Monitorare le prestazioni, l'integrità e l'utilizzo di Azure Esplora dati con le metriche
Le metriche di Azure Esplora dati forniscono indicatori chiave per l'integrità e le prestazioni delle risorse del cluster di Azure Esplora dati. Usare le metriche descritte in dettaglio in questo articolo per monitorare l'utilizzo, l'integrità e le prestazioni del cluster di Azure Esplora dati nello scenario specifico come metriche autonome. È anche possibile usare le metriche come base per dashboard operativi di Azure e avvisi di Azure.
Per altre informazioni su Esplora metriche di Azure, vedere Esplora metriche.
Prerequisiti
- Una sottoscrizione di Azure. Creare un account Azure gratuito.
- Un cluster e un database di Esplora dati di Azure. Creare un cluster e un database.
Usare le metriche per monitorare le risorse di Azure Esplora dati
- Accedere al portale di Azure.
- Nel riquadro sinistro del cluster di Azure Esplora dati cercare le metriche.
- Selezionare Metriche per aprire il riquadro delle metriche e iniziare l'analisi nel cluster.
Usare il riquadro delle metriche
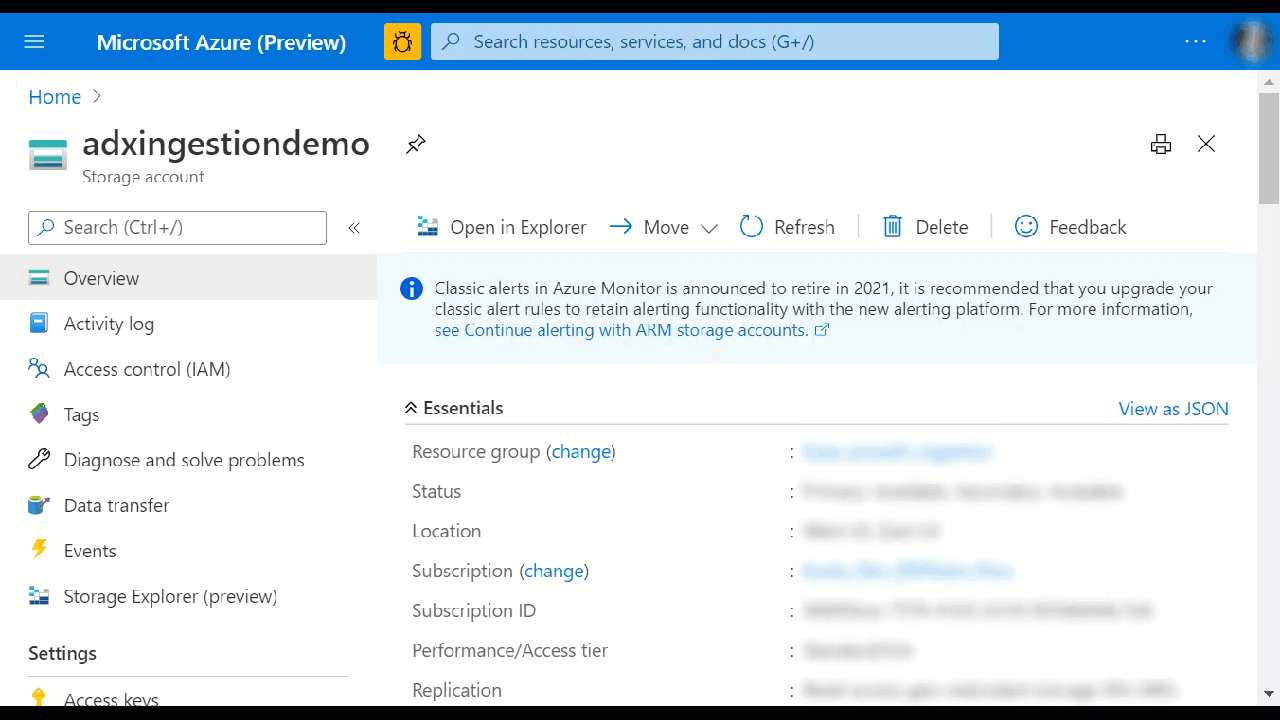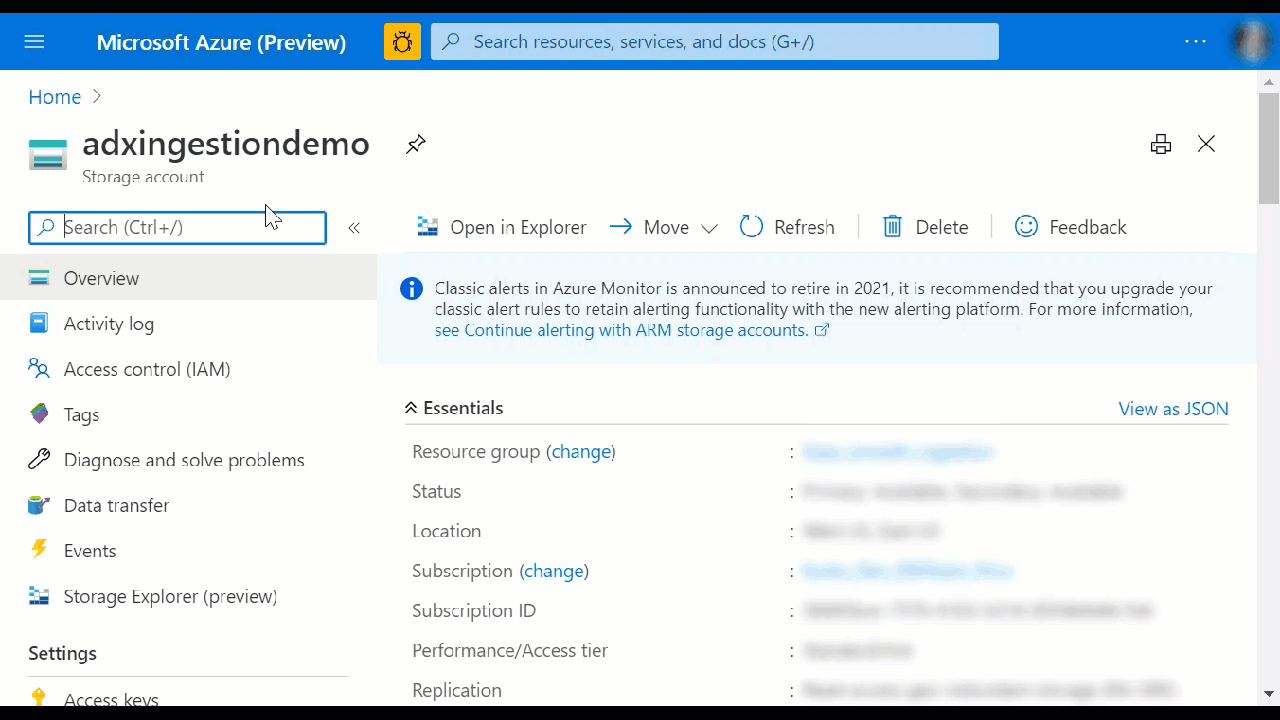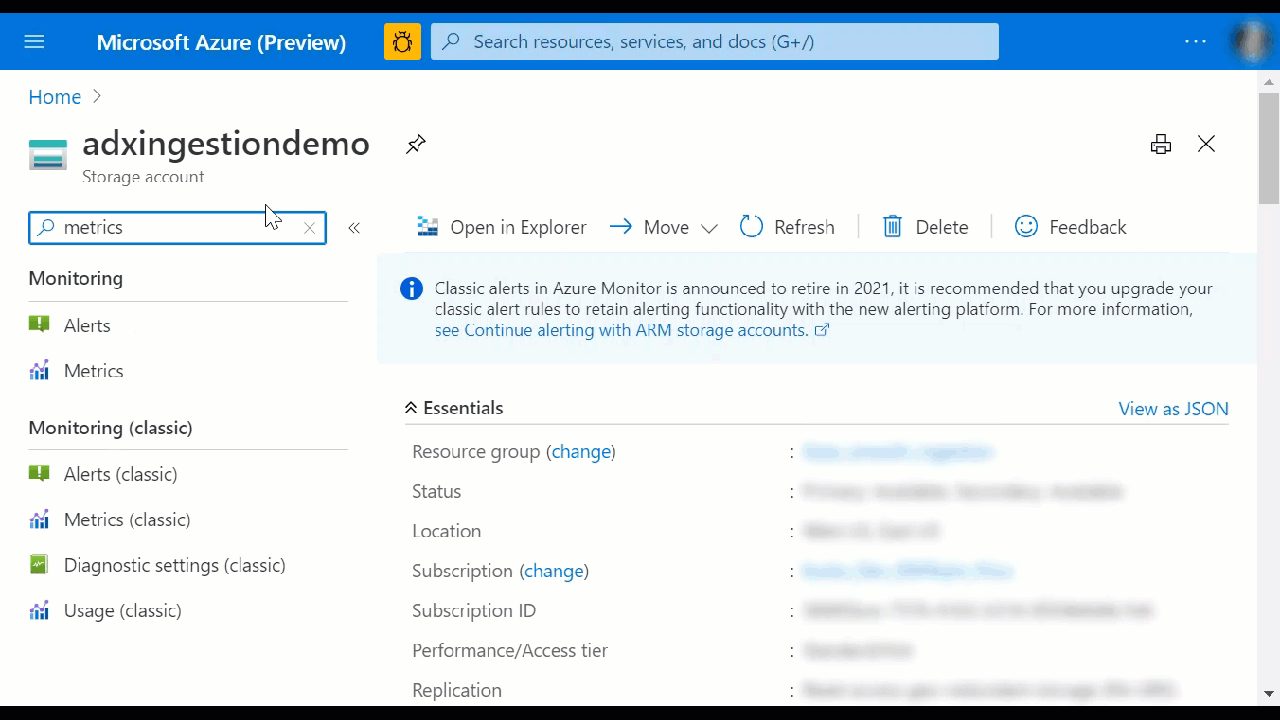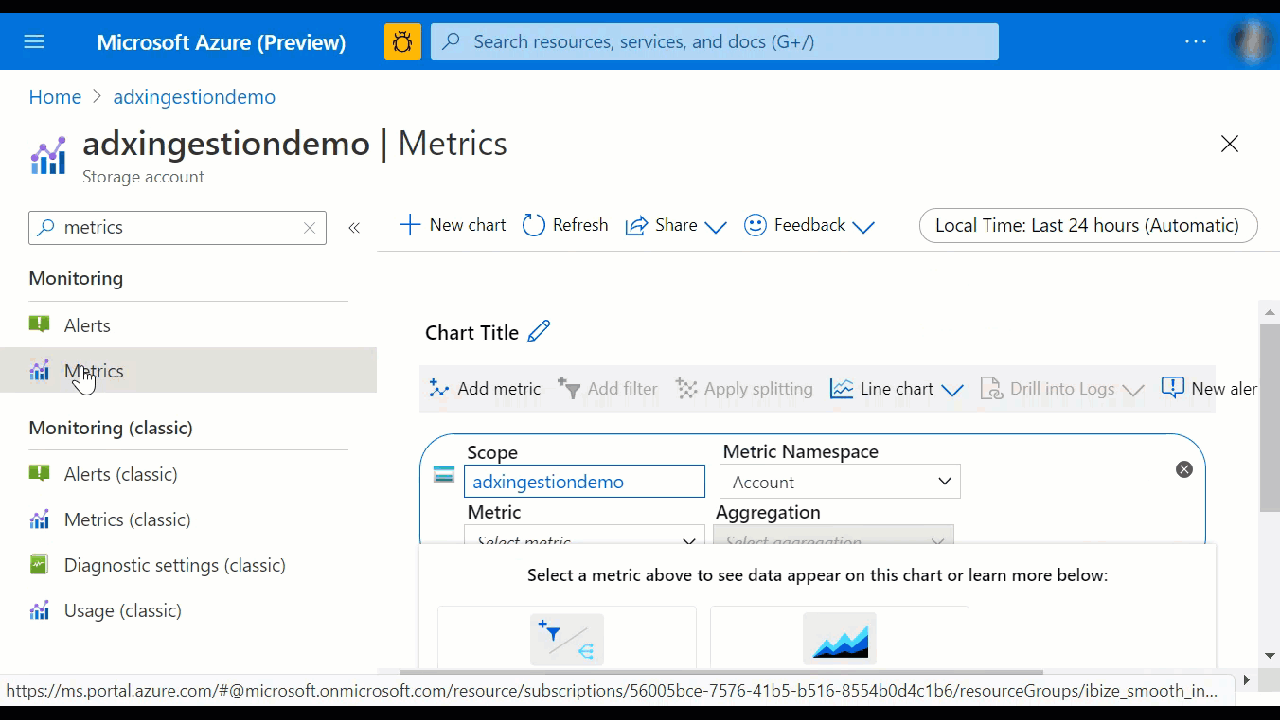
Nel riquadro delle metriche selezionare metriche specifiche da tenere traccia, scegliere come aggregare i dati e creare grafici delle metriche da visualizzare nel dashboard.
