Modello di acquisto vCore - Database SQL di Azure
si applica a:![]() database SQL di Azure
database SQL di Azure
Questo articolo esamina il modello di acquisto vCore per il Database SQL di Azure.
Panoramica
Un core virtuale (vCore) rappresenta una CPU logica e offre la possibilità di scegliere le caratteristiche fisiche dell'hardware (ad esempio, il numero di core, la memoria e le dimensioni di archiviazione). Il modello di acquisto basato su vCore offre flessibilità, controllo, trasparenza del consumo di singole risorse e un modo semplice per convertire i requisiti dei carichi di lavoro locali nel cloud. Questo modello ottimizza il prezzo e consente di scegliere risorse di calcolo, memoria e archiviazione in base alle esigenze del carico di lavoro.
Nel modello di acquisto basato su vCore i costi dipendono dalla scelta e dall'utilizzo di:
- Livello di servizio
- Configurazione hardware
- Risorse di calcolo (il numero di vCore e la quantità di memoria)
- Archiviazione di database riservata
- Archiviazione effettiva del backup
Importante
Le risorse di calcolo, le operazioni di I/O e archiviazione dei dati e dei log sono addebitate per ogni database o pool elastico. L'archiviazione di backup viene addebitata per ogni database. Per informazioni dettagliate sui prezzi, vedere la pagina dei prezzi del database SQL di Azure .
Confrontare i modelli di acquisto vCore e DTU
Il modello di acquisto vCore usato dal database SQL di Azure offre diversi vantaggi rispetto al modello di acquisto basato su DTU :
- Limiti di calcolo, memoria, I/O e archiviazione superiori.
- Scelta della configurazione hardware per soddisfare meglio i requisiti di calcolo e memoria del carico di lavoro.
- Sconti sui prezzi per Vantaggio Azure Hybrid (AHB).
- Maggiore trasparenza nei dettagli hardware che alimentano il calcolo, che facilita la pianificazione delle migrazioni dalle distribuzioni locali.
- I prezzi dell'istanza riservata sono disponibili solo per il modello di acquisto vCore.
- Maggiore granularità di scalabilità con più dimensioni di calcolo disponibili.
Per informazioni sulla scelta tra i modelli di acquisto vCore e DTU, vedere le differenze tra i modelli di acquisto basati su VCore e DTU.
Calcolare
Il modello di acquisto basato su vCore ha un livello di calcolo con provisioning e un livello di calcolo serverless. Nel livello di calcolo fornito, il costo di calcolo riflette la capacità totale di calcolo continuamente assegnata all'applicazione, indipendentemente dall'attività del carico di lavoro. Scegliere l'allocazione delle risorse più adatta alle esigenze aziendali in base ai requisiti di vCore e memoria, quindi aumentare e ridurre le risorse in base alle esigenze del carico di lavoro. Nel livello di calcolo serverless per il database SQL di Azure le risorse di calcolo vengono ridimensionate automaticamente in base alla capacità del carico di lavoro e fatturate per la quantità di calcolo usata, al secondo.
Per riepilogare:
- Mentre il livello di calcolo con provisioning fornisce una quantità specifica di risorse di calcolo continuamente fornite indipendentemente dall'attività del carico di lavoro, il livello di calcolo serverless ridimensiona automaticamente le risorse di calcolo in funzione dell'attività del carico di lavoro.
- Mentre il livello di calcolo con provisioning fattura per la quantità di calcolo di cui è stato effettuato il provisioning a un prezzo fisso all'ora, il livello di calcolo serverless fattura per la quantità di calcolo usata, al secondo.
Indipendentemente dal livello di calcolo, tre repliche secondarie a disponibilità elevata aggiuntive vengono allocate automaticamente nel livello di servizio Business Critical per offrire resilienza elevata agli errori e ai failover rapidi. Queste repliche aggiuntive rendono il costo di circa 2,7 volte superiore rispetto al livello di servizio Generale. Analogamente, il costo di archiviazione più elevato per GB nel livello di servizio Business Critical riflette i limiti di I/O più elevati e una latenza inferiore dell'archiviazione SSD locale.
In Hyperscale i clienti controllano il numero di repliche a disponibilità elevata aggiuntive da 0 a 4 per ottenere il livello di resilienza richiesto dalle applicazioni controllando i costi.
Per altre informazioni sul calcolo nel database SQL di Azure, vedere risorse di calcolo (CPU e memoria).
