Avvio rapido: Riconoscere le finalità della comprensione del linguaggio di conversazione
Documentazione di riferimento | Pacchetto (NuGet) | Ulteriori esempi in GitHub
In questo avvio rapido si useranno i servizi Voce e di linguaggio per riconoscere le finalità dei dati audio acquisiti da microfono. In particolare, si userà il servizio Voce per riconoscere la voce e un modello CLU (comprensione del linguaggio di conversazione) per identificare le finalità.
Importante
CLU (comprensione del linguaggio di conversazione) è disponibile per C# e C++ con Speech SDK versione 1.25 o successiva.
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa di linguaggio nel portale di Azure.
- Ottenere la chiave e l'endpoint della risorsa di linguaggio. Dopo aver distribuito la risorsa di linguaggio, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Speech SDK è disponibile come pacchetto NuGet e implementa .NET Standard 2.0. Speech SDK verrà installato più avanti in questa guida, ma innanzitutto controllare la guida all'installazione dell'SDK per eventuali altri requisiti.
Impostare le variabili di ambiente
Questo esempio richiede variabili di ambiente denominate LANGUAGE_KEY, LANGUAGE_ENDPOINT SPEECH_KEY e SPEECH_REGION.
L'applicazione deve essere autenticata per accedere alle risorse di Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
LANGUAGE_KEY, sostituireyour-language-keycon una delle chiavi della risorsa. - Per impostare la variabile di ambiente
LANGUAGE_ENDPOINT, sostituireyour-language-endpointcon una delle aree della risorsa. - Per impostare la variabile di ambiente
SPEECH_KEY, sostituireyour-speech-keycon una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituisciyour-speech-regioncon una delle aree della risorsa.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Nota
Se serve solo accedere alla variabile di ambiente nella console in esecuzione corrente, è possibile impostare la variabile di ambiente con set, anziché setx.
Dopo aver aggiunto le variabili di ambiente, potrebbe essere necessario riavviare tutti i programmi in esecuzione che dovranno leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Creare un progetto di comprensione del linguaggio di conversazione
Dopo aver creato una risorsa di linguaggio, creare un progetto di comprensione del linguaggio di conversazione in Studio del linguaggio. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa di linguaggio usata.
Passare a Language Studio e accedere con l'account Azure.
Creare un progetto di comprensione del linguaggio di conversazione
In questo avvio rapido è possibile scaricare questo progetto di esempio di domotica e importarlo. Questo progetto può prevedere i comandi previsti dall'input dell'utente, ad esempio, accendere e spegnere le luci.
In Studio del linguaggio nella sezione Comprendere le domande e il linguaggio di conversazioneselezionare Comprensione del linguaggio di conversazione.

Verrà visualizzata la pagina dei Progetti di comprensione del linguaggio di conversazione. Accanto al pulsante Crea nuovo progetto selezionare Importa.
Nella finestra visualizzata caricare il file JSON da importare. Assicurarsi che il file segua il formato JSON supportato.


Al termine del caricamento verrà visualizzata la pagina Definizione schema. In questo avvio rapido lo schema è già compilato e le espressioni sono già etichettate con finalità ed entità.
Eseguire il training del modello
In genere, dopo aver creato un progetto è necessario compilare uno schema ed etichettare le espressioni. In questo avvio rapido è già stato importato un progetto pronto con lo schema compilato e le espressioni etichettate.
Per eseguire il training di un modello è necessario avviare un processo di training. L'output di un processo di training corretto è il modello sottoposto a training.
Per avviare il training del modello dallo Studio del linguaggio:
Selezionare Esegui training del modello nel menu a sinistra.
Selezionare Avvia un processo di training nel menu in alto.
Selezionare Esegui training di un nuovo modello e digitare il nome di un modello nuovo nella casella di testo. In alternativa, per sostituire un modello esistente con uno sottoposto a training sui nuovi dati, selezionare Sovrascrivi un modello esistente e poi selezionare un modello esistente. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
Selezionare la modalità di training. È possibile scegliere Training standard per un training più rapido; anche se è disponibile solo in inglese. In alternativa, è possibile scegliere Training avanzato, che supporta altre lingue e progetti multilingue, ma comporta tempi di training più lunghi. Altre informazioni sulle modalità di training.
