalizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare l'ID del modello già ottimizzato. L'ID modello ottimizzato è simile al seguente gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
È anche consigliabile includere il parametro suffix per semplificare la distinzione tra iterazioni differenti del modello ottimizzato. suffix accetta una stringa ed è impostato per identificare il modello ottimizzato. Il suffisso può contenere fino a 40 caratteri (a-z, A-Z, 0-9 e _) che verranno aggiunti al nome del modello ottimizzato.
Se non si è certi dell'ID del modello ottimizzato, queste informazioni sono disponibili nella pagina Modelli di Azure AI Foundry oppure è possibile generare un elenco di modelli per una determinata risorsa OpenAI di Azure usando l'API REST.
Standard globale
L'ottimizzazione di Azure OpenAI supporta distribuzioni standard globali negli Stati Uniti orientali 2, Stati Uniti centro-settentrionali e Svezia centrale per:
gpt-4o-2024-08-06gpt-4o-mini-2024-07-18
Le distribuzioni standard globali offrono risparmi sui costi, ma i pesi dei modelli personalizzati possono essere archiviati temporaneamente all'esterno dell'area geografica della risorsa OpenAI di Azure.

Le distribuzioni di ottimizzazione standard globale attualmente non supportano la visione e gli output strutturati.
Ottimizzazione della visione
L'ottimizzazione è anche possibile con le immagini nei file JSONL. Proprio come è possibile inviare uno o più input di immagine ai completamenti della chat, è possibile includere gli stessi tipi di messaggio all'interno dei dati di training. Le immagini possono essere fornite come URL accessibili pubblicamente o URI dati contenenti immagini con codifica Base64.
Requisiti del set di dati delle immagini
- Il file di training può contenere un massimo di 50.000 esempi che contengono immagini (non inclusi esempi di testo).
- Ogni esempio può avere al massimo 64 immagini.
- Ogni immagine può essere al massimo 10 MB.
Formato
Le immagini devono essere:
- JPEG
- PNG
- WEBP
Le immagini devono essere in modalità immagine RGB o RGBA.
Non è possibile includere immagini come output dei messaggi con il ruolo assistente.
Criteri di contrazione modalità tenda
Le immagini vengono scansionate prima del training per assicurarsi che siano conformi alle note sulla trasparenza dei criteri di utilizzo. Ciò può introdurre latenza nella convalida dei file prima dell'avvio dell'ottimizzazione.
Le immagini contenenti quanto segue verranno escluse dal set di dati e non usate per il training:
- People
- Visi
- CAPTCHAs
Importante
Per l'ottimizzazione del processo di screening dei visi: viene visualizzata una schermata per i visi o le persone per ignorare tali immagini dal training del modello. La funzionalità di screening sfrutta il rilevamento dei volti SENZA identificazione viso, il che significa che non creiamo modelli facciali o misurano una geometria facciale specifica e la tecnologia usata per lo schermo per i visi non è in grado di identificare in modo univoco gli individui. Per altre informazioni sui dati e sulla privacy per i visi, vedere - Dati e privacy per Viso - Servizi di intelligenza artificiale di Azure | Microsoft Learn.
Memorizzazione nella cache prompt
L'ottimizzazione di Azure OpenAI supporta la memorizzazione nella cache dei prompt con modelli selezionati. La memorizzazione nella cache dei prompt consente di ridurre la latenza complessiva delle richieste e i costi per richieste più lunghe con contenuto identico all'inizio della richiesta. Per altre informazioni sulla memorizzazione nella cache dei prompt, vedere Introduzione alla memorizzazione nella cache dei prompt.
Ottimizzazione delle preferenze dirette (DPO) (anteprima)
L'ottimizzazione delle preferenze dirette (DPO) è una tecnica di allineamento per i modelli linguistici di grandi dimensioni, usata per regolare i pesi del modello in base alle preferenze umane. Differisce dall'apprendimento per rinforzo rispetto al feedback umano (RLHF) in quanto non richiede l'adattamento di un modello di ricompensa e usa preferenze di dati binari più semplici per il training. Si tratta di peso computazionale più leggero e più veloce di RLHF, pur essendo altrettanto efficace in corrispondenza dell'allineamento.
Perché dpo è utile?
Il DPO è particolarmente utile negli scenari in cui non esiste una risposta corretta chiara e elementi soggettivi come tono, stile o preferenze di contenuto specifiche sono importanti. Questo approccio consente anche al modello di apprendere da esempi positivi (ciò che è considerato corretto o ideale) e da esempi negativi (ciò che è meno desiderato o errato).
