Esercitazioni: Configurare i gruppi di disponibilità per SQL Server nelle macchine virtuali Ubuntu in Azure
Questa esercitazione illustra come:
- Creare le macchine virtuali, inserirle nel set di disponibilità
- Abilitare la disponibilità elevata
- Creare un cluster Pacemaker
- Configurare un agente di isolamento mediante la creazione di un dispositivo STONITH
- Installare SQL Server e mssql-tools in Ubuntu
- Configurare il gruppo di disponibilità Always On di SQL Server
- Configurare le risorse del gruppo di disponibilità nel cluster Pacemaker
- Testare un failover e l'agente di isolamento
Nota
Comunicazione senza distorsione
Questo articolo contiene riferimenti al termine slave, un termine che Microsoft considera offensivo se usato in questo contesto. Il termine viene visualizzato in questo articolo perché è attualmente incluso nel software. Quando il termine verrà rimosso dal software, verrà rimosso dall'articolo.
Questa esercitazione usa l'interfaccia della riga di comando di Azure per distribuire le risorse in Azure.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Usare l'ambiente Bash in Azure Cloud Shell. Per altre informazioni, vedere Avvio rapido per Bash in Azure Cloud Shell.

Se si preferisce eseguire i comandi di riferimento dell'interfaccia della riga di comando in locale, installare l'interfaccia della riga di comando di Azure. Per l'esecuzione in Windows o macOS, è consigliabile eseguire l'interfaccia della riga di comando di Azure in un contenitore Docker. Per altre informazioni, vedere Come eseguire l'interfaccia della riga di comando di Azure in un contenitore Docker.
Se si usa un'installazione locale, accedere all'interfaccia della riga di comando di Azure con il comando az login. Per completare il processo di autenticazione, seguire la procedura visualizzata nel terminale. Per altre opzioni di accesso, vedere Accedere tramite l'interfaccia della riga di comando di Azure.
Quando richiesto, installare l'estensione dell'interfaccia della riga di comando di Azure al primo utilizzo. Per altre informazioni sulle estensioni, vedere Usare le estensioni con l'interfaccia della riga di comando di Azure.
Eseguire az version per trovare la versione e le librerie dipendenti installate. Per eseguire l'aggiornamento alla versione più recente, eseguire az upgrade.
- Questo articolo richiede l'interfaccia della riga di comando di Azure versione 2.0.30 o successiva. Se si usa Azure Cloud Shell, la versione più recente è già installata.
Creare un gruppo di risorse
Se sono presenti più sottoscrizioni, selezionare la sottoscrizione in cui dovranno essere distribuite le risorse.
Usare il comando seguente per creare un gruppo di risorse <resourceGroupName> in un'area. Sostituire <resourceGroupName> con il nome desiderato. In questa esercitazione viene usato East US 2. Per altre informazioni, vedere la guida di Avvio rapido seguente.
az group create --name <resourceGroupName> --location eastus2
Creare un set di disponibilità
Il passaggio successivo prevede la creazione di un set di disponibilità. Eseguire il comando seguente in Azure Cloud Shell e sostituire <resourceGroupName> con il nome del gruppo di risorse. Scegliere un nome per <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Al termine del comando, verranno restituiti i risultati seguenti:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Creare una rete virtuale e una subnet
Creare una subnet denominata con un intervallo di indirizzi IP preassegnato. Sostituire questi valori nel comando seguente:
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24Il comando precedente crea una rete virtuale e una subnet contenente un intervallo IP personalizzato.
Creare macchine virtuali Ubuntu all'interno del set di disponibilità
Ottenere un elenco di immagini di macchine virtuali che offrono il sistema operativo basato su Ubuntu in Azure.
az vm image list --all --offer "sql2022-ubuntupro2004"Quando si cercano le immagini BYOS, verranno visualizzati i risultati seguenti:
[ { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230808", "version": "16.0.230808" } ]In questa esercitazione viene usato
Ubuntu 20.04.Importante
Per configurare il gruppo di disponibilità, i nomi delle macchine virtuali devono contenere meno di 15 caratteri. Il nome utente non può contenere caratteri maiuscoli e le password devono contenere tra 12 e 72 caratteri.
Creare tre macchine virtuali all'interno del set di disponibilità. Sostituire questi valori nel comando seguente:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>, ad esempio "Standard_D16_v3"<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "Canonical:0001-com-ubuntu-server-jammy:20_04-lts-gen2:latest" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
Il comando precedente crea le macchine virtuali usando la rete virtuale definita in precedenza. Per altre informazioni sulle diverse configurazioni, vedere l'articolo con le informazioni di riferimento su az vm create.
Il comando include anche il --os-disk-size-gb parametro per creare un'unità del sistema operativo personalizzata di 128 GB. Successivamente, configurare Logical Volume Manager (LVM) se è necessario espandere i volumi delle cartelle appropriati per l'installazione.
Al termine del comando per ogni macchina virtuale, si otterrà un risultato simile al seguente:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/ubuntu1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Testare la connessione alle macchine virtuali create
Connettersi a ciascuna macchina virtuale usando il comando seguente in Azure Cloud Shell. Se non si riesce a trovare gli indirizzi IP della macchina virtuale, seguire questa guida di Avvio rapido in Azure Cloud Shell.
ssh <username>@<publicIPAddress>
Se la connessione viene stabilita, verrà visualizzato l'output seguente che rappresenta il terminale Linux:
[<username>@ubuntu1 ~]$
Digitare exit per uscire dalla sessione SSH.
Configurare l'accesso SSH senza password tra nodi
L'accesso SSH senza password consente alle macchine virtuali di comunicare tra loro usando chiavi pubbliche SSH. È necessario configurare le chiavi SSH in ogni nodo e copiare tali chiavi in ogni nodo.
Generare nuove chiavi SSH
Le dimensioni della chiave SSH necessarie sono 4.096 bit. In ogni macchina virtuale, passare alla cartella /root/.ssh ed eseguire il comando seguente:
ssh-keygen -t rsa -b 4096
Durante questo passaggio potrebbe essere richiesto di sovrascrivere un file SSH esistente. È necessario accettare questa richiesta. Non è necessario immettere una passphrase.
Copiare le chiavi SSH pubbliche
Su ogni macchina virtuale è necessario copiare la chiave pubblica dal nodo appena creato usando il ssh-copy-id comando. Se si vuole specificare la directory di destinazione nel nodo gestito, è possibile usare il -i parametro.
Nel comando seguente, l'account <username> può essere lo stesso account configurato per ogni nodo durante la creazione della macchina virtuale. È anche possibile usare l'rootaccount, ma questo non è consigliato in un ambiente di produzione.
sudo ssh-copy-id <username>@ubuntu1
sudo ssh-copy-id <username>@ubuntu2
sudo ssh-copy-id <username>@ubuntu3
Verificare l'accesso senza password da ogni nodo
Per verificare che la chiave pubblica SSH sia stata copiata in ogni nodo, usare il ssh comando da ogni nodo. Se le chiavi sono state copiate correttamente, non viene richiesta una password e la connessione ha esito positivo.
In questo esempio ci si connette al secondo e al terzo nodo dalla prima macchina virtuale (ubuntu1). Nel comando seguente <username> l'account può essere lo stesso account configurato per ogni nodo durante la creazione della macchina virtuale.
ssh <username>@ubuntu2
ssh <username>@ubuntu3
Ripetere questo processo da tutti e tre i nodi, in modo che ogni nodo possa comunicare con gli altri senza richiedere password.
Configurare la risoluzione dei nomi
È possibile configurare la risoluzione dei nomi usando DNS o modificando manualmente il etc/hosts file in ogni nodo.
Per altre informazioni su DNS e Active Directory, vedere Aggiungere un host di SQL Server in Linux a un dominio di Active Directory.
Importante
È consigliabile usare l'indirizzo IP privato nell'esempio precedente. Se in questa configurazione si usa l'indirizzo IP pubblico, l'installazione avrà esito negativo ed esporrebbe la macchina virtuale alle reti esterne.
Le macchine virtuali e il relativo indirizzo IP usati in questo esempio sono elencati come segue:
ubuntu1: 10.0.0.85ubuntu2: 10.0.0.86ubuntu3: 10.0.0.87
Abilitare la disponibilità elevata
Usare ssh per connettersi a ognuna delle 3 macchine virtuali e, dopo la connessione, eseguire i comandi seguenti per abilitare la disponibilità elevata.
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Installare e configurare Pacemaker in ogni nodo del cluster
Per iniziare a configurare il cluster Pacemaker, è necessario installare i pacchetti e gli agenti di risorse necessari. Eseguire i comandi seguenti in ognuna delle macchine virtuali:
sudo apt-get install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure
Procedere ora con la creazione della chiave di autenticazione nel server primario:
sudo corosync-keygen
La chiave di autenticazione viene generata nel /etc/corosync/authkey percorso. Copiare la chiave di autenticazione nei server secondari in questo percorso: /etc/corosync/authkey
sudo scp /etc/corosync/authkey username@ubuntu2:~
sudo scp /etc/corosync/authkey username@ubuntu3:~
Spostare la chiave di autenticazione dalla home directory a /etc/corosync.
sudo mv authkey /etc/corosync/authkey
Creare il cluster tramite i comandi seguenti:
cd /etc/corosync/
sudo vi corosync.conf
Modificare il file Corosync per rappresentare il contenuto come segue:
totem {
version: 2
secauth: off
cluster_name: demo
transport: udpu
}
nodelist {
node {
ring0_addr: 10.0.0.85
name: ubuntu1
nodeid: 1
}
node {
ring0_addr: 10.0.0.86
name: ubuntu2
nodeid: 2
}
node {
ring0_addr: 10.0.0.87
name: ubuntu3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
two_node: 0
}
qb {
ipc_type: native
}
logging {
fileline: on
to_stderr: on
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: no
debug: off
}
Copiare il corosync.conf file in altri nodi in /etc/corosync/corosync.conf:
sudo scp /etc/corosync/corosync.conf username@ubuntu2:~
sudo scp /etc/corosync/corosync.conf username@ubuntu3:~
sudo mv corosync.conf /etc/corosync/
Riavviare Pacemaker e Corosync e confermare lo stato:
sudo systemctl restart pacemaker corosync
sudo crm status
L'output è simile al seguente esempio:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by hacluster via crmd on ubuntu1
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* No resources
Configurare l'agente di isolamento
Configurare l'isolamento nel cluster. L'isolamento è l'isolamento di un nodo non riuscito in un cluster. Riavvia il nodo non riuscito, consentendo di arrestarlo, reimpostarlo e tornare indietro, tornando al cluster.
Per configurare l'isolamento, eseguire le azioni seguenti:
- Registrare una nuova applicazione in Microsoft Entra ID e creare un segreto
- Creare un ruolo personalizzato dal file JSON in PowerShell/CLI
- Assegnare il ruolo e l'applicazione alle macchine virtuali nel cluster
- Impostare le proprietà dell'agente di isolamento
Registrare una nuova applicazione in Microsoft Entra ID e creare un segreto
- Passare a Microsoft Entra ID nel portale e prendere nota dell'ID tenant.
- Selezionare Registrazioni app nel riquadro di spostamento sinistro, quindi selezionare Nuova registrazione.
- Immettere un nome, selezionare Account solo in questa directory dell'organizzazione.
- Per Tipo di applicazione, selezionare Web, immettere
http://localhostcome URL di accesso e quindi selezionare Registra. - Nel riquadro sinistro selezionare Certificati e segreti e quindi selezionare Nuovo segreto client.
- Immettere una descrizione e selezionare un periodo di scadenza.
- Prendere nota del valore del segreto, viene usato come password successiva e l'ID segreto viene usato come nome utente seguente.
- Selezionare "Panoramica" e prendere nota dell'ID applicazione. Viene usato come account di accesso seguente.
Creare un file JSON denominato fence-agent-role.json e aggiungere quanto segue (aggiungendo l'ID sottoscrizione):
{
"Name": "Linux Fence Agent Role-ap-server-01-fence-agent",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [],
"AssignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
]
}
Creare un ruolo personalizzato dal file JSON in PowerShell/CLI
az role definition create --role-definition fence-agent-role.json
Assegnare il ruolo e l'applicazione alle macchine virtuali nel cluster
- Per ognuna delle macchine virtuali nel cluster, selezionare Controllo di accesso (IAM) dal menu laterale.
- Selezionare Aggiungi un'assegnazione di ruolo (usare l'esperienza classica).
- Selezionare il ruolo creato in precedenza.
- Nell'elenco Seleziona immettere il nome dell'applicazione creata sopra.
È ora possibile creare la risorsa agente di isolamento usando i valori precedenti e l'ID sottoscrizione:
sudo crm configure primitive fence-vm stonith:fence_azure_arm \
params \
action=reboot \
resourceGroup="resourcegroupname" \
resourceGroup="$resourceGroup" \
username="$secretId" \
login="$applicationId" \
passwd="$password" \
tenantId="$tenantId" \
subscriptionId="$subscriptionId" \
pcmk_reboot_timeout=900 \
power_timeout=60 \
op monitor \
interval=3600 \
timeout=120
Impostare le proprietà dell'agente di isolamento
Eseguire i comandi seguenti per configurare l'agente di isolamento:
sudo crm configure property cluster-recheck-interval=2min
sudo crm configure property start-failure-is-fatal=true
sudo crm configure property stonith-timeout=900
sudo crm configure property concurrent-fencing=true
sudo crm configure property stonith-enabled=true
Verificare lo stato del cluster:
sudo crm status
L'output è simile al seguente esempio:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 1 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Installare SQL Server e mssql-tools
Per installare SQL Server verranno usati i comandi seguenti:
Importare le chiavi GPG del repository pubblico:
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegistrare il repository Ubuntu:
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list)"Eseguire i comandi seguenti per installare SQL Server:
sudo apt-get update sudo apt-get install -y mssql-serverAl termine dell'installazione del pacchetto, esegui
mssql-conf setupe segui le istruzioni per impostare la password dell'amministratore di sistema e scegli l'edizione. Occorre ricordare che le edizioni sono concesse in licenza gratuitamente: Evaluation, Developer ed Express.sudo /opt/mssql/bin/mssql-conf setupAl termine della configurazione, verificare che il servizio sia in esecuzione:
systemctl status mssql-server --no-pagerInstallare gli strumenti da riga di comando di SQL Server
Per creare un database, è necessario connettersi con uno strumento in grado di eseguire istruzioni Transact-SQL in SQL Server. La procedura seguente installa gli strumenti da riga di comando di SQL Server sqlcmd e bcp.
Seguire questa procedura per installare mssql-tools18 in Ubuntu.
Nota
- Ubuntu 18.04 è supportato a partire da SQL Server 2019 CU3.
- Ubuntu 20.04 è supportato a partire da SQL Server 2019 CU10.
- Ubuntu 22.04 è supportato a partire da SQL Server 2022 CU10.
Entrare in modalità utente con privilegi avanzati.
sudo suImportare le chiavi GPG del repository pubblico.
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegistrare il repository Microsoft per Ubuntu.
Per Ubuntu 22.04, usare il comando seguente:
curl https://packages.microsoft.com/config/ubuntu/22.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPer Ubuntu 20.04, usare il comando seguente:
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPer Ubuntu 18.04, usare il comando seguente:
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPer Ubuntu 16.04, usare il comando seguente:
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
Uscire dalla modalità utente con privilegi avanzati.
exitAggiornare l'elenco di origini ed eseguire il comando di installazione con il pacchetto per sviluppatori unixODBC.
sudo apt-get update sudo apt-get install mssql-tools18 unixodbc-devNota
Per effettuare l'aggiornamento alla versione più recente di mssql-tools, eseguire i comandi seguenti:
sudo apt-get update sudo apt-get install mssql-tools18Facoltativo: aggiungere
/opt/mssql-tools18/bin/allaPATHvariabile di ambiente in una shell Bash.Per rendere sqlcmd e bcp accessibili dalla shell Bash per le sessioni di accesso, modificare
PATHnel~/.bash_profilefile con il comando seguente:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bash_profilePer rendere sqlcmd e bcp accessibili dalla shell Bash per le sessioni interattive/non di accesso, modificare
PATHnel file~/.bashrccon il comando seguente:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc source ~/.bashrc
Installare l'agente a disponibilità elevata SQL Server
Eseguire il comando seguente in tutti i nodi per installare il pacchetto dell'agente a disponibilità elevata per SQL Server:
sudo apt-get install mssql-server-ha
Configurare un gruppo di disponibilità
Per configurare un gruppo di disponibilità Always On di SQL Server per le macchine virtuali, seguire questa procedura. Per altre informazioni, vedere Configurare gruppi di disponibilità Always On di SQL Server per la disponibilità elevata in Linux.
Abilitare i gruppi di disponibilità e riavviare SQL Server
Abilitare i gruppi di disponibilità in ogni nodo che ospita un'istanza di SQL Server. Quindi riavviare il mssql-server server. Eseguire i comandi seguenti in ogni nodo:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Creare un certificato
Microsoft non supporta l'autenticazione di Active Directory per l'endpoint del gruppo di disponibilità. È quindi necessario usare un certificato per la crittografia dell'endpoint del gruppo di disponibilità.
Connettersi a tutti i nodi con SQL Server Management Studio (SSMS) o sqlcmd. Eseguire i comandi seguenti per abilitare la sessione AlwaysOn_health e creare una chiave master:
Importante
Se ci si connette all'istanza di SQL Server in modalità remota, sarà necessario aprire la porta 1433 sul firewall. Sarà inoltre necessario consentire le connessioni in ingresso alla porta 1433 nel gruppo di sicurezza di rete per ogni macchina virtuale. Per altre informazioni, vedere Creare una regola di sicurezza per la creazione di una regola di sicurezza in ingresso.
- Sostituire
<MasterKeyPassword>con la propria password.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GO- Sostituire
Connettersi alla replica primaria usando SSMS o sqlcmd. I comandi seguenti creeranno un certificato in
/var/opt/mssql/data/dbm_certificate.cere una chiave privata invar/opt/mssql/data/dbm_certificate.pvknella replica primaria di SQL Server:- Sostituire
<PrivateKeyPassword>con la propria password.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO- Sostituire
Per uscire dalla sessione sqlcmd eseguire il comando exit e tornare alla sessione SSH.
Copiare il certificato nelle repliche secondarie e creare i certificati nel server
Copiare i due file creati nello stesso percorso in tutti i server che ospiteranno le repliche di disponibilità.
Nel server primario eseguire il comando
scpper copiare il certificato nei server di destinazione:- Sostituire
<username>esles2con il nome utente e il nome della macchina virtuale di destinazione in uso. - Eseguire questo comando per tutte le repliche secondarie.
Nota
Non è necessario eseguire
sudo -i, che restituisce l'ambiente radice. È invece possibile eseguire ilsudocomando davanti a ogni comando.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>- Sostituire
Nel server di destinazione eseguire questo comando:
- Sostituire
<username>con il nome utente. - Il comando
mvsposta i file o la directory da una posizione a un'altra. - Il comando
chownviene usato per modificare il proprietario e il gruppo di file, directory o collegamenti. - Eseguire questi comandi per tutte le repliche secondarie.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Sostituire
Lo script Transact-SQL seguente crea un certificato dal backup creato nella replica primaria di SQL Server. Aggiornare lo script con password complesse. La password di decrittografia è la stessa password usata per creare il file PVK nel passaggio precedente. Per creare il certificato, eseguire lo script seguente in tutti i server secondari usando sqlcmd o SSMS:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
Creare endpoint di mirroring del database in tutte le repliche
Eseguire lo script seguente in tutte le istanze di SQL Server usando sqlcmd o SSMS:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Creare il gruppo di disponibilità
Connettersi all'istanza di SQL Server che ospita la replica primaria usando sqlcmd o SSMS. Per creare il gruppo di disponibilità, eseguire questo comando:
- Sostituire
ag1con il nome del gruppo di disponibilità desiderato. - Sostituire i valori di
ubuntu1,ubuntu2eubuntu3con i nomi delle istanze di SQL Server che ospitano le repliche.
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'ubuntu1'
WITH (
ENDPOINT_URL = N'tcp://ubuntu1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu2'
WITH (
ENDPOINT_URL = N'tcp://ubuntu2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu3'
WITH (
ENDPOINT_URL = N'tcp://ubuntu3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Creare un account di accesso di SQL Server per Pacemaker
In tutte le istanze di SQL Server creare un account di accesso di SQL Server per Pacemaker. Il codice Transact-SQL seguente crea un account di accesso.
- Sostituire
<password>con una password complessa personale.
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
In tutte le istanze di SQL Server salvare le credenziali usate per l'account di accesso di SQL Server.
Creare il file:
sudo vi /var/opt/mssql/secrets/passwdAggiungere le due righe seguenti al file:
pacemakerLogin <password>Per uscire dall'editor vi, premere prima il tasto ESC e quindi immettere il comando
:wqper eseguire la scrittura del file e uscire.Impostare il file come leggibile solo dall'utente ROOT:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Aggiungere le repliche secondarie al gruppo di disponibilità
Nelle repliche secondarie eseguire i comandi seguenti per aggiungerle al gruppo di disponibilità:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GONella replica primaria e in ogni replica secondaria eseguire lo script Transact-SQL seguente:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GODopo aver aggiunto le repliche secondarie, sarà possibile visualizzarle in Esplora oggetti di SSMS espandendo il nodo Disponibilità elevata Always On:
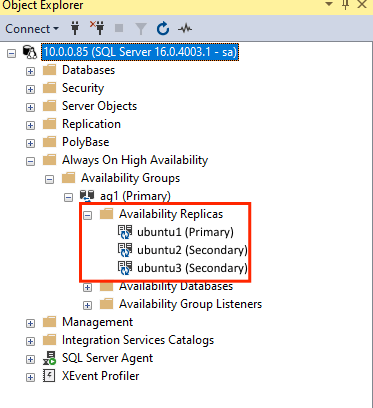
Aggiungere un database al gruppo di disponibilità
Questa sezione segue l'articolo relativo all'aggiunta di un database a un gruppo di disponibilità.
In questo passaggio verranno usati i comandi Transact-SQL seguenti. Eseguire questi comandi nella replica primaria:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery mode
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Verificare che il database sia creato nei server secondari
In ogni replica secondaria di SQL Server eseguire la query seguente per verificare che il database db1 sia stato creato e che si trovi nello stato SINCRONIZZATO:
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
Se l'elenco synchronization_state_desc restituisce SINCRONIZZATO per db1, significa che le repliche sono sincronizzate. I server secondari mostrano db1 nella replica primaria.
Creare le risorse del gruppo di disponibilità nel cluster Pacemaker
Usare il comando seguente per creare la risorsa nel gruppo di disponibilità in Pacemaker:
sudo crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
Questo comando precedente crea la risorsa ag1_cluster, ovvero la risorsa del gruppo di disponibilità. Crea quindi la risorsa ms-ag1 (risorsa primaria/secondaria in Pacemaker, quindi aggiunge la risorsa del gruppo di disponibilità. Ciò garantisce che la risorsa del gruppo di disponibilità venga eseguita in tutti e tre i nodi del cluster, ma solo uno di questi nodi è primario).
Per visualizzare la risorsa del gruppo di disponibilità e controllare lo stato del cluster:
sudo crm resource status ms-ag1
sudo crm status
L'output è simile al seguente esempio:
resource ms-ag1 is running on: ubuntu1 Master
resource ms-ag1 is running on: ubuntu3
resource ms-ag1 is running on: ubuntu2
L'output è simile al seguente esempio. Per aggiungere vincoli di condivisione e promozione, vedere Esercitazione: Configurare un listener del gruppo di disponibilità in macchine virtuali Linux.
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Eseguire il comando seguente per creare una risorsa di gruppo, in modo che non sia necessario applicare singolarmente i vincoli di condivisione e promozione applicati al listener e al servizio di bilanciamento del carico.
sudo crm configure group virtualip-group azure-load-balancer virtualip
L'output del crm status sarà simile all'esempio seguente:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 6 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* Resource Group: virtual ip-group:
* azure-load-balancer (ocf :: heartbeat:azure-lb): Started ubuntu1
* virtualip (ocf :: heartbeat: IPaddr2): Started ubuntu1
* fence-vm (stonith:fence_azure_arm): Started ubuntu1