Distribuire un carico di lavoro IoT Edge usando la condivisione GPU in Azure Stack Edge Pro
Questo articolo descrive in che modo i carichi di lavoro in contenitori possono condividere le GPU nel dispositivo AZURE Stack Edge Pro GPU. L'approccio prevede l'abilitazione del servizio Multi-Process (MPS) e quindi la specifica dei carichi di lavoro GPU tramite una distribuzione IoT Edge.
Prerequisiti
Prima di iniziare, verificare che:
Si ha accesso a un dispositivo AZURE Stack Edge Pro GPU attivato e configurato per il calcolo. L'endpoint dell'API Kubernetes è stato aggiunto al file nel
hostsclient che accederà al dispositivo.Si ha accesso a un sistema client con un sistema operativo supportato. Se si usa un client Windows, il sistema deve eseguire PowerShell 5.0 o versione successiva per accedere al dispositivo.
Salvare la distribuzione
jsonseguente nel sistema locale. Si useranno le informazioni di questo file per eseguire la distribuzione di IoT Edge. Questa distribuzione si basa su contenitori CUDA semplici disponibili pubblicamente da Nvidia.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Verificare il driver GPU, la versione CUDA
Il primo passaggio consiste nel verificare che il dispositivo esegua i driver GPU necessari e le versioni CUDA.
Esegui questo comando:
Get-HcsGpuNvidiaSmiNell'output di Nvidia smi prendere nota della versione GPU e della versione CUDA nel dispositivo. Se si esegue il software Azure Stack Edge 2102, questa versione corrisponde alle versioni del driver seguenti:
- Versione del driver GPU: 460.32.03
- Versione CUDA: 11.2
Di seguito è riportato un esempio di output:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Tenere aperta questa sessione perché verrà usata per visualizzare l'output smi nvidia in tutto l'articolo.
Eseguire la distribuzione senza condivisione del contesto
È ora possibile distribuire un'applicazione nel dispositivo quando il servizio Multi-Process non è in esecuzione e non è presente alcuna condivisione del contesto. La distribuzione viene eseguita tramite il portale di Azure nello iotedge spazio dei nomi esistente nel dispositivo.
Creare un utente nello spazio dei nomi IoT Edge
Prima di tutto si creerà un utente che si connetterà allo spazio dei iotedge nomi . I moduli IoT Edge vengono distribuiti nello spazio dei nomi iotedge. Per altre informazioni, vedere Spazi dei nomi Kubernetes nel dispositivo.
Seguire questa procedura per creare un utente e concedere all'utente l'accesso allo spazio dei iotedge nomi.
Creare un nuovo utente nello spazio dei
iotedgenomi . Esegui questo comando:New-HcsKubernetesUser -UserName <user name>Di seguito è riportato un esempio di output:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Copiare l'output visualizzato in testo normale. Salvare l'output come file di configurazione (senza estensione) nella
.kubecartella del profilo utente nel computer locale,C:\Users\<username>\.kubead esempio .Concedere all'utente creato l'accesso allo spazio dei
iotedgenomi . Esegui questo comando:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Di seguito è riportato un esempio di output:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Per istruzioni dettagliate, vedere Connessione a e gestire un cluster Kubernetes tramite kubectl nel dispositivo Azure Stack Edge Pro GPU.
Distribuire moduli tramite il portale
Distribuire moduli IoT Edge tramite il portale di Azure. Verranno distribuiti moduli di esempio Nvidia CUDA disponibili pubblicamente che eseguono la simulazione n-body.
Assicurarsi che il servizio IoT Edge sia in esecuzione nel dispositivo.
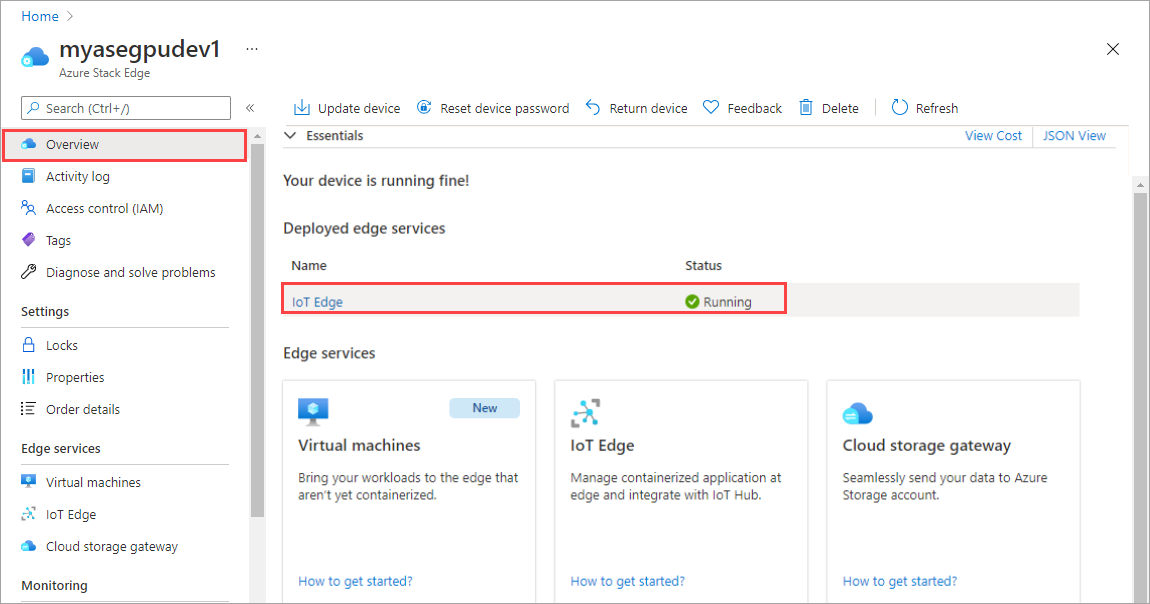
Selezionare il riquadro IoT Edge nel riquadro destro. Passare a Proprietà di IoT Edge>. Nel riquadro destro selezionare la risorsa hub IoT associata al dispositivo.
