Spostamento dei dati nel cluster vFXT - Inserimento di dati parallelo
Dopo aver creato un nuovo cluster vFXT, la prima attività potrebbe essere spostare i dati in un nuovo volume di archiviazione in Azure. Tuttavia, se il metodo che si usa in genere per spostare i dati è l'esecuzione di un semplice comando di copia da un client, probabilmente le prestazioni di copia risulteranno lente. La copia a thread singolo non è una buona opzione per copiare i dati nell'archiviazione back-end del cluster Avere vFXT.
Poiché il cluster Avere vFXT per Azure è una cache multi-client scalabile, il modo più rapido ed efficiente per copiare i dati è con più client. Questa tecnica parallelizza l'inserimento dei file e degli oggetti.
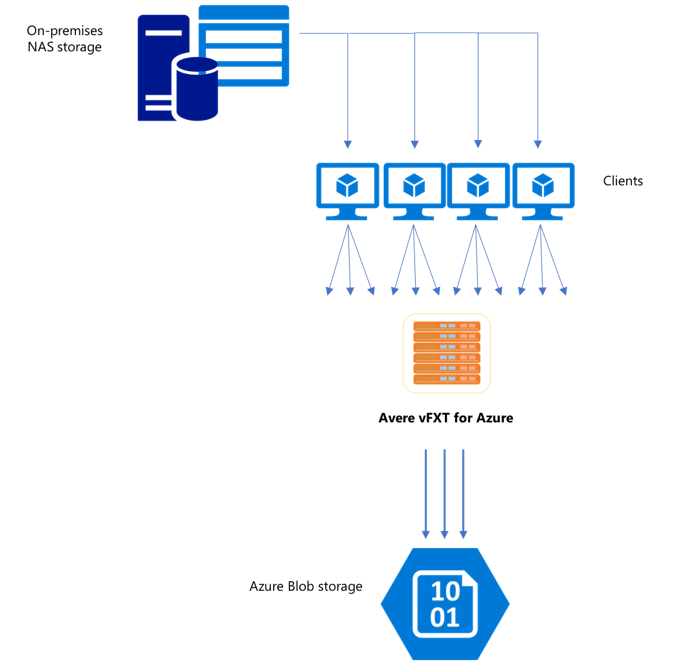
I comandi cp o copy che vengono comunemente usati per trasferire dati da un sistema di archiviazione all'altro sono processi a thread singolo, che copiano un solo file alla volta. Questo significa che il file server riceve un solo file alla volta, il che rappresenta uno spreco di risorse del cluster.
Questo articolo illustra le strategie per creare un sistema di copia multi-client a thread multipli per spostare dati nel cluster Avere vFXT. Spiega i concetti relativi al trasferimento di file e le decisioni da prendere per una copia dei dati efficiente usando più client e semplici comandi di copia.
Illustra inoltre alcune utilità che possono essere di ausilio. L'utilità msrsync può essere usata per automatizzare parzialmente il processo di divisione di un set di dati in bucket e tramite rsync comandi. Lo script parallelcp è un'altra utilità che legge la directory di origine e invia automaticamente i comandi di copia. Inoltre, lo rsync strumento può essere usato in due fasi per fornire una copia più rapida che fornisce comunque la coerenza dei dati.
Fare clic sul collegamento per passare a una sezione:
- Esempio di copia manuale : spiegazione completa sull'uso dei comandi di copia
- Esempio rsync in due fasi
- Esempio di automazione parziale (msrsync)
- Esempio di copia parallela
Modello di macchina virtuale per l'inserimento dei dati
In GitHub è disponibile un modello di Resource Manager per creare automaticamente una macchina virtuale con gli strumenti di inserimento dati parallelo menzionati in questo articolo.
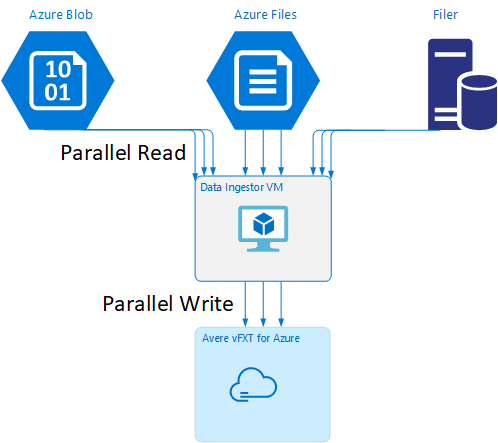
La macchina virtuale per l'inserimento dei dati fa parte di un'esercitazione in cui la macchina virtuale appena creata monta il cluster Avere vFXT e scarica lo script di bootstrap dal cluster. Per informazioni dettagliate, leggere Bootstrap a data ingestor VM (Bootstrap di una macchina virtuale per l'inserimento dei dati).
