Applicazioni intelligenti
Si applica a:![]() database SQL di Azure
database SQL di Azure![]() database SQL in Fabric
database SQL in Fabric
Questo articolo offre una panoramica dell'uso di opzioni di intelligenza artificiale ,ad esempio OpenAI e vettori, per creare applicazioni intelligenti con database SQL di Azure e database SQL di Infrastruttura, che condivide molte di queste funzionalità di database SQL di Azure.
Per campioni ed esempi, visitare il Repository di esempi di intelligenza artificiale SQL.
Guardare questo video nella serie Nozioni di base sul database SQL di Azure per una breve panoramica sulla creazione di un'applicazione AI-ready:
Panoramica
I modelli linguistici (LLM) di grandi dimensioni consentono agli sviluppatori di creare applicazioni basate su intelligenza artificiale con un’esperienza utente familiare.
L’uso di LLM nelle applicazioni offre un valore aggiunto e un’esperienza utente migliorata quando i modelli possono accedere ai dati corretti, al momento giusto, dal database dell’applicazione. Questo processo è noto come Generazione aumentata di recupero (RAG) e database SQL di Azure e il database SQL dell'infrastruttura hanno molte funzionalità che supportano questo nuovo modello, rendendolo un ottimo database per creare applicazioni intelligenti.
I collegamenti seguenti forniscono codice di esempio di varie opzioni per creare applicazioni intelligenti:
| Opzione IA | Descrizione |
|---|---|
| OpenAI di Azure | Generare incorporamenti per RAG e integrazioni con qualsiasi modello supportato da Azure OpenAI. |
| Vettori | Informazioni su come archiviare ed eseguire query sui vettori del database. |
| Azure AI Search | Usare il database insieme a Ricerca intelligenza artificiale di Azure per eseguire il training di LLM sui dati. |
| Applicazioni intelligenti | Informazioni su come creare una soluzione end-to-end con un modello comune che può essere replicato in qualsiasi scenario. |
| Capacità di Copilot nel database SQL di Azure | Ulteriori informazioni sull'insieme di esperienze assistite dall'intelligenza artificiale progettate per semplificare la progettazione, il funzionamento, l'ottimizzazione e l'integrità delle applicazioni basate sul database SQL di Azure. |
| Competenze di Copilot nel database SQL dell'infrastruttura | Informazioni sul set di esperienze basate su intelligenza artificiale progettate per semplificare la progettazione, l'operazione, l'ottimizzazione e l'integrità delle applicazioni basate su database SQL di Fabric. |
Concetti chiave per l'implementazione di RAG con Azure OpenAI
Questa sezione include i concetti chiave fondamentali per l'implementazione di RAG con Azure OpenAI in database SQL di Azure o nel database SQL dell'infrastruttura.
Generazione aumentata di recupero (RAG)
RAG è una tecnica che migliora la capacità dell’LLM di produrre risposte pertinenti e informative recuperando dati aggiuntivi da origini esterne. Ad esempio, RAG può eseguire query su articoli o documenti contenenti conoscenze specifiche del dominio correlate alla domanda o alla richiesta dell’utente. LLM può quindi usare i dati recuperati come riferimento durante la generazione della risposta. Ecco un esempio di un modello RAG semplice che usa database SQL di Azure:
- Inserire dati in una tabella.
- Collegamento del database SQL di Azure a Azure AI Search.
- Creare un modello GPT4 di Azure OpenAI e collegarlo a Azure AI Search.
- Chattare e porre domande sui dati con il modello OpenAI di Azure sottoposto a training dall’applicazione e dal database SQL di Azure.
Il modello RAG, con progettazione dei prompt, mira a migliorare la qualità della risposta offrendo informazioni più contestuali al modello. RAG consente al modello di applicare una knowledge base più ampia incorporando origini esterne pertinenti nel processo di generazione, ottenendo risposte più complete e informate. Per altre informazioni sui LLM di grounding, vedere LLM di grounding - Hub della community Microsoft.
Prompt e loro progettazione
Per prompt si intende testo o informazioni specifiche che fungono da istruzione a un LLM o come dati contestuali su cui l’LLM può basarsi. Può assumere varie forme, ad esempio una domanda, un’istruzione o anche un frammento di codice.
Di seguito è riportato un elenco di prompt che possono essere usati per generare una risposta da un LLM:
- Istruzioni: fornire direttive all’LLM
- Contenuto primario: fornisce informazioni all’LLM per l’elaborazione
- Esempi: consentono di definire la condizione del modello per un'attività o un processo specifico
- Segnali: indirizzano l'output dell'LLM nella direzione giusta
- Supporto del contenuto: rappresenta informazioni supplementari che l'LLM può usare per generare l'output
Il processo di creazione di prompt validi per uno scenario è denominato progettazione di prompt. Per altre informazioni sulle richieste e sulle procedure consigliate per la progettazione dei prompt, vedere Servizio OpenAI di Azure.
OAuth
I token sono piccoli blocchi di testo generati suddividendo il testo di input in segmenti più piccoli. Questi segmenti possono essere parole o gruppi di caratteri, che variano in lunghezza da un singolo carattere a un'intera parola. Ad esempio, la parola hamburger verrebbe suddivisa in token come ham, bur e ger mentre una parola breve e comune come pear verrebbe considerata un singolo token.
In Azure OpenAI il testo di input fornito all'API viene trasformato in token (tokenizzati). Il numero di token elaborati in ogni richiesta API dipende da fattori quali la lunghezza dei parametri di input, output e richiesta. La quantità di token elaborati influisce anche sul tempo di risposta e sulla produttività dei modelli. Vi sono limiti al numero di token che ogni modello può accettare in una singola richiesta/risposta da Azure OpenAI. Per altre informazioni, vedere Quote e limiti del Servizio OpenAI di Azure.
Vettori
I vettori sono matrici ordinate di numeri (in genere float) che possono rappresentare informazioni su alcuni dati. Ad esempio, un’immagine può essere rappresentata come vettore di valori pixel oppure una stringa di testo come un vettore o valori ASCII. Il processo per trasformare i dati in un vettore è denominato vettorializzazione. Per altre informazioni, vedere Vettori.
Incorporamenti
Gli incorporamenti sono vettori che rappresentano caratteristiche importanti dei dati. Gli incorporamenti vengono spesso appresi con un modello di Deep Learning e i modelli di apprendimento automatico e intelligenza artificiale li usano come funzionalità. Gli incorporamenti possono inoltre acquisire la somiglianza semantica tra concetti simili. Ad esempio, durante la generazione di un incorporamento per le parole person e human, ci si aspetterebbe che gli incorporamenti (rappresentazione vettoriale) siano simili in valore, poiché anche le parole sono semanticamente simili.
Azure OpenAI offre modelli per creare incorporamenti da dati di testo. Il servizio suddivide il testo in token e genera incorporamenti usando modelli sottoposti a training preliminare da OpenAI. Per altre informazioni, consultare Creazione di incorporamenti con Azure OpenAI.
Ricerca vettoriale
Per ricerca vettoriale si intende il processo di ricerca di tutti i vettori in un set di dati semanticamente simile a un vettore di query specifico. Pertanto, un vettore di query per la parola human cerca nell’intero dizionario parole semanticamente simili e deve trovare la parola person come corrispondenza di chiusura. Questa vicinanza o distanza viene misurata usando una metrica di somiglianza, ad esempio la somiglianza del coseno. I vettori più vicini sono in somiglianza; il più piccolo è la distanza tra di essi.
Si consideri uno scenario in cui si esegue una query su milioni di documenti per trovare nei dati a disposizione quelli più simili. È possibile creare incorporamenti per i dati ed eseguire query sui documenti usando Azure OpenAI. Dopodiché, si può eseguire una ricerca vettoriale per trovare i documenti più simili dal set di dati. Tuttavia, l’esecuzione di una ricerca vettoriale in pochi esempi è semplice, mentre farlo in migliaia o milioni di punti dati diventa complesso. Esistono anche compromessi tra la ricerca completa e i metodi di ricerca basate sull’approssimazione del vicino più prossimo, tra cui latenza, velocità effettiva, accuratezza e costi, che dipendono tutti dai requisiti dell’applicazione.
I vettori in database SQL di Azure possono essere archiviati e sottoposti a query in modo efficiente, come descritto nelle sezioni successive, consentendo la ricerca esatta più vicina con prestazioni elevate. Non è necessario decidere tra precisione e velocità: è possibile avere entrambi. L’archiviazione di incorporamenti di vettori insieme ai dati in una soluzione integrata riduce al minimo la necessità di gestire la sincronizzazione dei dati e accelera il time-to-market per lo sviluppo di applicazioni IA.
OpenAI di Azure
L’incorporamento è il processo di rappresentazione del mondo reale come dati. Testo, immagini o suoni possono essere convertiti in incorporamenti. I modelli OpenAI di Azure sono in grado di trasformare le informazioni del mondo reale in incorporamenti. I modelli sono disponibili come endpoint REST e pertanto possono essere facilmente utilizzati dal database SQL di Azure usando la stored procedure di sistema sp_invoke_external_rest_endpoint:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
L’uso di una chiamata a un servizio REST per ottenere incorporamenti è solo una delle opzioni di integrazione disponibili quando si lavora con database SQL e OpenAI. È possibile consentire a qualsiasi modello disponibile di accedere ai dati archiviati nel database SQL di Azure per creare soluzioni in cui gli utenti possono interagire con i dati, come nell’esempio seguente.
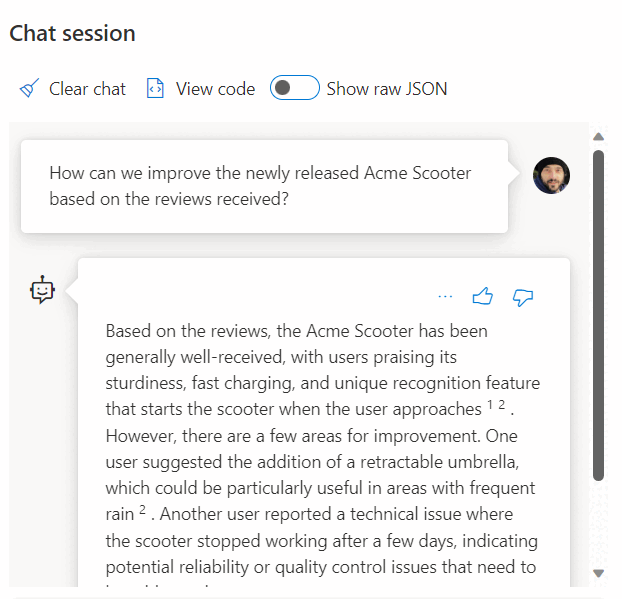
Per altri esempi sull’uso di database SQL e OpenAI, vedere gli articoli seguenti:
- Generare immagini con il Servizio Azure OpenAI (DALL-E) e database SQL di Azure
- Uso di endpoint REST OpenAI con il database SQL di Azure
Vettori
Tipo di dati vettoriali
Nel novembre 2024, il nuovo tipo di dati vector è stato introdotto in database SQL di Azure.
Il tipo di vettore dedicato consente l'archiviazione efficiente e ottimizzata dei dati vettoriali e include un set di funzioni che consentono agli sviluppatori di semplificare l'implementazione della ricerca vettoriale e di somiglianza. Il calcolo della distanza tra due vettori può essere eseguito in una riga di codice usando la nuova VECTOR_DISTANCE funzione. Per altre informazioni sul tipo di dati vector e sulle funzioni correlate, vedere Panoramica dei vettori nel motore di database SQL.
Ad esempio:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Vettori nelle versioni precedenti di SQL Server
Anche se le versioni precedenti del motore di SQL Server, fino a e incluso SQL Server 2022, non hanno un tipo di vettore nativo, un vettore non è altro che una tupla ordinata e i database relazionali sono ideali per la gestione delle tuple. Si può pensare a una tupla come il termine formale per la riga di una tabella.
Il database SQL di Azure supporta anche gli indici columnstore e l’esecuzione in modalità batch. Un approccio basato su vettori viene usato per l’elaborazione in modalità batch, il che significa che ogni colonna in un batch ha la propria posizione di memoria in cui è archiviata come vettore. Ciò consente un’elaborazione più rapida ed efficiente dei dati in batch.
Di seguito è riportato un esempio che illustra come un vettore può essere archiviato nel database SQL:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Per un esempio che usa un sottoinsieme comune di articoli di Wikipedia con incorporamenti già generati con OpenAI, consultare Ricerca di somiglianza vettoriale con database SQL di Azure e OpenAI.
Un’altra opzione per sfruttare la ricerca vettoriale nel database SQL di Azure è l’integrazione con Azure per intelligenza artificiale usando le funzionalità di vettorializzazione integrate: Ricerca vettoriale con database SQL di Azure e Azure AI Search
Azure AI Search
Implementare modelli RAG con database SQL di Azure e Azure AI Search. È possibile eseguire modelli di chat supportati sui dati archiviati nel database SQL di Azure, senza dover eseguire il training o ottimizzare i modelli, grazie all’integrazione di Azure AI Search con Azure OpenAI e il database SQL di Azure. L’esecuzione di modelli sui dati consente di chattare e analizzare i dati con maggiore precisione e velocità.
- Azure OpenAI sui dati
- Generazione aumentata di recupero (RAG) in Azure AI Search
- Ricerca vettoriale con database SQL di Azure e Azure AI Search
Applicazioni intelligenti
Il database SQL di Azure può essere usato per creare applicazioni intelligenti che includono funzionalità IA, ad esempio i suggerimenti e la generazione aumentata di recupero (RAG) come illustrato nel diagramma seguente:

Per un esempio end-to-end per creare un'applicazione abilitata all'intelligenza artificiale utilizzando le sessioni astratte come set di dati di esempio, vedere:
- Come è stato creato uno strumento di raccomandazione di sessione in 1 ora usando OpenAI.
- Utilizzo della Retrieval Augmented Generation per creare un assistente di sessione della conferenza
Integrazione di LangChain
LangChain è un noto framework per lo sviluppo di applicazioni basate su modelli linguistici. Per esempi che illustrano come è possibile usare LangChain per creare un chatbot sui propri dati, vedere:
- Pacchetto PyPI langchain-sqlserver
Alcuni esempi sull'uso di Azure SQL con LangChain:
Esempi completi:
- Creare un chatbot sui propri dati in 1 ora con Azure SQL, Langchain e Chainlit: creare un chatbot usando il modello RAG sui propri dati usando Langchain per orchestrare le chiamate LLM e Chainlit per l'interfaccia utente.
- Creazione di un copilota di database per Azure SQL con Azure OpenAI GPT-4: creare un'esperienza simile a un copilota per eseguire query sui database usando il linguaggio naturale.
Integrazione del kernel semantico
Il kernel semantico è un SDK open source che consente di compilare facilmente agenti che possono chiamare il codice esistente. Come SDK altamente estendibile, è possibile usare il kernel semantico con i modelli di OpenAI, OpenAI di Azure, Hugging Face e altro ancora. Combinando il codice C#, Python e Java esistente con questi modelli, è possibile creare agenti che rispondono a domande e automatizzare i processi.
Di seguito è riportato un esempio di facilità con cui il kernel semantico consente di creare una soluzione abilitata per l'intelligenza artificiale:
- Il chatbot finale?: creare un chatbot sui propri dati usando sia i modelli NL2SQL che RAG per l'esperienza utente finale.
Capacità di Microsoft Copilot in Database SQL di Azure
Le capacità di Microsoft Copilot nel database SQL di Azure (anteprima) è un set di esperienze assistite dall'intelligenza artificiale progettate per semplificare la progettazione, il funzionamento, l'ottimizzazione e l'integrità delle applicazioni basate sul database SQL di Azure. Copilot migliora la produttività offrendo la conversione dal linguaggio naturale a SQL e l'aiuto online per l'amministrazione del database.
Copilot fornisce risposte pertinenti alle domande degli utenti, semplificando la gestione dei database sfruttando contesto del database, documentazione, viste a gestione dinamica, Query Store e altre fonti di informazioni. Ad esempio:
- Gli amministratori di database possono gestire in modo indipendente i database e risolvere i problemi oppure venire a conoscenza di altre informazioni sulle prestazioni e sulle funzionalità del database.
- Gli sviluppatori possono porre domande sui dati via testo o conversazione per generare una query T-SQL. Gli sviluppatori possono anche imparare a scrivere query più velocemente tramite spiegazioni dettagliate della query generata.
Nota
Le capacità di Microsoft Copilot nel database SQL di Azure sono attualmente disponibili in anteprima per un numero limitato di early adopter. Per iscriversi a questo programma, visitare Richiedere l'accesso a Copilot in database SQL di Azure: Anteprima.
L'anteprima di Copilot per database SQL di Azure include due esperienze con il portale di Azure:
| Posizione del portale | Esperienze |
|---|---|
| Editor di query del portale di Azure | Linguaggio naturale in SQL: questa esperienza all'interno dell'editor di query portale di Azure per database SQL di Azure converte le query in linguaggio naturale in SQL, rendendo le interazioni del database più intuitive. Per un'esercitazione ed esempi di funzionalità del linguaggio naturale per SQL, vedere linguaggio naturale a SQL nell'editor di query del portale di Azure (anteprima). |
| Microsoft Copilot per Azure | Integrazione con Azure Copilot: questa esperienza aggiunge le competenze di Azure SQL a Microsoft Copilot per Azure, offrendo ai clienti assistenza autoguidata e consentendo loro di gestire i propri database e risolvere i problemi in modo indipendente. |
Per ulteriori informazioni, vedere Domande frequenti sulle capacità di Microsoft Copilot nel database SQL di Azure (anteprima).
Competenze di Microsoft Copilot nel database SQL di Infrastruttura (anteprima)
Copilot per il database SQL in Microsoft Fabric (anteprima) include un'assistenza integrata per l'intelligenza artificiale con le funzionalità seguenti:
Completamento del codice: iniziare a scrivere T-SQL nell'editor di query SQL e Copilot genererà automaticamente un suggerimento di codice per completare la query. Il tasto TAB accetta il suggerimento del codice o continua a digitare per ignorare il suggerimento.
Azioni rapide: nella barra multifunzione dell'editor di query SQL le opzioni Correzione e spiegazione sono azioni rapide. Evidenziare una query SQL di propria scelta e selezionare uno dei pulsanti azione rapida per eseguire l'azione selezionata nella query.
Correggi: Copilot può correggere gli errori nel codice man mano che si verificano messaggi di errore. Gli scenari di errore possono includere un codice T-SQL non corretto o non supportato, ortografie errate e altro ancora. Copilot fornirà anche commenti che spiegano le modifiche e suggeriscono le procedure consigliate per SQL.
Spiegazione: Copilot può fornire spiegazioni in linguaggio naturale della query SQL e dello schema del database in formato commenti.
Riquadro chat: usare il riquadro chat per porre domande a Copilot tramite il linguaggio naturale. Copilot risponde con una query SQL generata o un linguaggio naturale in base alla domanda posta.
Linguaggio naturale per SQL: generare codice T-SQL da richieste di testo normale e ottenere suggerimenti di domande da porre per accelerare il flusso di lavoro.
Domande e risposte basate su documenti: porre domande copilot sulle funzionalità generali del database SQL e risponde in linguaggio naturale. Copilot consente anche di trovare la documentazione correlata alla richiesta.
Copilot per il database SQL usa nomi di tabella e vista, nomi di colonna, chiave primaria e metadati di chiave esterna per generare codice T-SQL. Copilot per il database SQL non usa i dati nelle tabelle per generare suggerimenti T-SQL.
Contenuto correlato
- Creare e distribuire una risorsa del Servizio OpenAI di Azure
- Incorporamento di modelli
- Campioni ed esempi di intelligenza artificiale SQL
- Domande frequenti sulle capacità di Microsoft Copilot nel database SQL di Azure (anteprima)
- Domande frequenti sull’IA responsabile per Microsoft Copilot per Azure (anteprima)