Come valutare modelli e applicazioni di intelligenza artificiale generativi con Azure AI Foundry
Per valutare accuratamente le prestazioni dei modelli di intelligenza artificiale generativi e delle applicazioni quando applicati a un set di dati sostanziale, è possibile avviare un processo di valutazione. Durante questa valutazione, il modello o l'applicazione viene testata con il set di dati specificato e le relative prestazioni verranno misurate in modo quantitativo con metriche matematiche basate su intelligenza artificiale e metriche basate su intelligenza artificiale. L'esecuzione di questa valutazione offre informazioni dettagliate complete sulle funzionalità e sulle limitazioni dell'applicazione.
Per eseguire questa valutazione, è possibile usare la funzionalità di valutazione nel portale di Azure AI Foundry, una piattaforma completa che offre strumenti e funzionalità per valutare le prestazioni e la sicurezza del modello di intelligenza artificiale generativa. Nel portale di Azure AI Foundry è possibile registrare, visualizzare e analizzare metriche di valutazione dettagliate.
Questo articolo illustra come creare un'esecuzione di valutazione su un modello, un set di dati di test o un flusso con metriche di valutazione predefinite dall'interfaccia utente di Azure AI Foundry. Per una maggiore flessibilità, è possibile stabilire un flusso di valutazione personalizzato e usare la funzionalità di valutazione personalizzata. In alternativa, se l'obiettivo è eseguire soltanto un'esecuzione batch senza alcuna valutazione, è anche possibile usare la funzionalità di valutazione personalizzata.
Prerequisiti
Per eseguire una valutazione con le metriche basate sull'intelligenza artificiale, è necessario avere a disposizione quanto segue:
- Un set di dati di test in uno dei formati seguenti:
csvojsonl. - Connessione OpenAI di Azure: La distribuzione di uno di questi modelli: modello GPT 3.5, modello GPT 4 o modello Davinci. Obbligatorio solo quando si esegue la valutazione della qualità assistita dall'intelligenza artificiale.
Creare una valutazione con le metriche di valutazione predefinite
Un'esecuzione di valutazione consente di generare gli output delle metriche per ogni riga di dati nel set di dati di test. È possibile scegliere una o più metriche di valutazione per valutare l'output da diversi aspetti. È possibile creare un'esecuzione di valutazione dalle pagine di valutazione, catalogo di modelli o flusso di richieste nel portale di Azure AI Foundry. Viene quindi visualizzata una procedura guidata per la creazione della valutazione per guidare l'utente nel processo di configurazione di un'esecuzione di valutazione.
Nella pagina della valutazione
Dal menu a sinistra comprimibile selezionare Valutazione>+ Crea una nuova valutazione.

Dalla pagina del catalogo dei modelli
Dal menu a sinistra collapsible selezionare Catalogo> modelli passare a modello > specifico passare alla scheda > benchmark Provare con i propri dati. Verrà aperto il pannello di valutazione del modello per creare un'esecuzione di valutazione sul modello selezionato.

Nella pagina del flusso
Dal menu a sinistra collapsible selezionare Prompt flow>Evaluate Automated evaluation (Valuta>valutazione automatica).

Destinazione di valutazione
Quando si avvia una valutazione dalla pagina di valutazione, è dapprima necessario decidere qual è la destinazione di valutazione. Specificando il target di valutazione appropriato, è possibile personalizzare la valutazione in base alla natura specifica dell'applicazione, garantendo metriche accurate e pertinenti. Sono supportati tre tipi di destinazione di valutazione:
- Modello e richiesta: si vuole valutare l'output generato dal modello selezionato e dal prompt definito dall'utente.
- Set di dati: gli output generati dal modello sono già presenti in un set di dati di test.
- Prompt flow: è stato creato un flusso e si vuole valutare l'output proveniente da esso.

Set di dati o valutazione del flusso di richiesta
Quando si immette la creazione guidata della valutazione, è possibile specificare un nome facoltativo per l'esecuzione della valutazione. Attualmente è disponibile il supporto per lo scenario di query e risposta, progettato per le applicazioni che implicano la risposta alle query utente e la fornitura di risposte con o senza informazioni di contesto.
Facoltativamente, è possibile aggiungere descrizioni e tag alle esecuzioni di valutazione per migliorare organizzazione, contesto e facilità di recupero.
È anche possibile usare il pannello della Guida per controllare le domande frequenti e guidarsi tramite la procedura guidata.