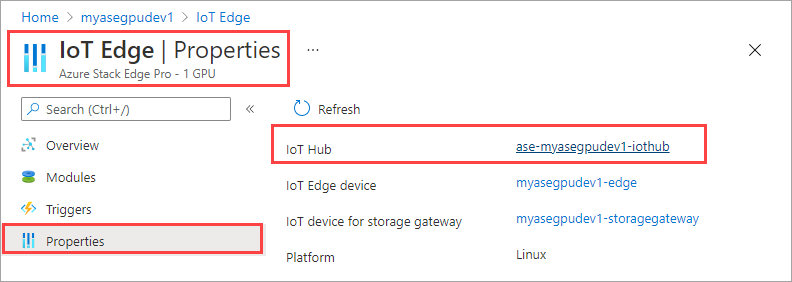
Nella risorsa hub IoT passare a Automatico Gestione dispositivi > IoT Edge. Nel riquadro destro selezionare il dispositivo IoT Edge associato al dispositivo.
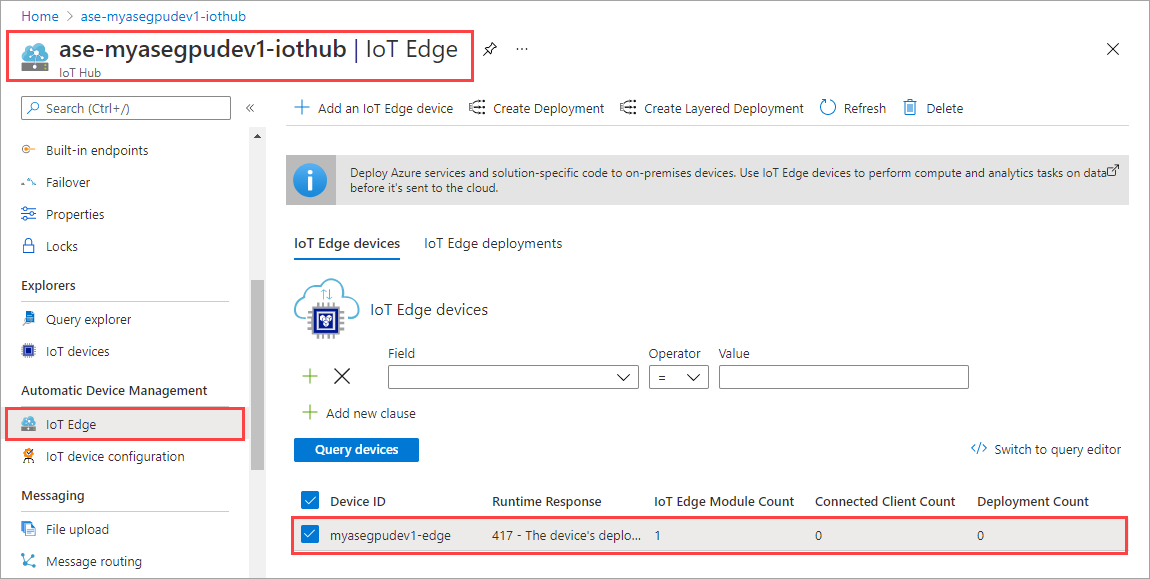
Selezionare Imposta moduli.
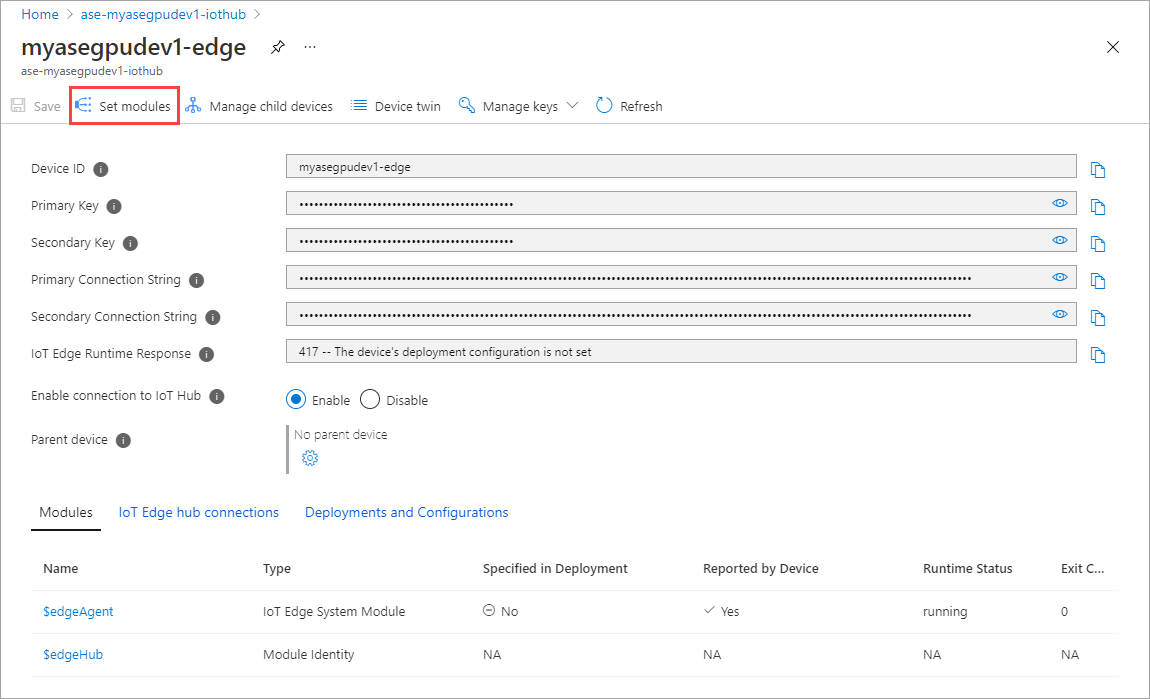
Selezionare + Aggiungi > + modulo IoT Edge.