I selettore Spazio dei nomi delle risorse e delle metriche sono pre-selezionati per il cluster Esplora dati di Azure. I numeri nell'immagine seguente corrispondono all'elenco numerato riportato di seguito. Illustrano le diverse opzioni per configurare e visualizzare le metriche.
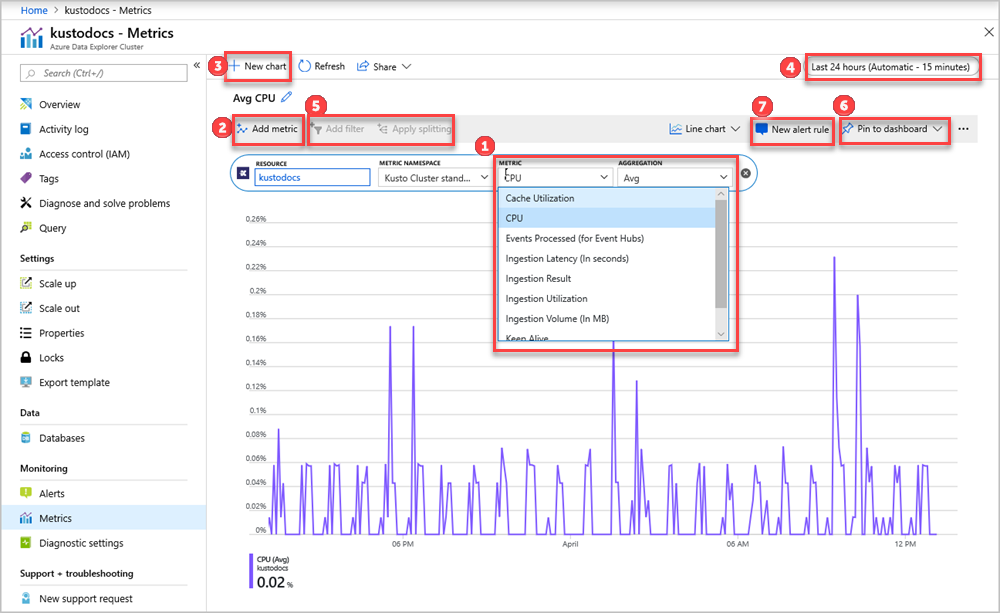
- Per creare un grafico delle metriche, selezionare Nome metrica e aggregazione pertinente per metrica. Per altre informazioni sulle diverse metriche, vedere Metriche di Azure Esplora dati supportate.
- Selezionare Aggiungi metrica per visualizzare più metriche tracciate nello stesso grafico.
- Selezionare + Nuovo grafico per visualizzare più grafici in una sola visualizzazione.
- Usare la selezione ora per modificare l'intervallo di tempo (impostazione predefinita: ultime 24 ore).
- Usare Aggiungi filtro e Applica suddivisione per le metriche con dimensioni.
- Selezionare Aggiungi al dashboard per aggiungere la configurazione del grafico ai dashboard in modo da poterla visualizzare di nuovo.
- Impostare Nuova regola di avviso per visualizzare le metriche usando i criteri impostati. La nuova regola di avviso includerà la risorsa di destinazione, la metrica, la suddivisione e le dimensioni di filtro del grafico. Modificare queste impostazioni nel riquadro di creazione della regola di avviso.
