Eseguire la migrazione di dati relazionali uno-a-pochi in un account Azure Cosmos DB for NoSQL
SI APPLICA A: ![]() NoSQL
NoSQL
Per eseguire la migrazione da un database relazionale ad Azure Cosmos DB for NoSQL, potrebbe essere necessario apportare modifiche al modello di dati per l'ottimizzazione.
Una trasformazione comune consiste nel denormalizzare i dati incorporando elementi secondari correlati all'interno di un documento JSON. Di seguito vengono esaminate alcune opzioni per l'uso di Azure Data Factory o Azure Databricks. Per altre informazioni sulla modellazione dei dati per Azure Cosmos DB, vedere Modellazione dei dati in Azure Cosmos DB.
Scenario di esempio
Si supponga di avere le due tabelle seguenti nel database SQL, Orders e OrderDetails.
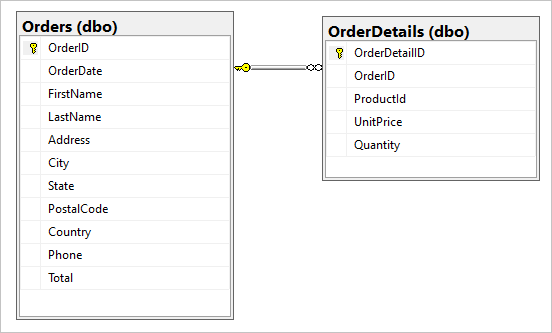
Si vuole combinare questa relazione uno-a-pochi in un documento JSON durante la migrazione. Per creare un singolo documento, creare una query T-SQL usando FOR JSON:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
I risultati di questa query includono i dati della tabella Ordini:

Idealmente, si vuole usare una singola attività di copia di Azure Data Factory (ADF) per eseguire query sui dati SQL come origine e scrivere l'output direttamente nel sink di Azure Cosmos DB come oggetti JSON appropriati. Attualmente, non è possibile eseguire la trasformazione JSON necessaria in un'attività di copia. Se si tenta di copiare i risultati della query precedente in un contenitore Azure Cosmos DB for NoSQL, viene visualizzato il campo OrderDetails come proprietà stringa del documento, anziché la matrice JSON prevista.
È possibile aggirare questa limitazione corrente in uno dei modi seguenti:
- Usare Azure Data Factory con due attività di copia:
- Ottenere dati in formato JSON da SQL a un file di testo in un percorso di archiviazione BLOB intermedio
- Caricare dati dal file di testo JSON a un contenitore in Azure Cosmos DB.
- Usare Azure Databricks per leggere da SQL e scrivere in Azure Cosmos DB. Sono disponibili due opzioni qui.
Esaminiamo questi approcci in modo più dettagliato:
Azure Data Factory
Anche se non è possibile incorporare OrderDetails come matrice JSON nel documento di Azure Cosmos DB di destinazione, è possibile risolvere il problema usando due attività di copia separate.
Attività di copia n. 1: SqlJsonToBlobText
Per i dati di origine, si usa una query SQL per ottenere il set di risultati come colonna singola con un oggetto JSON (che rappresenta l'ordine) per riga usando le funzionalità SQL Server OPENJSON e FOR JSON PATH:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