Limiti delle risorse
Per i limiti delle risorse vCore, esaminare le configurazioni hardware disponibili e, quindi esaminare i limiti delle risorse per:
Archiviazione di dati e log
I fattori seguenti influiscono sulla quantità di spazio di archiviazione usato per i file di dati e di log e si applicano ai livelli Utilizzo generico e Business Critical.
- Ogni dimensione di calcolo supporta una dimensione massima configurabile dei dati, con un valore predefinito di 32 GB.
- Quando si configurano dimensioni massime dei dati, viene aggiunto automaticamente un ulteriore 30% di spazio di archiviazione fatturabile per il file di log.
- Nel livello di servizio Utilizzo generico,
tempdbutilizza l'archiviazione SSD locale e questo costo d'archiviazione è incluso nel prezzo vCore. - Nel livello di servizio Business Critical,
tempdbcondivide l'archiviazione SSD locale con i file di dati e di log, e il costo di archiviazionetempdbè incluso nel prezzo vCore. - Nei livelli Utilizzo generico e Business Critical vengono addebitate le dimensioni massime di archiviazione configurate per un database o un pool elastico.
- Per il database SQL è possibile selezionare qualsiasi dimensione massima dei dati compresa tra 1 GB e le dimensioni massime di archiviazione supportate, in incrementi di 1 GB.
Le considerazioni sull'archiviazione seguenti si applicano a Hyperscale:
- La dimensione massima dell'archiviazione dei dati è impostata su 128 TB e non è configurabile.
- Vengono addebitati solo i costi per l'archiviazione dati allocata, non per la massima capacità di archiviazione.
- Non ti vengono addebitati costi per l'archiviazione dei log.
-
tempdbusa l'archiviazione SSD locale e il relativo costo è incluso nel prezzo vCore. Per monitorare le dimensioni correnti di archiviazione dati allocate e usate nel database SQL, usare rispettivamente le metricheallocated_data_storage earchiviazione Monitoraggio di Azure.
Per monitorare le dimensioni di archiviazione correnti allocate e usate dei singoli file di dati e di log in un database tramite T-SQL, usare la vista sys.database_files e la FILEPROPERTY(... , 'SpaceUsed').
Consiglio
In alcuni casi, potrebbe essere necessario compattare un database per recuperare lo spazio inutilizzato. Per altre informazioni, vedere Gestire lo spazio file nel database SQL di Azure.
Archiviazione di backup
L'archiviazione per i backup del database viene allocata per supportare le funzionalità di ripristino temporizzato (PITR) e di conservazione a lungo termine (LTR) del database SQL. Questa risorsa di archiviazione è separata dall'archiviazione di dati e file di log e viene fatturata separatamente.
- PITR: nei livelli Utilizzo Generico e Business Critical, i backup dei singoli database vengono copiati automaticamente in archiviazione Azure. Le dimensioni di archiviazione aumentano in modo dinamico man mano che vengono creati nuovi backup. L'archiviazione viene utilizzata per i backup completi, differenziali e dei log delle transazioni. Il consumo di archiviazione dipende dalla frequenza di modifica del database e dal periodo di conservazione configurato per i backup. È possibile configurare un periodo di conservazione separato per ogni database compreso tra 1 e 35 giorni per il database SQL. Una quantità di archiviazione di backup uguale alla dimensione massima configurata dei dati viene fornita senza costi aggiuntivi.
- LTR: è anche possibile configurare la conservazione a lungo termine dei backup completi per un massimo di 10 anni. Se si configura un criterio di conservazione a lungo termine, questi backup vengono archiviati automaticamente nell'archivio BLOB di Azure, ma è possibile controllare la frequenza con cui vengono copiati i backup. Per soddisfare requisiti di conformità diversi, è possibile selezionare periodi di conservazione diversi per i backup settimanali, mensili e/o annuali. La configurazione scelta determina la quantità di spazio di archiviazione usato per i backup con conservazione a lungo termine. Per altre informazioni, vedere conservazione dei backup a lungo termine.
Per la memorizzazione dei backup in Hyperscale, vedere Backup automatizzati per i database Hyperscale.