Metriche di Azure Esplora dati supportate
Le metriche di Azure Esplora dati forniscono informazioni dettagliate sulle prestazioni complessive e sull'uso delle risorse, nonché informazioni su azioni specifiche, ad esempio l'inserimento o la query. Le metriche in questo articolo sono state raggruppate in base al tipo di utilizzo.
I tipi di metriche sono:
- Metriche del cluster
- Esportare le metriche
- Metriche di inserimento
- Metriche di inserimento in streaming
- Metriche di query
- Metriche di visualizzazione materializzate
Per un elenco alfabetico delle metriche di Monitoraggio di Azure per le Esplora dati di Azure, vedere Metriche del cluster di Azure Esplora dati supportate.
Metriche del cluster
Le metriche del cluster tengono traccia dell'integrità generale del cluster. Ad esempio, uso di risorse e inserimento e velocità di risposta.
| Metrica | Unità | Aggregazione | Descrizione metrica | Dimensioni |
|---|---|---|---|---|
| Utilizzo della cache (deprecato) | Percentuale | Avg, Max, Min | Percentuale delle risorse della cache allocate attualmente in uso dal cluster. La cache corrisponde alle dimensioni dell'unità SSD allocata per l'attività utente in base ai criteri di cache definiti. Un utilizzo medio della cache non superiore all'80% è uno stato sostenibile per un cluster. Se l'utilizzo medio della cache è superiore all'80%, il cluster deve essere scalabilità fino a un piano tariffario ottimizzato per l'archiviazione o con scalabilità orizzontale a più istanze. In alternativa, adattare i criteri della cache a un minor numero di giorni nella cache. Se l'utilizzo della cache supera il 100%, le dimensioni dei dati da memorizzare nella cache sono maggiori delle dimensioni totali della cache nel cluster. Questa metrica è deprecata e presentata solo per la compatibilità con le versioni precedenti. Usare invece la metrica "Fattore di utilizzo cache". |
None |
| Fattore di utilizzo della cache | Percentuale | Avg, Max, Min | Percentuale di spazio su disco utilizzato dedicato per la cache ad accesso frequente nel cluster. Il 100% indica che lo spazio su disco assegnato ai dati ad accesso frequente viene utilizzato in modo ottimale. Non è necessaria alcuna azione e il cluster è completamente corretto. Meno del 100% significa che lo spazio su disco assegnato per i dati ad accesso frequente non è completamente utilizzato. Più del 100% significa che lo spazio su disco del cluster non è sufficientemente grande da contenere i dati ad accesso frequente, come definito dai criteri di memorizzazione nella cache. Per garantire che sia disponibile spazio sufficiente per tutti i dati ad accesso frequente, è necessario ridurre la quantità di dati ad accesso frequente o aumentare il numero di istanze del cluster. È consigliabile abilitare la scalabilità automatica. |
None |
| CPU | Percentuale | Avg, Max, Min | Percentuale delle risorse di calcolo allocate attualmente in uso dai computer nel cluster. Una CPU media non superiore all'80% è sostenibile per un cluster. Il valore massimo della CPU è pari al 100%, il che significa che non sono disponibili altre risorse di calcolo per elaborare i dati. Quando un cluster non funziona correttamente, controllare il valore massimo della CPU per determinare se sono presenti CPU specifiche bloccate. |
None |
| Utilizzo inserimento | Percentuale | Avg, Max, Min | Percentuale di risorse effettive usate per inserire dati dalle risorse totali allocate, nei criteri di capacità, per eseguire l'inserimento. I criteri di capacità predefiniti prevedono un massimo di 512 operazioni di inserimento simultanee oppure il 75% delle risorse del cluster investito nell'inserimento. Un utilizzo medio dell'inserimento non superiore all'80% è uno stato sostenibile per un cluster. Il valore massimo di utilizzo dell'inserimento è pari al 100%, il che significa che viene usata tutta la capacità di inserimento nel cluster e che potrebbe essere creata una coda di inserimento. |