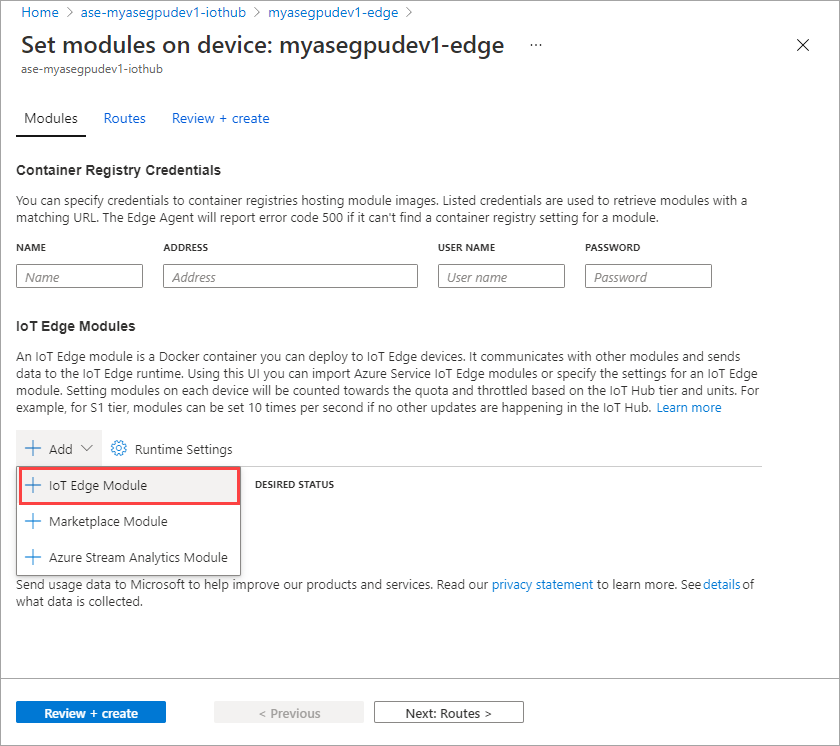
Nella scheda Modulo Impostazioni specificare il nome del modulo IoT Edge e l'URI immagine. Impostare Criteri pull immagine su Sì per la creazione.
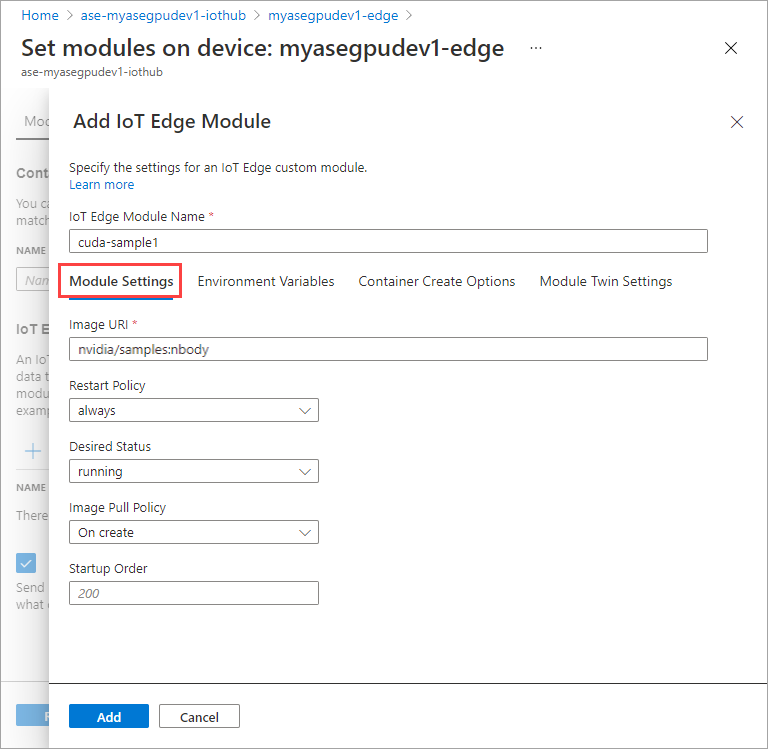
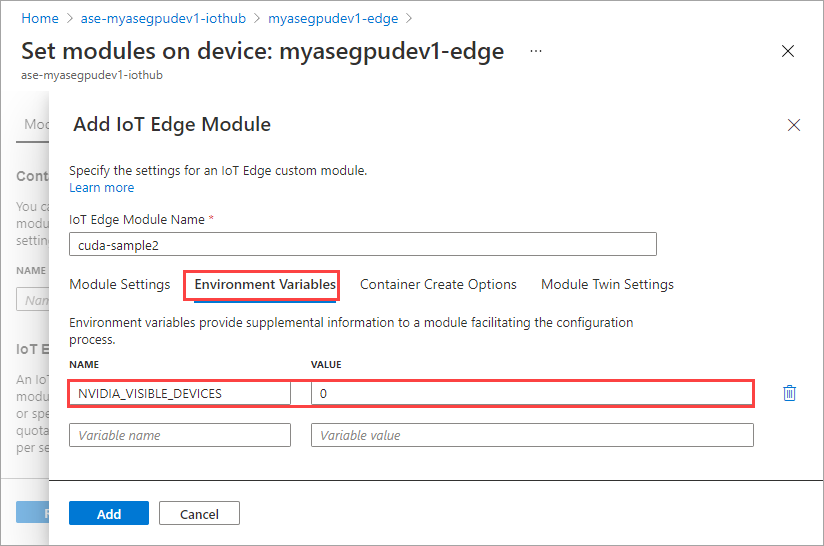
Nella scheda Variabili di ambiente specificare NVIDIA_VISIBLE_DEVICES come 0.
