Scale-out di Azure Analysis Services
Con la scalabilità orizzontale, le query client possono essere distribuite tra più repliche di query in un pool di query, riducendo i tempi di risposta durante carichi di lavoro di query elevati. È anche possibile separare l'elaborazione dal pool di query, assicurandosi che le query client non siano influenzate negativamente dalle operazioni di elaborazione. Il ridimensionamento orizzontale può essere configurato nel portale di Azure o tramite l'API REST di Analysis Services.
Il ridimensionamento orizzontale è disponibile per i server del piano tariffario Standard. Ogni replica di query viene fatturata alla stessa tariffa del server. Tutte le repliche di query vengono create nella stessa area del server. Il numero di repliche di query che è possibile configurare dipende dall'area in cui risiede il server. Per altre informazioni, vedere Disponibilità per area geografica. La scalabilità orizzontale non aumenta la quantità di memoria disponibile per il server. Per aumentare la memoria, è necessario aggiornare il piano.
Perché aumentare il numero di istanze?
In una distribuzione di server tipica, un server funge sia da server di elaborazione che da server di query. Se il numero di query client verso i modelli presenti nel server supera il numero di unità di elaborazione query (QPU, Query Processing Unit) del piano del server o se l'elaborazione dei modelli avviene contemporaneamente a carichi di lavoro di query elevati, le prestazioni possono peggiorare.
Con la scalabilità orizzontale, è possibile creare un pool di query con fino a sette risorse di replica di query (otto totali, incluso il server primario ). È possibile ridimensionare il numero di repliche nel pool di query per soddisfare le richieste di QPU nei momenti critici ed è possibile separare un server di elaborazione dal pool di query in qualsiasi momento.
Indipendentemente dal numero di repliche di query presenti in un pool di query, i carichi di lavoro di elaborazione non vengono distribuiti tra le repliche di query. Il server primario funge da server di elaborazione. Le repliche di query gestiscono solo query sui database modello sincronizzati tra il server primario e ogni replica nel pool di query.
Quando si aumenta il numero di istanze, possono essere necessari fino a cinque minuti prima che le nuove repliche di query vengano aggiunte in modo incrementale al pool di query. Quando tutte le nuove repliche di query sono in esecuzione, le nuove connessioni client vengono bilanciate tra le risorse nel pool di query. Le connessioni client esistenti non vengono modificate dalla risorsa a cui sono attualmente connesse. Quando si aumenta il numero di istanze, tutte le connessioni client esistenti a una risorsa del pool di query che viene rimossa dal pool di query vengono terminate. I client possono riconnettersi a una risorsa del pool di query rimanente.
Funzionamento
Quando si configura la scalabilità orizzontale per la prima volta, i database modello nel server primario vengono sincronizzati automaticamente con nuove repliche in un nuovo pool di query. La sincronizzazione automatica viene eseguita una sola volta. Durante la sincronizzazione automatica, i file di dati del server primario (crittografati inattivi nell'archivio BLOB) vengono copiati in un secondo percorso, crittografati anche inattivi nell'archiviazione BLOB. Le repliche nel pool di query vengono quindi idratate con i dati del secondo set di file.
Mentre viene eseguita una sincronizzazione automatica solo quando si aumenta il numero di istanze di un server per la prima volta, è anche possibile eseguire una sincronizzazione manuale. La sincronizzazione assicura che i dati nelle repliche nel pool di query corrispondano a quello del server primario. Durante l'elaborazione (aggiornamento) dei modelli nel server primario, è necessario eseguire una sincronizzazione al termine delle operazioni di elaborazione. Questa sincronizzazione copia i dati aggiornati dai file del server primario nell'archivio BLOB al secondo set di file. Le repliche nel pool di query vengono quindi idratate con i dati aggiornati dal secondo set di file nell'archiviazione BLOB.