None |
| InstanceCount | Count | Media | Numero totale di istanze. | |
| Keep alive | Count | Media | Tiene traccia della velocità di risposta del cluster. Se il cluster è completamente reattivo, viene restituito il valore 1, mentre se il cluster è bloccato o disconnesso, viene restituito 0. |
|
| Numero totale di comandi limitati | Count | Avg, Max, Min, Sum | Numero di comandi limitati (rifiutati) nel cluster, poiché è stato raggiunto il numero massimo consentito di comandi simultanei (paralleli). | None |
| Numero totale di extent | Count | Avg, Max, Min, Sum | Numero totale di extent di dati nel cluster. Le modifiche apportate a questa metrica possono implicare modifiche massicce della struttura dei dati e un carico elevato nel cluster, poiché l'unione degli extent di dati è un'attività pesante della CPU. |
None |
| Latenza dei follower | Millisecondi | Avg, Max, Min | I database follower sincronizzano le modifiche nei database leader. A causa della sincronizzazione, è previsto un ritardo dei dati di alcuni secondi fino a pochi minuti nella disponibilità dei dati. Questa metrica misura la durata del ritardo di tempo. Il ritardo di tempo dipende da diversi fattori, ad esempio la dimensione complessiva e la frequenza dei dati inseriti nel leader, il numero di database seguiti, la frequenza delle operazioni interne eseguite sul leader (operazioni di merge/ricompilazione). Si tratta di una metrica a livello di cluster: i follower intercettano i metadati di tutti i database seguiti. Questa metrica rappresenta la latenza del processo. |
None |
Esportare le metriche
Le metriche di esportazione tengono traccia dell'integrità generale e delle prestazioni delle operazioni di esportazione, ad esempio latenze, risultati, numero di record e utilizzo.
| Metrica | Unità | Aggregazione | Descrizione metrica | Dimensioni |
|---|---|---|---|---|
| Numero di esportazione continuo di record esportati | Conteggio | Somma | Numero di record esportati in tutti i processi di esportazione continua. | ContinuousExportName |
| Ritardo massimo esportazione continua | Count | Max | Ritardo (in minuti) segnalato dai processi di esportazione continua nel cluster. | None |
| Numero di esportazioni continue in sospeso | Count | Max | Numero di processi di esportazione continua in sospeso. Questi processi sono pronti per l'esecuzione ma in attesa in una coda, probabilmente a causa di capacità insufficiente. | |
| Risultato dell'esportazione continua | Conteggio | Conteggio | Risultato errore/esito positivo di ogni esecuzione dell'esportazione continua. | ContinuousExportName |
| Utilizzo esportazione | Percentuale | Max | Capacità di esportazione usata, fuori dalla capacità totale di esportazione nel cluster (compresa tra 0 e 100). | None |
Metriche di inserimento
Le metriche di inserimento tengono traccia dell'integrità generale e delle prestazioni delle operazioni di inserimento, ad esempio la latenza, i risultati e il volume. Per perfezionare l'analisi:
- Applicare filtri ai grafici per tracciare dati parziali in base alle dimensioni. Ad esempio, esplorare l'inserimento in un oggetto specifico
Database. - Applicare la suddivisione a un grafico per visualizzare i dati in base a componenti diversi. Questo processo è utile per analizzare le metriche segnalate da ogni passaggio della pipeline di inserimento, ad esempio
Blobs received.