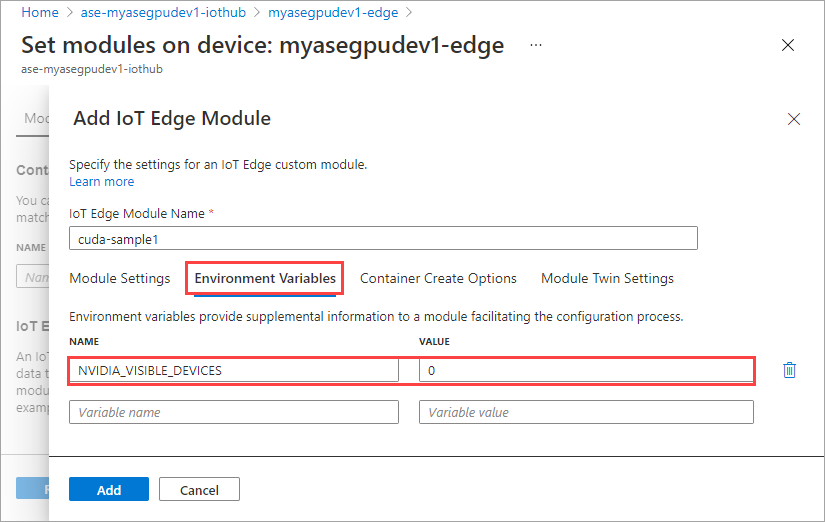
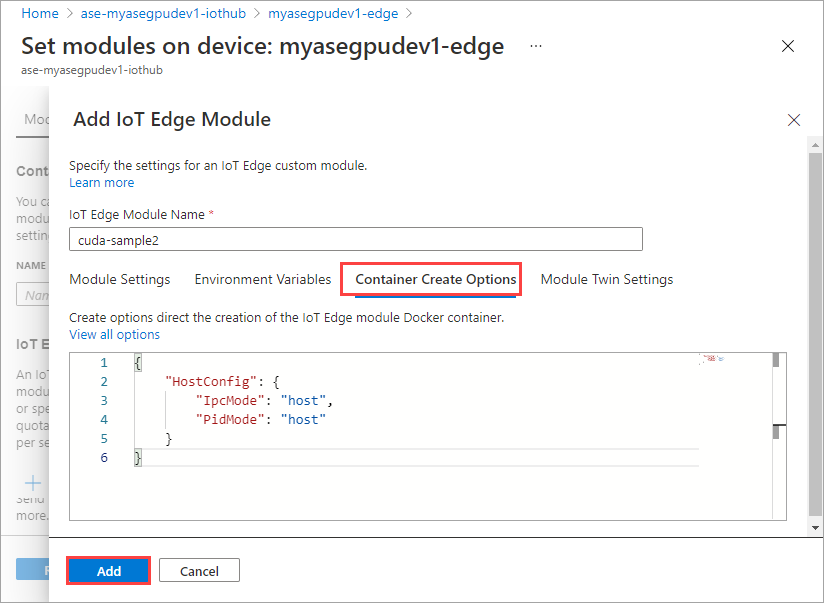
Nella scheda Opzioni di creazione del contenitore specificare le opzioni seguenti:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }Le opzioni vengono visualizzate nel modo seguente:
Seleziona Aggiungi.
Il modulo aggiunto deve essere visualizzato come In esecuzione.
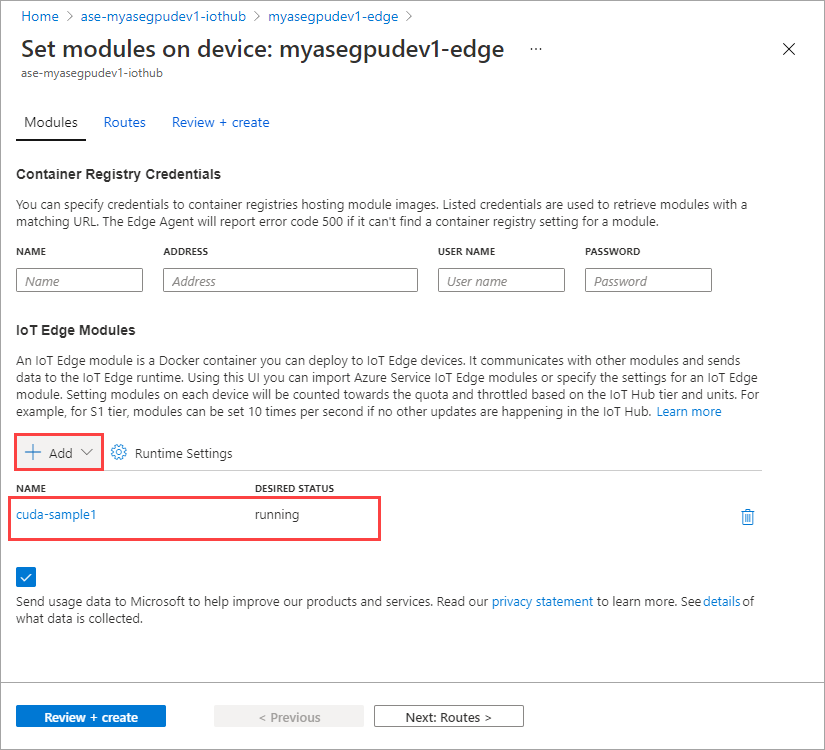
Ripetere tutti i passaggi per aggiungere un modulo seguito durante l'aggiunta del primo modulo. In questo esempio specificare il nome del modulo come
cuda-sample2.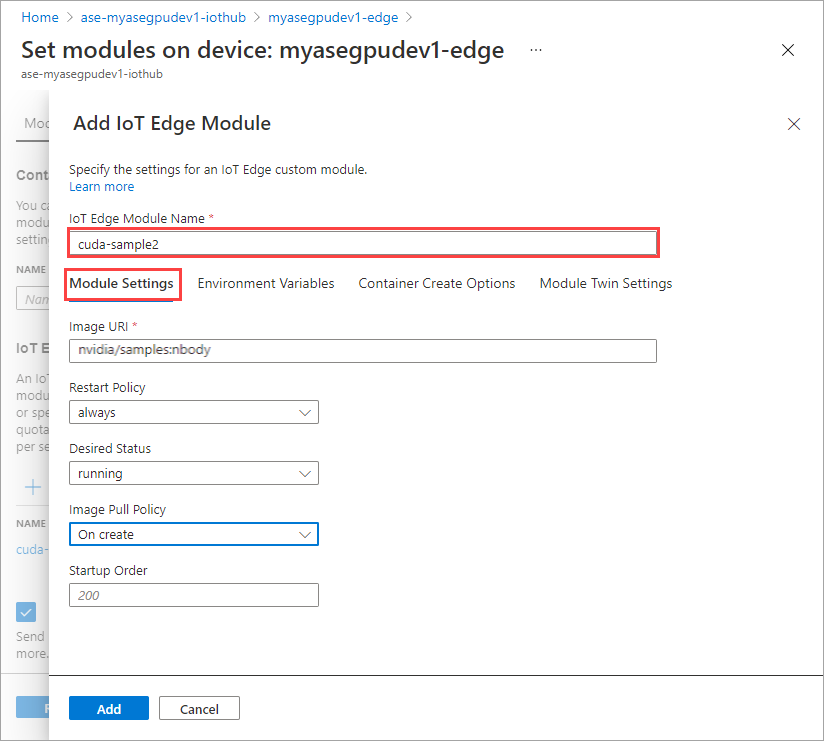
Usare la stessa variabile di ambiente di entrambi i moduli condividerà la stessa GPU.
Usare le stesse opzioni di creazione del contenitore fornite per il primo modulo e selezionare Aggiungi.