Se si sta valutando un flusso di richiesta, è possibile selezionare il flusso da valutare. Se si avvia la valutazione dalla pagina Flusso, il flusso verrà selezionato automaticamente per la valutazione. Se si intende valutare un altro flusso, è possibile selezionarne un altro. È importante notare che all'interno di un flusso potrebbero essere presenti più nodi, ognuno dei quali potrebbe avere un proprio set di varianti. In questi casi, è necessario specificare il nodo e le varianti da valutare durante il processo di valutazione.

Configura i dati test
È possibile scegliere tra set di dati preesistenti o caricare un nuovo set di dati destinato in modo specifico alla valutazione. Il set di dati di test deve usare gli output generati dal modello per la valutazione se non è stato selezionato alcun flusso nel passaggio precedente.
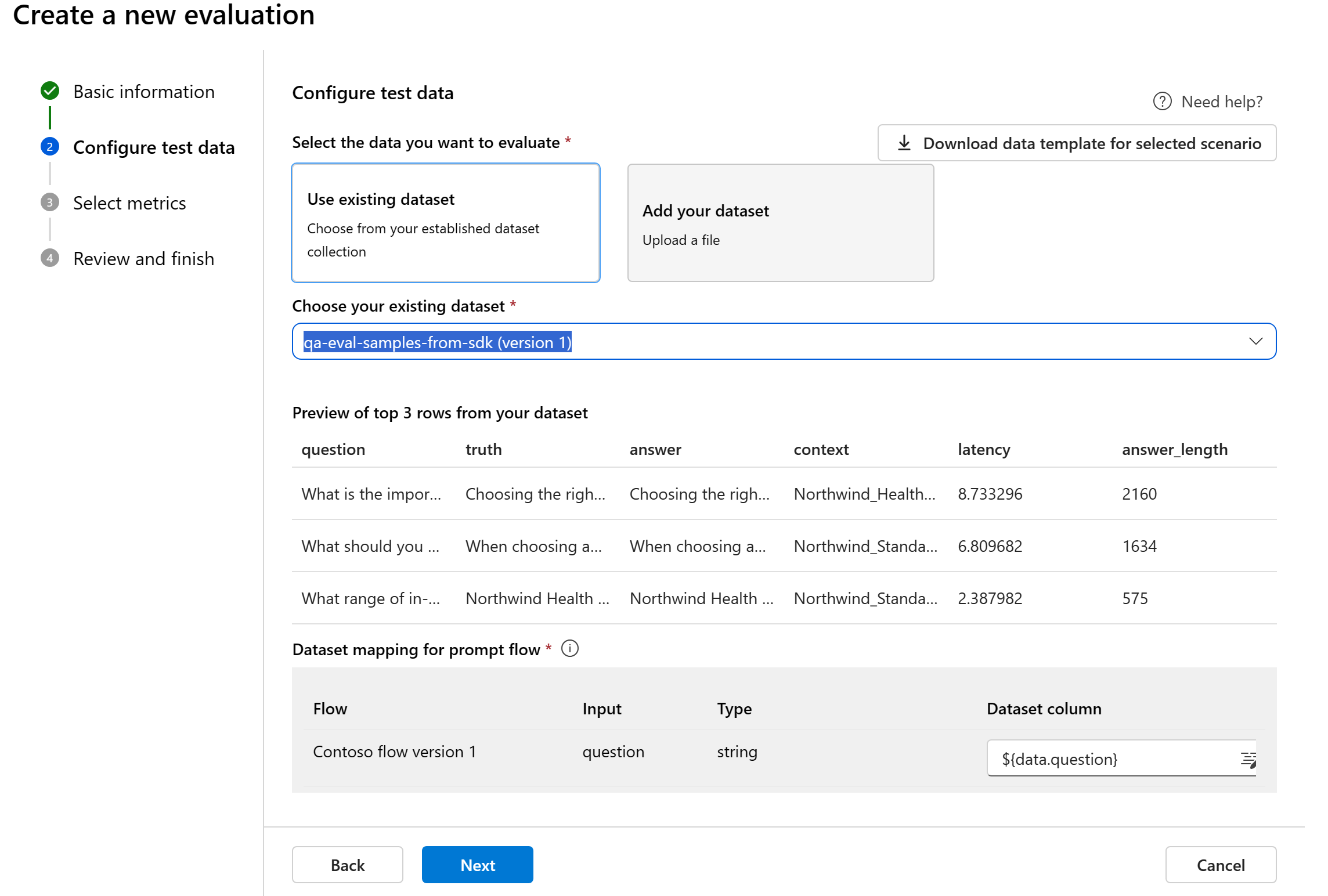
Scegliere un set di dati esistente: è possibile scegliere il set di dati di test dalla raccolta di set di dati stabilita.