Quando si esegue un'operazione di scalabilità orizzontale successiva, ad esempio aumentando il numero di repliche nel pool di query da due a cinque, le nuove repliche vengono idratate con i dati del secondo set di file nell'archiviazione BLOB. Non esiste alcuna sincronizzazione. Se si esegue una sincronizzazione dopo l'aumento del numero di istanze, le nuove repliche nel pool di query verranno idratate due volte, ovvero un'idratazione ridondante. Quando si esegue un'operazione di scalabilità orizzontale successiva, è importante tenere presente quanto segue:
Eseguire una sincronizzazione prima dell'operazione di scalabilità orizzontale per evitare l'idratazione ridondante delle repliche aggiunte. Le operazioni simultanee di sincronizzazione e scalabilità orizzontale in esecuzione contemporaneamente non sono consentite.
Quando si automatizzano sia l'elaborazione che le operazioni di scalabilità orizzontale, è importante elaborare prima i dati nel server primario, quindi eseguire una sincronizzazione e quindi eseguire l'operazione di scalabilità orizzontale. Questa sequenza garantisce un impatto minimo sulle risorse di QPU e memoria.
Durante le operazioni di scalabilità orizzontale, tutti i server nel pool di query, incluso il server primario, sono temporaneamente offline.
La sincronizzazione è consentita anche quando non sono presenti repliche nel pool di query. Se si passa da zero a una o più repliche con nuovi dati da un'operazione di elaborazione nel server primario, eseguire prima la sincronizzazione senza repliche nel pool di query e quindi aumentare il numero di istanze. La sincronizzazione prima della scalabilità orizzontale evita l'idratazione ridondante delle repliche appena aggiunte.
Quando si elimina un database modello dal server primario, non viene eliminato automaticamente dalle repliche nel pool di query. È necessario eseguire un'operazione di sincronizzazione usando il comando PowerShell Sync-AzAnalysisServicesInstance, che rimuove i file per tale database dal percorso di archiviazione BLOB condiviso della replica e quindi elimina il database modello nelle repliche nel pool di query. Per determinare se un database modello esiste nelle repliche nel pool di query ma non nel server primario, verificare che l'impostazione Separare il server di elaborazione dall'impostazione pool di query sia su Sì. Usare quindi SQL Server Management Studio (SSMS) per connettersi al server primario usando il
:rwqualificatore per verificare se il database esiste. Connettersi quindi alle repliche nel pool di query connettendosi senza il:rwqualificatore per verificare se lo stesso database esiste anche. Se il database esiste nelle repliche nel pool di query ma non nel server primario, eseguire un'operazione di sincronizzazione.Quando si rinomina un database nel server primario, è necessario un altro passaggio per assicurarsi che il database sia sincronizzato correttamente con qualsiasi replica. Dopo la ridenominazione, eseguire una sincronizzazione usando il comando Sync-AzAnalysisServicesInstance che specifica il
-Databaseparametro con il nome del database precedente. Questa sincronizzazione rimuove il database e i file con il nome precedente da qualsiasi replica. Eseguire quindi un'altra sincronizzazione specificando il-Databaseparametro con il nuovo nome del database. La seconda sincronizzazione copia il database appena denominato nel secondo set di file e idrata tutte le repliche. Queste sincronizzazioni non possono essere eseguite usando il comando Synchronize model (Sincronizza modello) nel portale.
Modalità di sincronizzazione
Per impostazione predefinita, le repliche di query vengono riattivate in modo completo e non incrementale. La riattivazione avviene in fasi. Vengono scollegati e collegati due alla volta (presupponendo che ci siano almeno tre repliche) per garantire che almeno una replica venga mantenuta online per le query in qualsiasi momento. In alcuni casi, i client potrebbero dover riconnettersi a una delle repliche online durante l'esecuzione di questo processo. Usando l'impostazione ReplicaSyncMode , è ora possibile specificare la sincronizzazione della replica di query in parallelo. La sincronizzazione parallela offre i vantaggi seguenti:
- Riduzione significativa del tempo di sincronizzazione.