Pianificazione strategica
Quando si progetta una strategia per copiare i dati in parallelo, è necessario comprendere i compromessi in base alle dimensioni del file, al numero di file e alla profondità della directory.
- Quando i file sono di piccole dimensioni, la metrica di interesse è file al secondo.
- Quando i file sono di grandi dimensioni (10 MiBi o oltre), la metrica di interesse è byte al secondo.
Ogni processo di copia ha una velocità effettiva e una velocità di trasferimento dei file, che può essere misurata cronometrando la lunghezza del comando di copia e considerando le dimensioni del file e il numero di file. Spiegare come misurare i tassi non rientra nell'ambito di questo documento, ma è importante capire se si tratta di file di piccole o grandi dimensioni.
Esempio di copia manuale
Si può creare manualmente una copia a thread multipli in un client eseguendo simultaneamente più comandi di copia in background su un set predefinito di file o percorsi.
Il comando Linux/UNIX cp include l'argomento -p per conservare i metadati mtime e di proprietà. L'aggiunta di questo argomento ai comandi riportati di seguito è facoltativa. (L'aggiunta dell'argomento aumenta il numero di chiamate al file system inviate dal client al file system di destinazione per la modifica dei metadati.)
Questo semplice esempio copia due file in parallelo:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Dopo aver eseguito questo comando, il comando jobs mostrerà che sono in esecuzione due thread.
Struttura dei nomi file prevedibile
Se i nomi file sono prevedibili, è possibile usare espressioni per creare thread di copia paralleli.
Ad esempio, se la directory contiene 1.000 file numerati in sequenza da 0001 a 1000, è possibile usare le espressioni seguenti per creare dieci thread paralleli, ognuno dei quali copia 100 file:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Struttura dei nomi file sconosciuta
Se la struttura di denominazione dei file non è prevedibile, è possibile raggruppare file per nomi di directory.
Questo esempio raccoglie intere directory a cui inviare comandi cp eseguiti come attività in background:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Dopo aver raccolto i file, è possibile eseguire comandi di copia parallela per copiare in modo ricorsivo le sottodirectory e tutti il relativi contenuti:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Quando aggiungere punti di montaggio
Quando si raggiunge un numero sufficiente di thread paralleli verso un singolo punto di montaggio del file system di destinazione, vi sarà un punto in cui l'aggiunta di più thread non offre una velocità effettiva maggiore. La velocità effettiva verrà misurata in file/secondi o byte al secondo, a seconda del tipo di dati. O peggio, il over-threading può talvolta causare una riduzione della velocità effettiva.
In questo caso, è possibile aggiungere punti di montaggio lato client ad altri indirizzi IP del cluster vFXT, usando lo stesso percorso di montaggio del file system remoto:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
L'aggiunta di punti di montaggio lato client consente di diramare gli ulteriori comandi di copia aggiuntiva verso i punti di montaggio /mnt/destination[1-3] aggiuntivi, ottenendo un maggiore parallelismo.
Ad esempio, se i file sono molto grandi, è possibile definire i comandi di copia in modo da usare percorsi di destinazione diversi, inviando altri comandi in parallelo dal client che esegue la copia.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
Nell'esempio precedente, tutti e tre i punti di montaggio di destinazione sono interessati dai processi di copia file del client.
Quando aggiungere client
Per concludere, una volta raggiunto il limite di capacità del client, l'aggiunta di altri thread di copia o punti di montaggio non produrrà alcun incremento in termini di file per secondo o byte per secondo. In questo caso è possibile distribuire un altro client con lo stesso set di punti di montaggio, che eseguirà un proprio set di processi di copia dei file.
Esempio:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Creare manifesti di file
Dopo aver compreso gli approcci descritti in precedenza (più thread di copia per ogni destinazione, più destinazioni per client, più client per file system di origine accessibile dalla rete), considerare questo consiglio: creare manifesti di file e quindi usarli con i comandi di copia tra più client.
Questo scenario usa il comando UNIX find per creare manifesti di file o directory:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Reindirizzare il risultato a un file: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Quindi è possibile scorrere nel manifesto, usando comandi BASH per contare i file e determinare le dimensioni delle sottodirectory:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Infine, è necessario creare gli effettivi comandi di copia file per i client.
Se si hanno quattro client, usare questo comando:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Se hai cinque client, usare un comando simile al seguente:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
E per sei. Estrapolare in base alle esigenze.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Si otterranno N file risultanti, uno per ognuno degli N client i cui nomi percorso si trovano nelle directory di quarto livello ottenute come parte dell'output del comando find.
