Ripristino di emergenza e distribuzione geografica in Azure Durable Functions
Microsoft si impegna per fare in modo che i servizi di Azure siano sempre disponibili. Possono tuttavia verificarsi interruzioni dei servizi non pianificate. Se l'applicazione richiede resilienza, Microsoft consiglia di configurare l'app per la ridondanza geografica. I clienti dovrebbero anche predisporre un piano di ripristino di emergenza per gestire un'interruzione dei servizi a livello di area. Una parte importante di un piano di ripristino di emergenza sta preparando il failover alla replica secondaria dell'app e dell'archiviazione nel caso in cui la replica primaria non sia disponibile.
In Durable Functions, tutti gli stati vengono mantenuti in Archiviazione di Azure per impostazione predefinita. Un hub attività è un contenitore logico per le risorse di Archiviazione di Azure usate per orchestrazioni ed entità. L'agente di orchestrazione, l'attività e le funzioni di entità possono interagire tra loro solo quando appartengono allo stesso hub attività. Questo documento fa riferimento agli hub attività durante la descrizione di scenari per mantenere a disponibilità elevata queste risorse di Archiviazione di Azure.
Nota
Le indicazioni contenute in questo articolo presuppongono che si usi il provider di archiviazione di Azure predefinito per archiviare Durable Functions stato di runtime. Tuttavia, è possibile configurare provider di archiviazione alternativi che archiviano lo stato altrove, ad esempio un database SQL Server. È possibile che siano necessarie diverse strategie di ripristino di emergenza e distribuzione geografica per i provider di archiviazione alternativi. Per altre informazioni sui provider di archiviazione alternativi, vedere la documentazione dei provider di archiviazione Durable Functions.
Le orchestrazioni e le entità possono essere attivate usando le funzioni client che vengono attivate tramite HTTP o uno degli altri tipi di trigger supportati Funzioni di Azure. Possono essere attivati anche usando LE API HTTP predefinite. Per semplicità, questo articolo si concentra sugli scenari che coinvolgono trigger di funzioni basati su Azure e su HTTP e opzioni per aumentare la disponibilità e ridurre al minimo i tempi di inattività durante le attività di ripristino di emergenza. Altri tipi di trigger, ad esempio il bus di servizio o i trigger di Azure Cosmos DB, non verranno trattati in modo esplicito.
Gli scenari seguenti si basano su configurazioni Active-Passive, poiché sono guidate dall'utilizzo di Archiviazione di Azure. Questo modello prevede la distribuzione di un'app per le funzioni di backup (passiva) in un'altra area. Gestione traffico monitorerà l'app per le funzioni primaria (attiva) per la disponibilità HTTP. In caso di errore dell'app primaria, verrà effettuato il failover all'app per le funzioni di backup. Per altre informazioni, vedere Il metodo Priority Traffic-Routing di Gestione traffico di Azure.
Nota
- La configurazione attiva-passiva proposta assicura che un client sia sempre in grado di attivare nuove orchestrazioni tramite HTTP. Tuttavia, come conseguenza di avere due app per le funzioni che condividono lo stesso hub attività nell'archiviazione, alcune transazioni di archiviazione in background verranno distribuite tra entrambi. Questa configurazione comporta quindi alcuni costi di uscita aggiunti per l'app per le funzioni secondarie.
- L'hub attività e l'account di archiviazione sottostante vengono creati nell'area primaria e sono condivisi da entrambe le app per le funzioni.
- Tutte le app per le funzioni distribuite con ridondanza devono condividere le stesse chiavi di accesso alle funzioni nel caso di essere attivata tramite HTTP. Il runtime di Funzioni espone un'API di gestione che consente ai consumer di aggiungere, eliminare e aggiornare le chiavi di funzione a livello di codice. È anche possibile usare le API di Azure Resource Manager.
Scenario 1 - Calcolo con bilanciamento del carico con archiviazione condivisa
In caso di errore dell'infrastruttura di calcolo in Azure, l'app per le funzioni potrebbe diventare non disponibile. Per ridurre al minimo la possibilità di tale tempo di inattività, questo scenario usa due app per le funzioni distribuite in aree diverse. Gestione traffico è configurato per rilevare i problemi nell'app per le funzioni primaria e reindirizzare automaticamente il traffico verso l'app per le funzioni nell'area secondaria. Questa app per le funzioni condivide lo stesso account di archiviazione di Azure e lo stesso hub attività. Pertanto, lo stato delle app per le funzioni non va perso e l'attività può riprendere normalmente. Una volta ripristinata l'integrità nell'area primaria, Gestione traffico di Azure avvierà automaticamente il routing delle richieste a tale app per le funzioni.