| Metrica | Unità | Aggregazione | Descrizione metrica | Dimensioni |
|---|---|---|---|---|
| Numero di BLOB batch | Count | Avg, Max, Min | Numero di origini dati in un batch completato per l'inserimento. | Database |
| Durata batch | Secondi | Avg, Max, Min | Durata della fase di invio in batch nel flusso di inserimento. | Database |
| Dimensioni del batch | Byte | Avg, Max, Min | Dimensioni dei dati non compresse previste in un batch aggregato per l'inserimento. | Database |
| Batch elaborati | Count | Sum, Max, Min | Numero di batch completati per l'inserimento. Batching Type: trigger per la chiusura di un batch. Per un elenco completo dei tipi di invio in batch, vedere Tipi di invio in batch. |
Database, tipo di invio in batch |
| BLOB ricevuti | Count | Sum, Max, Min | Numero di BLOB ricevuti dal flusso di input da un componente. Usare l'applicazione della suddivisione per analizzare ogni componente. |
Database, Tipo di componente, Nome componente |
| BLOB elaborati | Count | Sum, Max, Min | Numero di BLOB elaborati da un componente. Usare l'applicazione della suddivisione per analizzare ogni componente. |
Database, Tipo di componente, Nome componente |
| BLOB eliminati | Count | Sum, Max, Min | Numero di BLOB eliminati definitivamente da un componente. Per ogni BLOB di questo tipo, viene inviata una Ingestion result metrica con un motivo di errore. Usare l'applicazione della suddivisione per analizzare ogni componente. |
Database, Tipo di componente, Nome componente |
| Latenza di individuazione | Secondi | Media | Tempo trascorso dall'accodamento dei dati fino all'individuazione da parte delle connessioni dati. Questa volta non è incluso nella latenza di fase o nelle metriche di latenza di inserimento. La latenza di individuazione può aumentare nelle situazioni seguenti:
|
Tipo di componente, nome componente |
| Eventi ricevuti | Count | Sum, Max, Min | Numero di eventi ricevuti dalle connessioni dati dal flusso di input. | Tipo di componente, nome componente |
| Eventi elaborati | Count | Sum, Max, Min | Numero di eventi elaborati dalle connessioni dati. | Tipo di componente, nome componente |
| Eventi eliminati | Count | Sum, Max, Min | Numero di eventi eliminati definitivamente dalle connessioni dati. Per ogni evento di questo tipo, viene inviata una Ingestion result metrica con un motivo di errore. |
Tipo di componente, nome componente |
| Latenza di inserimento | Secondi | Avg, Max, Min | Latenza dei dati inseriti, dal momento in cui i dati sono stati ricevuti nel cluster fino a quando non è pronto per la query. Il periodo di latenza dell'inserimento dipende dallo scenario di inserimento.Ingestion Kind: inserimento in streaming o inserimento in coda |
Tipo di inserimento |
| Risultati inserimento | Conteggio | Somma | Numero totale di origini che non sono riuscite o che hanno avuto esito positivo da inserire.Status: operazione riuscita per l'inserimento riuscito o la categoria di errori per gli errori. Per un elenco completo delle possibili categorie di errori, vedere Codici di errore di inserimento in Azure Esplora dati. Failure Status Type: indica se l'errore è permanente o temporaneo. Per l'inserimento riuscito, questa dimensione è None.Nota:
|
Stato, Tipo di stato errore |
| Volume di inserimento (in byte) | Count | Max, Sum | Dimensioni totali dei dati inseriti nel cluster (in byte) prima della compressione. | Database |
| Lunghezza coda | Count | Media | Numero di messaggi in sospeso nella coda di input di un componente. Il componente di gestione batch ha un messaggio per BLOB. Il componente gestione inserimento ha un messaggio per batch. Un batch è un singolo comando di inserimento con uno o più BLOB. | Tipo di componente |
| Messaggio in coda meno recente | Secondi | Media | Tempo in secondi da quando è stato inserito il messaggio meno recente nella coda di input di un componente. | Tipo di componente |
| Byte delle dimensioni dei dati ricevuti | Byte | Avg, Sum | Dimensioni dei dati ricevuti dalle connessioni dati dal flusso di input. | Tipo di componente, nome componente |
| Latenza delle fasi | Secondi | Media | Ora da cui un messaggio viene accettato da Azure Esplora dati, fino a quando il relativo contenuto non viene ricevuto da un componente di inserimento per l'elaborazione. Usare applica filtri e selezionare Component Type > StorageEngine per visualizzare la latenza totale di inserimento. |
Database, tipo di componente |
Metriche di inserimento in streaming
Le metriche di inserimento in streaming tengono traccia dei dati di inserimento in streaming e della frequenza delle richieste, della durata e dei risultati.