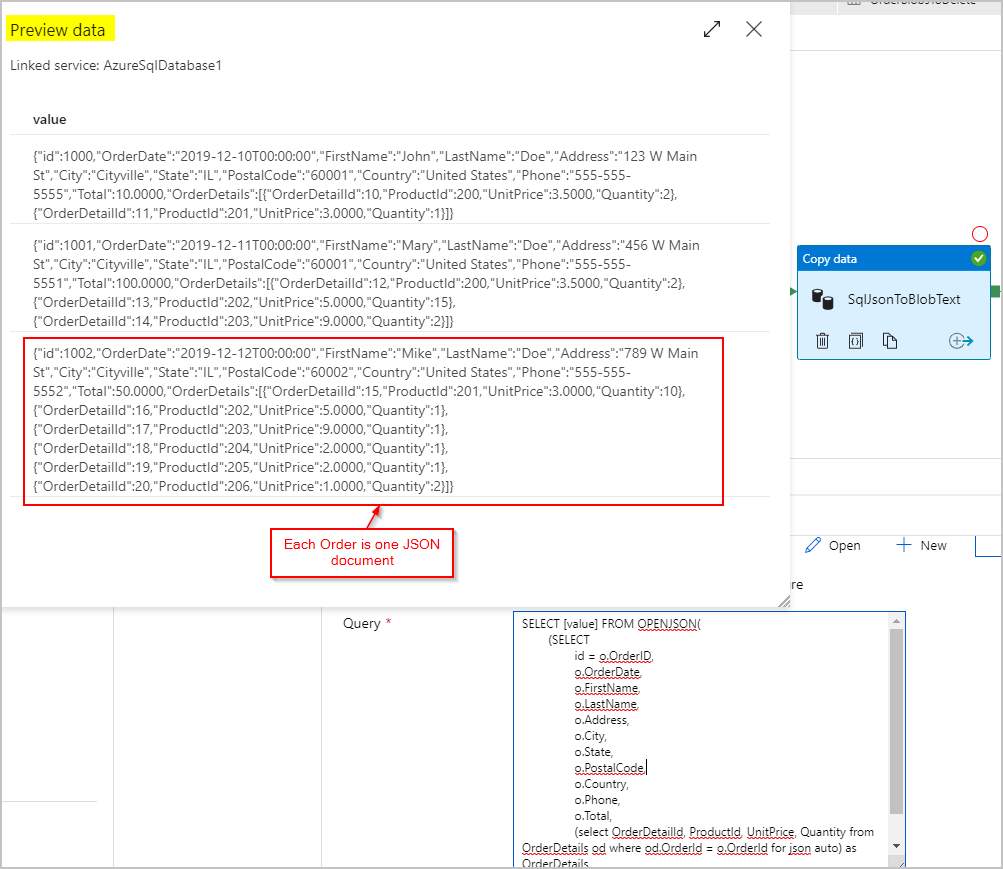
Per il sink dell'attività di copia SqlJsonToBlobText, si sceglie "Testo delimitato" e lo si punta a una cartella specifica in Archiviazione BLOB di Azure. Questo sink include un nome di file univoco generato dinamicamente, ad esempio @concat(pipeline().RunId,'.json').
Poiché il file di testo non è davvero "delimitato" e non si vuole che venga analizzato in colonne separate usando virgole. Si desidera anche mantenere le virgolette doppie ("), impostare "Delimitatore di colonna" su una scheda ("\t") o un altro carattere non presente nei dati e quindi impostare "Carattere virgolette" su "Nessun carattere virgolette".
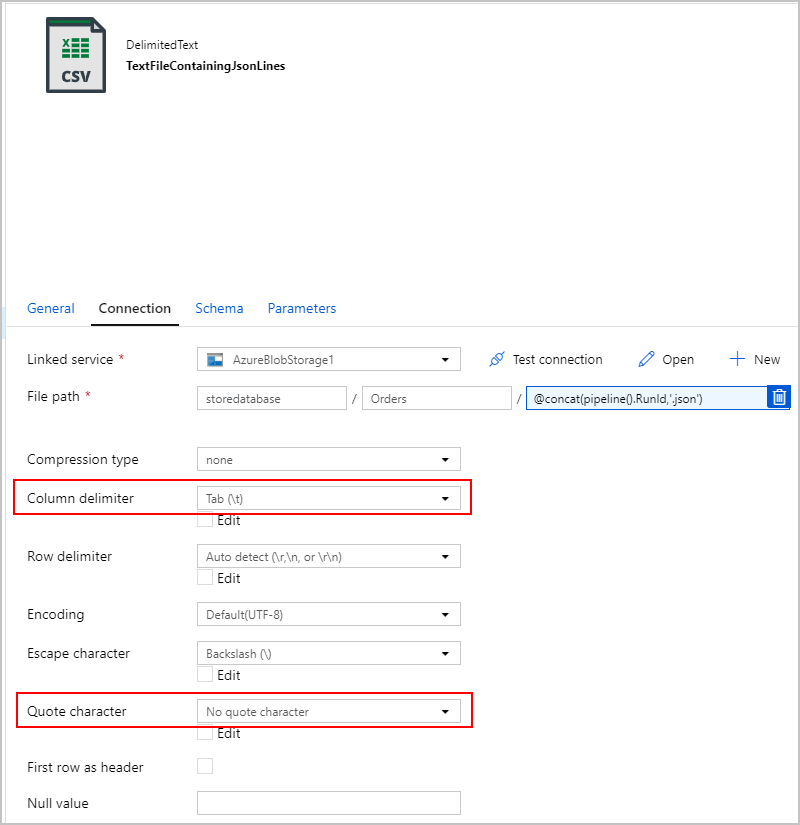
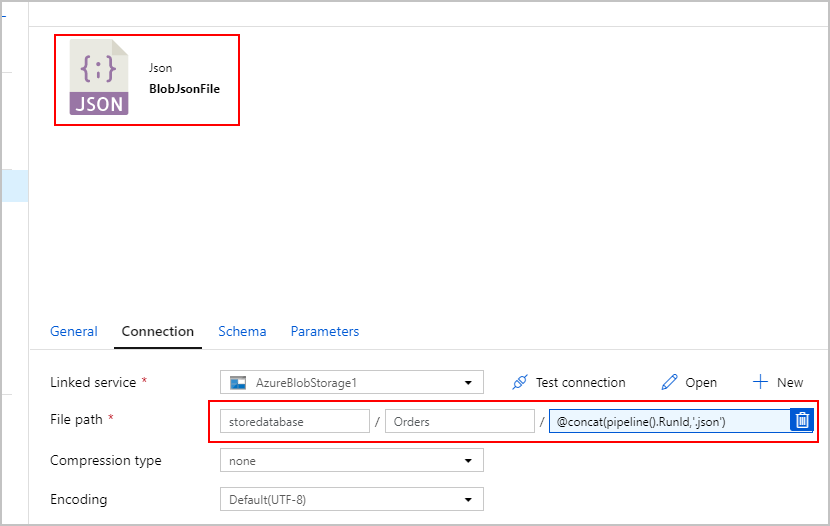
Attività di copia n. 2: BlobJsonToCosmos
Successivamente, si modifica la pipeline di Azure Data Factory aggiungendo la seconda attività di copia che cerca in Archiviazione BLOB di Azure il file di testo creato dalla prima attività. Lo elabora come origine "JSON" da inserire nel sink di Azure Cosmos DB come documento per ogni riga JSON presente nel file di testo.
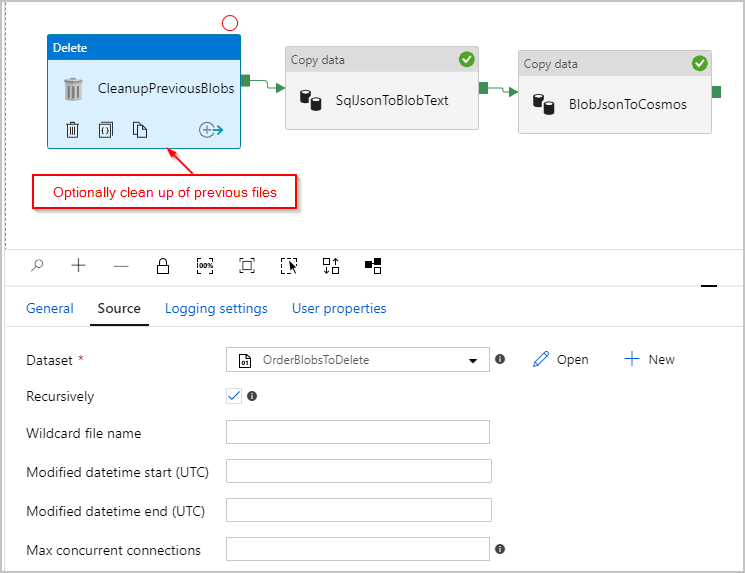
