Installare le dipendenze del notebook
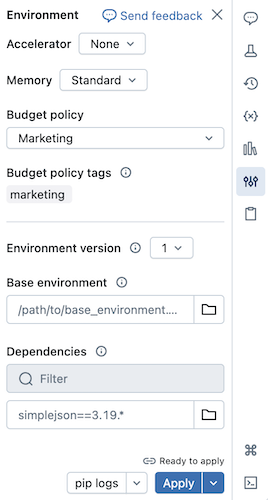
È possibile installare le dipendenze Python per i notebook serverless usando il pannello laterale Ambiente . Questo pannello offre un'unica posizione in cui modificare, visualizzare ed esportare i requisiti della libreria di un notebook. Queste dipendenze possono essere aggiunte usando un ambiente di base o singolarmente.
Per le attività non notebook, vedere Configurare ambienti e dipendenze per attività non notebook.
Importante
Non installare PySpark o qualsiasi libreria che installa PySpark come dipendenza dai notebook serverless. In questo modo la sessione verrà interrotta e verrà generato un errore. In questo caso, reimpostare l'ambiente.
Configurare un ambiente di base
Un ambiente di base è un file YAML archiviato come file dell'area di lavoro o in un volume di Catalogo Unity che specifica dipendenze di ambiente aggiuntive. Gli ambienti di base possono essere condivisi tra notebook. Per configurare un ambiente di base:
Creare un file YAML che definisce le impostazioni per un ambiente virtuale Python. L'esempio YAML seguente, basato sulla specifica dell'ambiente dei progetti MLflow, definisce un ambiente di base con alcune dipendenze della libreria:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - my-library==6.1 - "/Workspace/Shared/Path/To/simplejson-3.19.3-py3-none-any.whl" - git+https://github.com/databricks/databricks-cliCaricare il file YAML come file dell'area di lavoro o in un volume del catalogo Unity. Vedere Importare un file o Caricare file in un volume del catalogo Unity.
A destra del notebook fare clic sul
 pulsante per espandere il pannello Ambiente . Questo pulsante viene visualizzato solo quando un notebook è connesso al calcolo serverless.
pulsante per espandere il pannello Ambiente . Questo pulsante viene visualizzato solo quando un notebook è connesso al calcolo serverless.Nel campo Ambiente di base immettere il percorso del file YAML caricato o selezionarlo e selezionarlo.
Fare clic su Applica. In questo modo vengono installate le dipendenze nell'ambiente virtuale del notebook e viene riavviato il processo Python.
Gli utenti possono eseguire l'override delle dipendenze specificate nell'ambiente di base installando singolarmente le dipendenze.
Configurare l'ambiente notebook
È anche possibile installare le dipendenze in un notebook connesso al calcolo serverless usando la scheda Dipendenze del pannello Ambiente :
- A destra del notebook fare clic sul pulsante per espandere il pannello Ambiente . Questo pulsante viene visualizzato solo quando un notebook è connesso al calcolo serverless.
- Selezionare l'immagine client dall'elenco a discesa Versione client. Vedere Immagini client serverless. Databricks consiglia di scegliere la versione più recente per ottenere le funzionalità del notebook più aggiornate.
- Nella sezione Dipendenze fare clic su Aggiungi dipendenza e immettere il percorso della dipendenza della libreria nel campo . È possibile specificare una dipendenza in qualsiasi formato valido in un file di requirements.txt .
- Fare clic su Applica. In questo modo vengono installate le dipendenze nell'ambiente virtuale del notebook e viene riavviato il processo Python.
Nota
Un processo che usa il calcolo serverless installerà la specifica dell'ambiente del notebook prima di eseguire il codice del notebook. Ciò significa che non è necessario aggiungere dipendenze durante la pianificazione dei notebook come processi. Vedere Configurare ambienti e dipendenze.
Visualizzare le dipendenze installate e i log pip
Per visualizzare le dipendenze installate, fare clic su Installato nel pannello laterale Ambienti per un notebook. I log di installazione pip per l'ambiente notebook sono disponibili anche facendo clic su Pip logs (Log pip) nella parte inferiore del pannello.
Reimpostare l'ambiente
Se il notebook è connesso al calcolo serverless, Databricks memorizza automaticamente nella cache il contenuto dell'ambiente virtuale del notebook. Ciò significa che in genere non è necessario reinstallare le dipendenze Python specificate nel pannello Ambiente quando si apre un notebook esistente, anche se è stato disconnesso a causa dell'inattività.
La memorizzazione nella cache dell'ambiente virtuale Python si applica anche ai processi. Ciò significa che le esecuzioni successive dei processi sono più veloci in quanto le dipendenze necessarie sono già disponibili.
Nota
Se si modifica l'implementazione di un pacchetto Python personalizzato usato in un processo in serverless, è necessario aggiornarne anche il numero di versione in modo che i processi possano selezionare l'implementazione più recente.
Per cancellare la cache dell'ambiente ed eseguire una nuova installazione delle dipendenze specificate nel pannello Ambiente di un notebook collegato al calcolo serverless, fare clic sulla freccia accanto a Applica e quindi fare clic su Reimposta ambiente.
Nota
Reimpostare l'ambiente virtuale se si installano pacchetti che interrompono o modificano il notebook principale o l'ambiente Apache Spark. Scollegare il notebook dal calcolo serverless e ricollegarlo non cancella necessariamente l'intera cache dell'ambiente.