- È più probabile che i dati tra repliche siano coerenti durante il processo di sincronizzazione.
- I database vengono mantenuti online in tutte le repliche per l'intera durata del processo di sincronizzazione, quindi i client non devono ripetere la connessione.
- La cache in memoria viene aggiornata in modo incrementale solo con i dati modificati, che possono essere più veloci rispetto alla riattivazione completa del modello.
Impostazione di ReplicaSyncMode
Usare SSMS per impostare ReplicaSyncMode in Proprietà avanzate. I valori possibili sono:
1(impostazione predefinita): riattivazione completa del database di replica in fasi (incrementale).2: sincronizzazione ottimizzata in parallelo.
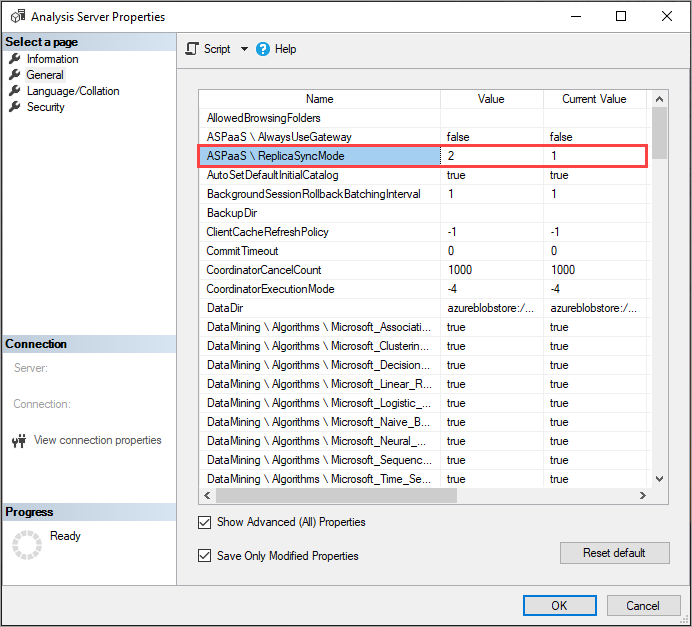
Quando si imposta ReplicaSyncMode=2, a seconda della quantità di cache da aggiornare, è possibile utilizzare una quantità maggiore di memoria dalle repliche di query. Per mantenere online il database e disponibile per le query, a seconda della quantità di dati modificati, l'operazione può richiedere fino a raddoppiare la memoria nella replica perché i segmenti vecchi e nuovi vengono mantenuti contemporaneamente in memoria. I nodi di replica hanno la stessa allocazione di memoria del nodo primario ed è normalmente disponibile memoria aggiuntiva nel nodo primario per le operazioni di aggiornamento, quindi potrebbe non essere probabile che le repliche esauriscano la memoria. Inoltre, lo scenario comune è che il database viene aggiornato in modo incrementale nel nodo primario e pertanto il requisito per il doppio della memoria deve essere insolito. Se l'operazione di sincronizzazione rileva un errore di memoria insufficiente, ritenta l'uso della tecnica predefinita (collegamento/scollegamento di due alla volta).
Separare l'elaborazione dal pool di query
Per ottenere prestazioni ottimali sia delle operazioni di elaborazione che delle operazioni di query, è possibile scegliere di separare il server di elaborazione dal pool di query. In caso di separazione, le nuove connessioni client vengono assegnate solo alle repliche di query nel pool di query. Se le operazioni di elaborazione richiedono pochi minuti, è possibile scegliere di separare il server di elaborazione dal pool di query solo per il tempo necessario per eseguire le operazioni di elaborazione e sincronizzazione e quindi includerlo nuovamente nel pool di query. La separazione del server di elaborazione dal pool di query o l'aggiunta al pool di query può richiedere fino a cinque minuti per il completamento dell'operazione.
