Trigger SQL di Azure per Funzioni
Nota
Nelle funzioni del piano a consumo il ridimensionamento automatico non è supportato per il trigger SQL. Se il processo di ridimensionamento automatico arresta la funzione, l'elaborazione degli eventi verrà arrestata e dovrà essere riavviata manualmente.
Usare piani Premium o dedicati per la scalabilità dei vantaggi con il trigger SQL.
Il trigger SQL di Azure usa la funzionalità di rilevamento delle modifiche SQL per monitorare una tabella SQL per rilevare le modifiche e attivare una funzione quando viene creata, aggiornata o eliminata una riga. Per informazioni dettagliate sulla configurazione per il rilevamento delle modifiche da usare con il trigger SQL di Azure, vedere Configurare il rilevamento delle modifiche. Per informazioni dettagliate sull'installazione dell'estensione SQL di Azure per Funzioni di Azure, vedere la panoramica dell'associazione SQL.
Le decisioni di ridimensionamento dei trigger sql di Azure per i piani a consumo e Premium vengono eseguite tramite il ridimensionamento basato sulla destinazione. Per altre informazioni, vedere Scalabilità basata su destinazione.
Panoramica delle funzionalità
L'associazione di trigger SQL di Azure usa un ciclo di polling per verificare la presenza di modifiche, attivando la funzione utente quando vengono rilevate modifiche. A livello generale, il ciclo è simile al seguente:
while (true) {
1. Get list of changes on table - up to a maximum number controlled by the Sql_Trigger_MaxBatchSize setting
2. Trigger function with list of changes
3. Wait for delay controlled by Sql_Trigger_PollingIntervalMs setting
}
Le modifiche vengono elaborate nell'ordine in cui sono state apportate le modifiche, con le modifiche meno recenti elaborate per prime. Un paio di note sull'elaborazione delle modifiche:
- Se le modifiche a più righe vengono apportate contemporaneamente all'ordine esatto in cui vengono inviate alla funzione si basa sull'ordine restituito dalla funzione CHANGETABLE
- Le modifiche vengono "raggruppate" per una riga. Se vengono apportate più modifiche a una riga tra ogni iterazione del ciclo, esiste solo una singola voce di modifica per tale riga che mostrerà la differenza tra l'ultimo stato elaborato e lo stato corrente
- Se vengono apportate modifiche a un set di righe e quindi viene apportato un altro set di modifiche alla metà delle stesse righe, la metà delle righe che non sono state modificate una seconda volta viene elaborata per prima. Questa logica di elaborazione è dovuta alla nota precedente con le modifiche in batch. Il trigger visualizzerà solo l'ultima modifica apportata e lo userà per l'ordine in cui li elabora.
Per altre informazioni sul rilevamento delle modifiche e sul modo in cui viene usato da applicazioni come i trigger SQL di Azure, vedere Usare il rilevamento delle modifiche.
Esempio di utilizzo
Altri esempi per il trigger Azure SQL sono disponibili nel repository GitHub.
L’esempio fa riferimento a una classe ToDoItem e a una tabella di database corrispondente:
namespace AzureSQL.ToDo
{
public class ToDoItem
{
public Guid Id { get; set; }
public int? order { get; set; }
public string title { get; set; }
public string url { get; set; }
public bool? completed { get; set; }
}
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Il rilevamento delle modifiche è abilitato nel database e nella tabella:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Il trigger SQL viene associato a un IReadOnlyList<SqlChange<T>>, un elenco di oggetti SqlChange, ognuno con due proprietà:
- Elemento: l'elemento modificato. Il tipo dell'elemento deve seguire lo schema della tabella come illustrato nella classe
ToDoItem. - Operazione: valore di enumerazione
SqlChangeOperation. I valori possibili sonoInsert,UpdateeDelete.
L'esempio seguente mostra una funzione C# richiamata quando sono presenti modifiche alla ToDo tabella:
using System;
using System.Collections.Generic;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Extensions.Sql;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
namespace AzureSQL.ToDo
{
public static class ToDoTrigger
{
[Function("ToDoTrigger")]
public static void Run(
[SqlTrigger("[dbo].[ToDo]", "SqlConnectionString")]
IReadOnlyList<SqlChange<ToDoItem>> changes,
FunctionContext context)
{
var logger = context.GetLogger("ToDoTrigger");
foreach (SqlChange<ToDoItem> change in changes)
{
ToDoItem toDoItem = change.Item;
logger.LogInformation($"Change operation: {change.Operation}");
logger.LogInformation($"Id: {toDoItem.Id}, Title: {toDoItem.title}, Url: {toDoItem.url}, Completed: {toDoItem.completed}");
}
}
}
}
Esempio di utilizzo
Altri esempi per il trigger Azure SQL sono disponibili nel repository GitHub.
