Script pre-post avanzati per snapshot coerenti con il database
Il servizio Backup di Azure offre già un framework di pre-post script per ottenere la coerenza dell'applicazione nelle macchine virtuali Linux usando Backup di Azure. Questo processo prevede la chiamata di uno script pre-post (per disattivare le applicazioni) prima di acquisire snapshot dei dischi e chiamare post-script (comandi per annullare il blocco delle applicazioni) dopo il completamento dello snapshot per riattivare la modalità normale delle applicazioni.
La creazione, il debug e la manutenzione di pre e post script possono essere operazioni complesse. Per rimuovere questa complessità, Backup di Azure offre un'esperienza semplificata di pre-post script per i database che consente di ottenere uno snapshot coerente con l'applicazione con tempi ridotti.
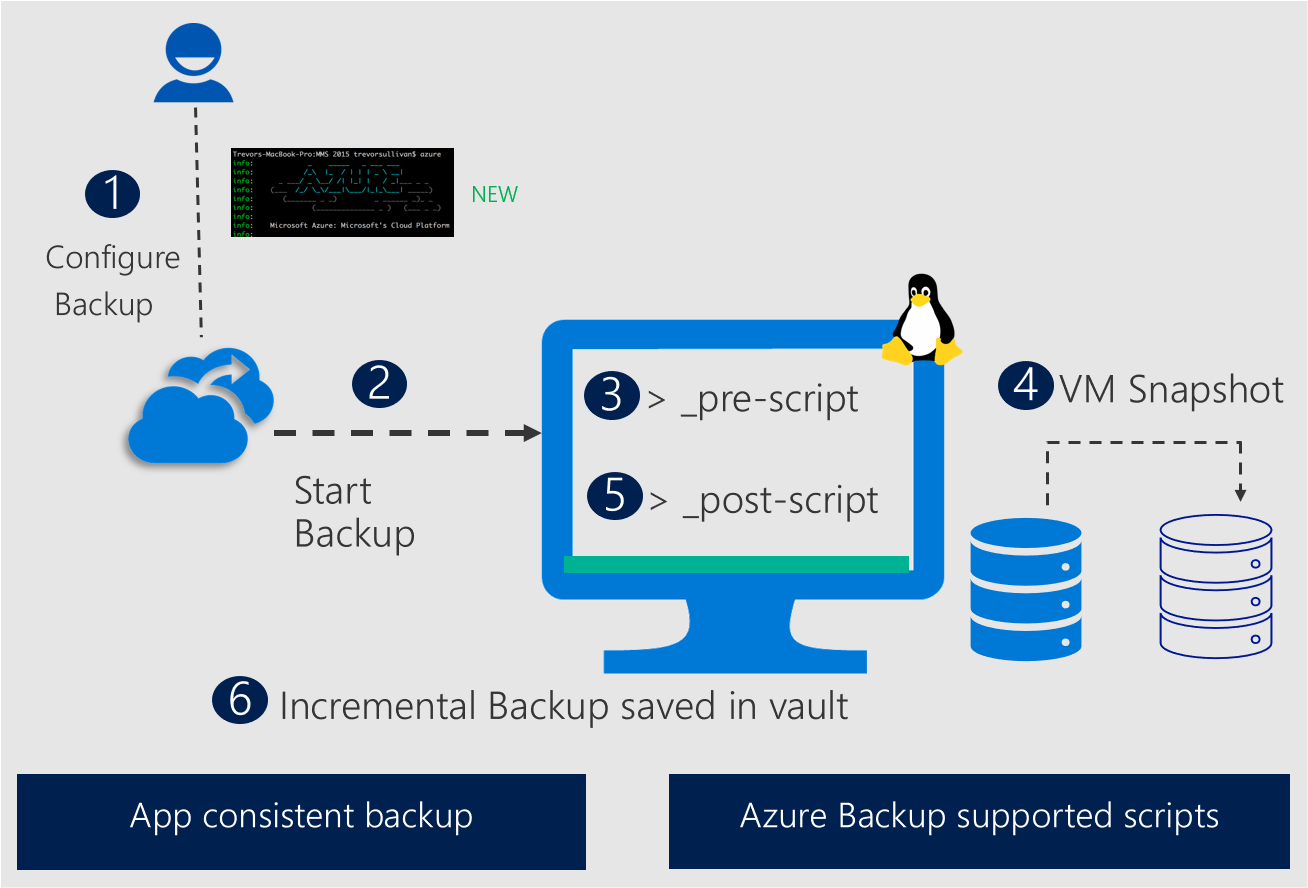
Il nuovo framework di pre-post script avanzato presenta i vantaggi principali seguenti:
- Questi script di pre-post vengono installati direttamente nelle macchine virtuali di Azure insieme all'estensione di backup, che consente di eliminare la creazione e scaricarli da un percorso esterno.