Nella pagina Imposta moduli selezionare Rivedi e crea e quindi crea.
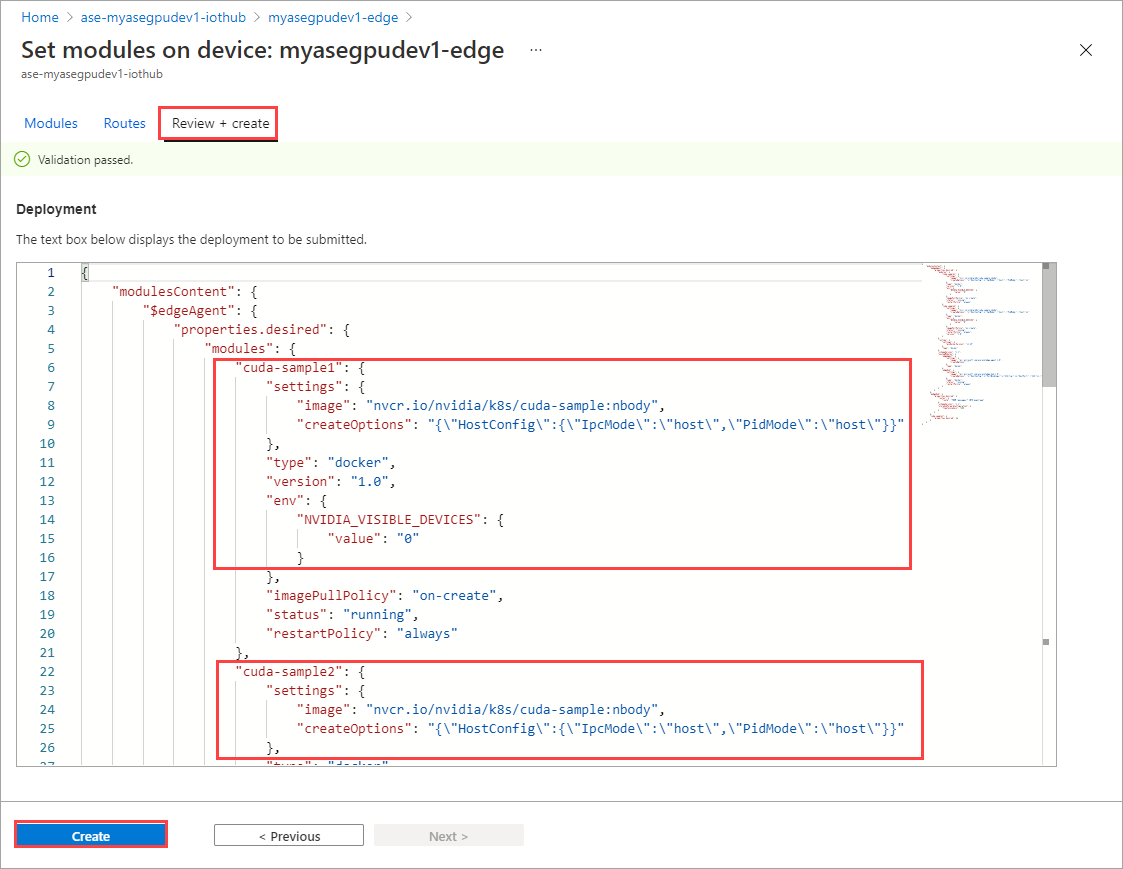
Lo stato di runtime di entrambi i moduli dovrebbe ora essere In esecuzione.
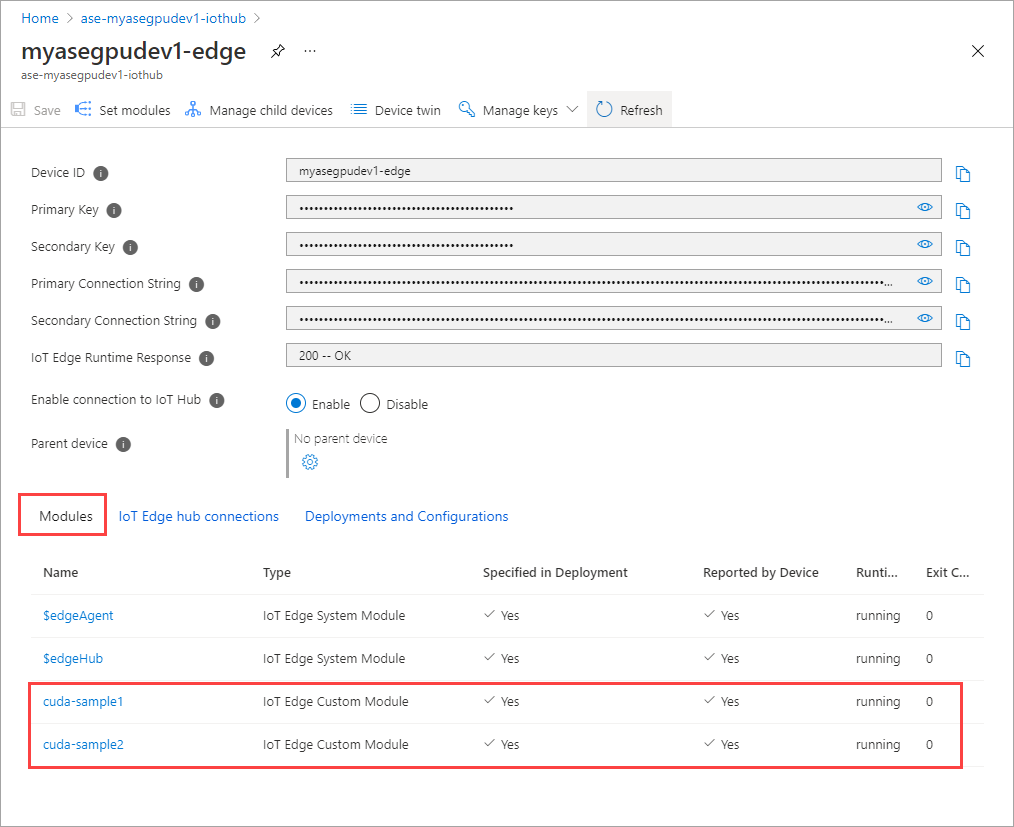
Monitorare la distribuzione del carico di lavoro
Aprire una nuova sessione di PowerShell.