L'esempio fa riferimento a una ToDoItem classe, a una SqlChangeToDoItem classe, a un'enumerazione SqlChangeOperation e a una tabella di database corrispondente:
In un file ToDoItem.javaseparato :
package com.function;
import java.util.UUID;
public class ToDoItem {
public UUID Id;
public int order;
public String title;
public String url;
public boolean completed;
public ToDoItem() {
}
public ToDoItem(UUID Id, int order, String title, String url, boolean completed) {
this.Id = Id;
this.order = order;
this.title = title;
this.url = url;
this.completed = completed;
}
}
In un file SqlChangeToDoItem.javaseparato :
package com.function;
public class SqlChangeToDoItem {
public ToDoItem item;
public SqlChangeOperation operation;
public SqlChangeToDoItem() {
}
public SqlChangeToDoItem(ToDoItem Item, SqlChangeOperation Operation) {
this.Item = Item;
this.Operation = Operation;
}
}
In un file SqlChangeOperation.javaseparato :
package com.function;
import com.google.gson.annotations.SerializedName;
public enum SqlChangeOperation {
@SerializedName("0")
Insert,
@SerializedName("1")
Update,
@SerializedName("2")
Delete;
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Il rilevamento delle modifiche è abilitato nel database e nella tabella:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Il trigger SQL viene associato a un oggetto SqlChangeToDoItem[], una matrice di SqlChangeToDoItem oggetti ognuno con due proprietà:
- item: l'elemento modificato. Il tipo dell'elemento deve seguire lo schema della tabella come illustrato nella classe
ToDoItem. - operation: valore di
SqlChangeOperationenumerazione. I valori possibili sonoInsert,UpdateeDelete.
L'esempio seguente mostra una funzione Java richiamata quando sono presenti modifiche alla ToDo tabella:
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.sql.annotation.SQLTrigger;
import com.function.Common.SqlChangeToDoItem;
import com.google.gson.Gson;
import java.util.logging.Level;
public class ProductsTrigger {
@FunctionName("ToDoTrigger")
public void run(
@SQLTrigger(
name = "todoItems",
tableName = "[dbo].[ToDo]",
connectionStringSetting = "SqlConnectionString")
SqlChangeToDoItem[] todoItems,
ExecutionContext context) {
context.getLogger().log(Level.INFO, "SQL Changes: " + new Gson().toJson(changes));
}
}
Esempio di utilizzo
Altri esempi per il trigger Azure SQL sono disponibili nel repository GitHub.
L'esempio fa riferimento a una ToDoItem tabella di database:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Il rilevamento delle modifiche è abilitato nel database e nella tabella:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Il trigger SQL viene associato a todoChanges, un elenco di oggetti ognuno con due proprietà:
- item: l'elemento modificato. La struttura dell'elemento seguirà lo schema della tabella.
- operation: i valori possibili sono
Insert,UpdateeDelete.
L'esempio seguente mostra una funzione di PowerShell richiamata quando sono presenti modifiche alla ToDo tabella.
Di seguito sono riportati i dati di associazione nel file function.json:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
Queste proprietà sono descritte nella sezione configuration.
Di seguito è riportato il codice di PowerShell di esempio per la funzione nel run.ps1 file :
using namespace System.Net
param($todoChanges)
# The output is used to inspect the trigger binding parameter in test methods.
# Use -Compress to remove new lines and spaces for testing purposes.
$changesJson = $todoChanges | ConvertTo-Json -Compress
Write-Host "SQL Changes: $changesJson"
Esempio di utilizzo
Altri esempi per il trigger Azure SQL sono disponibili nel repository GitHub.
L'esempio fa riferimento a una ToDoItem tabella di database:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Il rilevamento delle modifiche è abilitato nel database e nella tabella:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Il trigger SQL associa todoChanges, una matrice di oggetti ognuno con due proprietà:
- item: l'elemento modificato. La struttura dell'elemento seguirà lo schema della tabella.
- operation: i valori possibili sono
Insert,UpdateeDelete.
L'esempio seguente mostra una funzione JavaScript richiamata quando sono presenti modifiche alla ToDo tabella.
Di seguito sono riportati i dati di associazione nel file function.json:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
Queste proprietà sono descritte nella sezione configuration.
Di seguito è riportato il codice JavaScript di esempio per la funzione nel index.js file :
module.exports = async function (context, todoChanges) {
context.log(`SQL Changes: ${JSON.stringify(todoChanges)}`)
}
Esempio di utilizzo
Altri esempi per il trigger Azure SQL sono disponibili nel repository GitHub.
L'esempio fa riferimento a una ToDoItem tabella di database:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Il rilevamento delle modifiche è abilitato nel database e nella tabella:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Il trigger SQL viene associato a una variabile todoChanges, un elenco di oggetti ognuno con due proprietà:
- item: l'elemento modificato. La struttura dell'elemento seguirà lo schema della tabella.
- operation: i valori possibili sono
Insert,UpdateeDelete.
Nell'esempio seguente viene illustrata una funzione Python richiamata quando vengono apportate modifiche alla ToDo tabella.
Di seguito è riportato il codice Python di esempio per il file function_app.py:
import json
import logging
import azure.functions as func
from azure.functions.decorators.core import DataType
app = func.FunctionApp()
@app.function_name(name="ToDoTrigger")
@app.sql_trigger(arg_name="todo",
table_name="ToDo",
connection_string_setting="SqlConnectionString")
def todo_trigger(todo: str) -> None:
logging.info("SQL Changes: %s", json.loads(todo))
Attributi
La libreria C# usa l'attributo SqlTrigger per dichiarare il trigger SQL nella funzione, con le proprietà seguenti:
| Proprietà dell'attributo | Descrizione |
|---|---|
| TableName | Obbligatorio. Nome della tabella monitorata dal trigger. |
| ConnectionStringSetting | Obbligatorio. Nome di un'impostazione dell'app che contiene il stringa di connessione per il database contenente la tabella monitorata per le modifiche. Il nome dell'impostazione stringa di connessione corrisponde all'impostazione dell'applicazione (in local.settings.json per lo sviluppo locale) che contiene il stringa di connessione all'istanza di SQL o SQL Server di Azure. |
| LeasesTableName | Facoltativo. Nome della tabella utilizzata per archiviare i lease. Se non specificato, il nome della tabella lease verrà Leases_{FunctionId}_{TableId}. Altre informazioni su come viene generato sono disponibili qui. |
Annotazioni
Nella libreria di runtime delle funzioni Java usare l'annotazione @SQLTrigger (com.microsoft.azure.functions.sql.annotation.SQLTrigger) nei parametri il cui valore proviene da Azure SQL. Questa annotazione supporta gli elementi seguenti:
| Elemento | Descrizione |
|---|---|
| name | Obbligatorio. Nome del parametro a cui viene associato il trigger. |
| tableName | Obbligatorio. Nome della tabella monitorata dal trigger. |
| connectionStringSetting | Obbligatorio. Nome di un'impostazione dell'app che contiene il stringa di connessione per il database contenente la tabella monitorata per le modifiche. Il nome dell'impostazione stringa di connessione corrisponde all'impostazione dell'applicazione (in local.settings.json per lo sviluppo locale) che contiene il stringa di connessione all'istanza di SQL o SQL Server di Azure. |
| LeasesTableName | Facoltativo. Nome della tabella utilizzata per archiviare i lease. Se non specificato, il nome della tabella lease verrà Leases_{FunctionId}_{TableId}. Altre informazioni su come viene generato sono disponibili qui. |
Impostazione
Nella tabella seguente sono illustrate le proprietà di configurazione dell'associazione impostate nel file function.json.
| Proprietà di function.json | Descrizione |
|---|---|
| name | Obbligatorio. Nome del parametro a cui viene associato il trigger. |
| type | Obbligatorio. Deve essere impostato su sqlTrigger. |
| direction | Obbligatorio. Deve essere impostato su in. |
| tableName | Obbligatorio. Nome della tabella monitorata dal trigger. |
| connectionStringSetting | Obbligatorio. Nome di un'impostazione dell'app che contiene il stringa di connessione per il database contenente la tabella monitorata per le modifiche. Il nome dell'impostazione stringa di connessione corrisponde all'impostazione dell'applicazione (in local.settings.json per lo sviluppo locale) che contiene il stringa di connessione all'istanza di SQL o SQL Server di Azure. |
| LeasesTableName | Facoltativo. Nome della tabella utilizzata per archiviare i lease. Se non specificato, il nome della tabella lease verrà Leases_{FunctionId}_{TableId}. Altre informazioni su come viene generato sono disponibili qui. |
Configurazione facoltativa
Le impostazioni facoltative seguenti possono essere configurate per il trigger SQL per lo sviluppo locale o per le distribuzioni cloud.
host.json
Questa sezione descrive le impostazioni di configurazione disponibili per questa associazione nelle versioni 2.x e successive. Le impostazioni nel file host.json si applicano a tutte le funzioni in un'istanza dell'app per le funzioni. L'esempio host.json file seguente contiene solo le impostazioni della versione 2.x+ per questa associazione. Per altre informazioni sulle impostazioni di configurazione delle app per le funzioni nelle versioni 2.x e successive, vedere informazioni di riferimento host.json per Funzioni di Azure.
| Impostazione | Default | Descrizione |
|---|---|---|
| MaxBatchSize | 100 | Numero massimo di modifiche elaborate con ogni iterazione del ciclo di trigger prima di essere inviate alla funzione attivata. |
| PollingIntervalMs | 1000 | Ritardo in millisecondi tra l'elaborazione di ogni batch di modifiche. (1000 ms è 1 secondo) |
| MaxChangesPerWorker | 1000 | Limite massimo per il numero di modifiche in sospeso nella tabella utente consentite per ogni ruolo di lavoro dell'applicazione. Se il numero di modifiche supera questo limite, potrebbe comportare un aumento del numero di istanze. L'impostazione si applica solo alle app per le funzioni di Azure con scalabilità guidata dal runtime abilitata. |
File di host.json di esempio
Di seguito è riportato un esempio di file host.json con le impostazioni facoltative:
{
"version": "2.0",
"extensions": {
"Sql": {
"MaxBatchSize": 300,
"PollingIntervalMs": 1000,
"MaxChangesPerWorker": 100
}
},
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
},
"logLevel": {
"default": "Trace"
}
}
}
local.setting.json
Il file local.settings.json archivia le impostazioni e le impostazioni dell'app usate dagli strumenti di sviluppo locali. Le impostazioni nel file local.settings.json vengono usate solo quando si esegue il progetto in locale. Quando si pubblica il progetto in Azure, assicurarsi di aggiungere anche le impostazioni necessarie alle impostazioni dell'app per l'app per le funzioni.
Importante
Poiché il local.settings.json può contenere segreti, ad esempio le stringhe di connessione, non è mai consigliabile archiviarlo in un repository remoto. Gli strumenti che supportano Funzioni consentono di sincronizzare le impostazioni nel file local.settings.json con le impostazioni dell'app nell'app per le funzioni in cui viene distribuito il progetto.
| Impostazione | Default | Descrizione |
|---|---|---|
| Sql_Trigger_BatchSize | 100 | Numero massimo di modifiche elaborate con ogni iterazione del ciclo di trigger prima di essere inviate alla funzione attivata. |
| Sql_Trigger_PollingIntervalMs | 1000 | Ritardo in millisecondi tra l'elaborazione di ogni batch di modifiche. (1000 ms è 1 secondo) |
| Sql_Trigger_MaxChangesPerWorker | 1000 | Limite massimo per il numero di modifiche in sospeso nella tabella utente consentite per ogni ruolo di lavoro dell'applicazione. Se il numero di modifiche supera questo limite, potrebbe comportare un aumento del numero di istanze. L'impostazione si applica solo alle app per le funzioni di Azure con scalabilità guidata dal runtime abilitata. |
File di local.settings.json di esempio
Di seguito è riportato un esempio di file local.settings.json con le impostazioni facoltative:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"SqlConnectionString": "",
"Sql_Trigger_MaxBatchSize": 300,
"Sql_Trigger_PollingIntervalMs": 1000,
"Sql_Trigger_MaxChangesPerWorker": 100
}
}
Configurare il rilevamento delle modifiche (obbligatorio)
La configurazione del rilevamento delle modifiche da usare con il trigger SQL di Azure richiede due passaggi. Questi passaggi possono essere completati da qualsiasi strumento SQL che supporta l'esecuzione di query, tra cui Visual Studio Code, Azure Data Studio o SQL Server Management Studio.
Abilitare il rilevamento delle modifiche nel database SQL, sostituendo
your database namecon il nome del database in cui si trova la tabella da monitorare:ALTER DATABASE [your database name] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);L'opzione
CHANGE_RETENTIONspecifica il periodo di tempo per il quale vengono mantenute le informazioni di rilevamento delle modifiche (cronologia modifiche). La conservazione della cronologia delle modifiche da parte del database SQL potrebbe influire sulla funzionalità dei trigger. Ad esempio, se la funzione di Azure è disattivata per diversi giorni e quindi ripresa, il database conterrà le modifiche apportate negli ultimi due giorni nell'esempio di configurazione precedente.L'opzione
AUTO_CLEANUPviene usata per abilitare o disabilitare l'attività di pulizia che rimuove le informazioni di rilevamento delle modifiche precedenti. Se un problema temporaneo che impedisce l'esecuzione del trigger, disattivare la pulizia automatica può essere utile per sospendere la rimozione delle informazioni precedenti al periodo di conservazione fino a quando il problema non viene risolto.Altre informazioni sulle opzioni di rilevamento delle modifiche sono disponibili nella documentazione di SQL.
Abilitare il rilevamento delle modifiche nella tabella, sostituendo
your table namecon il nome della tabella da monitorare (modificando lo schema, se appropriato):ALTER TABLE [dbo].[your table name] ENABLE CHANGE_TRACKING;Il trigger deve avere accesso in lettura alla tabella monitorata per le modifiche e alle tabelle di sistema di rilevamento delle modifiche. Ogni trigger di funzione ha una tabella di rilevamento delle modifiche associata e una tabella lease in uno schema
az_func. Queste tabelle vengono create dal trigger se non esistono ancora. Altre informazioni su queste strutture di dati sono disponibili nella documentazione della libreria di associazioni SQL di Azure.
Abilitare il ridimensionamento basato sul runtime
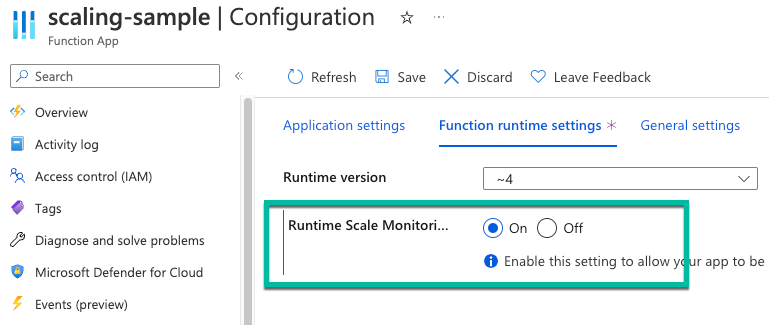
Facoltativamente, le funzioni possono essere ridimensionate automaticamente in base al numero di modifiche in sospeso da elaborare nella tabella utente. Per consentire alle funzioni di ridimensionare correttamente il piano Premium quando si usano i trigger SQL, è necessario abilitare il monitoraggio della scalabilità di runtime.
Nella portale di Azure, nell'app per le funzioni scegliere Configurazione e nella scheda Impostazioni runtime funzione impostare Monitoraggio della scalabilità di runtime su Sì.
Supporto di ripetizione dei tentativi
Altre informazioni sul supporto dei tentativi di trigger SQL e sulle tabelle di lease sono disponibili nel repository GitHub.
Tentativi di avvio
Se si verifica un'eccezione durante l'avvio, il runtime dell'host tenta automaticamente di riavviare il listener del trigger con una strategia di backoff esponenziale. Questi tentativi continuano fino a quando il listener non viene avviato correttamente o l'avvio viene annullato.
Tentativi di connessione interrotti
Se la funzione viene avviata correttamente, ma un errore causa l'interruzione della connessione , ad esempio il server offline, la funzione continua a provare e riaprire la connessione fino a quando la funzione non viene arrestata o la connessione ha esito positivo. Se la connessione viene ristabilita, l'elaborazione delle modifiche è stata interrotta.
Si noti che questi tentativi non rientrano nella logica di ripetizione dei tentativi di connessione inattiva predefinita che SqlClient può essere configurato con le ConnectRetryCount opzioni e ConnectRetryInterval stringa di connessione. I tentativi di connessione inattiva predefiniti vengono tentati per primi e se questi non riescono a riconnettersi, l'associazione trigger tenta di ristabilire la connessione stessa.
Tentativi di eccezione della funzione
Se si verifica un'eccezione nella funzione utente durante l'elaborazione delle modifiche, il batch di righe attualmente in fase di elaborazione viene ritentato in 60 secondi. Durante questo periodo di tempo vengono elaborate altre modifiche, ma le righe del batch che hanno causato l'eccezione vengono ignorate fino a quando non è trascorso il periodo di timeout.
Se l'esecuzione della funzione ha esito negativo cinque volte in una riga per una determinata riga, tale riga viene completamente ignorata per tutte le modifiche future. Poiché le righe di un batch non sono deterministiche, le righe di un batch non riuscito potrebbero terminare in batch diversi nelle chiamate successive. Ciò significa che non tutte le righe nel batch non riuscito verranno necessariamente ignorate. Se altre righe nel batch causavano l'eccezione, le righe "valide" potrebbero terminare in un batch diverso che non ha esito negativo nelle chiamate future.