Distribuire un modello di riconoscimento vocale personalizzato
In questo articolo si apprende come distribuire un endpoint per un modello di riconoscimento vocale personalizzato. Fatta eccezione per la trascrizione batch, è necessario distribuire un endpoint personalizzato per usare un modello di riconoscimento vocale personalizzato.
Suggerimento
Per usare Riconoscimento vocale personalizzato con l'API di trascrizione batch non è necessario un endpoint di distribuzione ospitata. È possibile risparmiare risorse se il modello di conversione voce/testo personalizzato viene usato solo per la trascrizione batch. Per altre informazioni, vedere Prezzi del servizio Voce.
È possibile distribuire un endpoint per un modello di base o personalizzato e quindi aggiornare l'endpoint in un secondo momento per usare un modello con training migliore.
Nota
Gli endpoint usati dalle risorse Voce F0 vengono eliminati dopo sette giorni.
Aggiungere un endpoint di distribuzione
Per creare un endpoint personalizzato, seguire questa procedura:
Accedere a Speech Studio.
Selezionare Riconoscimento vocale personalizzato> Nome progetto >Distribuire modelli.
Se si tratta del primo endpoint, si noterà che nella tabella non ci sono endpoint elencati. Dopo aver creato un endpoint, usare questa pagina per tenere traccia di tutti gli endpoint distribuiti.
Selezionare Distribuisci modello per avviare la creazione guidata del nuovo endpoint.
Nella pagina Nuovo endpoint immettere un nome e una descrizione per l'endpoint personalizzato.
Selezionare il modello personalizzato che si desidera associare all'endpoint.
Facoltativamente, è possibile selezionare la casella per abilitare la registrazione audio e diagnostica del traffico dell'endpoint.
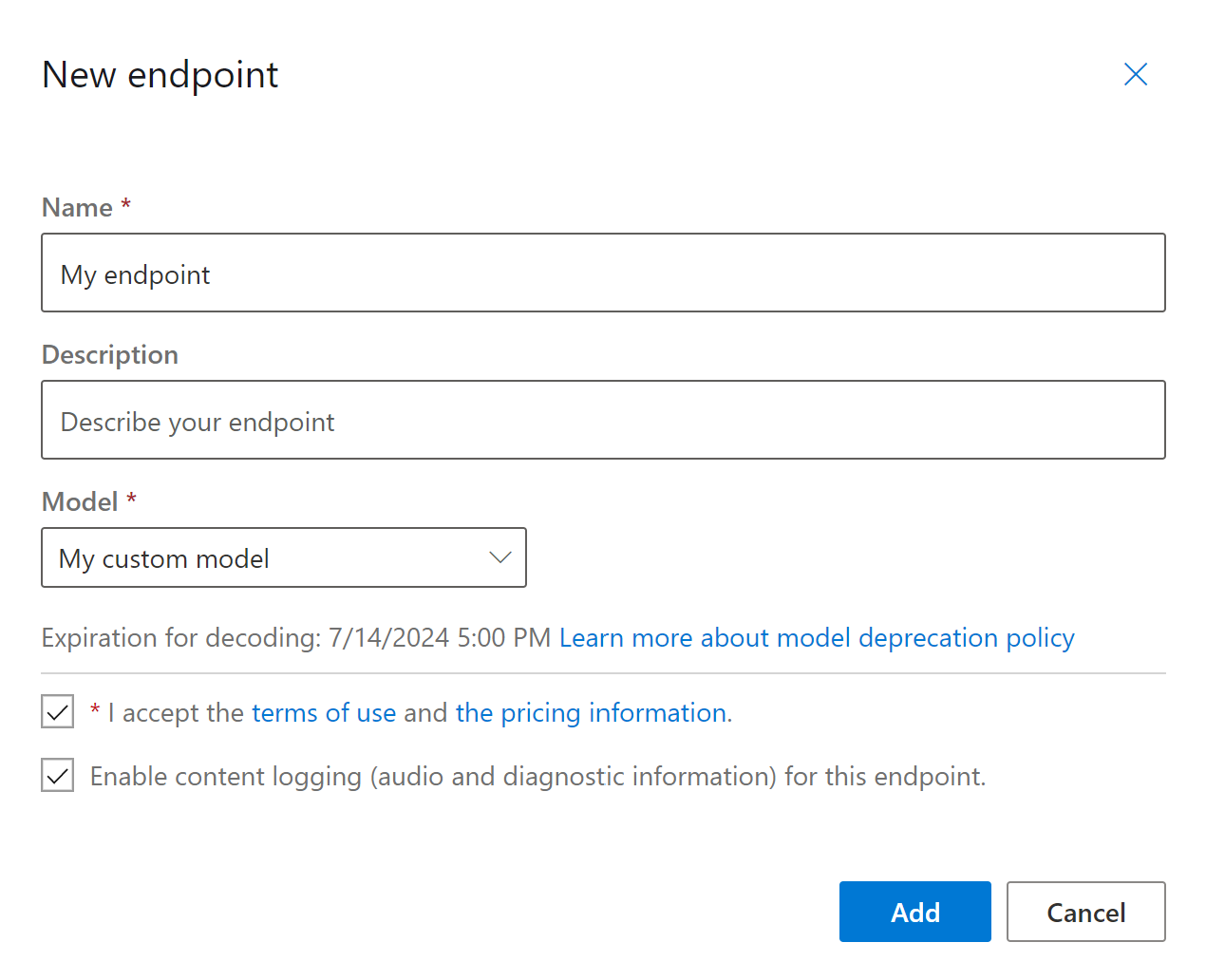
Selezionare Aggiungi per salvare e distribuire l'endpoint.
Nella pagina principale Distribuisci modelli i dettagli sul nuovo endpoint vengono visualizzati in una tabella, ad esempio nome, descrizione, stato e data di scadenza. La creazione di un'istanza del nuovo endpoint che usa i modelli personalizzati può richiedere fino a 30 minuti. Quando lo stato della distribuzione passa a Operazione completata, l'endpoint è pronto per l'uso.
Importante
Prendere nota della data di scadenza del modello. Questa è l'ultima data in cui è possibile usare il modello personalizzato per il riconoscimento vocale. Per altre informazioni, vedere Modello e ciclo di vita dell'endpoint.
Selezionare il collegamento all'endpoint per visualizzare informazioni specifiche, ad esempio la chiave dell'endpoint, l'URL dell'endpoint e il codice di esempio.
