Nei passaggi precedenti della soluzione Retrieval-Augmented Generation (RAG) i documenti sono stati suddivisi in blocchi e sono stati arricchiti i blocchi. In questo passaggio vengono generati incorporamenti per i blocchi e i campi dei metadati in cui si prevede di eseguire ricerche vettoriali.
Questo articolo fa parte di una serie. Leggere l'introduzione .
Un incorporamento è una rappresentazione matematica di un oggetto, ad esempio testo. Quando viene eseguito il training di una rete neurale, vengono create molte rappresentazioni di un oggetto. Ogni rappresentazione ha connessioni ad altri oggetti nella rete. Un incorporamento è importante perché acquisisce il significato semantico dell'oggetto.
La rappresentazione di un oggetto ha connessioni a rappresentazioni di altri oggetti, in modo da poter confrontare gli oggetti matematicamente. L'esempio seguente illustra come gli incorporamenti acquisiscono il significato semantico e le relazioni tra loro:
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
Gli incorporamenti vengono confrontati tra loro usando le nozioni di somiglianza e distanza. La griglia seguente mostra un confronto tra incorporamenti.

In una soluzione RAG spesso si incorpora la query utente usando lo stesso modello di incorporamento dei blocchi. Quindi, si cerca nel database i vettori pertinenti per restituire i blocchi più rilevanti a livello semantico. Il testo originale dei blocchi pertinenti viene passato al modello linguistico come dati di base.
Nota
I vettori rappresentano il significato semantico del testo in modo da consentire un confronto matematico. È necessario pulire i blocchi in modo che la prossimità matematica tra vettori rifletta accuratamente la pertinenza semantica.
Importanza del modello di incorporamento
Il modello di incorporamento scelto può influire significativamente sulla pertinenza dei risultati della ricerca vettoriale. È necessario considerare il vocabolario del modello di incorporamento. Ogni modello di incorporamento viene sottoposto a training con un vocabolario specifico. Ad esempio, le dimensioni del vocabolario del modello BERT sono circa 30.000 parole.
Il vocabolario di un modello di incorporamento è importante perché gestisce parole che non sono nel suo vocabolario in modo univoco. Se una parola non è presente nel vocabolario del modello, calcola comunque un vettore. A tale scopo, molti modelli suddivideno le parole in parole secondarie. Considerano le parole secondarie come token distinti oppure aggregano i vettori per le parole secondarie per creare un singolo incorporamento.
Ad esempio, la parola istamina potrebbe non trovarsi nel vocabolario di un modello di incorporamento. La parola istamina ha un significato semantico come una sostanza chimica che il corpo rilascia, che causa sintomi di allergia. Il modello di incorporamento non contiene istamina. Quindi, potrebbe separare la parola in parole secondarie che sono nel suo vocabolario, ad esempio il suo, tae mio.

I significati semantici di queste parole secondarie sono lontani dal significato di istamina. I valori vettoriali singoli o combinati delle parole secondarie generano corrispondenze di vettore più scarse rispetto a se
Scegliere un modello di incorporamento
Determinare il modello di incorporamento corretto per il caso d'uso. Si consideri la sovrapposizione tra il vocabolario del modello di incorporamento e le parole dei dati quando si sceglie un modello di incorporamento.

Prima di tutto, determinare se si dispone di contenuto specifico del dominio. Ad esempio, i documenti sono specifici di un caso d'uso, dell'organizzazione o di un settore? Un buon modo per determinare la specificità del dominio consiste nel verificare se è possibile trovare le entità e le parole chiave nel contenuto su Internet. Se possibile, anche un modello di incorporamento generale può essere.
Contenuto generale o non specifico del dominio
Quando si sceglie un modello di incorporamento generale, iniziare con la classifica Hugging Face. Ottenere up-toclassificazioni dei modelli di incorporamento data. Valutare il funzionamento dei modelli con i dati e iniziare con i modelli di rango superiore.
Contenuto specifico del dominio
Per il contenuto specifico del dominio, determinare se è possibile usare un modello specifico del dominio. Ad esempio, i dati potrebbero trovarsi nel dominio biomedico, quindi è possibile usare il modello bioGPT . Questo modello linguistico è pre-addestrato su una vasta raccolta di letteratura biomedica. È possibile usarlo per il data mining e la generazione di testo biomedico. Se sono disponibili modelli specifici del dominio, valutare il funzionamento di questi modelli con i dati.
Se non si dispone di un modello specifico del dominio o se il modello specifico del dominio non funziona correttamente, è possibile ottimizzare un modello di incorporamento generale con il vocabolario specifico del dominio.
Importante
Per qualsiasi modello scelto, è necessario verificare che la licenza soddisfi le proprie esigenze e che il modello fornisca il supporto linguistico necessario.
Valutare i modelli di incorporamento
Per valutare un modello di incorporamento, visualizzare gli incorporamenti e valutare la distanza tra i vettori della domanda e del blocco.
Visualizzare gli incorporamenti
È possibile usare librerie, ad esempio t-SNE, per tracciare i vettori per i blocchi e la domanda su un grafico X-Y. È quindi possibile determinare la distanza tra i blocchi l'uno dall'altro e dalla domanda. Il grafico seguente mostra i vettori di blocchi tracciati. Le due frecce che si avvicinano l'una all'altra rappresentano due vettori di blocchi. L'altra freccia rappresenta un vettore di domanda. È possibile usare questa visualizzazione per comprendere quanto lontano la domanda proviene dai blocchi.
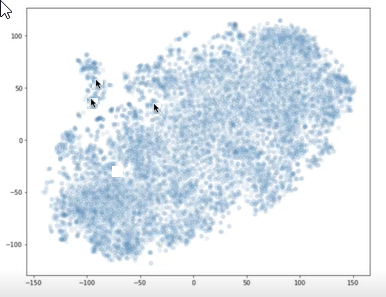
Due frecce puntano a tracciare punti uno vicino all'altro e un'altra freccia mostra un punto di tracciato lontano dagli altri due.
Calcolare le distanze di incorporamento
È possibile usare un metodo programmatico per valutare il funzionamento del modello di incorporamento con le domande e i blocchi. Calcolare la distanza tra i vettori di domanda e i vettori di blocchi. È possibile utilizzare la distanza euclidea o la distanza di Manhattan.
Incorporamento dell'economia
Quando si sceglie un modello di incorporamento, è necessario spostarsi tra prestazioni e costi. I modelli di incorporamento di grandi dimensioni hanno in genere prestazioni migliori sui set di dati di benchmarking. Tuttavia, l'aumento delle prestazioni comporta un aumento dei costi. I vettori di grandi dimensioni richiedono più spazio in un database vettoriale. Richiedono anche più risorse di calcolo e tempo per confrontare gli incorporamenti. I modelli di incorporamento di piccole dimensioni hanno in genere prestazioni inferiori sugli stessi benchmark. Richiedono meno spazio nel database vettoriale e meno calcolo e tempo per confrontare gli incorporamenti.
Quando si progetta il sistema, è consigliabile considerare il costo dell'incorporamento in termini di archiviazione, calcolo e requisiti di prestazioni. È necessario convalidare le prestazioni dei modelli tramite la sperimentazione. I benchmark disponibili pubblicamente sono principalmente set di dati accademici e potrebbero non essere applicati direttamente ai dati aziendali e ai casi d'uso. A seconda dei requisiti, è possibile favorire le prestazioni rispetto al costo o accettare un compromesso di prestazioni sufficienti per un costo inferiore.