Livelli di servizio
Le opzioni del livello di servizio nel modello di acquisto vCore includono Utilizzo generico, Business Critical e Hyperscale. Il livello di servizio determina in genere il tipo di archiviazione e le prestazioni, le opzioni di disponibilità elevata e ripristino di emergenza e la disponibilità di determinate funzionalità, ad esempio In-Memory OLTP.
| caso d'uso | utilizzo generico | critico per il business | Hyperscale |
|---|---|---|---|
| migliore per | La maggior parte dei carichi di lavoro aziendali. Offre opzioni di calcolo e archiviazione scalabili, orientate al budget, bilanciate e scalabili. | Offre alle applicazioni aziendali la massima resilienza agli errori usando diverse repliche secondarie a disponibilità elevata e offre le prestazioni di I/O più elevate. | La più ampia gamma di carichi di lavoro, inclusi i carichi di lavoro con archiviazione altamente scalabile e requisiti di scalabilità per la lettura. Offre maggiore resilienza agli errori consentendo la configurazione di più repliche secondarie a disponibilità elevata. |
| dimensioni di calcolo | Da 2 a 128 vCore | Da 2 a 128 vCore | Da 2 a 128 vCore |
| tipo di archiviazione | Archiviazione remota Premium (per ogni istanza) | Archiviazione SSD locale super veloce (per istanza) | Archiviazione disaccoppiata con cache SSD locale (per replica di calcolo) |
| dimensioni di archiviazione | 1 GB - 4 TB | 1 GB - 4 TB | 10 GB - 128 TB |
| IOPS | 320 operazioni di I/O al secondo per vCore con 16.000 operazioni di I/O al secondo massime | 4.000 IOPS per vCore con 327.680 IOPS massime | 327.680 IOPS con SSD locale massimo Hyperscale è un'architettura multilivello con memorizzazione nella cache a più livelli. Le operazioni di I/O al secondo effettive dipendono dal carico di lavoro. |
| Memoria/vCore | 5,1 GB | 5,1 GB | 5,1 GB o 10,2 GB |
| backup | Una scelta tra archiviazione di backup con ridondanza geografica, ridondanza zonale o ridondanza locale, con durata di 1-35 giorni (impostazione predefinita 7 giorni) Conservazione a lungo termine disponibile fino a 10 anni |
È possibile scegliere un'archiviazione di backup con ridondanza geografica, di zona o locale, con una durata di conservazione di 1-35 giorni (impostazione predefinita 7 giorni) Conservazione a lungo termine disponibile fino a 10 anni |
Scelta di archiviazione con ridondanza locale, ridondanza della zona o archiviazione con ridondanza geografica Conservazione di 1-35 giorni (7 giorni per impostazione predefinita), con un massimo di 10 anni di conservazione a lungo termine disponibile |
| Disponibilità | Una replica, senza repliche con scalabilità per la lettura, disponibilità elevata con ridondanza della zona |
Tre repliche, una replica con scalabilità in lettura, disponibilità elevata con ridondanza della zona |
disponibilità elevata con ridondanza zonale |
| Prezzi e Fatturazione | I vCore , l'archiviazione riservata e l'archiviazione di backup sono addebitati. Le IOPS non sono addebitate. |
Sono a pagamento vCore , archiviazione riservata e archiviazione di backup. Le IOPS non vengono addebitate. |
vCore per ogni replica e lo spazio di archiviazione utilizzato sono addebitati. Non vengono addebitati gli IOPS. |
| modelli di sconto |
istanze riservate Azure Hybrid Benefit (non disponibile negli abbonamenti di sviluppo/test) Enterprise e sottoscrizioni con pagamento in base al consumoYou-Go offerte di sviluppo/test |
istanze riservate Vantaggio Azure Hybrid (non disponibile negli abbonamenti di sviluppo/test) Enterprise e sottoscrizioni con pagamento in base al consumoYou-Go offerte di sviluppo/test |
vantaggio Azure Hybrid (non disponibile nelle sottoscrizioni di sviluppo/test) 1 Enterprise e sottoscrizioni con pagamento in base al consumoYou-Go offerte di sviluppo/test |
| tabelle OLTP in memoria | No | Sì | nessuna |
1 prezzi semplificati per il database SQL Hyperscale presto disponibili. Per informazioni dettagliate, vedere il blog sui prezzi di
Per altri dettagli, consultare i limiti delle risorse per server logico, database singoloe database in pool.
Nota
Per altre informazioni sul contratto di servizio, vedere contratto di servizio per il database SQL di Azure
Utilizzo generico
Il modello di architettura per il livello di servizio Per utilizzo generico si basa su una separazione delle risorse di calcolo e archiviazione. Questo modello di architettura si basa sulla disponibilità elevata e sull'affidabilità dell'archiviazione BLOB di Azure che replica in modo trasparente i file di database e garantisce alcuna perdita di dati se si verifica un errore dell'infrastruttura sottostante.