Usare ogni file per compilare il comando di copia:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Il comando precedente fornirà N file, ognuno con un comando di copia per riga, che può essere eseguito come script BASH nel client.
L'obiettivo è eseguire contemporaneamente più thread di questi script per client, in parallelo in più client.
Usare un processo rsync in due fasi
L'utilità standard rsync non funziona correttamente per popolare l'archiviazione cloud tramite il sistema Avere vFXT per Azure perché genera un numero elevato di operazioni di creazione e ridenominazione dei file per garantire l'integrità dei dati. Tuttavia, è possibile usare in modo sicuro l'opzione --inplace con rsync per ignorare la procedura di copia più attenta se si segue con una seconda esecuzione che controlla l'integrità dei file.
Un'operazione di copia standard rsync crea un file temporaneo e lo riempie di dati. Se il trasferimento dei dati viene completato correttamente, il file temporaneo viene rinominato nel nome file originale. Questo metodo garantisce coerenza anche se i file sono accessibili durante la copia. Questo metodo genera tuttavia più operazioni di scrittura, che rallenta lo spostamento dei file nella cache.
L'opzione --inplace scrive il nuovo file direttamente nel percorso finale. Non è garantito che i file siano coerenti durante il trasferimento, ma questo non è importante se si sta eseguendo il priming di un sistema di archiviazione per usarli in un secondo momento.
La seconda rsync operazione funge da verifica coerenza per la prima operazione. Poiché i file sono già stati copiati, la seconda fase è un'analisi rapida per garantire che i file nella destinazione corrispondano ai file nell'origine. Se i file non corrispondono, vengono copiati nuovamente.
È possibile eseguire entrambe le fasi insieme in un unico comando:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Questo metodo è un metodo semplice ed efficace per i set di dati fino al numero di file che il gestore di directory interno può gestire. Si tratta in genere di 200 milioni di file per un cluster a 3 nodi, 500 milioni di file per un cluster a sei nodi e così via.
Usare l'utilità msrsync
Lo msrsync strumento può essere usato anche per spostare i dati in un core filer back-end per il cluster Avere. Questo strumento è progettato per ottimizzare l'utilizzo della larghezza di banda mediante l'esecuzione parallela di più processi rsync. È disponibile da GitHub all'indirizzo https://github.com/jbd/msrsync.
msrsync suddivide la directory di origine in contenitori separati e quindi esegue singoli processi rsync in ogni contenitore.
I test preliminari su una macchina virtuale con quattro core hanno indicato la massima efficienza utilizzando 64 processi. Usare l'opzione -p di msrsync per impostare il numero di processi su 64.
È anche possibile usare l'argomento --inplace con msrsync i comandi. Se si usa questa opzione, è consigliabile eseguire un secondo comando (come con rsync, descritto in precedenza) per garantire l'integrità dei dati.
msrsync può scrivere solo da e verso volumi locali. L'origine e la destinazione devono essere accessibili montaggi locali nella rete virtuale del cluster.
Per usare msrsync per popolare un volume cloud di Azure con un cluster Avere, seguire queste istruzioni:
Installare
msrsynce i relativi prerequisiti (rsync e Python 2.6 o versione successiva)Determinare il numero totale di file e directory da copiare.
Ad esempio, usare l'utilità
prime.pyAvere con argomentiprime.py --directory /path/to/some/directory(disponibili scaricando l'URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Se non si usa
prime.py, è possibile calcolare il numero di elementi con lo strumento GNUfindcome indicato di seguito:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Dividere il numero di elementi per 64 per determinare il numero di elementi per ogni processo. Usare questo numero con l'opzione
-fper impostare le dimensioni dei contenitori quando si esegue il comando.Eseguire il
msrsynccomando per copiare i file:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Se si usa
--inplace, aggiungere una seconda esecuzione senza l'opzione per verificare che i dati vengano copiati correttamente:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Ad esempio, questo comando è progettato per spostare 11.000 file in 64 processi da /test/source-repository a /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Usare lo script di copia parallela
Lo parallelcp script può essere utile anche per lo spostamento dei dati nell'archiviazione back-end del cluster vFXT.
Lo script seguente aggiungerà l'eseguibile parallelcp. Questo script è progettato per Ubuntu, se si usa un'altra distribuzione è necessario installare parallel separatamente.
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Esempio di copia parallela
Questo esempio usa lo script di copia parallela per compilare glibc usando file di origine dal cluster Avere.
I file di origine vengono archiviati nel punto di montaggio del cluster Avere e i file oggetto vengono archiviati nel disco rigido locale.
Questo script usa lo script di copia parallela precedente. L'opzione -j viene usata con parallelcp e make per ottenere la parallelizzazione.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j