Un'architettura di Big Data è progettata per gestire l'inserimento, l'elaborazione e l'analisi dei dati troppo grandi o complessi per i sistemi di database tradizionali.

Le soluzioni Big Data in genere coinvolgono uno o più dei tipi di carico di lavoro seguenti:
- Elaborazione batch di origini Big Data inattive.
- Elaborazione in tempo reale dei Big Data in movimento.
- Esplorazione interattiva dei Big Data.
- Analisi predittiva e Machine Learning.
La maggior parte delle architetture di Big Data include alcuni o tutti i componenti seguenti:
origini dati: tutte le soluzioni Big Data iniziano con una o più origini dati. Gli esempi includono:
- Archivi dati dell'applicazione, ad esempio database relazionali.
- File statici prodotti dalle applicazioni, ad esempio file di log del server Web.
- Origini dati in tempo reale, ad esempio dispositivi IoT.
archiviazione dati: i dati per le operazioni di elaborazione batch vengono in genere archiviati in un archivio file distribuito che può contenere volumi elevati di file di grandi dimensioni in vari formati. Questo tipo di archivio viene spesso chiamato data lake . Le opzioni per l'implementazione di questa risorsa di archiviazione includono Azure Data Lake Store o contenitori BLOB in Archiviazione di Azure.
l'elaborazione batch: poiché i set di dati sono così grandi, spesso una soluzione Big Data deve elaborare i file di dati usando processi batch a esecuzione prolungata per filtrare, aggregare e preparare in altro modo i dati per l'analisi. In genere questi processi comportano la lettura dei file di origine, l'elaborazione e la scrittura dell'output in nuovi file. Le opzioni includono l'uso di flussi di dati, pipeline di dati in Microsoft Fabric.
inserimento di messaggi in tempo reale: se la soluzione include origini in tempo reale, l'architettura deve includere un modo per acquisire e archiviare messaggi in tempo reale per l'elaborazione dei flussi. Potrebbe trattarsi di un archivio dati semplice, in cui i messaggi in arrivo vengono rilasciati in una cartella per l'elaborazione. Tuttavia, molte soluzioni richiedono un archivio di inserimento messaggi per fungere da buffer per i messaggi e per supportare l'elaborazione con scalabilità orizzontale, il recapito affidabile e altre semantiche di accodamento dei messaggi. Le opzioni includono Hub eventi di Azure, hub IoT di Azure e Kafka.
l'elaborazione del flusso: dopo l'acquisizione di messaggi in tempo reale, la soluzione deve elaborarli filtrando, aggregando e preparando in altro modo i dati per l'analisi. I dati del flusso elaborati vengono quindi scritti in un sink di output. Analisi di flusso di Azure offre un servizio di elaborazione dei flussi gestito basato su query SQL in esecuzione perpetua che operano su flussi non associati. Un'altra opzione consiste nell'usare l'intelligence in tempo reale in Microsoft Fabric che consente di eseguire query KQL durante l'inserimento dei dati.
archivio dati analitici: molte soluzioni Big Data preparano i dati per l'analisi e quindi gestiscono i dati elaborati in un formato strutturato su cui è possibile eseguire query usando gli strumenti analitici. L'archivio dati analitici usato per gestire queste query può essere un data warehouse relazionale in stile Kimball, come illustrato nella maggior parte delle soluzioni di business intelligence (BI) tradizionali o in una lakehouse con architettura medallion (Bronze, Silver e Gold). Azure Synapse Analytics offre un servizio gestito per il data warehousing basato su cloud su larga scala. In alternativa, Microsoft Fabric offre entrambe le opzioni, warehouse e lakehouse, che possono essere eseguite rispettivamente tramite SQL e Spark.
Analisi e creazione di report: l'obiettivo della maggior parte delle soluzioni Big Data è fornire informazioni dettagliate sui dati tramite analisi e creazione di report. Per consentire agli utenti di analizzare i dati, l'architettura può includere un livello di modellazione dei dati, ad esempio un cubo OLAP multidimensionale o un modello di dati tabulare in Azure Analysis Services. Potrebbe anche supportare la business intelligence self-service, usando le tecnologie di modellazione e visualizzazione in Microsoft Power BI o Microsoft Excel. L'analisi e la creazione di report possono anche assumere la forma di esplorazione interattiva dei dati da parte di data scientist o analisti di dati. Per questi scenari, Microsoft Fabric offre strumenti come notebook in cui l'utente può scegliere SQL o un linguaggio di programmazione preferito.
orchestrazione: la maggior parte delle soluzioni Big Data consiste in operazioni ripetute di elaborazione dei dati, incapsulate nei flussi di lavoro, che trasformano i dati di origine, spostano i dati tra più origini e sink, caricano i dati elaborati in un archivio dati analitici o eseguono il push dei risultati direttamente in un report o in un dashboard. Per automatizzare questi flussi di lavoro, è possibile usare una tecnologia di orchestrazione, ad esempio Azure Data Factory o pipeline di Microsoft Fabric.
Azure include molti servizi che possono essere usati in un'architettura di Big Data. Rientrano approssimativamente in due categorie:
- Servizi gestiti, tra cui Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Analisi di flusso di Azure, Hub eventi di Azure, Hub IoT di Azure e Azure Data Factory.
- Tecnologie open source basate sulla piattaforma Apache Hadoop, tra cui HDFS, HBase, Hive, Spark e Kafka. Queste tecnologie sono disponibili in Azure nel servizio Azure HDInsight.
Queste opzioni non si escludono a vicenda e molte soluzioni combinano tecnologie open source con i servizi di Azure.
Quando usare questa architettura
Prendere in considerazione questo stile di architettura quando è necessario:
- Archiviare ed elaborare i dati in volumi troppo grandi per un database tradizionale.
- Trasformare i dati non strutturati per l'analisi e la creazione di report.
- Acquisire, elaborare e analizzare flussi di dati non associati in tempo reale o con bassa latenza.
- Usare Azure Machine Learning o Servizi cognitivi di Azure.
Benefici
- Scelte tecnologico. È possibile combinare e abbinare i servizi gestiti di Azure e le tecnologie Apache nei cluster HDInsight per sfruttare le competenze o gli investimenti tecnologici esistenti.
- prestazioni tramite parallelismo. Le soluzioni Big Data sfruttano il parallelismo, consentendo soluzioni ad alte prestazioni che si adattano a grandi volumi di dati.
- scala elastica. Tutti i componenti dell'architettura big data supportano il provisioning con scalabilità orizzontale, in modo da poter modificare la soluzione in carichi di lavoro di piccole o grandi dimensioni e pagare solo per le risorse usate.
- l'interoperabilità con le soluzioni esistenti. I componenti dell'architettura dei Big Data vengono usati anche per l'elaborazione IoT e le soluzioni di business intelligence aziendali, consentendo di creare una soluzione integrata tra carichi di lavoro di dati.
Sfide
- complessità. Le soluzioni Big Data possono essere estremamente complesse, con numerosi componenti per gestire l'inserimento dei dati da più origini dati. Può essere difficile compilare, testare e risolvere i problemi dei processi di Big Data. Inoltre, può essere presente un numero elevato di impostazioni di configurazione in più sistemi che devono essere usati per ottimizzare le prestazioni.
- set di competenze. Molte tecnologie Big Data sono altamente specializzate e usano framework e linguaggi che non sono tipici di architetture applicative più generali. D'altra parte, le tecnologie Big Data stanno evolvendo nuove API che si basano su linguaggi più consolidati.
- Maturità tecnologica. Molte delle tecnologie usate in Big Data sono in continua evoluzione. Anche se le principali tecnologie Hadoop come Hive e Spark si sono stabilizzate, le tecnologie emergenti come delta o iceberg introducono notevoli cambiamenti e miglioramenti. I servizi gestiti come Microsoft Fabric sono relativamente giovani, rispetto ad altri servizi di Azure e probabilmente si evolveranno nel tempo.
- Security. Le soluzioni Big Data si basano in genere sull'archiviazione di tutti i dati statici in un data lake centralizzato. La protezione dell'accesso a questi dati può risultare complessa, soprattutto quando i dati devono essere inseriti e utilizzati da più applicazioni e piattaforme.
Procedure consigliate
Sfruttare il parallelismo. La maggior parte delle tecnologie di elaborazione dei Big Data distribuisce il carico di lavoro tra più unità di elaborazione. Ciò richiede che i file di dati statici vengano creati e archiviati in un formato splittable. I file system distribuiti, ad esempio HDFS, possono ottimizzare le prestazioni di lettura e scrittura e l'elaborazione effettiva viene eseguita da più nodi del cluster in parallelo, riducendo così i tempi complessivi del processo. È consigliabile usare un formato di dati splitable, ad esempio Parquet.
Dati della partizione. L'elaborazione batch avviene in genere in base a una pianificazione ricorrente, ad esempio settimanale o mensile. Partizionare i file di dati e le strutture di dati, ad esempio tabelle, in base a periodi temporali che corrispondono alla pianificazione dell'elaborazione. Ciò semplifica l'inserimento dei dati e la pianificazione dei processi e semplifica la risoluzione degli errori. Inoltre, le tabelle di partizionamento usate nelle query Hive, Spark o SQL possono migliorare significativamente le prestazioni delle query.
Applicare la semantica di lettura dello schema. L'uso di un data lake consente di combinare l'archiviazione per i file in più formati, strutturati, semistrutturati o non strutturati. Usare semantica di di lettura dello schema, che proietta uno schema sui dati durante l'elaborazione dei dati, non quando vengono archiviati i dati. Ciò consente di creare flessibilità nella soluzione e di evitare colli di bottiglia durante l'inserimento dei dati causati dalla convalida dei dati e dal controllo dei tipi.
Elaborare i dati sul posto. Le soluzioni bi tradizionali usano spesso un processo di estrazione, trasformazione e caricamento (ETL) per spostare i dati in un data warehouse. Con volumi più grandi e una maggiore varietà di formati, le soluzioni Big Data usano in genere variazioni di ETL, ad esempio trasformazione, estrazione e caricamento (TEL). Con questo approccio, i dati vengono elaborati all'interno dell'archivio dati distribuito, trasformandolo nella struttura richiesta, prima di spostare i dati trasformati in un archivio dati analitici.
Bilanciare i costi di utilizzo e tempo. Per i processi di elaborazione batch, è importante considerare due fattori: il costo per unità dei nodi di calcolo e il costo al minuto dell'uso di tali nodi per completare il processo. Ad esempio, un processo batch può richiedere otto ore con quattro nodi del cluster. Tuttavia, potrebbe risultare che il processo usa tutti e quattro i nodi solo durante le prime due ore e successivamente sono necessari solo due nodi. In tal caso, l'esecuzione dell'intero processo in due nodi aumenterebbe il tempo totale del processo, ma non la raddoppierebbe, quindi il costo totale sarebbe minore. In alcuni scenari aziendali, un tempo di elaborazione più lungo può essere preferibile al costo più elevato dell'uso di risorse cluster sottoutilizzate.
Risorse separate. Quando possibile, mirare a separare le risorse in base ai carichi di lavoro per evitare scenari come un carico di lavoro usando tutte le risorse mentre altre sono in attesa.
orchestrare l'inserimento dati. In alcuni casi, le applicazioni aziendali esistenti possono scrivere file di dati per l'elaborazione batch direttamente nei contenitori BLOB di archiviazione di Azure, in cui possono essere usati da servizi downstream come Microsoft Fabric. Tuttavia, spesso sarà necessario orchestrare l'inserimento di dati da origini dati locali o esterne nel data lake. Usare un flusso di lavoro di orchestrazione o una pipeline, ad esempio quelli supportati da Azure Data Factory o Microsoft Fabric, per ottenere questo risultato in modo prevedibile e gestibile centralmente.
Eseguire lo scrubing dei dati sensibili nelle prime. Il flusso di lavoro di inserimento dati deve eseguire lo scrubing dei dati sensibili all'inizio del processo, per evitare di archiviarli nel data lake.
Architettura IoT
Internet delle cose (IoT) è un subset specializzato di soluzioni Big Data. Il diagramma seguente mostra una possibile architettura logica per IoT. Il diagramma evidenzia i componenti di streaming di eventi dell'architettura.
diagramma 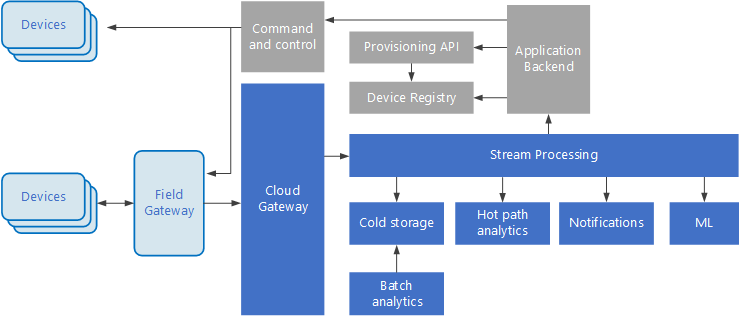
Il gateway cloud inserisce gli eventi del dispositivo al limite del cloud, usando un sistema di messaggistica affidabile e a bassa latenza.
I dispositivi possono inviare eventi direttamente al gateway cloud o tramite un gateway sul campo . Un gateway sul campo è un dispositivo o un software specializzato, in genere racchiuso con i dispositivi, che riceve gli eventi e li inoltra al gateway cloud. Il gateway sul campo può anche pre-elaborare gli eventi del dispositivo non elaborati, eseguendo funzioni come il filtro, l'aggregazione o la trasformazione del protocollo.
Dopo l'inserimento, gli eventi passano attraverso uno o più processori di flusso che possono instradare i dati (ad esempio, all'archiviazione) o eseguire analisi e altre elaborazioni.
Di seguito sono riportati alcuni tipi comuni di elaborazione. (Questo elenco non è certamente esaustivo.
Scrittura dei dati degli eventi nell'archiviazione ad accesso sporadico, per l'archiviazione o l'analisi batch.
Analisi dei percorsi ad accesso frequente, analisi del flusso di eventi in tempo reale (quasi) per rilevare anomalie, riconoscere i modelli nelle finestre temporali in sequenza o attivare avvisi quando si verifica una condizione specifica nel flusso.
Gestione di tipi speciali di messaggi non di telemetria dai dispositivi, ad esempio notifiche e allarmi.
Apprendimento automatico.
Le caselle ombreggiate in grigio mostrano i componenti di un sistema IoT che non sono direttamente correlati allo streaming di eventi, ma sono inclusi qui per completezza.
Il registro dei dispositivi è un database dei dispositivi di cui è stato effettuato il provisioning, inclusi gli ID dispositivo e in genere i metadati del dispositivo, ad esempio la posizione.
L'API di provisioning è un'interfaccia esterna comune per il provisioning e la registrazione di nuovi dispositivi.
Alcune soluzioni IoT consentono di inviare messaggi di comando e controllo ai dispositivi.
Questa sezione ha presentato una panoramica molto generale di IoT e ci sono molte sottigliezze e sfide da considerare. Per altre informazioni, vedere architetture IoT.