La figura seguente mostra quattro nodi nel modello architetturale standard con i livelli di calcolo e archiviazione separati.
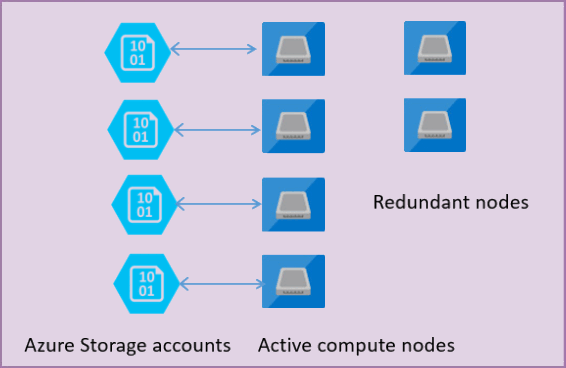
Nel modello architetturale per il livello di servizio Utilizzo generico sono disponibili due livelli:
- Strato di calcolo senza stato che esegue il processo
sqlservr.exee contiene solo dati temporanei e memorizzati nella cache, come ad esempio la cache del piano, il pool di buffer e il pool di archiviazione a colonne. Questo nodo senza stato viene gestito da Azure Service Fabric che inizializza il processo, controlla l'integrità del nodo ed esegue il failover in un'altra posizione, se necessario. - Livello dati con stato con file di database (.mdf/.ldf) archiviati nell'archivio BLOB di Azure. L'archiviazione BLOB di Azure garantisce che non si verifichi alcuna perdita di dati di qualsiasi record inserito in qualsiasi file di database. Azure Storage include una disponibilità/ridondanza dei dati integrata che garantisce il mantenimento di ogni record nei file di log o delle pagine dei file di dati anche in caso di blocco del processo.
Ogni volta che il motore di database o il sistema operativo viene aggiornato, una parte dell'infrastruttura sottostante va in errore, oppure se viene rilevato un problema critico nel processo di sqlservr.exe, Azure Service Fabric sposta il processo senza stato su un altro nodo di calcolo senza stato. È disponibile un set di nodi di riserva in attesa di eseguire un nuovo servizio di calcolo se si verifica un failover del nodo primario per ridurre al minimo il tempo di failover. I dati nel livello di archiviazione di Azure non sono interessati e i file di dati/log vengono allegati al processo appena inizializzato. Questo processo garantisce la disponibilità di 99,99% per impostazione predefinita e la disponibilità di 99,995% quando è abilitata la ridondanza della zona . Potrebbero verificarsi alcuni impatti sulle prestazioni per carichi di lavoro pesanti in fase di esecuzione a causa del tempo di transizione e del fatto che il nuovo nodo parte con la cache non ancora riscaldata.
Quando scegliere questo livello di servizio
Il livello di servizio Per utilizzo generico è il livello di servizio predefinito nel database SQL di Azure progettato per la maggior parte dei carichi di lavoro generici. Se è necessario un motore di database completamente gestito con un contratto di servizio predefinito e una latenza di archiviazione compresa tra 5 ms e 10 ms, il livello Utilizzo generico è l'opzione ideale.
Critico per il Business
Il modello di livello di servizio Business Critical si basa su un cluster di processi del motore di database. Questo modello di architettura si basa su un quorum di nodi del motore di database per ridurre al minimo gli effetti sulle prestazioni del carico di lavoro, anche durante le attività di manutenzione. Gli aggiornamenti e le patch del sistema operativo sottostante, dei driver e del motore di database vengono eseguiti in modo trasparente, con tempi di inattività minimi per gli utenti finali.
Nel modello Business Critical il calcolo e l'archiviazione sono integrati in ogni nodo. La replica dei dati tra i processi del motore di database in ogni nodo di un cluster a quattro nodi raggiunge la disponibilità elevata, con ogni nodo che usa unità SSD collegate localmente come archiviazione dati. Il diagramma seguente mostra come il livello di servizio Business Critical organizza le repliche del gruppo di disponibilità per formare un cluster di nodi del motore di database.