Aggiungere un nuovo set di dati: è possibile caricare file dalla risorsa di archiviazione locale. Sono supportati solo i formati di file
.csve.jsonl.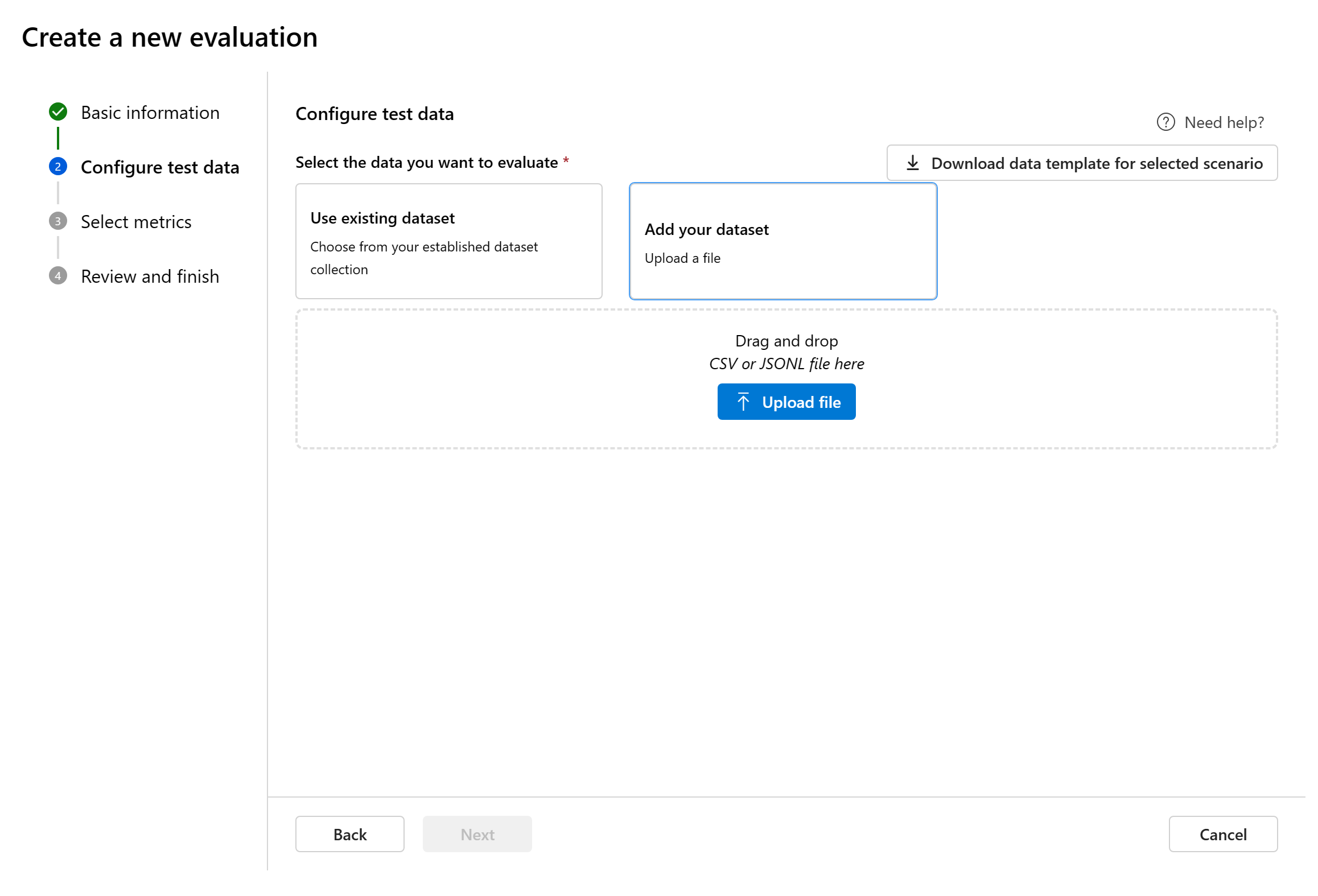
Mapping dei dati per il flusso: se si seleziona un flusso da valutare, assicurarsi che le colonne di dati siano configurate per l'allineamento con gli input necessari al flusso per eseguire un'esecuzione batch, generando l'output per la valutazione. La valutazione verrà quindi eseguita usando l'output del flusso. Quindi, configurare il mapping dei dati per gli input della valutazione nel passaggio successivo.