Elencare i pod in esecuzione nello spazio dei
iotedgenomi . Esegui questo comando:kubectl get pods -n iotedgeDi seguito è riportato un esempio di output:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Nel dispositivo sono presenti due pod
cuda-sample1-97c494d7f-lnmnsecuda-sample2-d9f6c4688-2rld9in esecuzione.Mentre entrambi i contenitori eseguono la simulazione n-body, visualizzare l'utilizzo della GPU dall'output smi Nvidia. Passare all'interfaccia di PowerShell del dispositivo ed eseguire
Get-HcsGpuNvidiaSmi.Di seguito è riportato un esempio di output quando entrambi i contenitori eseguono la simulazione n-body:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Come si può notare, sono disponibili due contenitori in esecuzione con simulazione n corpo sulla GPU 0. È anche possibile visualizzare l'utilizzo della memoria corrispondente.
Una volta completata la simulazione, l'output smi Nvidia mostrerà che non sono presenti processi in esecuzione nel dispositivo.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Al termine della simulazione n-body, visualizzare i log per comprendere i dettagli della distribuzione e il tempo necessario per il completamento della simulazione.
Di seguito è riportato un esempio di output del primo contenitore:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Di seguito è riportato un esempio di output del secondo contenitore:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Arrestare la distribuzione del modulo. Nella risorsa hub IoT per il dispositivo:
Passare a Distribuzione > automatica dei dispositivi IoT Edge. Selezionare il dispositivo IoT Edge corrispondente al dispositivo.
Passare a Imposta moduli e selezionare un modulo.
Nella scheda Moduli selezionare un modulo.
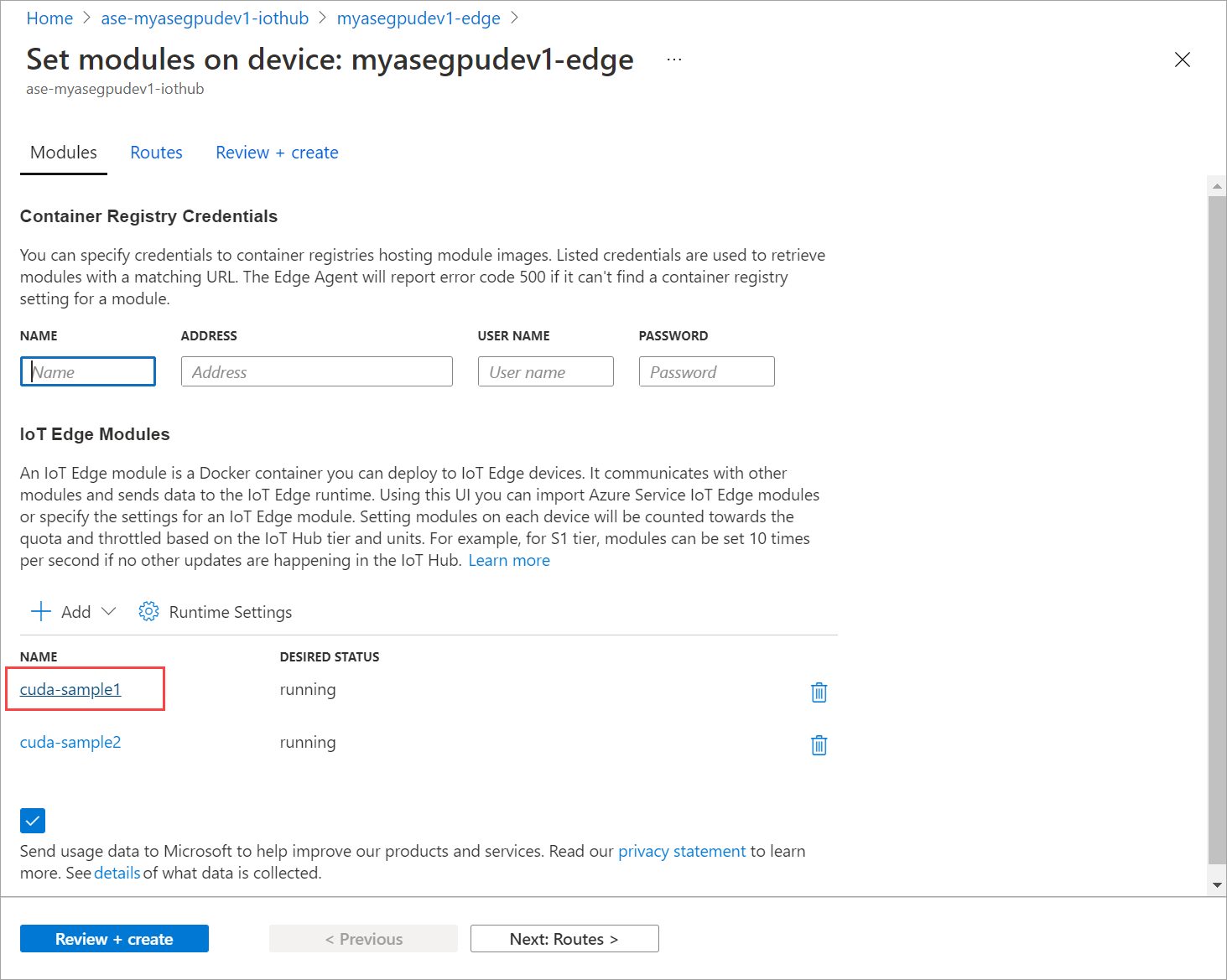
Nella scheda Impostazioni modulo impostare Stato desiderato su arrestato. Selezionare Aggiorna.