Monitorare l'utilizzo di QPU
Per determinare se è necessario aumentare il numero di istanze per il server, monitorare le metriche del server nel portale di Azure. Se le QPU si esauriscono regolarmente, significa che il numero di query verso i modelli supera il limite di QPU per il piano. La metrica relativa alla lunghezza della coda dei processi del pool di query aumenta anche quando il numero di query nella coda del pool di thread di query supera le QPU disponibili.
Un'altra buona metrica da controllare è la media QPU di ServerResourceType. Questa metrica confronta la media di QPU per il server primario con il pool di query.
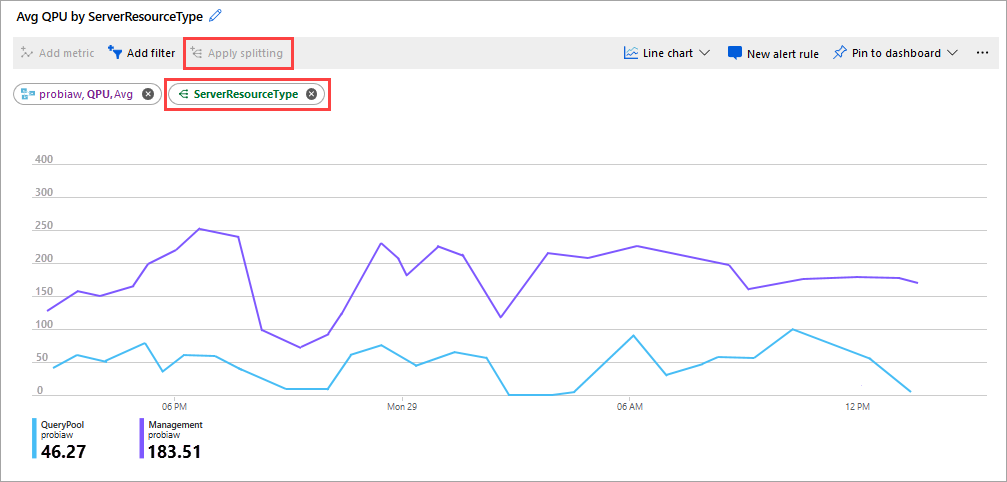
Per configurare QPU by ServerResourceType
- In un grafico a linee metriche fare clic su Aggiungi metrica.
- In RISORSA selezionare il server, quindi in SPAZIO DEI NOMI DELLE METRICHE selezionare Metriche standard di Analysis Services, quindi in METRICA selezionare QPU e quindi in AGGREGAZIONE selezionare Media.
- Fare clic su Applica suddivisione.
- In VALORI selezionare ServerResourceType.
Registrazione diagnostica dettagliata
Usare i log di Monitoraggio di Azure per una diagnostica più dettagliata delle risorse del server con scalabilità orizzontale. Con i log, è possibile usare le query di Log Analytics per suddividere QPU e memoria in base al server e alla replica. Per altre informazioni, vedere Analizzare i log nell'area di lavoro Log Analytics. Per le query di esempio, vedere Query Kusto di esempio.
Configurare l'aumento del numero di istanze
Nel portale di Azure
Nel portale fare clic su Scale-out. Usare il dispositivo di scorrimento per selezionare il numero di server di replica di query. Il numero di repliche scelto viene aggiunto al server esistente.