Seleziona metriche
Microsoft supporta tre tipi di metriche curate da Microsoft per facilitare una valutazione completa dell'applicazione:
- Qualità dell'intelligenza artificiale (intelligenza artificiale assistita): queste metriche valutano la qualità complessiva e la coerenza del contenuto generato. Per eseguire queste metriche, è necessaria una distribuzione del modello come giudice.
- Qualità dell'intelligenza artificiale (NLP): queste metriche NLP sono basate su matematica e valutano anche la qualità complessiva del contenuto generato. Spesso richiedono dati di verità sul terreno, ma non richiedono la distribuzione del modello come giudice.
- Metriche di rischio e di sicurezza: queste metriche sono dedicate all'identificazione di potenziali rischi relativi ai contenuti e garantiscono la sicurezza del contenuto generato.

È possibile fare riferimento alla tabella per l'elenco completo delle metriche supportate in ogni scenario. Per informazioni più approfondite su ogni definizione di metrica e su come viene calcolata, vedere Valutazione e monitoraggio delle metriche.
| Qualità dell'IA (intelligenza artificiale assistita) | Qualità dell'intelligenza artificiale (NLP) | Metriche di rischio e di sicurezza |
|---|---|---|
| Base, rilevanza, coerenza, fluenza, somiglianza GPT | Punteggio F1, ROUGE, punteggio, punteggio BLEU, punteggio GLEU, punteggio METEOR | Contenuti correlati all'autolesionismo, contenuti di odio e ingiustizia, contenuti violenti, contenuti sessuali, materiale protetto, attacco indiretto |
Quando si esegue la valutazione della qualità assistita dall'intelligenza artificiale, è necessario specificare un modello GPT per il processo di calcolo. Scegliere una connessione OpenAI di Azure e una distribuzione con GPT-3.5, GPT-4 o il modello Davinci per i calcoli.

Le metriche di qualità dell'intelligenza artificiale (NLP) sono misurazioni matematiche basate su calcoli che valutano le prestazioni dell'applicazione. Spesso richiedono dati di verità sul terreno per il calcolo. ROUGE è una famiglia di metriche. È possibile selezionare il tipo ROUGE per calcolare i punteggi. Vari tipi di metriche ROUGE offrono modi per valutare la qualità della generazione di testo. ROUGE-N misura la sovrapposizione di n-grammi tra i testi candidati e di riferimento.

Per le metriche di rischio e sicurezza, non è necessario fornire una connessione e una distribuzione. Il servizio back-end delle valutazioni di sicurezza del portale di Azure AI Foundry effettua il provisioning di un modello GPT-4 che può generare punteggi di gravità del rischio di contenuto e ragionamento per consentire di valutare l'applicazione in caso di danni al contenuto.
È possibile impostare la soglia per calcolare la percentuale di difetti per le metriche relative ai danni causati dai contenuti (contenuti correlati all'autolesionismo, contenuti di odio e ingiustizia, contenuti violenti, contenuti sessuali). Il tasso di difetti viene calcolato prendendo una percentuale di istanze con livelli di gravità (molto bassa, bassa, media, alta) al di sopra di una soglia. Per impostazione predefinita, la soglia viene impostata su "Media".
Per il materiale protetto e l'attacco indiretto, la percentuale di difetti viene calcolata prendendo una percentuale di istanze in cui l'output è "true" (Percentuale di difetto = (#trues /#instances) × 100).

Nota
Le metriche di sicurezza e rischio assistito dall'intelligenza artificiale sono ospitate dal servizio back-end di valutazione della sicurezza di Azure AI Foundry ed è disponibile solo nelle aree seguenti: Stati Uniti orientali 2, Francia centrale, Regno Unito meridionale, Svezia centrale
Mapping dei dati per la valutazione: è necessario specificare le colonne di dati nel set di dati corrispondenti agli input necessari nella valutazione. Metriche di valutazione diverse richiedono tipi distinti di input di dati per ottenere calcoli accurati.