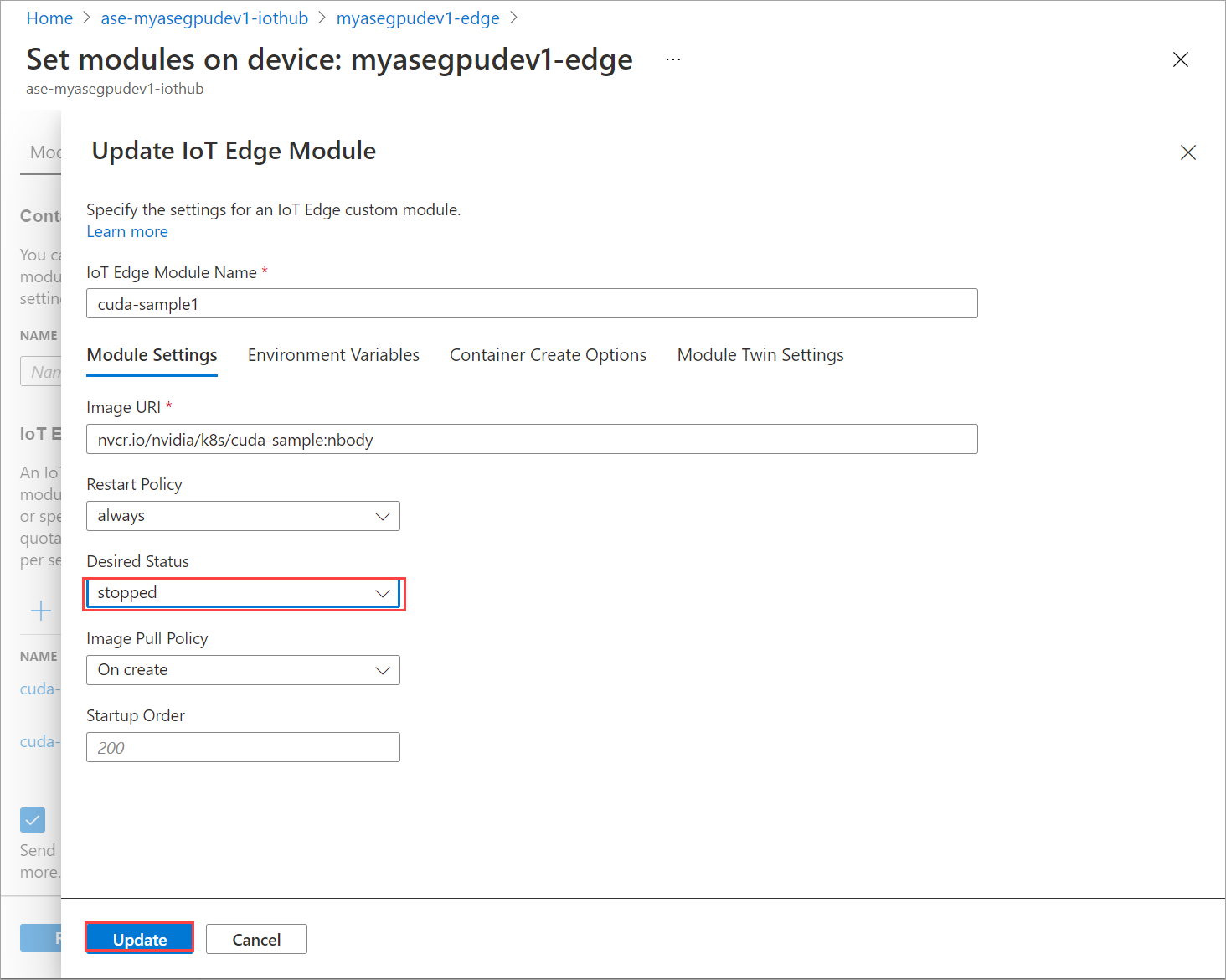
Ripetere i passaggi per arrestare il secondo modulo distribuito nel dispositivo. Selezionare Rivedi e crea e quindi Crea. Questa operazione deve aggiornare la distribuzione.
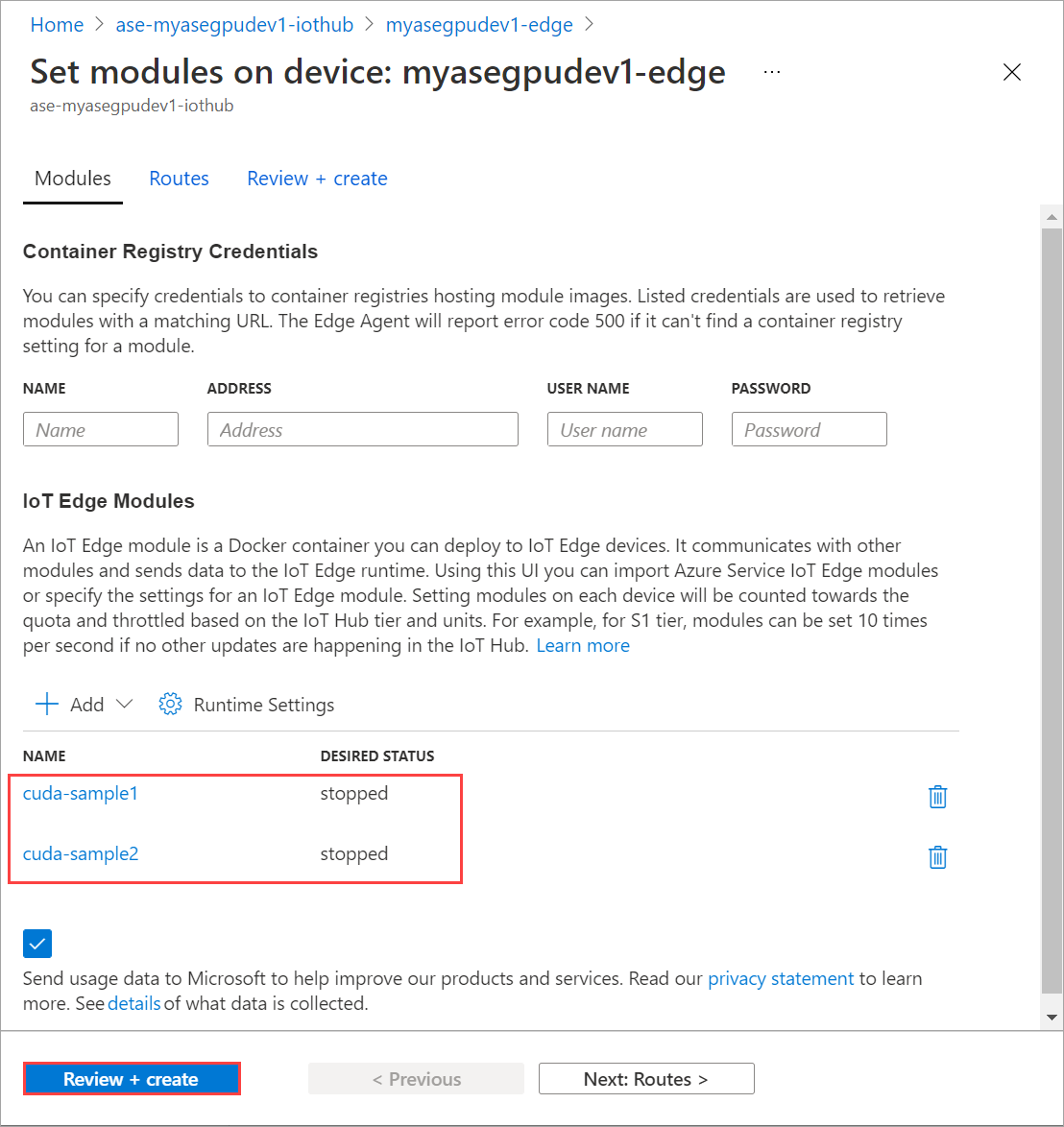
Aggiornare la pagina Imposta moduli più volte. fino a quando lo stato del runtime del modulo non viene visualizzato come Arrestato.