Si ritiene che il DPO sia una tecnica che renderà più semplice per i clienti generare set di dati di training di alta qualità. Anche se molti clienti faticano a generare set di dati di grandi dimensioni sufficienti per l'ottimizzazione con supervisione, spesso dispongono di dati sulle preferenze già raccolti in base ai log utente, ai test A/B o a attività di annotazione manuali più piccole.
Formato del set di dati di ottimizzazione delle preferenze dirette
I file di ottimizzazione delle preferenze dirette hanno un formato diverso rispetto all'ottimizzazione con supervisione. I clienti forniscono una "conversazione" contenente il messaggio di sistema e il messaggio utente iniziale, quindi "completamenti" con dati di preferenza associati. Gli utenti possono fornire solo due completamenti.
Tre campi di primo livello: input, preferred_output e non_preferred_output
- Ogni elemento nel preferred_output/non_preferred_output deve contenere almeno un messaggio di assistente
- Ogni elemento nel preferred_output/non_preferred_output può avere ruoli solo in (assistente, strumento)
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
I set di dati di training devono essere in jsonl formato:
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
Supporto del modello di ottimizzazione delle preferenze dirette
gpt-4o-2024-08-06supporta l'ottimizzazione delle preferenze dirette nelle rispettive aree di ottimizzazione. La disponibilità dell'area più recente viene aggiornata nella pagina dei modelli
Gli utenti possono usare l'ottimizzazione delle preferenze con i modelli di base e i modelli che sono già stati ottimizzati usando l'ottimizzazione con supervisione, purché siano di un modello/versione supportato.