Selezionare il metodo di divisione dei dati. È possibile scegliere Divisione automatica del set di test dai dati di training: il sistema dividerà le espressioni tra il set di training e il set di test in base alle percentuali specificate. In alternativa, è possibile scegliere l’opzione Usa una divisione manuale dei dati di training e di testing che è abilitata solo se sono state aggiunte espressioni al set di test durante l’etichettatura delle espressioni.
Selezionare il pulsante Esegui il training.
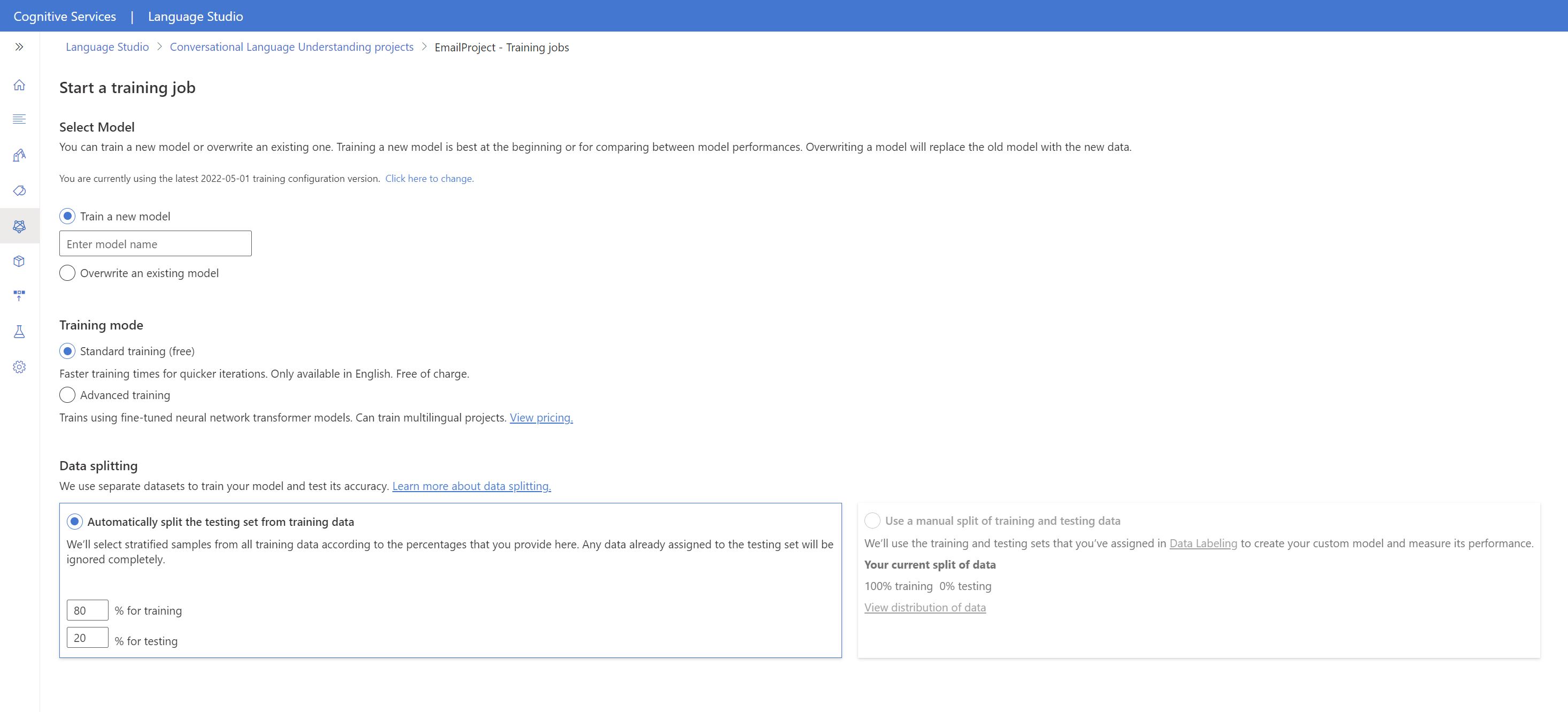
Selezionare l'ID processo di training dall'elenco. Sarà visualizzato un riquadro in cui è possibile verificare lo stato del training, lo stato del processo e altri dettagli sul processo.
Nota
- Solo i processi di training completati correttamente genereranno modelli.
- Il training può richiedere da un paio di minuti a un paio d’ore, in base al numero di espressioni.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training nello stesso progetto fino al completamento del processo in esecuzione.