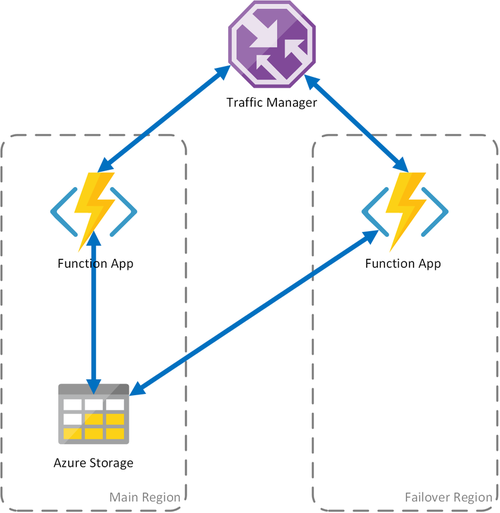
L'uso di questo scenario di distribuzione comporta diversi vantaggi:
- Se l'infrastruttura di calcolo non riesce, il lavoro può riprendere nell'area di failover senza perdita di dati.
- Gestione traffico si occupa automaticamente del failover automatico all'app per le funzioni integre.
- Gestione traffico ristabilisce automaticamente il traffico all'app per le funzioni primaria dopo che l'interruzione è stata risolta.
Tuttavia, usando questo scenario si consideri:
- Se l'app per le funzioni viene distribuita usando un piano di servizio app dedicato, replicare l'infrastruttura di calcolo nel data center di failover aumenta i costi.
- Questo scenario riguarda le interruzioni nell'infrastruttura di calcolo, ma l'account di archiviazione continua a essere il singolo punto di guasto per l'app per le funzioni. Se si verifica un'interruzione dell'archiviazione, l'applicazione subisce tempi di inattività.
- Se è stato effettuato il failover dell'app per le funzioni, si verificherà un aumento della latenza dal momento che accederà al relativo account di archiviazione tra le diverse aree.
- L'accesso al servizio di archiviazione da un'area diversa da quella in cui è situato comporta costi più elevati a causa del traffico di rete in uscita.
- Questo scenario dipende da Gestione traffico. Prendendo in considerazione la modalità di funzionamento di Gestione traffico, potrebbe passare del tempo prima che un'applicazione client che utilizza una funzione durevole necessiti di eseguire nuovamente una query sull'indirizzo dell'app per le funzioni da Gestione traffico.
Nota
A partire dalla versione 2.3.0 dell'estensione Durable Functions, due app per le funzioni possono essere eseguite contemporaneamente con lo stesso account di archiviazione e configurazione dell'hub attività. La prima app da avviare acquisirà un lease BLOB a livello di applicazione che impedisce ad altre app di rubare messaggi dalle code dell'hub attività. Se questa prima app smette di eseguire, il lease scade e può essere acquisito da una seconda app, che procederà quindi per elaborare i messaggi dell'hub attività.
Prima della versione 2.3.0, le app per le funzioni configurate per l'uso dello stesso account di archiviazione elaborano i messaggi e aggiornano gli artefatti di archiviazione simultaneamente, causando ritardi complessivi molto più elevati e costi di uscita. Se le app primarie e di replica hanno mai distribuito codice diverso, anche temporaneamente, le orchestrazioni potrebbero anche non riuscire a eseguire correttamente a causa delle incoerenze della funzione dell'agente di orchestrazione tra le due app. È quindi consigliabile che tutte le app che richiedono la distribuzione geografica per scopi di ripristino di emergenza usino la versione 2.3.0 o successiva dell'estensione Durable.
Scenario 2 - Calcolo con bilanciamento del carico con archiviazione a livello di area
Lo scenario precedente riguarda solo i casi di errore nell'infrastruttura di calcolo. Se si verifica un errore nel servizio di archiviazione, comporterà un'interruzione dell'app per le funzioni. Per garantire il funzionamento continuo delle funzioni durevoli, questo scenario usa un account di archiviazione locale in ogni area a cui sono distribuite le app per le funzioni.
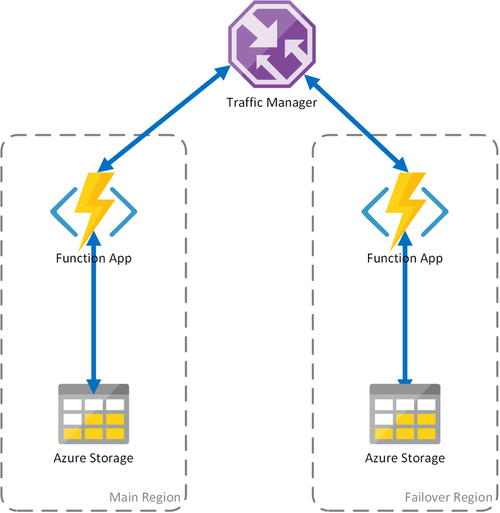
Questo approccio implica diversi miglioramenti rispetto allo scenario precedente:
- In caso di errore dell'app per le funzioni, Gestione traffico si occupa di effettuare il failover all'area secondaria. Tuttavia, poiché l'app per le funzioni si basa sul proprio account di archiviazione, le funzioni durevoli continueranno a funzionare.