Come usare l'ottimizzazione delle preferenze dirette?
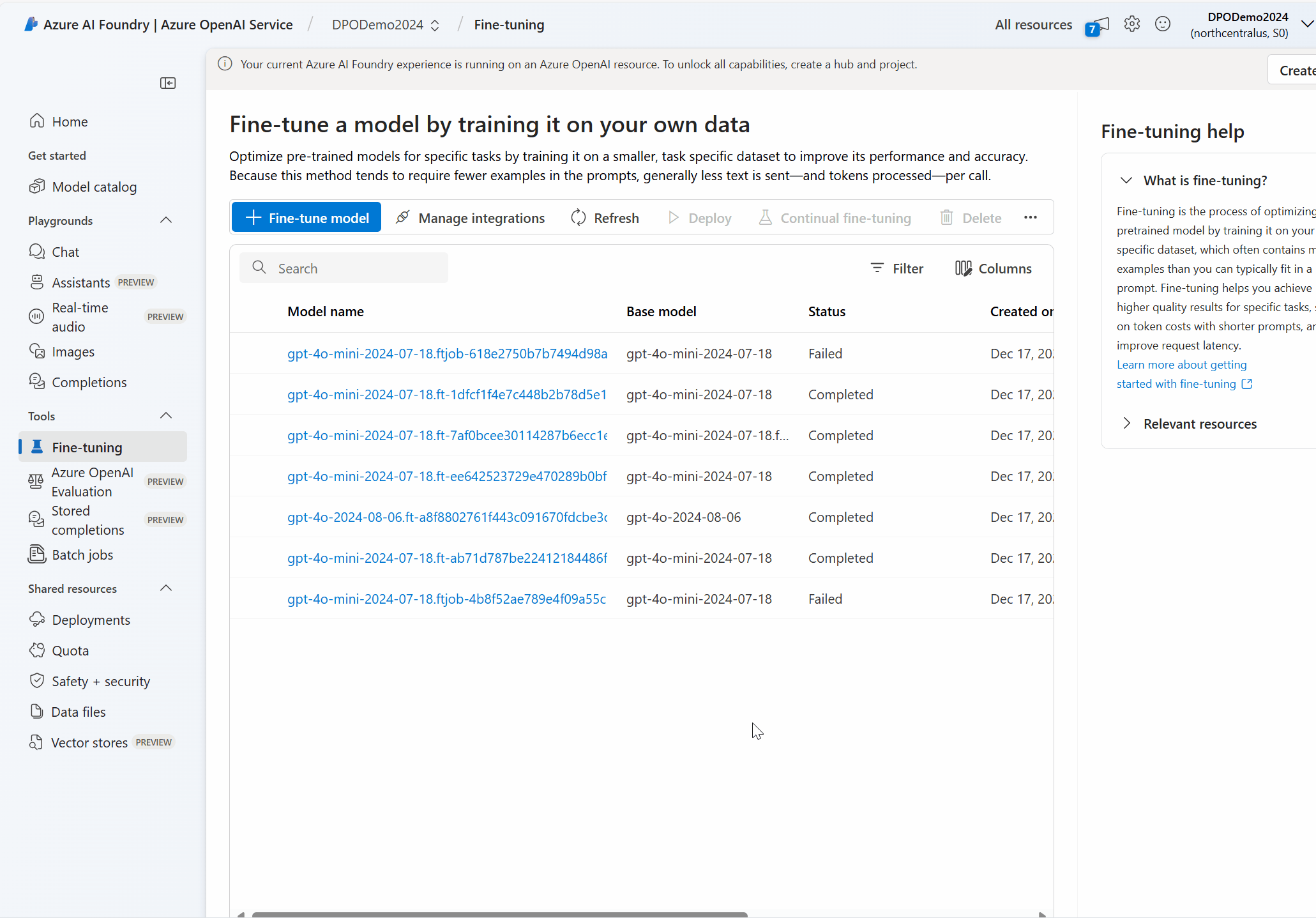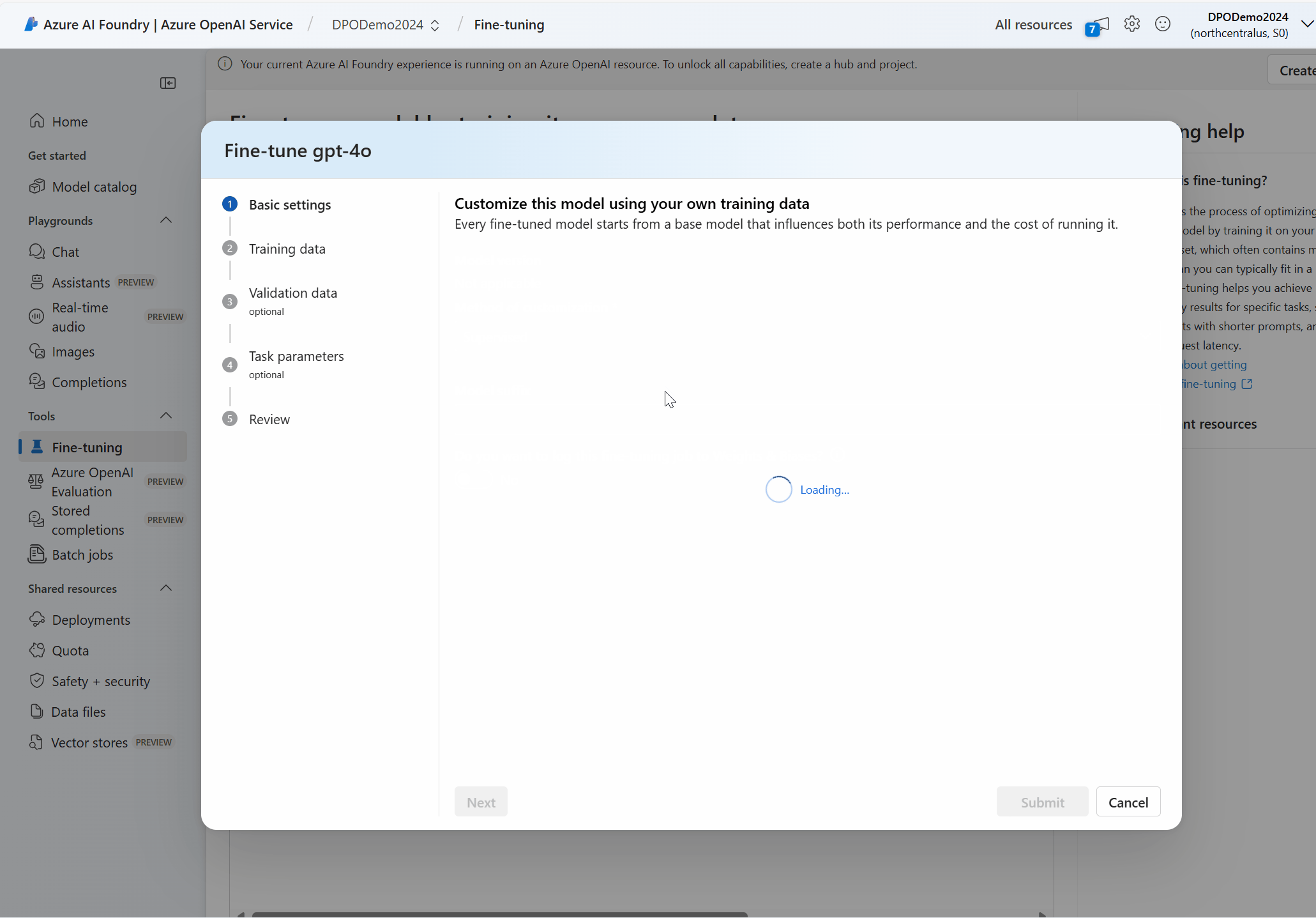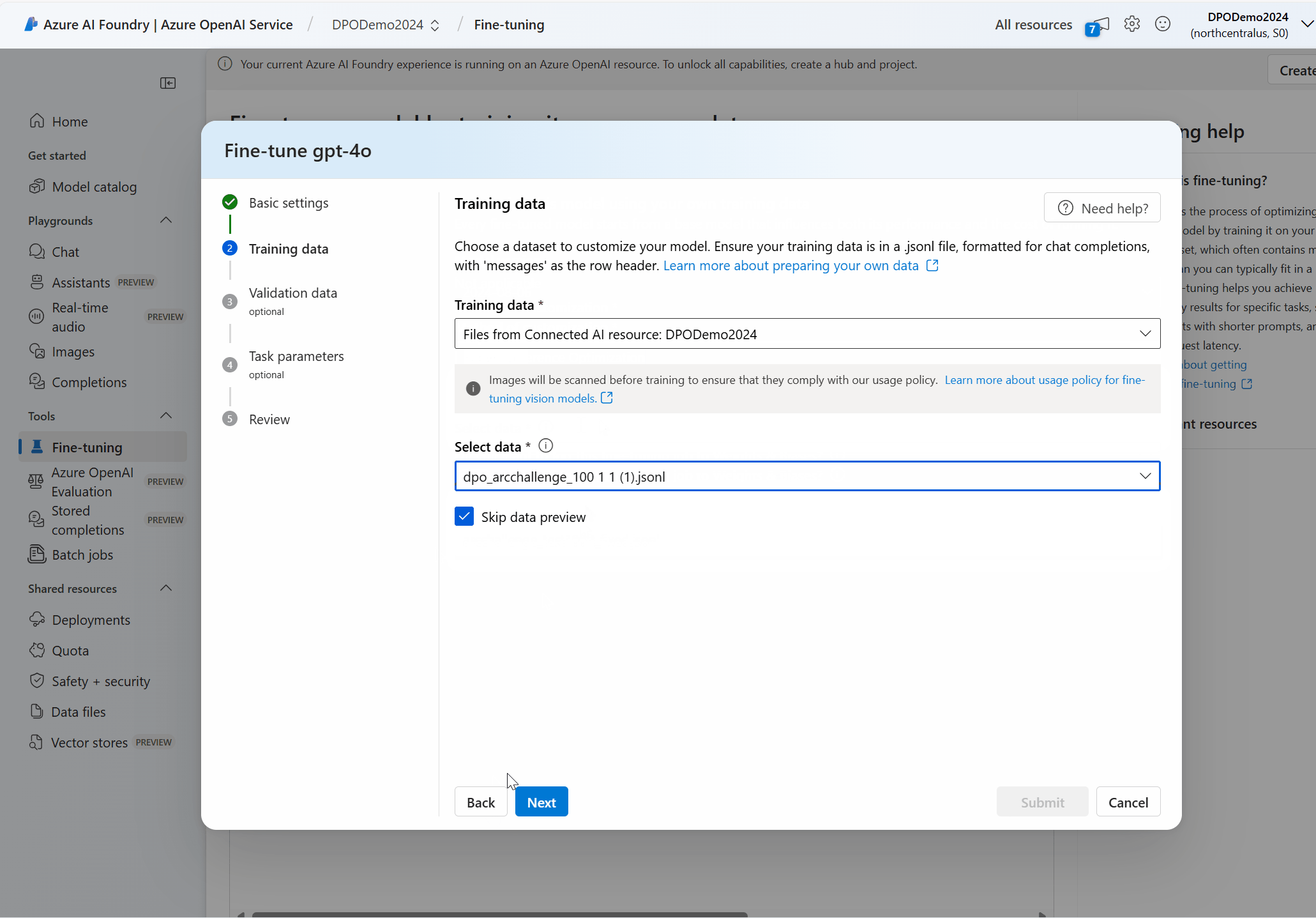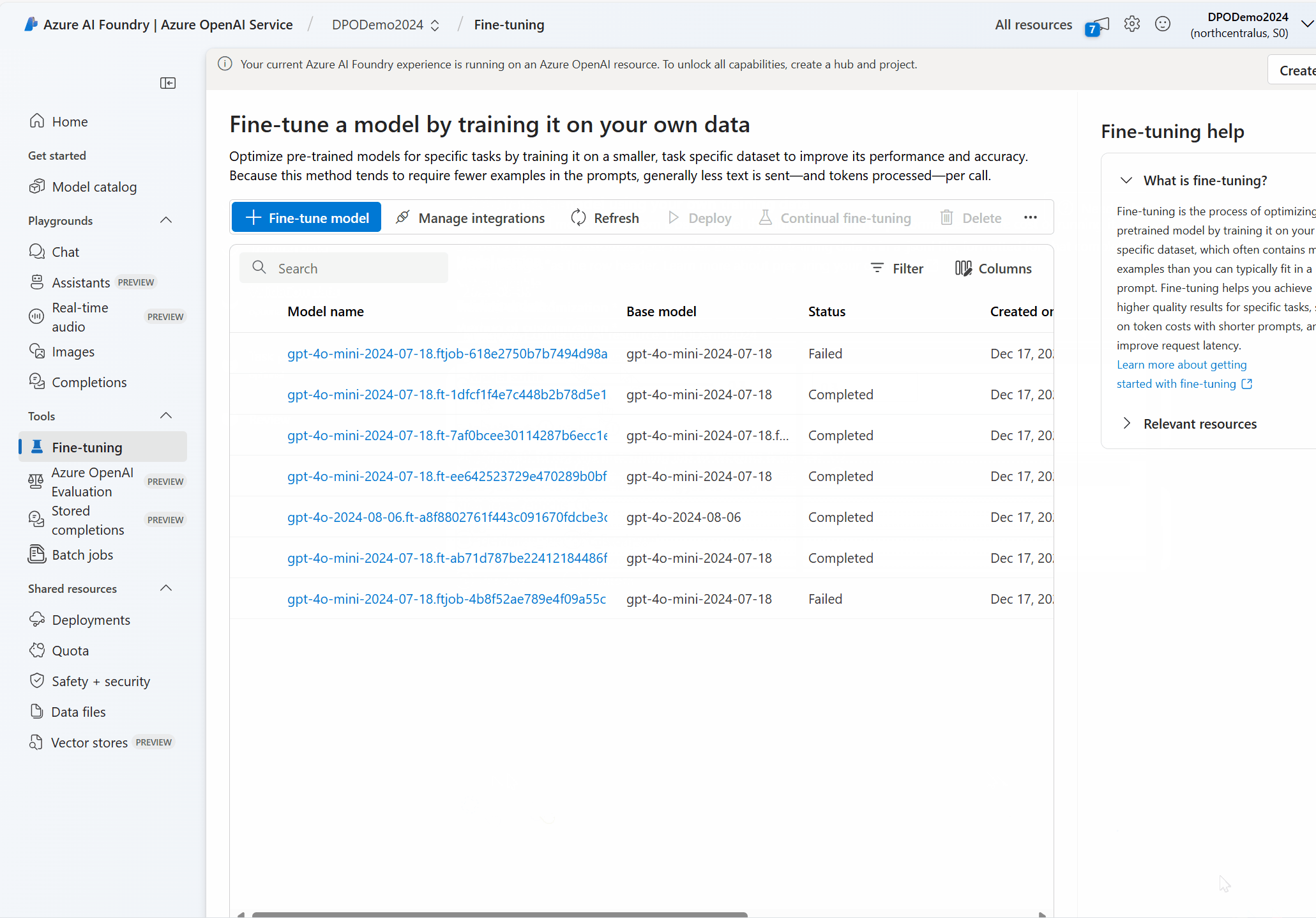
- Preparare
jsonli set di dati nel formato delle preferenze. - Selezionare il modello e quindi selezionare il metodo di personalizzazione di Ottimizzazione preferenza diretta.
- Caricare set di dati: training e convalida. Anteprima in base alle esigenze.
- Selezionare gli iperparametri, i valori predefiniti sono consigliati per la sperimentazione iniziale.