- L'apprendimento automatico usato per eseguire il training dei modelli viene aggiornato regolarmente. Per eseguire il training su una precedente versione di configurazione selezionare Selezionare qui per modificare nella pagina Avvia un processo di training e scegliere una versione precedente.

Distribuire il modello
In genere dopo il training di un modello, si esaminano i relativi dettagli di valutazione. In questo avvio rapido si distribuirà solo il modello e lo si renderà disponibile per la prova in Studio del linguaggio; in alternativa, è possibile effettuare la chiamata all' API di stima.
Per distribuire un modello all’interno di Studio di linguaggio:
Selezionare Distribuzione di un modello nel menu a sinistra.
Selezionare Aggiungi distribuzione per avviare la procedura guidata Aggiungi distribuzione.
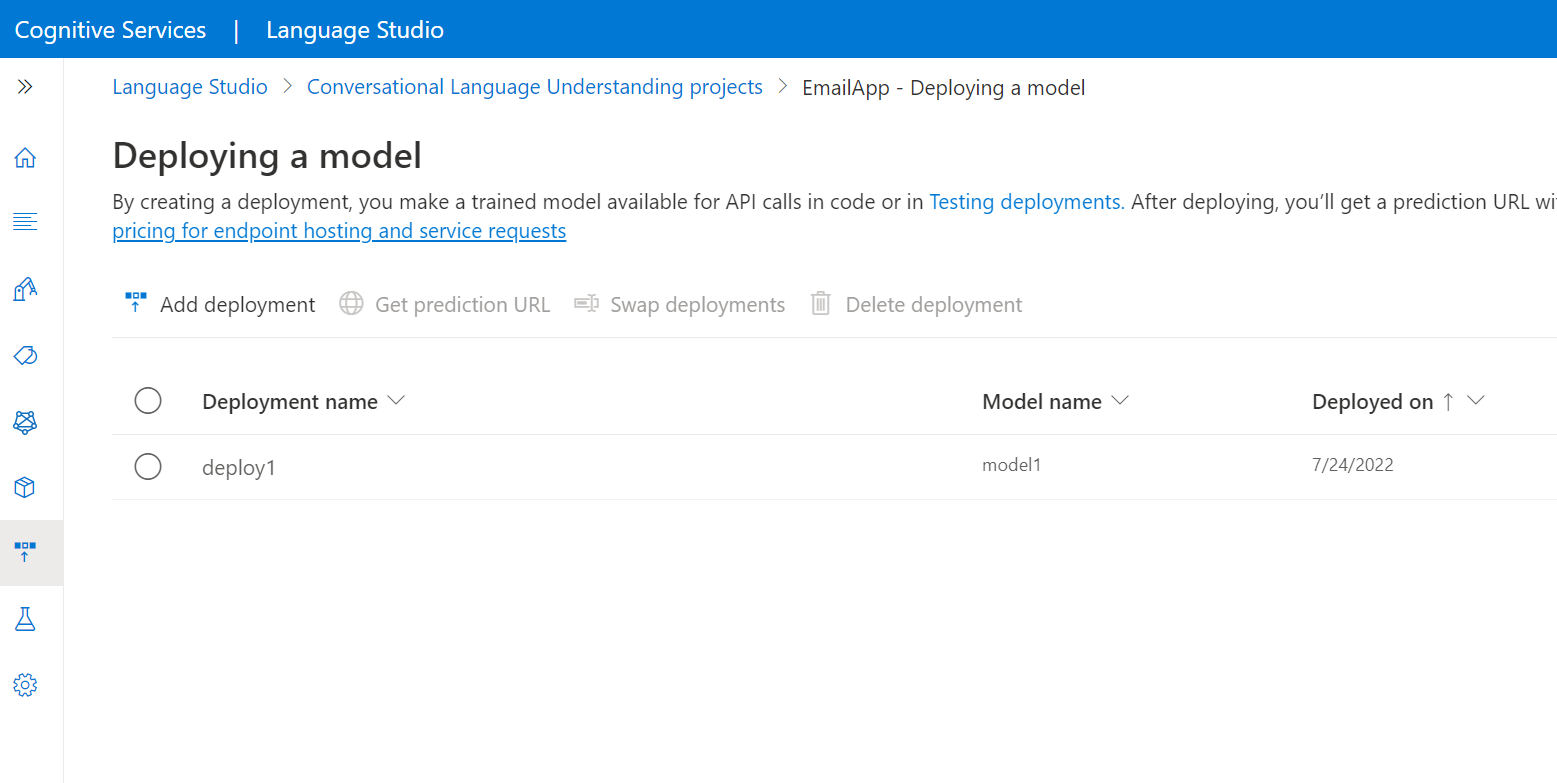
Selezionare Crea un nuovo nome di distribuzione per creare una nuova distribuzione e assegnare un modello sottoposto a training dall'elenco a discesa seguente. In alternativa, selezionare Sovrascrivi un nome di distribuzione esistente per sostituire effettivamente il modello usato da una distribuzione esistente.