- È possibile visualizzare la definizione e il contenuto di pre-post script in GitHub e anche di inviare suggerimenti e modifiche. È inoltre possibile inviare suggerimenti e modifiche tramite GitHub, che verranno valutati e aggiunti per offrire vantaggi a una community di utenti più ampia.
- Tramite GitHub è altresì possibile aggiungere nuovi pre-post script per altri database che verranno valutati e verificati per offrire vantaggi a una community di utenti più ampia.
- Il framework affidabile garantisce un'efficienza ottimale per gestire vari scenari, ad esempio errori di esecuzione pre-script o arresti anomali. In qualsiasi caso, viene eseguito automaticamente il post-script per eseguire il rollback di tutte le modifiche eseguite nel pre-script.
- Il framework fornisce anche un canale di messaggistica che consente agli strumenti esterni di recuperare gli aggiornamenti e preparare il proprio piano d'azione per qualsiasi messaggio/evento.
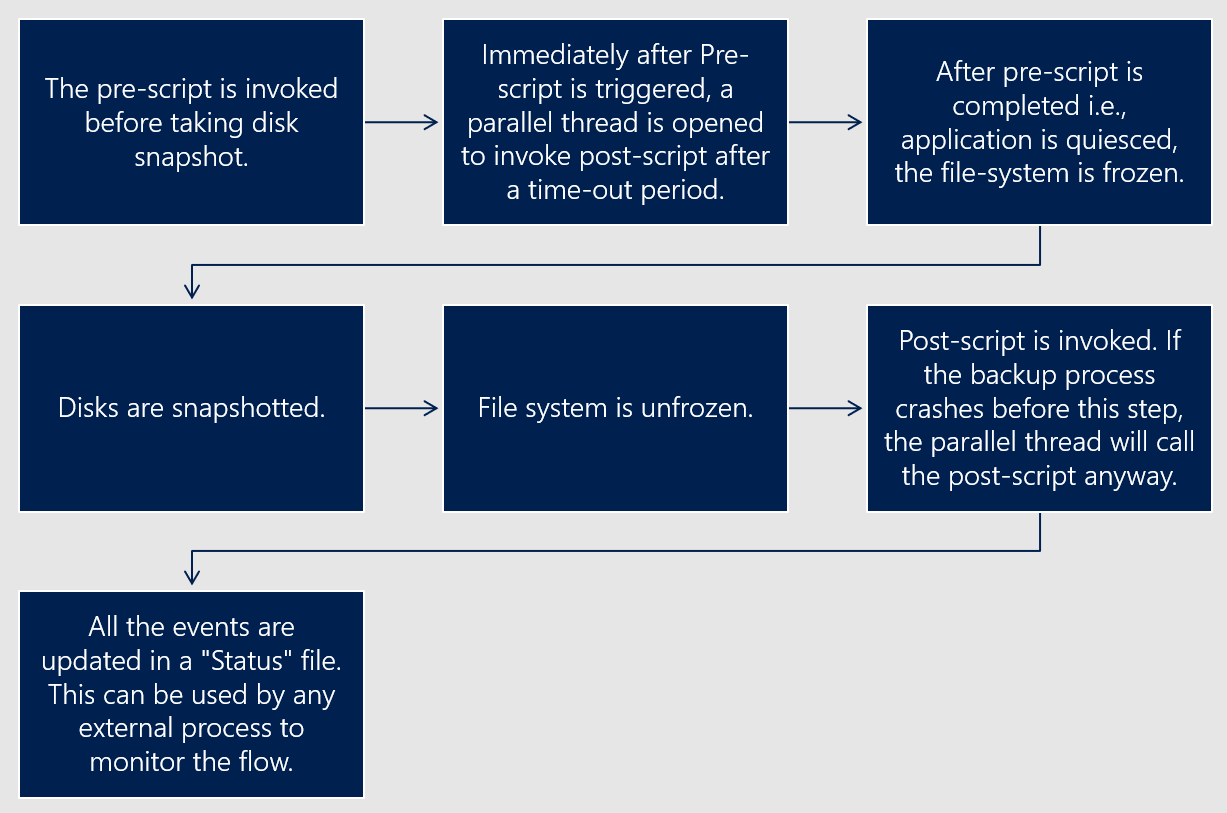
Flusso della soluzione
Matrice di supporto
Di seguito è riportato l'elenco dei database supportati nel framework avanzato:
- Oracle (disponibile a livello generale) - Collegamento alla matrice di supporto
- MySQL (anteprima)
Prerequisiti
È sufficiente modificare un file di configurazione, workload.conf in /etc/azure, per fornire i dettagli di connessione. In questo modo Backup di Azure può connettersi all'applicazione pertinente ed eseguire pre e post-script. Il file di configurazione ha i parametri seguenti.
[workload]
# valid values are mysql, oracle
workload_name =
command_path =
linux_user =
credString =
ipc_folder =
timeout =
La tabella seguente descrive i parametri:
| Parametro | Obbligatorio | Spiegazione |
|---|---|---|
| workload_name | Sì | Contiene il nome del database per cui è necessario eseguire il backup coerente con l'applicazione. I valori attualmente supportati sono oracle o mysql. |
| command_path/configuration_path | Contiene il percorso del file binario del carico di lavoro. Questo non è un campo obbligatorio se il file binario del carico di lavoro è impostato come variabile di percorso. | |