Nota
Se si esegue la valutazione dai dati, "response" deve eseguire il mapping alla colonna di risposta nel set di dati ${data$response}. Se si sta valutando dal flusso, "response" deve provenire dall'output ${run.outputs.response}del flusso.
Per indicazioni sui requisiti specifici per il mapping dei dati per ogni metrica, fare riferimento alle informazioni fornite nella tabella:
Requisiti delle metriche di query e risposta
| Metric | Query | Response | Contesto | Verità di base |
|---|---|---|---|---|
| Allineamento | Obbligatorio: Str | Obbligatorio: Str | Obbligatorio: Str | N/D |
| Coerenza | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
| Scorrevolezza | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
| Pertinenza | Obbligatorio: Str | Obbligatorio: Str | Obbligatorio: Str | N/D |
| Somiglianza GPT | Obbligatorio: Str | Obbligatorio: Str | N/D | Obbligatorio: Str |
| Punteggio F1 | N/D | Obbligatorio: Str | N/D | Obbligatorio: Str |
| Punteggio BLEU | N/D | Obbligatorio: Str | N/D | Obbligatorio: Str |
| Punteggio GLEU | N/D | Obbligatorio: Str | N/D | Obbligatorio: Str |
| Punteggio METEOR | N/D | Obbligatorio: Str | N/D | Obbligatorio: Str |
| Punteggio ROUGE | N/D | Obbligatorio: Str | N/D | Obbligatorio: Str |
| Contenuto correlato ad autolesionismo | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
| Contenuto odioso e fazioso | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
| Contenuto violento | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
| Contenuto sessuale | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
| Materiale protetto | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
| Attacco indiretto | Obbligatorio: Str | Obbligatorio: Str | N/D | N/D |
- Query: query che cerca informazioni specifiche.
- Risposta: risposta alla query generata dal modello.
- Contesto: l'origine generata dalla risposta rispetto a (ovvero, i documenti di base)...
- Verità sul terreno: la risposta alla query generata dall'utente/umano come risposta vera.
Verifica e termina
Dopo aver completato tutte le configurazioni necessarie, è possibile esaminare e procedere selezionando "Invia" per inviare l'esecuzione della valutazione.

Modello e richiesta di valutazione
Per creare una nuova valutazione per la distribuzione del modello selezionata e la richiesta definita, usare il pannello di valutazione del modello semplificato. Questa interfaccia semplificata consente di configurare e avviare valutazioni all'interno di un unico pannello consolidato.
Informazioni di base
Per iniziare, è possibile configurare il nome per l'esecuzione della valutazione. Selezionare quindi la distribuzione del modello da valutare. Sono supportati sia i modelli OpenAI di Azure che altri modelli aperti compatibili con i modelli Model-as-a-Service (MaaS), ad esempio i modelli della famiglia Meta Llama e Phi-3. Facoltativamente, è possibile modificare i parametri del modello, ad esempio la risposta massima, la temperatura e la parte superiore P in base alle esigenze.
Nella casella di testo Messaggio di sistema specificare il prompt per lo scenario. Per altre informazioni su come creare la richiesta, vedere il catalogo dei prompt. È possibile scegliere di aggiungere un esempio per mostrare alla chat le risposte desiderate. Tenterà di simulare le risposte aggiunte qui per assicurarsi che corrispondano alle regole disposte nel messaggio di sistema.

Configurare i dati di test
Dopo aver configurato il modello e richiesto, configurare il set di dati di test che verrà usato per la valutazione. Questo set di dati verrà inviato al modello per generare risposte per la valutazione. Sono disponibili tre opzioni per la configurazione dei dati di test:
- Generare dati di esempio
- Usare il set di dati esistente
- Aggiungere il set di dati
Se non si dispone di un set di dati prontamente disponibile e si vuole eseguire una valutazione con un piccolo esempio, è possibile selezionare l'opzione per usare un modello GPT per generare domande di esempio in base all'argomento scelto. L'argomento consente di personalizzare il contenuto generato in base all'area di interesse. Le query e le risposte verranno generate in tempo reale ed è possibile rigenerarle in base alle esigenze.
Nota
Il set di dati generato verrà salvato nell'archivio BLOB del progetto dopo la creazione dell'esecuzione della valutazione.