Nota
La sovrascrittura di una distribuzione esistente non richiede modifiche alla chiamata API di previsione, ma i risultati ottenuti saranno basati sul modello appena assegnato.

Selezionare un modello sottoposto a training dall'elenco a discesa Modello.
Fare clic su Distribuisci per avviare il processo di distribuzione.
Al termine della distribuzione verrà visualizzata una data di scadenza. la scadenza della distribuzione si riferisce alla data in cui il modello distribuito non sarà disponibile per la previsione, che in genere si verifica dodici mesi dopo la scadenza di una configurazione di training.


Nella sezione successiva si useranno il nome del progetto e il nome della distribuzione.
Riconoscere le finalità da microfono
Seguire questi passaggi per creare una nuova applicazione console e installare Speech SDK.
Aprire un prompt dei comandi dove si vuole creare il nuovo progetto e creare un'applicazione console con l'interfaccia della riga di comando di .NET. Il file
Program.csdeve essere creato nella directory del progetto.dotnet new consoleInstallare Speech SDK nel nuovo progetto con l'interfaccia della riga di comando di .NET.
dotnet add package Microsoft.CognitiveServices.SpeechSostituire il contenuto di
Program.cscon il codice seguente.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }In
Program.csimpostare le variabilicluProjectNameecluDeploymentNamecon i nomi del progetto e della distribuzione. Per informazioni su come creare un progetto e una distribuzione CLU vedere Creare un progetto di comprensione del linguaggio di conversazione.Per modificare la lingua del riconoscimento vocale sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper Spagnolo (Spagna). La lingua predefinita èen-US, se non si specifica una lingua. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.
Eseguire la nuova applicazione console per avviare il riconoscimento vocale da microfono:
dotnet run
Importante
Assicurarsi di impostare le variabili di ambiente LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYe SPEECH_REGION come descritto sopra. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.
Parlare al microfono quando richiesto. Il parlato deve essere restituito come testo:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Nota
Il supporto per la risposta JSON per CLU tramite la proprietà LanguageUnderstandingServiceResponse_JsonResult è stato aggiunto in Speech SDK versione 1.26.
Le finalità vengono restituite seguendo l’ordine di probabilità dal più probabile al meno probabile. Ecco una versione formattata dell'output JSON in cui topIntent è HomeAutomation.TurnOn con un punteggio di attendibilità pari a 0,97712576 (97,71%). La seconda finalità più probabile potrebbe essere HomeAutomation.TurnOff con un punteggio di attendibilità pari a 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Osservazioni:
A completamento di questo avvio rapido, ecco alcune considerazioni:
- In questo esempio viene usata l'operazione
RecognizeOnceAsyncper trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato. - Per riconoscere il parlato da un file audio usare
FromWavFileInput, anzichéFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Per i file audio compressi, ad esempio MP4, installare GStreamer e usare
PullAudioInputStreamoPushAudioInputStream. Per altre informazioni vedere Come usare audio di input compresso.
Pulire le risorse
Per rimuovere la risorsa Voce e la risorsa di linguaggio create è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Documentazione di riferimento | Pacchetto (NuGet) | Ulteriori esempi in GitHub
In questo avvio rapido si useranno i servizi Voce e di linguaggio per riconoscere le finalità dei dati audio acquisiti da microfono. In particolare, si userà il servizio Voce per riconoscere la voce e un modello CLU (comprensione del linguaggio di conversazione) per identificare le finalità.
Importante
CLU (comprensione del linguaggio di conversazione) è disponibile per C# e C++ con Speech SDK versione 1.25 o successiva.
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa di linguaggio nel portale di Azure.