In Separare il server di elaborazione dal pool di query selezionare Sì per escludere il server di elaborazione dal server di query. Le connessioni client che usano il stringa di connessione predefinito (senza
:rw) vengono reindirizzate alle repliche nel pool di query.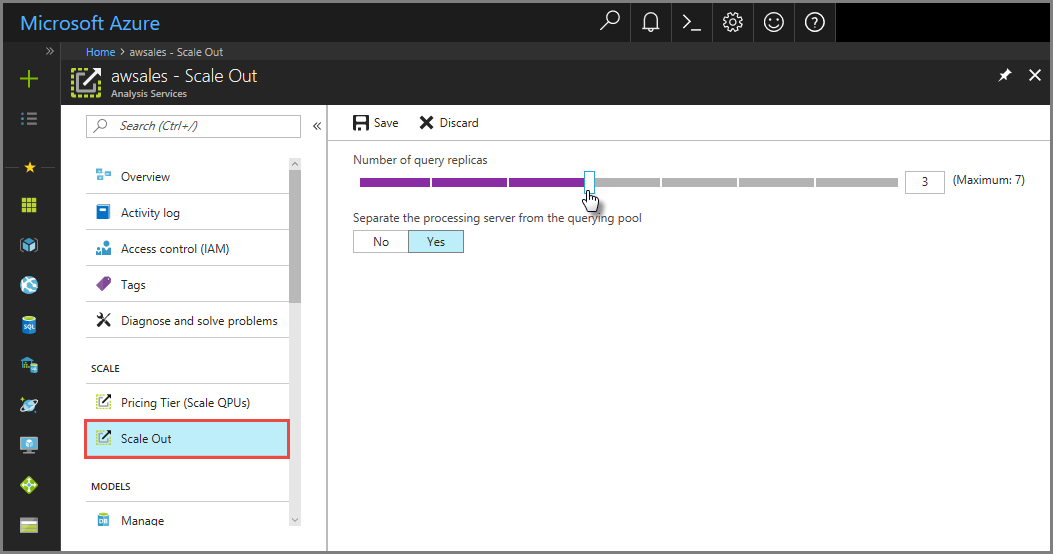
Fare clic su Salva per effettuare il provisioning dei nuovi server di replica di query.
Quando si configura la scalabilità orizzontale per un server la prima volta, i modelli nel server primario vengono sincronizzati automaticamente con le repliche nel pool di query. La sincronizzazione automatica viene eseguita una sola volta, quando si configura per la prima volta la scalabilità orizzontale in una o più repliche. Le modifiche successive al numero di repliche nello stesso server non attivano un'altra sincronizzazione automatica. La sincronizzazione automatica non si verifica di nuovo anche se si imposta il server su zero repliche e quindi si aumenta nuovamente il numero di repliche.
Sincronizza
Le operazioni di sincronizzazione devono essere eseguite manualmente o tramite l'API REST.
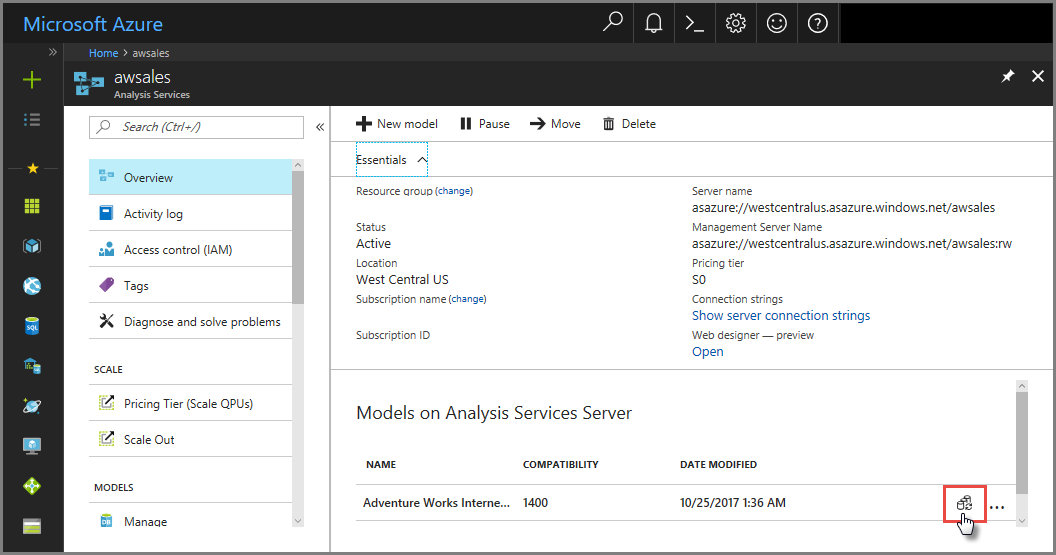
Nel portale di Azure
In Panoramica> modello >Sincronizza modello.