| linux_user | Sì | Contiene il nome utente dell'utente Linux con accesso all'account di accesso utente del database. Se questo valore non è impostato, l'utente ROOT corrisponde all'utente predefinito. |
| credString | Si tratta della stringa delle credenziali per la connessione al database. Contiene l'intera stringa di accesso. | |
| ipc_folder | Il carico di lavoro può scrivere solo in determinati percorsi del file system. È necessario specificare qui questo percorso della cartella in modo che il pre-script possa scrivere gli stati in questo percorso della cartella. | |
| timeout | Sì | Si tratta del limite di tempo massimo durante il quale il database sarà in stato di disattivazione. Il valore predefinito è 90 (secondi). Non è consigliabile impostare un valore inferiore a 60 secondi. |
Nota
La definizione JSON è un modello che il servizio Backup di Azure può modificare in base a un database specifico. Per informazioni sul file di configurazione per ogni database, vedere il manuale di ogni database.
L'esperienza complessiva per l'uso del framework di pre-post script avanzato è la seguente:
- Preparare l'ambiente del database
- Modificare il file di configurazione
- Attivare il backup della macchina virtuale
- Ripristinare le macchine virtuali o i dischi/file dal punto di ripristino coerente con l'applicazione in base alle esigenze.
Creare una strategia di backup del database
Utilizzo di snapshot anziché dello streaming
In genere, gli amministratori dei database usano i backup in streaming (ad esempio, completi, differenziali o incrementali) e i log nella strategia di backup. Di seguito sono riportati alcuni degli aspetti cardine della progettazione.
- Prestazioni e costi: un backup completo + log giornaliero è la soluzione più veloce durante il ripristino, ma comporta costi significativi. L'inclusione del tipo di backup in streaming differenziale/incrementale riduce i costi, ma potrebbe influire sulle prestazioni di ripristino. Gli snapshot offrono tuttavia la migliore combinazione di prestazioni e costi. Poiché gli snapshot sono intrinsecamente incrementali, hanno un impatto minimo sulle prestazioni durante il backup, vengono ripristinati rapidamente e consentono anche di risparmiare sui costi.
- Impatto sul database o sull'infrastruttura: le prestazioni di un backup in streaming dipendono dalle operazioni di I/O al secondo di archiviazione sottostanti e dalla larghezza di banda di rete disponibile quando il flusso è destinato a una posizione remota. Gli snapshot non hanno questa dipendenza e la richiesta in termini di operazioni di I/O al secondo e larghezza di banda di rete è notevolmente ridotta.
- Riutilizzabilità: i comandi per l'attivazione di tipi di backup in streaming diversi sono diversi per ogni database. Gli script non possono quindi essere riutilizzati facilmente. Inoltre, se si usano tipi di backup diversi, assicurarsi di valutare la catena di dipendenze per mantenere il ciclo di vita. Per gli snapshot, è facile scrivere script perché non esiste alcuna catena di dipendenze.
- Conservazione a lungo termine: i backup completi sono sempre utili per la conservazione a lungo termine, perché possono essere spostati e ripristinati in modo indipendente. Tuttavia, per i backup operativi con conservazione a breve termine, gli snapshot sono più adatti.
Di conseguenza, uno snapshot + log giornaliero con backup completo occasionale per la conservazione a lungo termine rappresenta il miglior criterio di backup per i database.
Strategia di backup del log
Il framework di pre-post script migliorato è basato sul backup di macchine virtuali di Azure che pianifica il backup una volta al giorno. Pertanto, la finestra di perdita dei dati con Obiettivo del punto di ripristino (RPO) come 24 ore non è adatta per i database di produzione. Questa soluzione è integrata con una strategia di backup del log in cui i backup del log vengono trasmessi in streaming in modo esplicito.
NFS in BLOB e NFS in Condivisioni file di Azure (anteprima) semplificano il montaggio dei volumi direttamente nelle macchine virtuali dei database e usano i client di database per trasferire i backup del log. La finestra di perdita dei dati, ovvero l'obiettivo del punto di ripristino (RPO), rientra nella frequenza dei backup del log. Inoltre, le destinazioni NFS non devono garantire prestazioni estremamente elevate perché potrebbe non essere necessario attivare lo streaming regolare (completo e incrementale) per i backup operativi dopo aver creato snapshot coerenti con il database.
Nota
Il pre-script avanzato in genere si occupa di scaricare tutte le transazioni di log in transito nella destinazione di backup del log, prima di disattivare il database per creare uno snapshot. Di conseguenza, gli snapshot sono coerenti con il database e affidabili durante il ripristino.
Strategia di ripristino
Una volta che gli snapshot coerenti con il database sono stati acquisiti e i backup del log vengono trasmessi a un volume NFS, la strategia di ripristino del database potrebbe usare la funzionalità di ripristino dei backup delle macchine virtuali di Azure. La funzionalità di backup del log viene ulteriormente applicata anche tramite il client di database. Di seguito sono riportate alcune opzioni per la strategia di ripristino:
- Creare nuove macchine virtuali dal punto di ripristino coerente con il database. Nella macchina virtuale deve già essere connesso il punto di montaggio del log. Usare i client di database per eseguire i comandi di ripristino per il ripristino temporizzato.
- Creare dischi dal punto di ripristino coerente con il database e collegarli a un'altra macchina virtuale di destinazione. Montare quindi la destinazione del log e usare i client di database per eseguire i comandi di ripristino per il ripristino temporizzato
- Usare l'opzione di ripristino file e generare uno script. Eseguire lo script nella macchina virtuale di destinazione e collegare il punto di ripristino come dischi iSCSI. Usare quindi i client di database per eseguire le funzioni di convalida specifiche del database nei dischi collegati e convalidare i dati di backup. Usare anche i client di database per esportare/ripristinare alcune tabelle/file anziché ripristinare l'intero database.
- Usare la funzionalità ripristino tra aree per eseguire le azioni precedenti dall'area secondaria associata durante un'emergenza a livello di area.
Riepilogo
Usando snapshot e log di backup coerenti con il database con una soluzione personalizzata, è possibile creare una soluzione di backup di database efficiente e conveniente sfruttando i vantaggi del backup delle macchine virtuali di Azure e riutilizzando le funzionalità dei client di database.