- Ottenere la chiave e l'endpoint della risorsa di linguaggio. Dopo aver distribuito la risorsa di linguaggio, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Speech SDK è disponibile come pacchetto NuGet e implementa .NET Standard 2.0. Speech SDK verrà installato più avanti in questa guida, ma innanzitutto controllare la guida all'installazione dell'SDK per eventuali altri requisiti.
Impostare le variabili di ambiente
Questo esempio richiede variabili di ambiente denominate LANGUAGE_KEY, LANGUAGE_ENDPOINT SPEECH_KEY e SPEECH_REGION.
L'applicazione deve essere autenticata per accedere alle risorse di Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
LANGUAGE_KEY, sostituireyour-language-keycon una delle chiavi della risorsa. - Per impostare la variabile di ambiente
LANGUAGE_ENDPOINT, sostituireyour-language-endpointcon una delle aree della risorsa. - Per impostare la variabile di ambiente
SPEECH_KEY, sostituireyour-speech-keycon una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituisciyour-speech-regioncon una delle aree della risorsa.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Nota
Se serve solo accedere alla variabile di ambiente nella console in esecuzione corrente, è possibile impostare la variabile di ambiente con set, anziché setx.
Dopo aver aggiunto le variabili di ambiente, potrebbe essere necessario riavviare tutti i programmi in esecuzione che dovranno leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Creare un progetto di comprensione del linguaggio di conversazione
Dopo aver creato una risorsa di linguaggio, creare un progetto di comprensione del linguaggio di conversazione in Studio del linguaggio. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa di linguaggio usata.
Passare a Language Studio e accedere con l'account Azure.
Creare un progetto di comprensione del linguaggio di conversazione
In questo avvio rapido è possibile scaricare questo progetto di esempio di domotica e importarlo. Questo progetto può prevedere i comandi previsti dall'input dell'utente, ad esempio, accendere e spegnere le luci.
In Studio del linguaggio nella sezione Comprendere le domande e il linguaggio di conversazioneselezionare Comprensione del linguaggio di conversazione.
Verrà visualizzata la pagina dei Progetti di comprensione del linguaggio di conversazione. Accanto al pulsante Crea nuovo progetto selezionare Importa.
Nella finestra visualizzata caricare il file JSON da importare. Assicurarsi che il file segua il formato JSON supportato.
Al termine del caricamento verrà visualizzata la pagina Definizione schema. In questo avvio rapido lo schema è già compilato e le espressioni sono già etichettate con finalità ed entità.
Eseguire il training del modello
In genere, dopo aver creato un progetto è necessario compilare uno schema ed etichettare le espressioni. In questo avvio rapido è già stato importato un progetto pronto con lo schema compilato e le espressioni etichettate.
Per eseguire il training di un modello è necessario avviare un processo di training. L'output di un processo di training corretto è il modello sottoposto a training.
Per avviare il training del modello dallo Studio del linguaggio:
Selezionare Esegui training del modello nel menu a sinistra.
Selezionare Avvia un processo di training nel menu in alto.
Selezionare Esegui training di un nuovo modello e digitare il nome di un modello nuovo nella casella di testo. In alternativa, per sostituire un modello esistente con uno sottoposto a training sui nuovi dati, selezionare Sovrascrivi un modello esistente e poi selezionare un modello esistente. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
Selezionare la modalità di training. È possibile scegliere Training standard per un training più rapido; anche se è disponibile solo in inglese. In alternativa, è possibile scegliere Training avanzato, che supporta altre lingue e progetti multilingue, ma comporta tempi di training più lunghi. Altre informazioni sulle modalità di training.
Selezionare il metodo di divisione dei dati. È possibile scegliere Divisione automatica del set di test dai dati di training: il sistema dividerà le espressioni tra il set di training e il set di test in base alle percentuali specificate. In alternativa, è possibile scegliere l’opzione Usa una divisione manuale dei dati di training e di testing che è abilitata solo se sono state aggiunte espressioni al set di test durante l’etichettatura delle espressioni.
Selezionare il pulsante Esegui il training.
Selezionare l'ID processo di training dall'elenco. Sarà visualizzato un riquadro in cui è possibile verificare lo stato del training, lo stato del processo e altri dettagli sul processo.
Nota
- Solo i processi di training completati correttamente genereranno modelli.
- Il training può richiedere da un paio di minuti a un paio d’ore, in base al numero di espressioni.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training nello stesso progetto fino al completamento del processo in esecuzione.