| Metrica | Unità | Aggregazione | Descrizione metrica | Dimensioni |
|---|---|---|---|---|
| Streaming Ingest Data Rate (Velocità dati inserimento streaming) | Count | RateRequestsPerSecond | Volume totale di dati inseriti nel cluster. | None |
| Streaming Ingest Duration (Durata inserimento streaming) | Millisecondi | Avg, Max, Min | Durata totale di tutte le richieste di inserimento in streaming. | None |
| Streaming Ingest Request Rate (Frequenza richieste inserimento streaming) | Count | Count, Avg, Max, Min, Sum | Numero totale di richieste di inserimento in streaming. | None |
| Streaming Ingest Result (Risultato inserimento streaming) | Count | Media | Numero totale di richieste di inserimento in streaming in base al tipo di risultato. | Risultato |
Metriche di query
Le metriche delle prestazioni delle query tengono traccia della durata delle query e del numero totale di query simultanee o limitate.
| Metrica | Unità | Aggregazione | Descrizione metrica | Dimensioni |
|---|---|---|---|---|
| Durata delle query | Millisecondi | Avg, Min, Max, Sum | Tempo totale fino alla ricezione dei risultati della query (non include latenza di rete). | QueryStatus |
| QueryResult | Conteggio | Conteggio | Numero totale di query. | QueryStatus |
| Numero totale di query simultanee | Count | Avg, Max, Min, Sum | Numero di query eseguite in parallelo nel cluster. Questa metrica è un buon modo per stimare il carico nel cluster. | None |
| Numero totale di query limitate | Count | Avg, Max, Min, Sum | Numero di query limitate (rifiutate) nel cluster. Il numero massimo di query simultanee (parallele) consentite è definito nei criteri di limite di frequenza delle richieste. | None |
| Latenza di coerenza debole | Millisecondi | Avg, Max, Min | Età dello snapshot dei metadati usato dai nodi che eseguono il servizio di coerenza debole. | Database, Nodo |
Metriche di visualizzazione materializzate
| Metrica | Unità | Aggregazione | Descrizione metrica | Dimensioni |
|---|---|---|---|---|
| MaterializedViewHealth | 1, 0 | Media | Il valore è 1 se la vista è considerata integra; in caso contrario, 0. | Database, MaterializedViewName |
| MaterializedViewAgeSeconds | Secondi | Media | L'oggetto age della vista è definito dall'ora corrente meno l'ora dell'ultima inserimento elaborata dalla vista. Il valore della metrica è il tempo in secondi (minore è il valore, la visualizzazione è "più sana"). |
Database, MaterializedViewName |
| MaterializedViewResult | 1 | Media | La metrica include una Result dimensione che indica il risultato dell'ultimo ciclo di materializzazione (vedere la metrica MaterializedViewResult per informazioni dettagliate sui valori possibili). Il valore della metrica è sempre uguale a 1. |
Database, MaterializedViewName, Result |
| MaterializedViewRecordsInDelta | Conteggio record | Media | Numero di record attualmente presenti nella parte non elaborata della tabella di origine. Per altre informazioni, vedere come funzionano le viste materializzate | Database, MaterializedViewName |
| MaterializedViewExtentsRebuild | Conteggio extent | Media | Numero di extent che richiedevano aggiornamenti nel ciclo di materializzazione. | Database, MaterializedViewName |
| MaterializedViewDataLoss | 1 | Max | La metrica viene generata quando i dati di origine non elaborati si avvicinano alla conservazione. Indica che la vista materializzata non è integra. | Database, MaterializedViewName, Kind |
Metriche di partizionamento
Le metriche di partizionamento monitorano il processo di partizionamento per le tabelle con criteri di partizionamento.
| Metrica | Unità | Aggregazione | Descrizione metrica | Dimensioni |
|---|---|---|---|---|
| PartitioningPercentage | Percentuale | Avg, Min, Max | Percentuale di record partizionati rispetto al numero totale di record. | Database, Tabella |
| PartitioningPercentageHot | Percentuale | Avg, Min, Max | Percentuale di record partizionati correlati al numero totale di record (solo nella cache "ad accesso frequente"). | Database, Tabella |
| ProcessedPartitionedRecords | Percentuale | Avg, Min, Max, Sum | Numero di record partizionati nell'intervallo di tempo misurato. | Database, Tabella |