Per creare un endpoint e distribuire un modello, usare il comando spx csr endpoint create. Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare il parametro
projectsull'ID di un progetto esistente. Questa opzione è consigliata per consentire anche di visualizzare e gestire l'endpoint in Speech Studio. È possibile eseguire il comandospx csr project listper ottenere i progetti disponibili. - Impostare il parametro
modelobbligatorio sull'ID del modello che si vuole distribuire all'endpoint. - Impostare il parametro
languageobbligatorio. Le impostazioni locali dell'endpoint devono corrispondere alle impostazioni locali del modello. Le impostazioni locali non possono essere modificate in un secondo momento. Il parametrolanguagedell'interfaccia della riga di comando di Voce corrisponde alla proprietàlocalenella richiesta e nella risposta JSON. - Impostare il parametro
nameobbligatorio. Si tratta del nome che verrà visualizzato in Speech Studio. Il parametronamedell'interfaccia della riga di comando di Voce corrisponde alla proprietàdisplayNamenella richiesta e nella risposta JSON. - Facoltativamente, è possibile impostare il parametro
logging. Impostare questa opzione suenabledper abilitare la registrazione di audio e diagnostica del traffico dell'endpoint. Il valore predefinito èfalse.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce per creare un endpoint e distribuire un modello:
spx csr endpoint create --api-version v3.2 --project YourProjectId --model YourModelId --name "My Endpoint" --description "My Endpoint Description" --language "en-US"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd"
},
"links": {
"logs": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37/files/logs",
"restInteractive": "https://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restConversation": "https://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restDictation": "https://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketInteractive": "wss://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketConversation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketDictation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"loggingEnabled": true
},
"lastActionDateTime": "2024-07-15T16:29:36Z",
"status": "NotStarted",
"createdDateTime": "2024-07-15T16:29:36Z",
"locale": "en-US",
"displayName": "My Endpoint",
"description": "My Endpoint Description"
}
La proprietà di primo livello self nel corpo della risposta è l’URI dell’endpoint. Usare questo URI per ottenere informazioni dettagliate sul progetto, il modello e i log dell'endpoint. Usare anche questo URI per aggiornare l'endpoint.