- L'apprendimento automatico usato per eseguire il training dei modelli viene aggiornato regolarmente. Per eseguire il training su una precedente versione di configurazione selezionare Selezionare qui per modificare nella pagina Avvia un processo di training e scegliere una versione precedente.
Distribuire il modello
In genere dopo il training di un modello, si esaminano i relativi dettagli di valutazione. In questo avvio rapido si distribuirà solo il modello e lo si renderà disponibile per la prova in Studio del linguaggio; in alternativa, è possibile effettuare la chiamata all' API di stima.
Per distribuire un modello all’interno di Studio di linguaggio:
Selezionare Distribuzione di un modello nel menu a sinistra.
Selezionare Aggiungi distribuzione per avviare la procedura guidata Aggiungi distribuzione.
Selezionare Crea un nuovo nome di distribuzione per creare una nuova distribuzione e assegnare un modello sottoposto a training dall'elenco a discesa seguente. In alternativa, selezionare Sovrascrivi un nome di distribuzione esistente per sostituire effettivamente il modello usato da una distribuzione esistente.
Nota
La sovrascrittura di una distribuzione esistente non richiede modifiche alla chiamata API di previsione, ma i risultati ottenuti saranno basati sul modello appena assegnato.
Selezionare un modello sottoposto a training dall'elenco a discesa Modello.
Fare clic su Distribuisci per avviare il processo di distribuzione.
Al termine della distribuzione verrà visualizzata una data di scadenza. la scadenza della distribuzione si riferisce alla data in cui il modello distribuito non sarà disponibile per la previsione, che in genere si verifica dodici mesi dopo la scadenza di una configurazione di training.
Nella sezione successiva si useranno il nome del progetto e il nome della distribuzione.
Riconoscere le finalità da microfono
Seguire questi passaggi per creare una nuova applicazione console e installare Speech SDK.
Creare un nuovo progetto console C++ in Visual Studio Community 2022 con il nome
SpeechRecognition.Installare Speech SDK nel nuovo progetto con gestione pacchetti NuGet.
Install-Package Microsoft.CognitiveServices.SpeechSostituire il contenuto di
SpeechRecognition.cppcon il codice seguente:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }In
SpeechRecognition.cppimpostare le variabilicluProjectNameecluDeploymentNamecon i nomi del progetto e della distribuzione. Per informazioni su come creare un progetto e una distribuzione CLU vedere Creare un progetto di comprensione del linguaggio di conversazione.Per modificare la lingua del riconoscimento vocale sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper Spagnolo (Spagna). La lingua predefinita èen-US, se non si specifica una lingua. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.
Compila ed esegui la nuova applicazione console per avviare il riconoscimento vocale da microfono.
Importante
Assicurarsi di impostare le variabili di ambiente LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYe SPEECH_REGION come descritto sopra. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.
Parlare al microfono quando richiesto. Il parlato deve essere restituito come testo:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Nota
Il supporto per la risposta JSON per CLU tramite la proprietà LanguageUnderstandingServiceResponse_JsonResult è stato aggiunto in Speech SDK versione 1.26.
Le finalità vengono restituite seguendo l’ordine di probabilità dal più probabile al meno probabile. Ecco una versione formattata dell'output JSON in cui topIntent è HomeAutomation.TurnOn con un punteggio di attendibilità pari a 0,97712576 (97,71%). La seconda finalità più probabile potrebbe essere HomeAutomation.TurnOff con un punteggio di attendibilità pari a 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Osservazioni:
A completamento di questo avvio rapido, ecco alcune considerazioni:
- In questo esempio viene usata l'operazione
RecognizeOnceAsyncper trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato. - Per riconoscere il parlato da un file audio usare
FromWavFileInput, anzichéFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Per i file audio compressi, ad esempio MP4, installare GStreamer e usare
PullAudioInputStreamoPushAudioInputStream. Per altre informazioni vedere Come usare audio di input compresso.
Pulire le risorse
Per rimuovere la risorsa Voce e la risorsa di linguaggio create è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
documentazione di riferimento | Esempi aggiuntivi in GitHub
Speech SDK per Java non supporta il riconoscimento delle finalità con CLU (comprensione del linguaggio di conversazione). Selezionare un altro linguaggio di programmazione o i riferimenti e gli esempi Java collegati all'inizio di questo articolo.