Facoltativamente, si aggiunge anche un'attività "Elimina" alla pipeline in modo che elimini tutti i file precedenti rimanenti nella cartella /Orders/ prima di ogni esecuzione. La pipeline di Azure Data Factory sarà ora simile alla seguente:
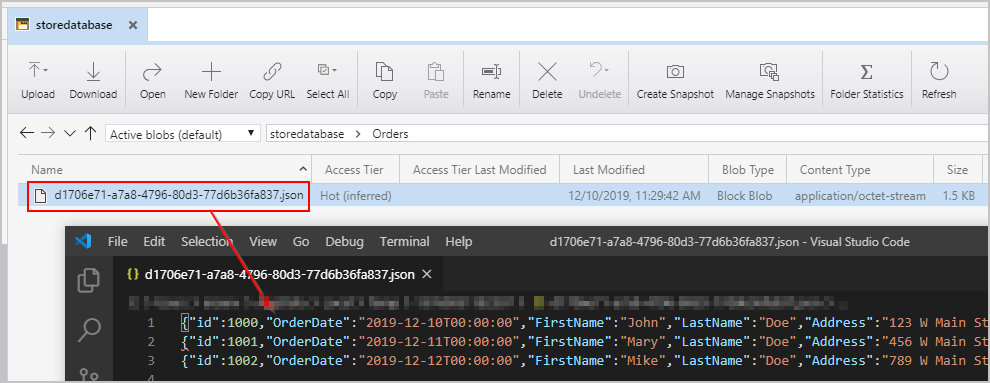
Dopo aver attivato la pipeline menzionata in precedenza, viene visualizzato un file creato nel percorso di Archiviazione BLOB di Azure intermedio contenente un oggetto JSON per riga:
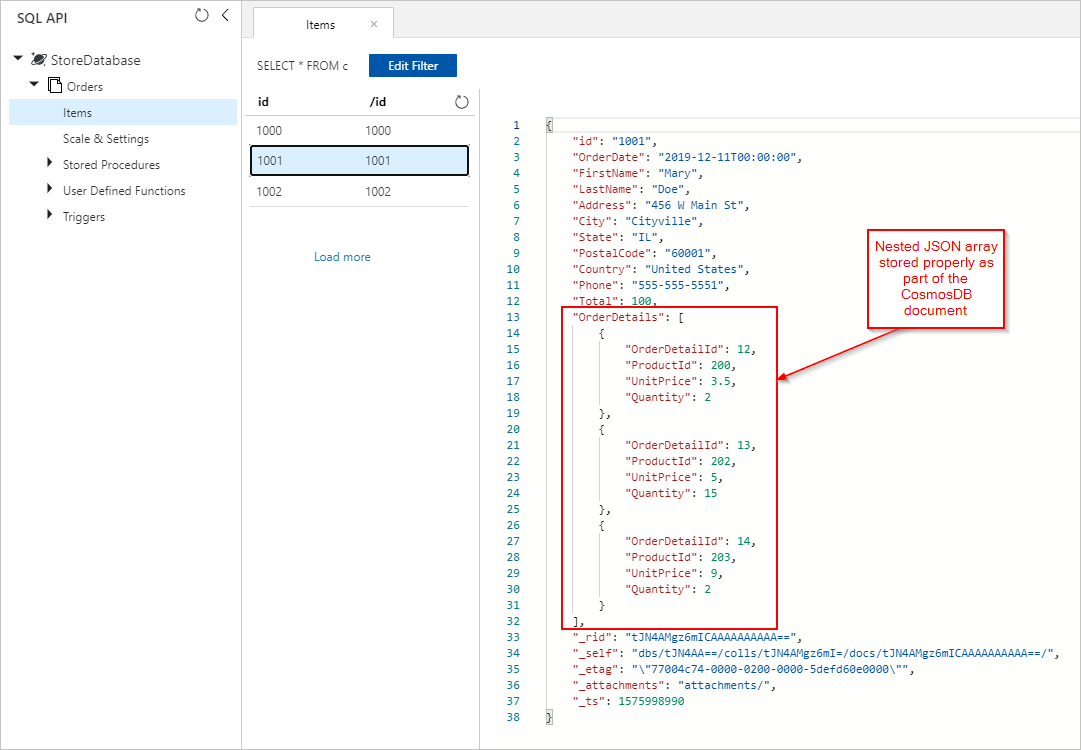
Vengono anche visualizzati i documenti Orders con OrderDetails incorporati correttamente inseriti nella raccolta di Azure Cosmos DB:
Azure Databricks
È anche possibile usare Spark in Azure Databricks per copiare i dati dall'origine del database SQL alla destinazione Azure Cosmos DB senza creare i file di testo intermedio/JSON nell'Archiviazione BLOB di Azure.
Nota
Per maggiore chiarezza e semplicità, i frammenti di codice includono password fittizie del database inline, ma è consigliabile usare idealmente i segreti di Azure Databricks.
Prima di tutto, vengono creati e collegati il connettore SQL necessario e le librerie del connettore Azure Cosmos DB per il cluster Azure Databricks. Riavviare il cluster per assicurarsi che le librerie vengano caricate.

Verranno quindi presentati due esempi, per Scala e Python.