Per ottenere la guida dell’interfaccia della riga di comando di Voce con gli endpoint, eseguire il comando seguente:
spx help csr endpoint
Per creare un endpoint e distribuire un modello, usare l'operazione Endpoints_Create dell'API REST Riconoscimento vocale in testo. Creare il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà
projectsull'URI di un progetto esistente. Questa opzione è consigliata per consentire anche di visualizzare e gestire l'endpoint in Speech Studio. È possibile effettuare una richiesta Projects_List per ottenere i progetti disponibili. - Impostare la proprietà
modelobbligatoria sull'URI del modello che si vuole distribuire nell'endpoint. - Impostare la proprietà
localeobbligatoria. Le impostazioni locali dell'endpoint devono corrispondere alle impostazioni locali del modello. Le impostazioni locali non possono essere modificate in un secondo momento. - Impostare la proprietà
displayNameobbligatoria. Si tratta del nome che verrà visualizzato in Speech Studio. - Facoltativamente, è possibile impostare le proprietà
loggingEnabledall'interno diproperties. Impostare sutrueper abilitare la registrazione audio e diagnostica del traffico dell'endpoint. Il valore predefinito èfalse.
Effettuare una richiesta HTTP POST usando l'URI come illustrato nell'esempio di Endpoints_Create seguente. Sostituire YourSubscriptionKey con la chiave della risorsa Voce e YourServiceRegion con l'area della risorsa Voce, quindi impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"loggingEnabled": true
},
"displayName": "My Endpoint",
"description": "My Endpoint Description",
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ae8d1643-53e4-4554-be4c-221dcfb471c5"
},
"locale": "en-US",
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd"
},
"links": {
"logs": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37/files/logs",
"restInteractive": "https://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restConversation": "https://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restDictation": "https://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketInteractive": "wss://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketConversation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketDictation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"loggingEnabled": true
},
"lastActionDateTime": "2024-07-15T16:29:36Z",
"status": "NotStarted",
"createdDateTime": "2024-07-15T16:29:36Z",
"locale": "en-US",
"displayName": "My Endpoint",
"description": "My Endpoint Description"
}
La proprietà di primo livello self nel corpo della risposta è l’URI dell’endpoint. Usare questo URI per ottenere informazioni dettagliate sul progetto, il modello e i log dell'endpoint. È anche possibile usare questo URI per aggiornare o eliminare l’endpoint.
Cambiare il modello e ridistribuire l’endpoint
Un endpoint può essere aggiornato per usare un altro modello creato dalla stessa risorsa Voce. Come accennato in precedenza, è necessario aggiornare il modello dell'endpoint prima della scadenza del modello.
Per usare un nuovo modello e ridistribuire l'endpoint personalizzato:
- Accedere a Speech Studio.
- Selezionare Riconoscimento vocale personalizzato> Nome progetto >Distribuire modelli.
- Selezionare il collegamento a un endpoint in base al nome e quindi selezionare Cambia modello.
- Selezionare il nuovo modello da usare per l'endpoint.
- Selezionare Fine per salvare e ridistribuire l'endpoint.
Per ridistribuire l'endpoint personalizzato con un nuovo modello, usare il comando spx csr model update. Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare il parametro
endpointobbligatorio sull'ID dell'endpoint che si vuole distribuire. - Impostare il parametro
modelobbligatorio sull'ID del modello che si vuole distribuire all'endpoint.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che ridistribuisce l'endpoint personalizzato con un nuovo modello:
spx csr endpoint update --api-version v3.2 --endpoint YourEndpointId --model YourModelId
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd"
},
"links": {
"logs": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37/files/logs",
"restInteractive": "https://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restConversation": "https://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restDictation": "https://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketInteractive": "wss://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketConversation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketDictation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"loggingEnabled": true
},
"lastActionDateTime": "2024-07-15T16:30:12Z",
"status": "Succeeded",
"createdDateTime": "2024-07-15T16:29:36Z",
"locale": "en-US",
"displayName": "My Endpoint",
"description": "My Endpoint Description"
}
Per ottenere la guida dell’interfaccia della riga di comando di Voce con gli endpoint, eseguire il comando seguente:
spx help csr endpoint
Per ridistribuire l'endpoint personalizzato con un nuovo modello, usare l'operazione di Endpoints_Update dell'API REST riconoscimento vocale. Creare il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà
modelsull'URI del modello che si vuole distribuire all'endpoint.