REST API
Usare l'operazione sync.
Sincronizzare un modello
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Ottenere lo stato di sincronizzazione
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Restituire i codici di stato:
| Codice | Descrizione |
|---|---|
| -1 | Non valido |
| 0 | Replica |
| 1 | Riattivazione |
| 2 | Completato |
| 3 | Non riuscito |
| 4 | Finalizzazione |
PowerShell
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Prima di usare PowerShell, installare o aggiornare il modulo di Azure PowerShell più recente.
Per eseguire la sincronizzazione, usare Sync-AzAnalysisServicesInstance.
Per impostare il numero di repliche di query, usare Set-AzAnalysisServicesServer. Specificare il parametro facoltativo -ReadonlyReplicaCount.
Per separare il server di elaborazione dal pool di query, usare Set-AzAnalysisServicesServer. Specificare il parametro facoltativo -DefaultConnectionMode da usare Readonly.
Per altre informazioni, vedere Uso di un'entità servizio con il modulo Az.AnalysisServices.
Connessioni
Nella pagina Panoramica del server sono presenti due nomi di server. Se il ridimensionamento orizzontale non è stato ancora configurato per un server, entrambi i nomi di server funzionano allo stesso modo. Dopo che per un server è stato configurato il ridimensionamento orizzontale, è necessario specificare il nome del server appropriato a seconda del tipo di connessione.
Per le connessioni client destinate agli utenti finali, ad esempio Power BI Desktop, Excel e le applicazioni personalizzate, usare il nome del server.
Per SSMS, Visual Studio e stringa di connessione in PowerShell, app per le funzioni di Azure e AMO, usare il nome del server di gestione. Il nome del server di gestione include un qualificatore (lettura e scrittura) :rw speciale. Tutte le operazioni di elaborazione vengono eseguite nel server di gestione (primario).
Aumento delle prestazioni, riduzione delle prestazioni e scalabilità orizzontale
È possibile modificare il piano tariffario in un server con più repliche. Lo stesso piano tariffario si applica a tutte le repliche. Un'operazione di scalabilità riduce prima tutte le repliche contemporaneamente e quindi tutte le repliche vengono visualizzate nel nuovo piano tariffario.
Risoluzione dei problemi
Problema: gli utenti ricevono un errore non riescono a trovare il server '<Nome dell'istanza del server>' in modalità di connessione 'ReadOnly'.
Soluzione: quando si seleziona l'opzione Separare il server di elaborazione dall'opzione pool di query, le connessioni client che usano il stringa di connessione predefinito (senza :rw) vengono reindirizzate alle repliche del pool di query. Se le repliche nel pool di query non sono ancora online perché la sincronizzazione non è ancora stata completata, le connessioni client reindirizzate possono non riuscire. Quando si esegue una sincronizzazione, per evitare errori di connessione, nel pool di query devono essere presenti almeno due server. Ogni server viene sincronizzato singolarmente, mentre gli altri rimangono online. Se si sceglie di non tenere il server di elaborazione all'interno del pool di query durante l'elaborazione, è possibile rimuoverlo dal pool per l'elaborazione e quindi riaggiungerlo al termine di questa, ma prima della sincronizzazione. Usare le metriche di memoria e di QPU per monitorare lo stato della sincronizzazione.
Informazioni correlate
Monitorare Azure Analysis ServicesGestire Azure Analysis Services