Scala
In questo caso si ottengono i risultati della query SQL con l'output "FOR JSON” in un DataFrame:
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
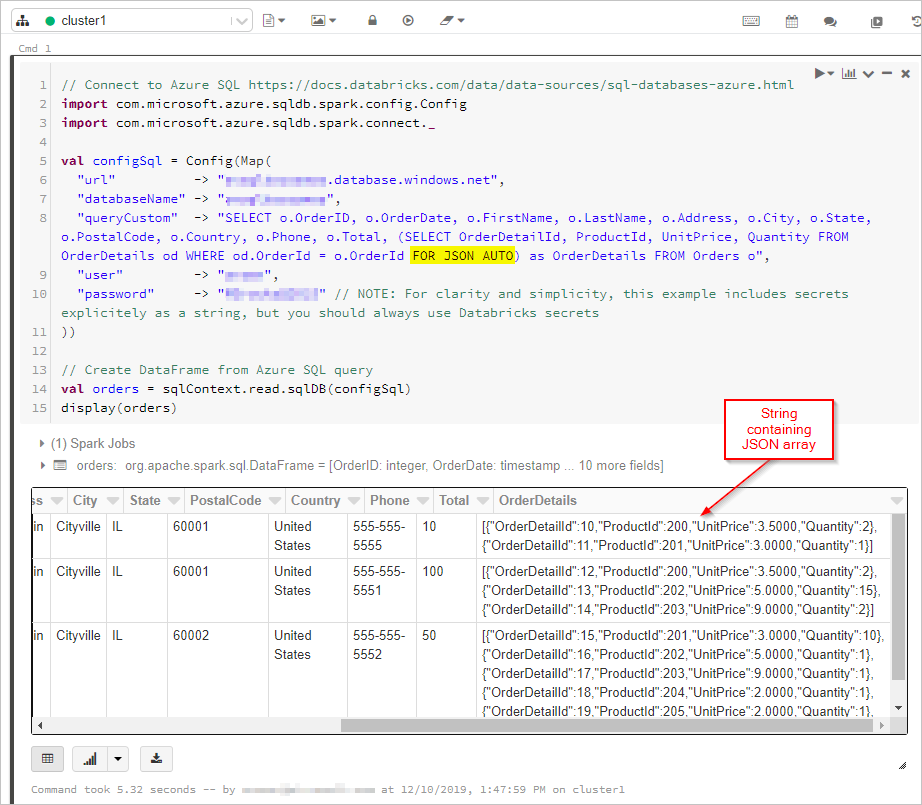
Successivamente, ci si connette al database e alla raccolta di Azure Cosmos DB:
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
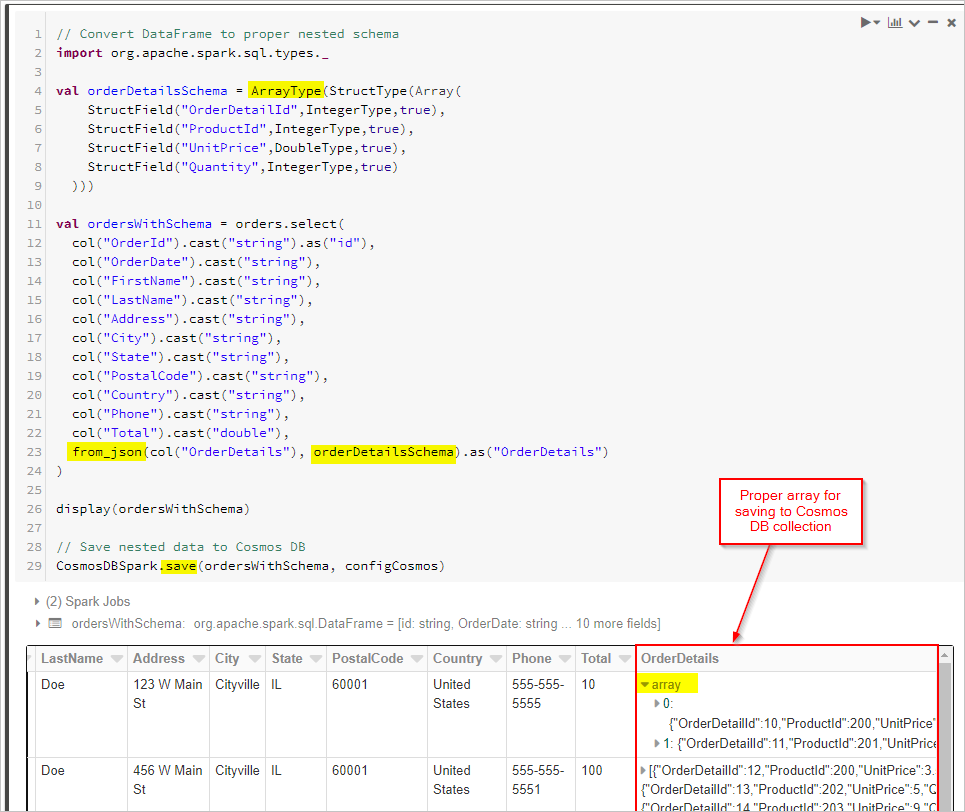
Infine, definiamo lo schema e usiamo from_json per applicare il DataFrame prima di salvarlo nella raccolta Cosmos DB.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Python
In alternativa, potrebbe essere necessario eseguire trasformazioni JSON in Spark se il database di origine non supporta FOR JSON o un'operazione simile. È anche possibile usare operazioni parallele per un set di dati di grandi dimensioni. Ecco un esempio di PySpark. Per iniziare, configurare le connessioni di database di origine e di destinazione nella prima cella:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Quindi, si esegue una query sul database di origine (in questo caso SQL Server) per i record dell'ordine e dei relativi dettagli, inserendo i risultati in dataframe Spark. Viene anche creato un elenco contenente tutti gli ID ordine e un pool di thread per le operazioni parallele:
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Creare quindi una funzione per scrivere Orders nell'API di destinazione per la raccolta NoSQL. Questa funzione filtra tutti i dettagli dell'ordine per l'ID ordine specificato, li converte in una matrice JSON e inserisce la matrice in un documento JSON. Il documento JSON viene quindi scritto nell'API di destinazione per il contenitore NoSQL per tale ordine:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://zcusa.951200.xyz/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Infine, chiamiamo la funzione writeOrder di Python usando una funzione mappa nel pool di thread per l'esecuzione in parallelo, passando l'elenco degli ID ordine creati in precedenza:
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
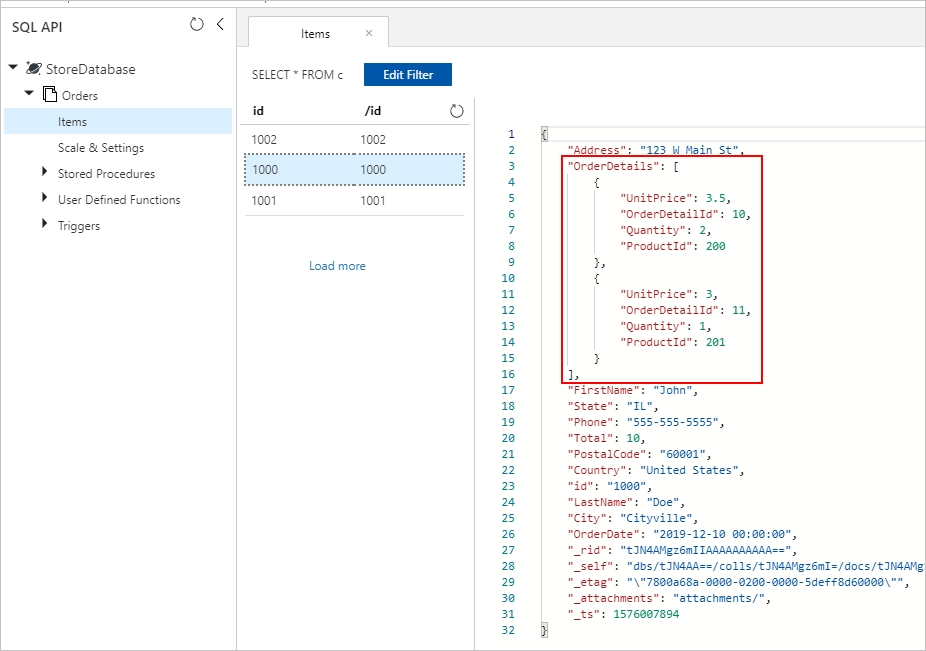
In entrambi gli approcci, alla fine, si dovrebbero salvare correttamente gli OrderDetails incorporati all'interno di ogni documento Order nella raccolta di Azure Cosmos DB:
Passaggi successivi
- Informazioni sulla modellazione dei dati in Azure Cosmos DB
- Informazioni su come modellare e partizionare i dati in Azure Cosmos DB