Effettuare una richiesta HTTP PATCH usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSubscriptionKey con la chiave della risorsa Voce, sostituire YourServiceRegion con l'area della risorsa Voce, sostituire YourEndpointId con l'ID endpoint e impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/YourEndpointId"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd"
},
"links": {
"logs": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37/files/logs",
"restInteractive": "https://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restConversation": "https://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restDictation": "https://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketInteractive": "wss://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketConversation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketDictation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"loggingEnabled": true
},
"lastActionDateTime": "2024-07-15T16:30:12Z",
"status": "Succeeded",
"createdDateTime": "2024-07-15T16:29:36Z",
"locale": "en-US",
"displayName": "My Endpoint",
"description": "My Endpoint Description"
}
La ridistribuzione richiede alcuni minuti. Nel frattempo, l'endpoint usa il modello precedente senza interruzioni del servizio.
Visualizzare i dati di registrazione
I dati di registrazione sono disponibili per l'esportazione se sono stati configurati durante la creazione dell'endpoint.
Per scaricare i log degli endpoint:
- Accedere a Speech Studio.
- Selezionare Riconoscimento vocale personalizzato> Nome progetto >Distribuire modelli.
- Selezionare il collegamento in base al nome dell'endpoint.
- In Registrazione contenuto selezionare Scarica log.
Per ottenere i log per un endpoint, usare il comando spx csr endpoint list. Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare il parametro
endpointobbligatorio sull'ID della trascrizione per cui si desidera recuperare i log.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che ottiene i log per un endpoint:
spx csr endpoint list --api-version v3.2 --endpoint YourEndpointId
I percorsi di ogni file di log con altri dettagli vengono restituiti nel corpo della risposta.
Per ottenere i log per un endpoint, iniziare usando l'operazione di Endpoints_Get dell'API REST riconoscimento vocale.
Effettuare una richiesta HTTP GET usando l'URI come illustrato nell'esempio seguente. Sostituire YourEndpointId con l'ID endpoint, sostituire YourSubscriptionKey con la chiave della risorsa Voce e sostituire YourServiceRegion con l'area della risorsa Voce.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/YourEndpointId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"model": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd"
},
"links": {
"logs": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/a07164e8-22d1-4eb7-aa31-bf6bb1097f37/files/logs",
"restInteractive": "https://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restConversation": "https://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"restDictation": "https://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketInteractive": "wss://eastus.stt.speech.microsoft.com/speech/recognition/interactive/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketConversation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37",
"webSocketDictation": "wss://eastus.stt.speech.microsoft.com/speech/recognition/dictation/cognitiveservices/v1?cid=a07164e8-22d1-4eb7-aa31-bf6bb1097f37"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"loggingEnabled": true
},
"lastActionDateTime": "2024-07-15T16:30:12Z",
"status": "Succeeded",
"createdDateTime": "2024-07-15T16:29:36Z",
"locale": "en-US",
"displayName": "My Endpoint",
"description": "My Endpoint Description"
}
Effettuare una richiesta HTTP GET usando l'URI "logs" del corpo della risposta precedente. Sostituire YourEndpointId con l'ID endpoint, sostituire YourSubscriptionKey con la chiave della risorsa Voce e sostituire YourServiceRegion con l'area della risorsa Voce.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/endpoints/YourEndpointId/files/logs" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
I percorsi di ogni file di log con altri dettagli vengono restituiti nel corpo della risposta.
I dati di registrazione sono disponibili nella risorsa di archiviazione di proprietà di Microsoft per 30 giorni e poi vengono rimossi. Se il proprio account di archiviazione è collegato alla sottoscrizione di Servizi di Azure AI, i dati di registrazione non vengono eliminati automaticamente.