- Esaminare le selezioni e creare un processo di ottimizzazione.
Risoluzione dei problemi
Come si abilita l'ottimizzazione?
Per accedere correttamente all'ottimizzazione, è necessario ricoprire il ruolo di Collaboratore OpenAI di Servizi cognitivi. Persino un utente con autorizzazioni di Amministratore del servizio di alto livello avrebbe comunque bisogno di questo account impostato in modo esplicito per accedere all'ottimizzazione. Per altre informazioni, vedere le linee guida per il controllo degli accessi in base al ruolo.
Perché il caricamento non è riuscito?
Se il caricamento del file non riesce in Azure OpenAI Studio, è possibile visualizzare il messaggio di errore in "file di dati" in Azure OpenAI Studio. Passare il puntatore del mouse su dove viene visualizzato "errore" (sotto la colonna dello stato) per visualizzare una spiegazione dell'errore.

Il mio modello ottimizzato non sembra aver migliorato
Messaggio di sistema mancante: è necessario fornire un messaggio di sistema durante l'ottimizzazione. È necessario fornire lo stesso messaggio di sistema quando si usa il modello ottimizzato. Se si specifica un messaggio di sistema diverso, è possibile che vengano visualizzati risultati differenti rispetto a quelli ottimizzati.
Dati non sufficienti: anche se 10 rappresenta il valore minimo per l'esecuzione della pipeline, sono necessarie centinaia a migliaia di punti dati per insegnare al modello una nuova competenza. Un numero di punti dati troppo basso comporta il rischio di overfitting e scarsa generalizzazione. Il modello ottimizzato potrebbe performare bene sui dati di training, ma male su altri dati perché ha memorizzato gli esempi di training, anziché i modelli di apprendimento. Per ottenere risultati ottimali, pianificare la preparazione di un set di dati con centinaia o migliaia di punti dati.
Dati non validi: un set di dati non accurato o non rappresentativo produrrà un modello di bassa qualità. Il modello può apprendere modelli non accurati o distorti dal set di dati. Ad esempio, se si esegue il training di un chatbot per il servizio clienti, ma si forniscono solo i dati di training per uno scenario (ad esempio, resi di articoli), il suddetto non saprà come rispondere ad altri scenari. In alternativa, se i dati di training non sono corretti (contengono risposte non corrette), il modello imparerà a fornire risultati inesatti.
Ottimizzazione con la visione
Cosa fare se le immagini vengono ignorate
Le immagini possono essere ignorate per i motivi seguenti:
- contiene CAPTCHAs
- contiene persone
- contiene visi
Rimuovere l'immagine. Per il momento, non è possibile ottimizzare i modelli con immagini contenenti queste entità.
Problemi comuni
| Problema | Motivo/soluzione |
|---|---|
| Immagini ignorate | Le immagini possono essere ignorate per i motivi seguenti: contiene CAPTCHA, persone o visi. Rimuovere l'immagine. Per il momento, non è possibile ottimizzare i modelli con immagini contenenti queste entità. |
| URL inaccessibile | Verificare che l'URL dell'immagine sia accessibile pubblicamente. |
| Immagine troppo grande | Verificare che le immagini rientrano nei limiti delle dimensioni del set di dati. |
| Formato immagine non valido | Verificare che le immagini siano incluse nel formato del set di dati. |
Come caricare file di grandi dimensioni
I file di training potrebbero avere dimensioni piuttosto grandi. È possibile caricare file fino a 8 GB in più parti usando l'API Caricamenti anziché l'API File, che consente solo caricamenti di file fino a 512 MB.
Riduzione dei costi di training
Se si imposta il parametro dettaglio per un'immagine su basso, l'immagine viene ridimensionata a 512 di 512 pixel ed è rappresentata solo da 85 token indipendentemente dalle dimensioni. In questo modo si ridurrà il costo del training.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
Altre considerazioni per l'ottimizzazione della visione
Per controllare la fedeltà della comprensione delle immagini, impostare il parametro di dettaglio di image_url su low, higho auto per ogni immagine. Ciò influirà anche sul numero di token per immagine che il modello vede durante il tempo di training e influirà sul costo del training.
Passaggi successivi
- Esplorare le funzionalità di ottimizzazione nell'esercitazione sull'ottimizzazione di Azure OpenAI.
- Esaminare la disponibilità a livello di area del modello di ottimizzazione
- Altre informazioni sulle quote Azure OpenAI