- Durante un failover, non è presente alcuna latenza aggiuntiva nell'area di failover poiché l'app per le funzioni e l'account di archiviazione vengono raggruppati.
- L'errore del livello di archiviazione causerà errori nelle funzioni durevoli, che a sua volta attiveranno un reindirizzamento all'area di failover. Anche in questo caso, dal momento che l'app per le funzioni e l'archiviazione sono isolate per area, le funzioni durevoli continueranno a funzionare.
Considerazioni importanti per questo scenario:
- Se l'app per le funzioni viene distribuita usando un piano di servizio app dedicato, replicare l'infrastruttura di calcolo nel data center di failover aumenta i costi.
- Lo stato corrente non viene eseguito il failover, che implica che le orchestrazioni e le entità esistenti verranno sospese in modo efficace e non saranno disponibili fino a quando l'area primaria non viene ripristinata.
Per riepilogare, il compromesso tra il primo e il secondo scenario è che la latenza viene mantenuta e i costi di uscita vengono ridotti al minimo, ma le orchestrazioni e le entità esistenti non saranno disponibili durante il tempo di inattività. Se questi compromessi sono accettabili dipendono dai requisiti dell'applicazione.
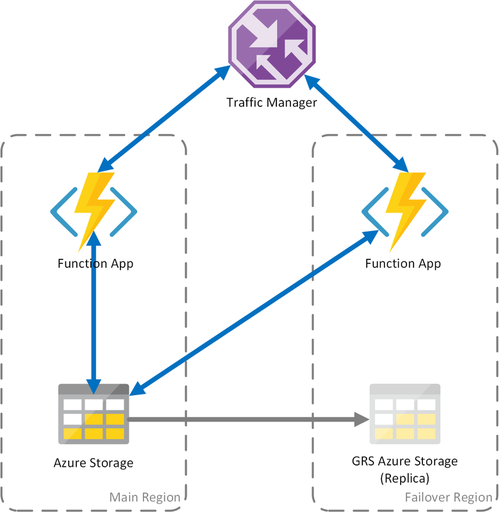
Scenario 3 - Calcolo con bilanciamento del carico con archiviazione con ridondanza geografica condivisa
Questo scenario costituisce una modifica rispetto al primo scenario e comporta l'implementazione di un account di archiviazione condiviso. La differenza principale è che l'account di archiviazione viene creato con replica geografica abilitata. Dal punto di vista funzionale, questo scenario offre gli stessi vantaggi dello Scenario 1, ma assicura altri benefici a livello di ripristino dei dati:
- L'archiviazione con ridondanza geografica (GRS) e l'archiviazione con ridondanza geografica e accesso in lettura (RA-GRS) ottimizza la disponibilità per l'account di archiviazione.
- Se si verifica un'interruzione a livello di area del servizio di archiviazione, è possibile avviare manualmente un failover alla replica secondaria. In casi estremi, in cui un'area va persa a causa di una grave emergenza, Microsoft potrebbe avviare un failover a livello di area. In tal caso, non è necessaria alcuna azione da parte dell'utente.
- Quando si verifica un failover, lo stato delle funzioni durevoli verrà mantenuto fino all'ultima replica dell'account di archiviazione, che in genere si verifica ogni pochi minuti.
Come per gli altri scenari, ci sono considerazioni importanti di cui tenere conto:
- Un failover alla replica potrebbe richiedere qualche tempo. Finché il failover non viene completato e i record DNS di Archiviazione di Azure sono stati aggiornati, l'app per le funzioni subirà un'interruzione.
- È previsto un costo aggiuntivo per l'uso degli account di archiviazione con replica geografica.
- La replica grS copia i dati in modo asincrono. Alcune delle transazioni più recenti potrebbero andare perse a causa della latenza del processo di replica.
Nota
Come descritto nello scenario 1, è consigliabile che le app per le funzioni distribuite con questa strategia usino la versione 2.3.0 o successiva dell'estensione Durable Functions.
Per altre informazioni, vedere la documentazione relativa al failover dell'account di archiviazione e ripristino di emergenza di Archiviazione di Azure .