Mapping dei dati
Se si sceglie di usare un set di dati esistente o caricare un nuovo set di dati, sarà necessario eseguire il mapping delle colonne del set di dati ai campi necessari per la valutazione. Durante la valutazione, la risposta del modello verrà valutata in base agli input chiave, ad esempio:
- Query: obbligatorio per tutte le metriche
- Contesto: facoltativo
- Ground Truth: facoltativo, obbligatorio per le metriche di qualità dell'intelligenza artificiale (NLP)
Questi mapping garantiscono un allineamento accurato tra i dati e i criteri di valutazione.

Scegliere le metriche di valutazione
L'ultimo passaggio consiste nel selezionare gli elementi da valutare. Invece di selezionare singole metriche e di acquisire familiarità con tutte le opzioni disponibili, è possibile semplificare il processo consentendo di selezionare le categorie di metriche più adatte alle proprie esigenze. Quando si sceglie una categoria, tutte le metriche pertinenti all'interno di tale categoria verranno calcolate in base alle colonne di dati fornite nel passaggio precedente. Dopo aver selezionato le categorie di metriche, è possibile selezionare "Crea" per inviare l'esecuzione della valutazione e passare alla pagina di valutazione per visualizzare i risultati.
Sono supportate tre categorie:
- Qualità dell'intelligenza artificiale (intelligenza artificiale assistita): è necessario fornire una distribuzione del modello OpenAI di Azure come giudice per calcolare le metriche assistita dall'intelligenza artificiale.
- Qualità dell'intelligenza artificiale (NLP)
- Sicurezza
| Qualità dell'IA (intelligenza artificiale assistita) | Qualità dell'intelligenza artificiale (NLP) | Sicurezza |
|---|---|---|
| Groundedness (require context), Relevance (require context), Coerenza, Fluency | Punteggio F1, ROUGE, punteggio, punteggio BLEU, punteggio GLEU, punteggio METEOR | Contenuti correlati all'autolesionismo, contenuti di odio e ingiustizia, contenuti violenti, contenuti sessuali, materiale protetto, attacco indiretto |
Creare una valutazione con un flusso di valutazione personalizzato
È possibile sviluppare metodi di valutazione personalizzati:
Dalla pagina del flusso: dal menu comprimibile a sinistra, selezionare Prompt flow>Valuta>Valutazione personalizzata.

Visualizzare e gestire i valutatori nella libreria valutatori
La libreria valutatori è una posizione centralizzata che consente di visualizzare i dettagli e lo stato dei valutatori. È possibile visualizzare e gestire i valutatori curati da Microsoft.
Suggerimento
È possibile utilizzare valutatori personalizzati tramite l'SDK del prompt flow. Per altre informazioni, vedere Valutare con l'SDK del prompt flow.
La libreria valutatori consente anche la gestione delle versioni. È possibile confrontare versioni diverse del lavoro, ripristinare versioni precedenti, se necessario, e collaborare con altri utenti più facilmente.
Per usare la libreria dell'analizzatore nel portale di Azure AI Foundry, passare alla pagina Valutazione del progetto e selezionare la scheda Libreria analizzatore.

È possibile selezionare il nome del valutatore per visualizzare altri dettagli. È possibile visualizzare il nome, la descrizione e i parametri, oltre a controllare i file associati al valutatore. Ecco alcuni esempi di valutatori curati da Microsoft:
- Per i valutatori di prestazioni e qualità curati da Microsoft, è possibile visualizzare il prompt di annotazione nella pagina dei dettagli. È possibile adattare queste richieste al proprio caso d'uso modificando i parametri o i criteri in base ai dati e agli obiettivi di Azure AI Evaluation SDK. Ad esempio, è possibile selezionare Groundedness-Evaluator e controllare il file Prompty che mostra come calcolare la metrica.
- Per i valutatori di rischi e sicurezza curati da Microsoft, è possibile visualizzare la definizione delle metriche. Ad esempio, è possibile selezionare Self-Harm-Related-Content-Evaluator e scoprire cosa significa e come Microsoft determina i vari livelli di gravità per questa metrica di sicurezza.
Passaggi successivi
Altre informazioni su come valutare le applicazioni di intelligenza artificiale generative:
- Valutare le app di intelligenza artificiale generativa tramite il playground
- Visualizzare i risultati della valutazione
- Altre informazioni sulle tecniche di mitigazione dei danni.
- Nota sulla trasparenza per le valutazioni di sicurezza di Azure AI Foundry.