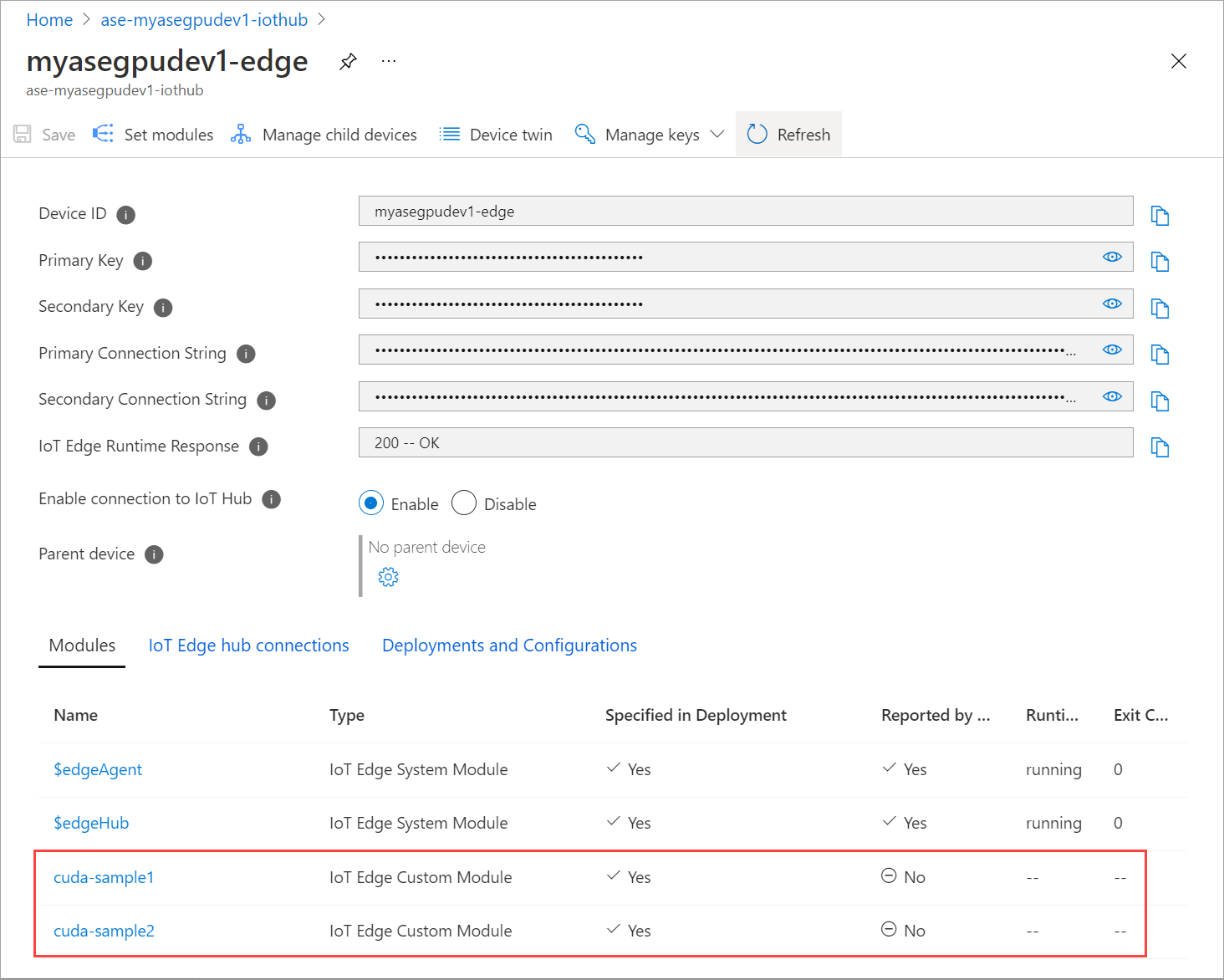
Eseguire la distribuzione con la condivisione del contesto
È ora possibile distribuire la simulazione n-body in due contenitori CUDA quando MPS è in esecuzione nel dispositivo. Prima di tutto, si abiliterà MPS nel dispositivo.
Per abilitare MPS nel dispositivo, eseguire il
Start-HcsGpuMPScomando .[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Ottenere l'output di Nvidia smi dall'interfaccia PowerShell del dispositivo. È possibile visualizzare il
nvidia-cuda-mps-serverprocesso o il servizio MPS è in esecuzione nel dispositivo.Di seguito è riportato un esempio di output:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiDistribuire i moduli arrestati in precedenza. Impostare Lo stato desiderato su in esecuzione tramite Set modules (Imposta moduli).
Di seguito è riportato l'output di esempio:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>È possibile notare che i moduli vengono distribuiti e in esecuzione nel dispositivo.
Quando i moduli vengono distribuiti, la simulazione n-body viene avviata anche in entrambi i contenitori. Di seguito è riportato l'output di esempio quando la simulazione è stata completata nel primo contenitore:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Di seguito è riportato l'output di esempio al termine della simulazione nel secondo contenitore:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Ottenere l'output smi Nvidia dall'interfaccia PowerShell del dispositivo quando entrambi i contenitori eseguono la simulazione n-body. Di seguito è riportato un esempio di output. Esistono tre processi, il
nvidia-cuda-mps-serverprocesso (tipo C) corrisponde al servizio MPS e i/tmp/nbodyprocessi (tipo M + C) corrispondono ai carichi di lavoro n-body distribuiti dai moduli.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi