Effettuare il provisioning dell'analisi su scala cloud
Processo di distribuzione della zona di approdo per la gestione dei dati
Il team operativo della piattaforma dati è responsabile della distribuzione di una zona di destinazione per la gestione dei dati. La zona di destinazione per la gestione dei dati deve avere un proprio repository gestito dal team operativo della piattaforma dati.
Attenzione
Creare e distribuire una zona di atterraggio per la gestione dei dati prima della distribuzione di qualsiasi zona di atterraggio dei dati.
Processo di distribuzione della zona di destinazione dei dati
I team possono usare i modelli forniti dal team delle operazioni della piattaforma dati per evitare l'avvio da zero per ogni asset. Si consiglia di usare uno schema di fork per automatizzare la distribuzione di una nuova area di atterraggio.
Ad esempio, un team operativo della zona di destinazione dei dati richiede una nuova zona di destinazione dei dati usando uno strumento di gestione IT o Power Apps. Dopo l'approvazione della richiesta, avviare il flusso di lavoro seguente usando i parametri della richiesta:
- Distribuire una nuova sottoscrizione per la nuova zona di destinazione dei dati.
- Creare un fork del ramo principale del modello di zona di destinazione dei dati per creare un nuovo repository.
- Creare una connessione al servizio nel nuovo repository.
- Aggiornare i parametri nel nuovo repository in base ai parametri della richiesta.
- Creare una pipeline di distribuzione per distribuire i servizi, attivata dal check-in dei parametri aggiornati.
- Notificare al team operativo della zona di ricezione dei dati che la nuova zona di ricezione è disponibile.
Il team operativo della zona di destinazione dei dati può ora modificare o aggiungere modelli di Azure Resource Manager.
Questo flusso di lavoro può essere automatizzato usando più set di servizi nella piattaforma Azure. Gestire alcuni dei passaggi, ad esempio la ridenominazione dei parametri nei file di parametri, usando le pipeline CI/CD. È possibile eseguire altri passaggi usando altri strumenti di orchestrazione del flusso di lavoro, ad esempio App per la logica.
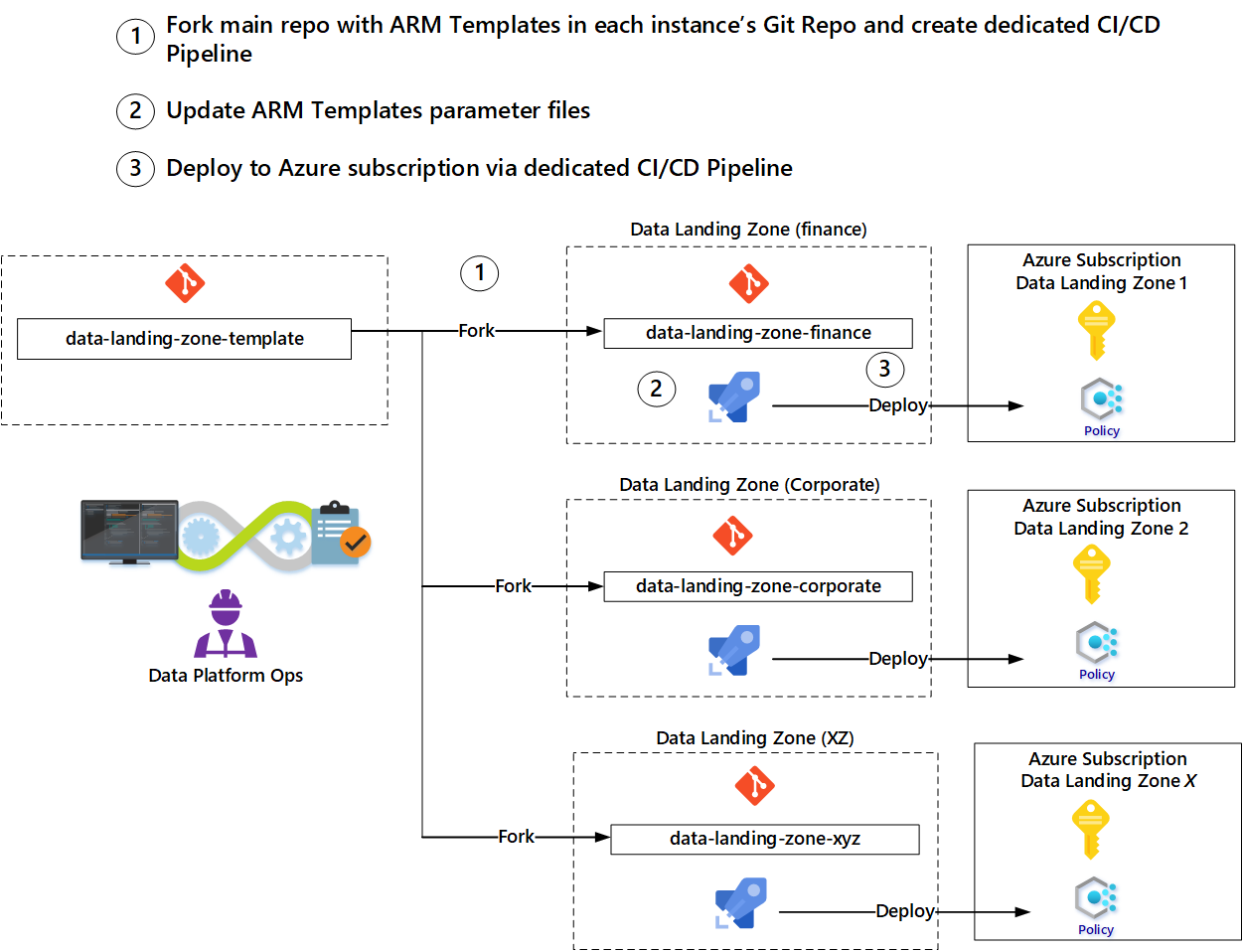
Il modello di diramazione consente ai team di aggiornare i propri modelli a partire dai modelli originali utilizzati per la diramazione. Inoltre, se i miglioramenti o le nuove funzionalità vengono implementati nei repository dei modelli, i team operativi possono integrarli nel proprio fork.
Adottare le procedure consigliate per i repository, ad esempio:
- Proteggere il ramo principale.
- Usare rami per modifiche, aggiornamenti e miglioramenti.
- Definire i proprietari del codice che approvano le pull request prima di integrare le modifiche nel ramo principale.
- Convalidare i rami tramite test automatizzati.
- Limitare il numero di azioni e persone nel team, come ad esempio chi può attivare le pipeline di compilazione e rilascio.
Consiglio
Coordinare le attività tra i team per garantire che i miglioramenti o le nuove funzionalità nei modelli originali vengano replicati in tutte le istanze della zona di destinazione dei dati. I team operativi possono importare le modifiche del modello originale nel proprio fork.
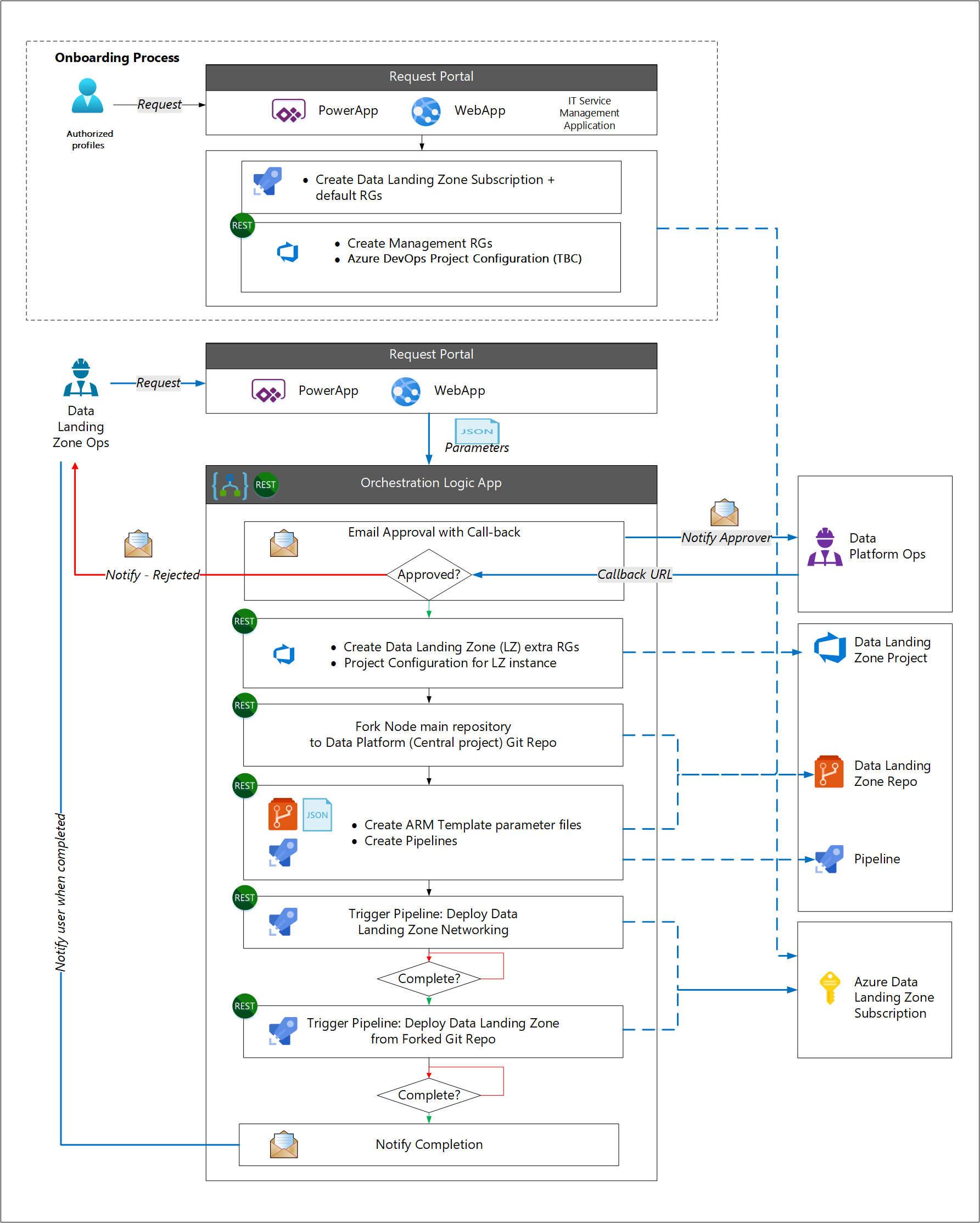
Il processo di onboarding è separato dal processo di distribuzione della zona di destinazione dei dati. Questa separazione si basa sul presupposto che la maggior parte delle organizzazioni disponga di un processo di distribuzione della sottoscrizione di Azure standard come parte del modello operativo cloud. Il processo di onboarding distribuisce i componenti aziendali standard, ad esempio uno strumento di gestione dei servizi IT di terze parti. I componenti specifici della zona di destinazione dei dati vengono distribuiti successivamente.
Nella soluzione di automazione proposta non sono disponibili API Git per clonare,aggiornare/eseguire il commit/push. L'approccio consiste quindi nell'usare un account di automazione di Azure contenente runbook di PowerShell che:
- Configurare una zona di destinazione dei dati
- Creare un fork del repository principale su un repository Git della piattaforma di dati
- Configurare le configurazioni della subnet per la zona di destinazione dei dati
- Configurare Microsoft Entra ID
I runbooks usano le funzioni Git del modulo di PowerShell GitAutomation per lavorare con i repository Git. Installando questo modulo all'interno di un account di Automazione di Azure, gli utenti possono eseguire operazioni di creazione, clonazione, query, push, pull e commit nei repository Git. L'immagine seguente mostra il modulo GitAutomation installato in un account di Automazione di Azure:

Usare la funzione Copy-GitRepository dal modulo GitAutomation per clonare il repository Git principale dall'URL specificato da URL al percorso Git della piattaforma dati specificato da DestinationPath.
Questo approccio alla distribuzione della zona di destinazione dei dati è flessibile, garantendo al tempo stesso che le azioni siano conformi ai requisiti dell'organizzazione. La gestione del ciclo di vita è abilitata applicando nuove funzionalità o ottimizzazioni dai modelli originali.
Processo di distribuzione delle applicazioni di dati
Dopo aver creato una zona di atterraggio dei dati, l'onboarding può iniziare per i team delle applicazioni dati. I team operativi della piattaforma dati o della zona di destinazione dei dati concedono l'approvazione della distribuzione.
La distribuzione viene eseguita direttamente utilizzando gli strumenti DevOps o richiamata tramite pipeline o flussi di lavoro esposti come API. Analogamente alla zona di destinazione dei dati, la distribuzione inizia con la copia tramite fork del repository dell'applicazione dati originale.
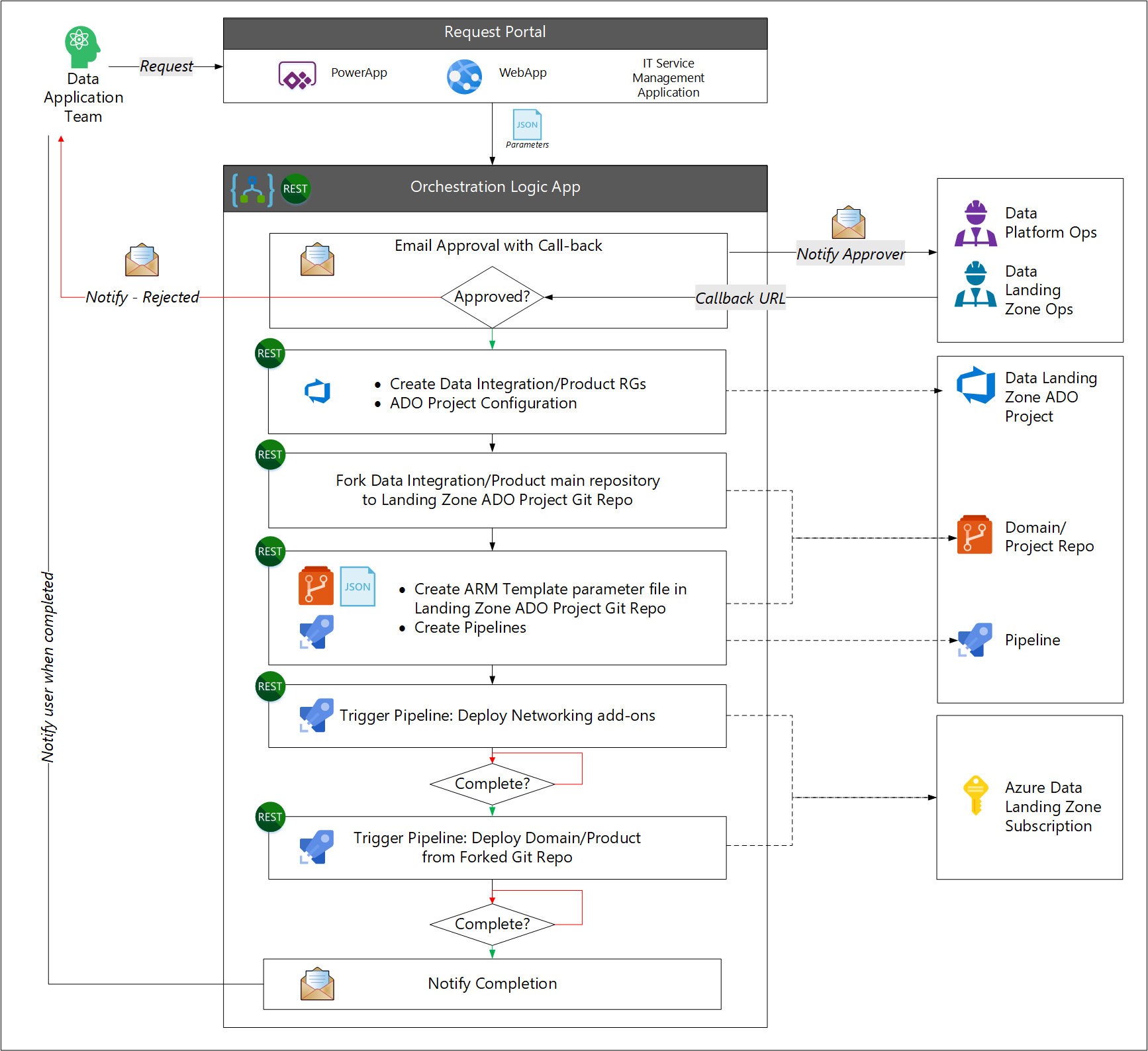
- L'utente effettua una richiesta per nuovi servizi di applicazione dati.
- Il processo del flusso di lavoro richiede l'approvazione del team operativo della piattaforma dati o della zona di destinazione dei dati.
- Il flusso di lavoro chiama l'API di gestione dei servizi IT per creare i gruppi di risorse necessari e la creazione di una connessione al servizio Azure DevOps. Il flusso di lavoro assegna un team al progetto Azure DevOps.
- Il flusso di lavoro crea un fork del repository dell'applicazione dati originale per creare il progetto Azure DevOps di destinazione.
- Il flusso di lavoro crea un file di parametri del modello di Azure Resource Manager e le pipeline.
- Il flusso di lavoro avvia quindi una pipeline di Azure per creare i requisiti di rete e un'altra pipeline di Azure per distribuire i servizi dell'applicazione dati.
- Il flusso di lavoro notifica all'utente al completamento.
Mancia
Se non si ha familiarità con DataOps, esaminare il laboratorio pratico DataOps per il moderno data warehouse nel Centro di Architetture Azure. Lo scenario del laboratorio descrive un ufficio di pianificazione urbana fittizio che può usare questa soluzione di implementazione. La soluzione di distribuzione fornisce una pipeline di dati end-to-end che segue il modello architettonico moderno del data warehouse, insieme ai processi DevOps e DataOps corrispondenti, per valutare l'uso del parcheggio e prendere decisioni aziendali informate.
Sommario
I modelli precedenti forniscono controllo, agilità, autoservizio e gestione del ciclo vitale delle politiche.
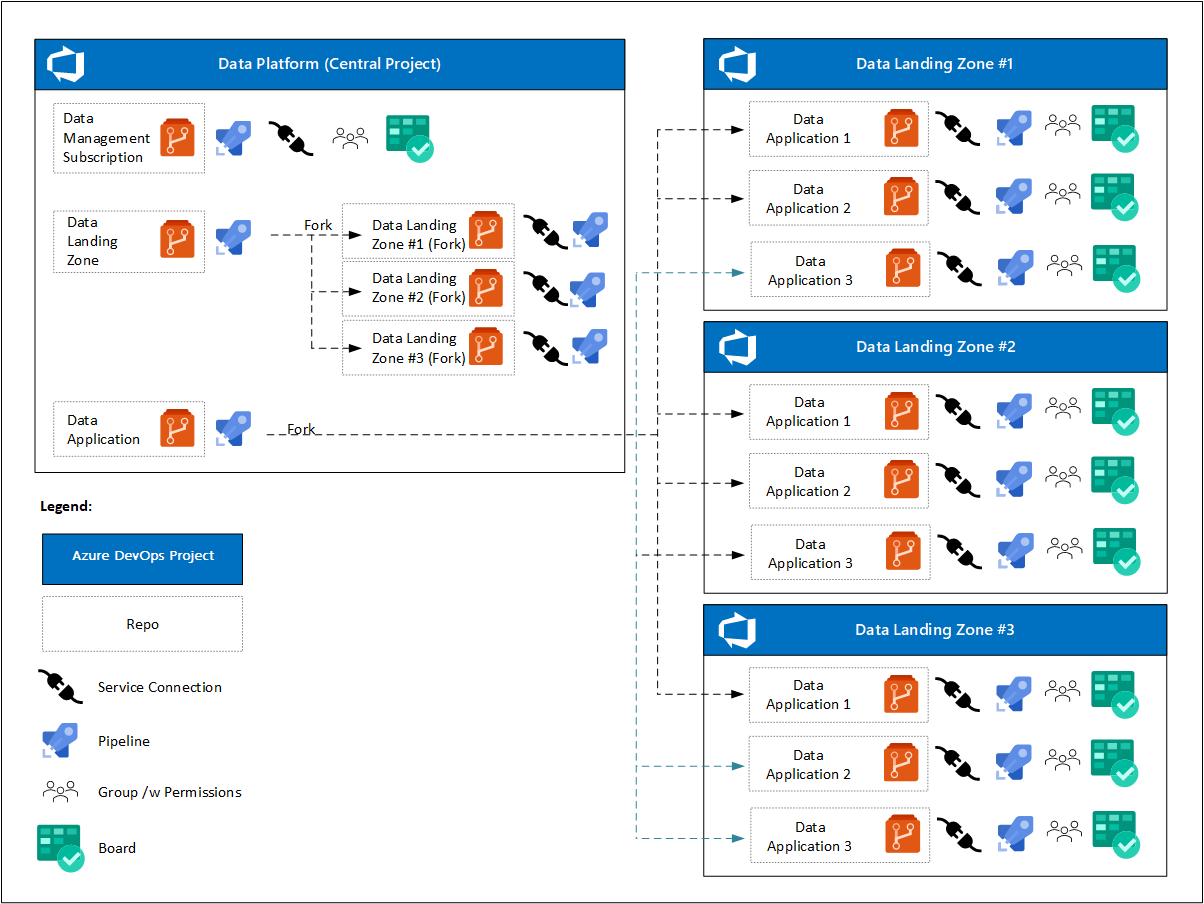
All'inizio del progetto, la piattaforma dati ha un progetto Azure DevOps con uno o più Azure Boards. I singoli team DevOps si concentrano su:
- Un repository per la zona di atterraggio per la gestione dei dati, le pipeline e una connessione di servizio all'ambiente cloud.
- Un repository di modelli per la zona di destinazione dei dati, le pipeline per distribuire un'istanza della zona di destinazione dei dati e le connessioni del servizio agli ambienti cloud.
- Un unico repository di modelli per i servizi dei prodotti di dati, le pipeline per distribuire un'istanza di un prodotto di dati e le connessioni del servizio agli ambienti cloud. Queste connessioni vengono copiate tramite fork dalla zona di destinazione dei dati di Azure DevOps Projects.
Dopo la distribuzione delle zone di destinazione dei dati, l'analisi su scala cloud prevede che:
- Ogni zona di destinazione dei dati avrà un proprio progetto Azure DevOps con uno o più Azure Boards.
- Per ogni applicazione dati, il fork del progetto Azure DevOps per la zona di destinazione dei dati viene creato dopo l'approvazione della richiesta.
- Ogni applicazione di dati include:
- Connessione al servizio.
- Una pipeline registrata.
- Un team DevOps con accesso alla scheda e al repository di Azure.
- Un diverso set di politiche per il repository biforcato.
Per controllare la distribuzione delle applicazioni dati, seguire queste procedure:
- Il team operativo della zona di destinazione dei dati è proprietario e protegge il ramo principale del repository.
- Solo il ramo principale viene usato per la distribuzione in ambienti di test e produzione.
- I rami di funzionalità possono essere distribuiti in ambienti di sviluppo.
- I rami di funzionalità appartengono ai team DataOps. Vengono usati per testare le funzionalità nuove o modificate.
- I team DataOps possono unire rami di funzionalità in altri rami di funzionalità senza approvazione.
- I team di DataOps creano una richiesta pull per unire i rami di funzionalità nel ramo principale e il team operativo della zona di destinazione dei dati fornisce l'approvazione.
- Le nuove funzionalità o i miglioramenti apportati ai modelli originali vengono integrati nel repository forkato per mantenerli aggiornati.