I cicli di rilascio più veloci rappresentano uno dei principali vantaggi delle architetture di microservizi. Ma senza un buon processo CI/CD, non si otterrà l'agilità che i microservizi promettono. Questo articolo descrive le sfide e consiglia alcuni approcci al problema.
Che cos'è CI/CD?
Quando si parla di CI/CD, si parla davvero di diversi processi correlati: integrazione continua, recapito continuo e distribuzione continua.
integrazione continua. Le modifiche al codice vengono spesso unite nel ramo principale. I processi di compilazione e test automatizzati assicurano che il codice nel ramo principale sia sempre di qualità di produzione.
Recapito continuo. Tutte le modifiche al codice che superano il processo di integrazione continua vengono pubblicate automaticamente in un ambiente simile a quello di produzione. La distribuzione nell'ambiente di produzione live può richiedere l'approvazione manuale, ma in caso contrario è automatizzata. L'obiettivo è che il codice deve essere sempre pronto da distribuire nell'ambiente di produzione.
distribuzione continua. Le modifiche al codice che superano i due passaggi precedenti vengono distribuite automaticamente nell'ambiente di produzione.
Ecco alcuni obiettivi di un processo CI/CD affidabile per un'architettura di microservizi:
Ogni team può creare e distribuire i servizi di cui è proprietario indipendentemente, senza influire o interrompere altri team.
Prima di distribuire una nuova versione di un servizio nell'ambiente di produzione, viene distribuita in ambienti di sviluppo/test/controllo di qualità per la convalida. I controlli di qualità vengono applicati in ogni fase.
Una nuova versione di un servizio può essere distribuita side-by-side con la versione precedente.
Sono disponibili criteri di controllo di accesso sufficienti.
Per i carichi di lavoro in contenitori, è possibile considerare attendibili le immagini del contenitore distribuite nell'ambiente di produzione.
Perché una pipeline CI/CD affidabile è importante
In un'applicazione monolitica tradizionale è presente una singola pipeline di compilazione il cui output è l'eseguibile dell'applicazione. Tutti i feed di lavoro di sviluppo in questa pipeline. Se viene trovato un bug ad alta priorità, è necessario integrare, testare e pubblicare una correzione, che può ritardare il rilascio delle nuove funzionalità. È possibile attenuare questi problemi grazie alla presenza di moduli con fattore corretto e all'uso dei rami di funzionalità per ridurre al minimo l'impatto delle modifiche al codice. Tuttavia, man mano che l'applicazione cresce più complessa e vengono aggiunte altre funzionalità, il processo di rilascio per un monolith tende a diventare più fragile e probabilmente si interrompe.
Seguendo la filosofia dei microservizi, non dovrebbe mai esserci un training di rilascio lungo in cui ogni team deve entrare in linea. Il team che compila il servizio "A" può rilasciare un aggiornamento in qualsiasi momento, senza attendere che le modifiche nel servizio "B" vengano unite, testate e distribuite.
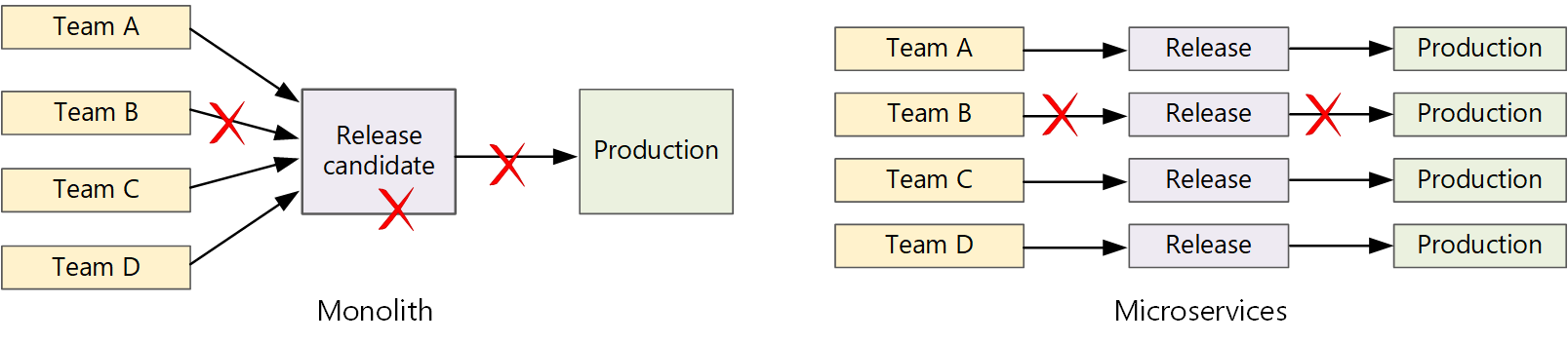
Per ottenere una velocità di rilascio elevata, la pipeline di versione deve essere automatizzata e altamente affidabile per ridurre al minimo i rischi. Se si rilascia alla produzione una o più volte al giorno, le regressioni o le interruzioni del servizio devono essere rare. Allo stesso tempo, se un aggiornamento non valido viene distribuito, è necessario disporre di un modo affidabile per eseguire rapidamente il rollback o il rollforward a una versione precedente di un servizio.
Sfide
Molte codebase indipendenti di piccole dimensioni. Ogni team è responsabile della creazione di un proprio servizio, con la propria pipeline di compilazione. In alcune organizzazioni, i team possono usare repository di codice separati. I repository separati possono causare una situazione in cui la conoscenza di come creare il sistema viene distribuita tra team e nessuno dell'organizzazione sa come distribuire l'intera applicazione. Ad esempio, cosa accade in uno scenario di ripristino di emergenza, se è necessario distribuire rapidamente in un nuovo cluster?
Mitigazione: avere una pipeline unificata e automatizzata per compilare e distribuire i servizi, in modo che questa conoscenza non sia "nascosta" all'interno di ogni team.
più linguaggi e framework. Con ogni team che usa una propria combinazione di tecnologie, può essere difficile creare un singolo processo di compilazione che funzioni nell'intera organizzazione. Il processo di compilazione deve essere sufficientemente flessibile che ogni team possa adattarlo per la propria scelta di linguaggio o framework.
Mitigazione: in contenitori il processo di compilazione per ogni servizio. In questo modo, il sistema di compilazione deve solo essere in grado di eseguire i contenitori.
Integrazione e test di carico. Con i team che rilasciano gli aggiornamenti in base al proprio ritmo, può essere difficile progettare test end-to-end affidabili, soprattutto quando i servizi hanno dipendenze da altri servizi. Inoltre, l'esecuzione di un cluster di produzione completo può essere costosa, quindi è improbabile che ogni team esegua il proprio cluster completo su larga scala di produzione, solo per i test.
Gestione delle versioni. Ogni team deve essere in grado di distribuire un aggiornamento nell'ambiente di produzione. Ciò non significa che ogni membro del team disponga delle autorizzazioni necessarie. Ma avere un ruolo di Release Manager centralizzato può ridurre la velocità delle distribuzioni.
mitigazione: più il processo CI/CD è automatizzato e affidabile, meno dovrebbe essere necessario un'autorità centrale. Detto questo, si potrebbero avere criteri diversi per il rilascio degli aggiornamenti delle funzionalità principali rispetto alle correzioni di bug secondarie. La decentralizzazione non significa governance zero.
Service updates. Quando si aggiorna un servizio a una nuova versione, non dovrebbe interrompere altri servizi che dipendono da esso.
Mitigazione: usare tecniche di distribuzione come la versione blu-verde o canary per le modifiche non di rilievo. Per le modifiche che causano un'interruzione dell'API, distribuire la nuova versione affiancata alla versione precedente. In questo modo, i servizi che usano l'API precedente possono essere aggiornati e testati per la nuova API. Vedere Aggiornamento dei servizidi seguito.
Monorepo e multi-repository
Prima di creare un flusso di lavoro CI/CD, è necessario sapere come verrà strutturata e gestita la codebase.
- I team funzionano in repository separati o in un monorepo (singolo repository)?
- Qual è la strategia di diramazione?
- Chi può eseguire il push del codice nell'ambiente di produzione? Esiste un ruolo di gestione delle versioni?
L'approccio monorepo ha guadagnato favore, ma ci sono vantaggi e svantaggi per entrambi.
| Monorepo | Più repository | |
|---|---|---|
| vantaggi | Condivisione del codice Più facile standardizzare codice e strumenti Più facile effettuare il refactoring del codice Individuabilità: singola visualizzazione del codice |
Cancellare la proprietà per ogni team Potenzialmente meno conflitti di unione Consente di applicare il disaccoppiamento dei microservizi |
| sfide | Le modifiche apportate al codice condiviso possono influire su più microservizi Maggiore potenziale per i conflitti di merge Gli strumenti devono essere ridimensionati in una codebase di grandi dimensioni Controllo di accesso Processo di distribuzione più complesso |
Più difficile condividere il codice Più difficile applicare gli standard di codifica Gestione delle dipendenze Base di codice diffusa, scarsa individuabilità Mancanza di infrastruttura condivisa |
Aggiornamento dei servizi
Esistono diverse strategie per aggiornare un servizio già in produzione. Di seguito vengono illustrate tre opzioni comuni: aggiornamento in sequenza, distribuzione blu-verde e versione canary.
Aggiornamenti in sequenza
In un aggiornamento in sequenza si distribuiscono nuove istanze di un servizio e le nuove istanze iniziano subito a ricevere richieste. Man mano che vengono visualizzate le nuove istanze, le istanze precedenti vengono rimosse.
Esempio. In Kubernetes gli aggiornamenti in sequenza sono il comportamento predefinito quando si aggiorna la specifica del pod per una distribuzione . Il controller di distribuzione crea un nuovo oggetto ReplicaSet per i pod aggiornati. Aumenta quindi il nuovo Set di repliche riducendo il valore precedente per mantenere il numero di repliche desiderato. Non elimina i pod precedenti finché non sono pronti quelli nuovi. Kubernetes mantiene una cronologia dell'aggiornamento, quindi è possibile eseguire il rollback di un aggiornamento, se necessario.
Esempio. Azure Service Fabric usa la strategia di aggiornamento in sequenza per impostazione predefinita. Questa strategia è più adatta per distribuire una versione di un servizio con nuove funzionalità senza modificare le API esistenti. Service Fabric avvia una distribuzione di aggiornamento aggiornando il tipo di applicazione a un subset dei nodi o di un dominio di aggiornamento. Esegue quindi il roll forward al dominio di aggiornamento successivo fino a quando non vengono aggiornati tutti i domini. Se un dominio di aggiornamento non viene aggiornato, il tipo di applicazione esegue il rollback alla versione precedente in tutti i domini. Tenere presente che un tipo di applicazione con più servizi (e se tutti i servizi vengono aggiornati come parte di una distribuzione di aggiornamento) è soggetto a errori. Se un servizio non viene aggiornato, viene eseguito il rollback dell'intera applicazione alla versione precedente e gli altri servizi non vengono aggiornati.
Una sfida per gli aggiornamenti in sequenza è che durante il processo di aggiornamento, una combinazione di versioni precedenti e nuove è in esecuzione e riceve traffico. Durante questo periodo, qualsiasi richiesta potrebbe essere instradata a una delle due versioni.
Per le modifiche che causano un'interruzione dell'API, è consigliabile supportare entrambe le versioni affiancate, fino a quando non vengono aggiornati tutti i client della versione precedente. Vedere controllo delle versioni dell'API.
Distribuzione blu-verde
In una distribuzione blu-verde si distribuisce la nuova versione insieme alla versione precedente. Dopo aver convalidato la nuova versione, si passa tutto il traffico contemporaneamente dalla versione precedente alla nuova versione. Dopo l'opzione, si monitora l'applicazione per eventuali problemi. Se si verifica un errore, è possibile tornare alla versione precedente. Supponendo che non ci siano problemi, è possibile eliminare la versione precedente.
Con un'applicazione monolitica o a più livelli più tradizionale, la distribuzione blu-verde ha in genere significato il provisioning di due ambienti identici. Distribuire la nuova versione in un ambiente di staging, quindi reindirizzare il traffico client all'ambiente di gestione temporanea, ad esempio scambiando indirizzi VIP. In un'architettura di microservizi gli aggiornamenti vengono eseguiti a livello di microservizio, quindi in genere si distribuisce l'aggiornamento nello stesso ambiente e si usa un meccanismo di individuazione dei servizi per lo scambio.
esempio. In Kubernetes non è necessario effettuare il provisioning di un cluster separato per eseguire distribuzioni blu-verde. È invece possibile sfruttare i selettori. Creare una nuova risorsa distribuzione
Uno svantaggio della distribuzione blu-verde è che durante l'aggiornamento, vengono eseguiti due volte più pod per il servizio (corrente e successiva). Se i pod richiedono molte risorse di CPU o memoria, potrebbe essere necessario aumentare temporaneamente il numero di istanze del cluster per gestire l'utilizzo delle risorse.
Versione Canary
In una versione canary si esegue l'implementazione di una versione aggiornata in un numero ridotto di client. Monitorare quindi il comportamento del nuovo servizio prima di distribuirlo a tutti i client. In questo modo è possibile eseguire un'implementazione lenta in modo controllato, osservare i dati reali e individuare i problemi prima che tutti i clienti siano interessati.
Una versione canary è più complessa da gestire rispetto all'aggiornamento blu-verde o in sequenza, perché è necessario instradare dinamicamente le richieste a versioni diverse del servizio.
esempio. In Kubernetes è possibile configurare un servizio per estendersi su due set di repliche (uno per ogni versione) e modificare manualmente i conteggi delle repliche. Tuttavia, questo approccio è piuttosto con granularità grossolana, a causa del modo in cui Kubernetes bilancia il carico tra i pod. Ad esempio, se si dispone di un totale di 10 repliche, è possibile spostare il traffico solo in 10% incrementi. Se si usa una mesh di servizi, è possibile usare le regole di routing della mesh del servizio per implementare una strategia di rilascio canary più sofisticata.
Passaggi successivi
- percorso di apprendimento : definire e implementare l'integrazione continua
- formazione : Introduzione alle di recapito continuo
- architettura microservizi
- perché usare un approccio ai microservizi per la creazione di applicazioni