Sia il processo del motore di database che i file .mdf/.ldf sottostanti vengono inseriti nello stesso nodo con un'archiviazione SSD collegata localmente, fornendo bassa latenza al tuo carico di lavoro. La disponibilità elevata viene implementata usando una tecnologia simile a SQL Server gruppi di disponibilità AlwaysOn. Ogni database è un cluster di nodi di database con una replica primaria accessibile per i carichi di lavoro dei clienti e tre repliche secondarie contenenti copie di dati. La replica primaria invia costantemente le modifiche alle repliche secondarie per garantire che i dati siano disponibili nelle repliche secondarie se la replica primaria fallisce per qualsiasi motivo. Il failover viene gestito da Service Fabric e dal motore di database. Una replica secondaria diventa primaria e viene creata una nuova replica secondaria per garantire che nel cluster siano presenti nodi sufficienti. Il carico di lavoro viene reindirizzato automaticamente alla nuova replica primaria.
Inoltre, il cluster Business Critical dispone di una funzionalità predefinita di scalabilità orizzontale in lettura che offre una replica di sola lettura gratuita usata per eseguire query di sola lettura (ad esempio i report) che non influiscono sulle prestazioni del carico di lavoro nella replica primaria.
Quando scegliere questo livello di servizio
Il livello di servizio Business Critical è progettato per le applicazioni che richiedono risposte a bassa latenza dall'archiviazione SSD sottostante (in media 1-2 ms), un ripristino più rapido se l'infrastruttura sottostante fallisce, o la necessità di scaricare report, analisi e query di sola lettura sulla replica secondaria leggibile gratuita del database primario.
I motivi principali per cui scegliere il livello di servizio Business Critical anziché il livello Per utilizzo generico sono:
- requisiti di latenza di I/O bassa: i carichi di lavoro che necessitano di una risposta costantemente veloce dal livello di archiviazione (in media 1-2 millisecondi) devono usare il livello Business Critical.
- Carico di lavoro con query per reportistica e analisi dove è sufficiente una sola replica secondaria gratuita solo per la lettura.
- Maggiore resilienza e ripristino più rapido da errori. In caso di errore di sistema, il database nell'istanza primaria è disabilitato e una delle repliche secondarie diventa immediatamente il nuovo database primario di lettura/scrittura, pronto per elaborare le query.
- Protezione avanzata del danneggiamento dei dati. Poiché il livello Business Critical usa repliche di database dietro le quinte, il servizio utilizza il ripristino automatico delle pagine abilitato da mirroring e i gruppi di disponibilità per contribuire a mitigare la corruzione dei dati. Se una replica non riesce a leggere una pagina a causa di un problema di integrità dei dati, una nuova copia della pagina viene recuperata da un'altra replica, sostituendo la pagina illeggibile senza perdita di dati o tempi di inattività dei clienti. Questa funzionalità è disponibile nel livello Utilizzo generico se il database ha una replica geografica secondaria.
- Maggiore disponibilità - Il livello Business Critical in una configurazione multi-zona di disponibilità offre resilienza ai guasti zonali e un livello di disponibilità superiore.
- Ripristino geografico rapido - Quando è configurata la replica geografica attiva, il livello tariffario Business Critical ha un Obiettivo del Punto di Ripristino (RPO) garantito di 5 secondi e un Obiettivo del Tempo di Ripristino (RTO) di 30 secondi per ciascuna delle 100% ore distribuite.
Iperscala
Il livello di servizio Hyperscale è adatto a tutti i tipi di carico di lavoro. L'architettura nativa del cloud offre risorse di calcolo e archiviazione scalabili in modo indipendente per supportare la più ampia gamma di applicazioni tradizionali e moderne. Le risorse di calcolo e archiviazione in Hyperscale superano sostanzialmente le risorse disponibili nei livelli Utilizzo generico e Business Critical.
Per altre informazioni, vedere livello di servizio Hyperscale per il database SQL di Azure.
Quando scegliere questo livello di servizio
Il livello di servizio Hyperscale rimuove molti dei limiti pratici tradizionalmente visti nei database cloud. Se la maggior parte degli altri database è limitata dalle risorse disponibili in un singolo nodo, i database nel livello di servizio Hyperscale non hanno limiti di questo tipo. Con l'architettura di archiviazione flessibile, un database Hyperscale aumenta in base alle esigenze e viene addebitata solo la capacità di archiviazione usata.
Oltre alle funzionalità di scalabilità avanzate, Hyperscale è un'ottima opzione per qualsiasi carico di lavoro, non solo per i database di grandi dimensioni. Con Hyperscale è possibile:
- Raggiungere con alta resilienza e un rapido ripristino dei guasti, controllando i costi scegliendo il numero di repliche ad alta disponibilità da 0 a 4.
- Migliorare a disponibilità elevata abilitando la ridondanza della zona per il calcolo e l'archiviazione.
- Raggiungi una bassa latenza di I/O (1-2 millisecondi in media) per la parte del database a cui si accede di frequente. Per i database di dimensioni inferiori, questa operazione può essere applicata all'intero database.
- Implementare un'ampia gamma di scenari di scalabilità orizzontale in lettura con repliche denominate.
- Approfitta della scalabilità rapida , senza attendere che i dati vengano copiati sull'archiviazione locale sui nuovi nodi.
- Goditi il backup continuo del database a impatto zero e il ripristino veloce .
- Soddisfare i requisiti di continuità aziendale utilizzando gruppi di failover e la replica geografica.
Configurazione hardware
Le configurazioni hardware comuni nel modello vCore includono serie standard (Gen5), serie Fsv2 e serie DC. Hyperscale offre anche un'opzione per la serie Premium e per l'hardware ottimizzato per la memoria della serie Premium. La configurazione hardware definisce i limiti di calcolo e memoria e altre caratteristiche che influiscono sulle prestazioni del carico di lavoro.
Alcune configurazioni hardware, ad esempio la serie standard (Gen5) possono usare più di un tipo di processore (CPU), come descritto in risorse di calcolo (CPU e memoria). Anche se un determinato database o pool elastico tende a rimanere sull'hardware con lo stesso tipo di CPU per molto tempo (in genere per più mesi), esistono alcuni eventi che possono causare lo spostamento di un database o di un pool nell'hardware che usa un tipo di CPU diverso.
È possibile spostare un database o un pool per diversi scenari, tra cui, ad esempio, quando:
- L'obiettivo del servizio viene modificato
- L'infrastruttura corrente in un data center sta raggiungendo i limiti di capacità
- L'hardware attualmente usato viene rimosso a causa della fine del ciclo di vita
- La configurazione con ridondanza di zona è abilitata, si sta spostando a un hardware diverso a causa della capacità disponibile.
Per alcuni carichi di lavoro, un passaggio a un tipo di CPU diverso può modificare le prestazioni. Il database SQL configura l'hardware con l'obiettivo di offrire prestazioni prevedibili del carico di lavoro anche se il tipo di CPU cambia, mantenendo le modifiche delle prestazioni all'interno di una banda ridotta. Tuttavia, nell'ampio spettro dei carichi di lavoro dei clienti nel database SQL e man mano che diventano disponibili nuovi tipi di CPU, è occasionalmente possibile visualizzare modifiche più evidenti nelle prestazioni, se un database o un pool passa a un tipo di CPU diverso.
Indipendentemente dal tipo di CPU usato, i limiti delle risorse per un database o un pool elastico ,ad esempio il numero di core, memoria, operazioni di I/O al secondo massime dei dati, frequenza massima dei log e numero massimo di ruoli di lavoro simultanei, rimangono invariati a condizione che il database rimanga nello stesso obiettivo di servizio.
Risorse di calcolo (CPU e memoria)
La tabella seguente confronta le risorse di calcolo in diverse configurazioni hardware e livelli di calcolo:
| Configurazione hardware | CPU | Memoria |
|---|---|---|
| Serie Standard (Gen5) |
Calcolo configurato - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, processori AMD EPYC 7763v (Milano) - Effettuare il provisioning di un massimo di 128 vCore (con hyperthreading) di calcolo serverless - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, processori AMD EPYC 7763v (Milano) - Scalabilità automatica fino a 80 vCore (con hyperthreading) - Il rapporto da memoria a vCore si adatta dinamicamente all'utilizzo della memoria e della CPU in base alla domanda del carico di lavoro e può essere pari a 24 GB per vCore. Ad esempio, in un determinato momento un carico di lavoro può usare ed essere fatturato per 240 GB di memoria e solo 10 vCores. |
Risorse computazionali fornite - 5,1 GB per vCore - Effettuare il provisioning di un massimo di 625 GB di calcolo serverless - Scalabilità automatica fino a 24 GB per vCore - Scalabilità automatica fino a 240 GB massimo |
| Serie Fsv2 | - Processori Intel® 8168 (Skylake) - Con una frequenza turbo sostenuta su tutti i nuclei di 3,4 GHz e una frequenza turbo massima su un singolo nucleo di 3,7 GHz. - Effettuare il provisioning di un massimo di 72 vCore (con hyperthreading) |
- 1,9 GB per vCore - Configurare fino a 136 GB |
| Serie DC | - Processori Intel® Xeon® E-2288G - Dotato di Intel Software Guard Extension (Intel SGX) - Effettuare il provisioning di un massimo di 8 vCores (fisici) |
4,5 GB per vCore |
* Nella visualizzazione a gestione dinamica sys.dm_user_db_resource_governance, la generazione hardware per i database che usano processori Intel® SP-8160 (Skylake) viene visualizzata come Gen6, la generazione hardware per i database che usano Intel® 8272CL (Cascade Lake) viene visualizzata come Gen7 e la generazione hardware per i database che usano Intel® Xeon® Platinum 8370C (Ice Lake) o AMD® EPYC® 7763v (Milano) viene visualizzata come Gen8. Per una determinata configurazione hardware e dimensioni di calcolo, i limiti delle risorse sono uguali indipendentemente dal tipo di CPU (Intel Broadwell, Skylake, Ice Lake, Cascade Lake o AMD Milano).
Per altre informazioni, vedere Limiti delle risorse per database singoli e pool elastici .
Per le risorse di calcolo e le specifiche del database Hyperscale, vedere risorse di calcolo Hyperscale.
Serie Standard (Gen5)
- L'hardware serie Standard (Gen5) offre risorse di calcolo e memoria bilanciate ed è adatto per la maggior parte dei carichi di lavoro del database.
L'hardware serie Standard (Gen5) è disponibile in tutte le aree pubbliche in tutto il mondo.
Serie Premium Hyperscale
- Le opzioni hardware della serie Premium usano la tecnologia cpu e memoria più recente di Intel e AMD. La serie Premium offre un aumento delle prestazioni di calcolo rispetto all'hardware della serie standard.
- L'opzione Serie Premium offre prestazioni CPU più veloci rispetto alle serie Standard e un numero più elevato di vCore massimi.
- L'opzione ottimizzata per la memoria della serie Premium offre il doppio della quantità di memoria rispetto alla serie Standard.
- Le serie standard, le serie Premium e le serie ottimizzate per memoria Premium sono disponibili per hyperscale pool elastici.
Per altre informazioni, vedere l'annuncio di serie Premium hyperscale.
Per le aree disponibili, vedere disponibilità Premium della serie Hyperscale.
Serie Fsv2
- La serie Fsv2 è una configurazione hardware ottimizzata per il calcolo che offre bassa latenza della CPU e velocità di clock elevata per i carichi di lavoro più impegnativi della CPU. Simile a Serie Premium Hyperscale configurazioni hardware, la serie Fsv2 è basata sulla più recente tecnologia CPU e memoria di Intel e AMD, consentendo ai clienti di sfruttare l'hardware più recente utilizzando database e pool elastici nel livello di servizio Generico.
- A seconda del carico di lavoro, la serie Fsv2 può offrire prestazioni della CPU maggiori per vCore rispetto ad altri tipi di hardware. Ad esempio, la dimensione di calcolo 72 vCore Fsv2 può offrire prestazioni della CPU superiori rispetto a 80 vCore nella Serie Standard (Gen5), a un costo inferiore.
- Fsv2 offre meno memoria e
tempdbper vCore rispetto ad altri hardware, quindi i carichi di lavoro sensibili a tali limiti potrebbero offrire prestazioni migliori nelle serie standard (Gen5).
La serie Fsv2 è supportata solo nel livello General Purpose. Per le aree in cui è disponibile la serie Fsv2, vedere disponibilità della serie Fsv2.
Serie DC
- L'hardware della serie DC usa processori Intel con tecnologia Intel SGX (Software Guard Extensions).
- La serie DC è necessaria per Always Encrypted con sicure enclave per carichi di lavoro che richiedono una protezione più avanzata delle enclave hardware, rispetto alle enclave basate sulla Sicurezza basata sulla virtualizzazione (VBS).
- La serie DC è progettata per carichi di lavoro che elaborano dati sensibili e richiedono funzionalità di elaborazione di query riservate, fornite da Always Encrypted con enclave sicuri.
- L'hardware della serie DC fornisce risorse di calcolo e memoria bilanciate.
La serie DC è supportata solo per il calcolo provisioning (il serverless non è supportato) e non supporta la ridondanza zonale. Per le aree in cui è disponibile la serie DC, vedere la disponibilità della serie DC .
Tipi di offerta di Azure supportati dalla serie DC
Per creare database o pool elastici nell'hardware della serie DC, la sottoscrizione deve essere un tipo di offerta a pagamento, tra cui pagamento in base al consumoYou-Go o Enterprise Agreement (EA). Per un elenco completo dei tipi di offerta di Azure supportati dalla serie DC, vedere offerte correnti senza limiti di spesa.
Selezionare la configurazione hardware
È possibile selezionare la configurazione hardware per un database o un pool elastico nel database SQL al momento della creazione. È anche possibile modificare la configurazione hardware di un database o di un pool elastico esistente.
Per selezionare una configurazione hardware durante la creazione di un database SQL o di un pool
Per informazioni dettagliate, vedere Creare un database SQL.
Nella scheda Informazioni di base, selezionare il collegamento Configura database nella sezione Calcolo + archiviazione, e quindi selezionare il collegamento Modifica configurazione.

Selezionare la configurazione hardware desiderata:

Per modificare la configurazione hardware di un database SQL o di un pool esistente
Per un database, nella pagina Panoramica, selezionare il collegamento piano tariffario.

Per un pool, nella pagina Panoramica selezionare Configura.
Seguire la procedura per modificare la configurazione e selezionare la configurazione hardware come descritto nei passaggi precedenti.
Disponibilità hardware
Per informazioni sull'hardware di generazione precedente, vedere Disponibilità hardware di generazione precedente.
Serie Standard (Gen5)
L'hardware serie Standard (Gen5) è disponibile in tutte le aree pubbliche in tutto il mondo.
Serie Premium Hyperscale
L'hardware ottimizzato per la memoria premium e la serie Premium del livello di servizio Hyperscale sono disponibili per database singoli e pool elastici nelle aree seguenti:
- Australia orientale **
- Australia sud-orientale
- Brasile meridionale **,*
- Canada centrale **
- Canada orientale
- Asia orientale
- Europa settentrionale **
- Europa occidentale **
- Francia centrale
- Germania centro-occidentale
- India centrale
- India meridionale
- Giappone orientale **
- Giappone occidentale
- Sud-est asiatico**
- Svizzera settentrionale
- Svezia centrale **,*
- Regno Unito meridionale **
- Regno Unito occidentale *
- Stati Uniti centrali **
- Stati Uniti orientali **
- Stati Uniti orientali 2 **
- Stati Uniti centro-settentrionali
- Stati Uniti centro-meridionali
- Stati Uniti centro-occidentali
- Stati Uniti occidentali 1
- Stati Uniti occidentali 2 **
- Stati Uniti occidentali 3 **
* L'hardware ottimizzato per la memoria della serie Premium non è attualmente disponibile.
** Include il supporto per la ridondanza della zona .
Serie Fsv2
La serie Fsv2 è disponibile nelle aree seguenti:
- Australia centrale
- Australia centrale 2
- Australia orientale
- Australia sud-orientale
- Brasile meridionale
- Canada centrale
- Asia orientale
- Europa settentrionale
- Europa occidentale
- Francia centrale
- India centrale
- Corea centrale
- Corea del Sud
- Sudafrica settentrionale
- Sud-est asiatico
- Regno Unito meridionale
- Regno Unito occidentale
- Stati Uniti orientali
- Stati Uniti occidentali 2
Serie DC
La serie DC è disponibile nelle aree seguenti:
- Canada centrale
- Europa occidentale
- Europa settentrionale
- Sud-est asiatico
- Regno Unito meridionale
- Stati Uniti occidentali
- Stati Uniti orientali
Se hai bisogno di serie DC in un'area attualmente non supportata, inviare una richiesta di supporto. Nella pagina informazioni di base specificare quanto segue:
- Per Tipo di problema, selezionare Tecnico.
- Specificare la sottoscrizione desiderata per l'hardware. Seleziona Avanti.
- Per Tipo di Servizio, selezionare Database SQL.
- Per Resource, selezionare domanda generica.
- Per Riepilogo, specificare la disponibilità hardware desiderata e la regione.
- Per tipo di problema, selezionare Sicurezza, Privacy e Conformità.
- Per sottotipo di problema, selezionare Always Encrypted.

Hardware di generazione precedente
Quarta Generazione
L'hardware Gen4 è stato ritirato e non è disponibile per il provisioning, l'espansione o la riduzione delle risorse. Migra il tuo database a una generazione hardware supportata per una gamma più ampia di scalabilità per vCore e archiviazione, rete accelerata, migliori prestazioni di I/O e latenza minima. Esaminare le opzioni hardware per database singoli e le opzioni hardware per i pool elastici. Per altre informazioni, vedere Supporto è terminato per l'hardware di quarta generazione nel database SQL di Azure.
Passaggio successivo
Avvio rapido di : Creare un database singolo - Database SQL di Azure