Configurare ambienti e dipendenze per attività non notebook
Per altri tipi di attività supportati, ad esempio script Python, rotellina Python o attività dbt, un ambiente predefinito include librerie Python installate. Per visualizzare l'elenco delle librerie installate, vedere la sezione Librerie Python installate della versione client in uso. Vedere Immagini client serverless. Se un'attività richiede una libreria Python non installata, è possibile installare la libreria da file dell'area di lavoro, volumi del catalogo Unity o repository di pacchetti pubblici. Per aggiungere una libreria quando si crea o si modifica un'attività:
Nel menu a discesa Ambiente e librerie fare clic
 accanto all'ambiente predefinito oppure fare clic su + Aggiungi nuovo ambiente.
accanto all'ambiente predefinito oppure fare clic su + Aggiungi nuovo ambiente.
Selezionare l'immagine client dall'elenco a discesa Versione client. Vedere Immagini client serverless. Databricks consiglia di scegliere la versione più recente per ottenere le funzionalità più aggiornate.
Nella finestra di dialogo Configura ambiente fare clic su + Aggiungi libreria.
Selezionare il tipo di dipendenza dal menu a discesa in Librerie.
Nella casella di testo Percorso file immettere il percorso della libreria.
Per una rotellina Python in un file dell'area di lavoro, il percorso deve essere assoluto e iniziare con
/Workspace/.Per una rotellina Python in un volume del catalogo Unity, il percorso deve essere
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.Per un
requirements.txtfile, selezionare PyPi e immettere-r /path/to/requirements.txt.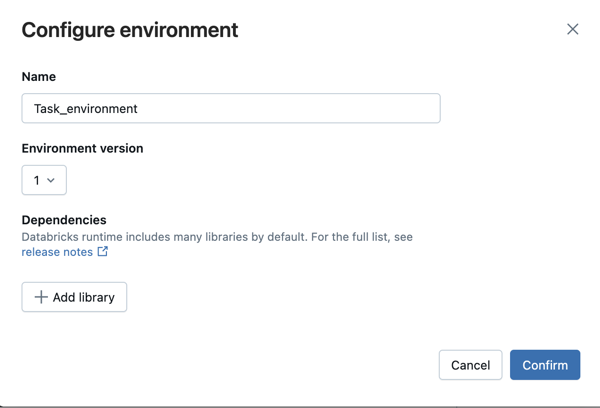
- Fare clic su Conferma o + Aggiungi libreria per aggiungere un'altra raccolta.
- Se si sta aggiungendo un task, cliccare Crea task. Se si sta modificando un task, cliccare Salva task.
Configurare i repository di pacchetti Python predefiniti
Importante
Questa funzionalità è in Public Preview.
Gli amministratori possono configurare repository di pacchetti privati o autenticati all'interno di aree di lavoro come configurazione pip predefinita per notebook serverless e processi serverless. In questo modo gli utenti possono installare pacchetti da repository Python interni senza definire in modo esplicito index-url o extra-index-url. Tuttavia, se questi valori vengono specificati nel codice o in un notebook, hanno la precedenza sulle impostazioni predefinite dell'area di lavoro.
Questa configurazione sfrutta segreti di Databricks per archiviare e gestire in modo sicuro GLI URL e le credenziali del repository. Gli amministratori possono configurare l'installazione utilizzando un ambito segreto predefinito e i comandi segreti della CLI di Databricks o l'API REST .
Per configurare i repository di pacchetti Python predefiniti, creare un ambito segreto predefinito e configurare le autorizzazioni di accesso, quindi aggiungere i segreti del repository di pacchetti.
Nome dell'ambito del segreto predefinito
Gli amministratori dell'area di lavoro possono impostare URL di indice PIP predefiniti o URL di indice aggiuntivi insieme ai token di autenticazione e ai segreti in un ambito segreto designato in chiavi predefinite:
- Nome dell'ambito segreto:
databricks-package-management - Chiave segreta per index-url:
pip-index-url - Chiave segreta per URL extra-indice:
pip-extra-index-urls - Chiave privata per il contenuto della certificazione SSL:
pip-cert
Creare l'ambito segreto
È possibile creare un ambito di segreti usando i comandi segreti della CLI di Databricks o l'API REST . Dopo aver creato l'ambito segreto, configurare gli elenchi di controllo di accesso per concedere a tutti gli utenti dell'area di lavoro l'accesso in lettura. In questo modo il repository rimane sicuro e non può essere modificato dai singoli utenti.
databricks secrets create-scope databricks-package-management
databricks secrets put-acl databricks-package-management admins MANAGE
databricks secrets put-acl databricks-package-management users READ
Aggiungi i segreti del repository dei pacchetti Python
Aggiungi i dettagli del repository dei pacchetti Python usando i nomi delle chiavi segrete predefinite.
# Add index URL.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-index-url", "string_value":"<index-url-value>"}'
# Add extra index URLs. If you have multiple extra index URLs, separate them using white space.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-extra-index-urls", "string_value":"<extra-index-url-1 extra-index-url-2>"}'
# Add cert content. If you want to pip configure a custom SSL certificate, put the cert file content here.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-cert", "string_value":"<cert-content>"}'
Modificare o eliminare segreti del repository PyPI privato
Per modificare i segreti del repository PyPI, usare il comando put-secret. Per eliminare i segreti del repository PyPI, usare delete-secret come illustrato di seguito:
# delete secret
databricks secrets delete-secret databricks-package-management pip-index-url
databricks secrets delete-secret databricks-package-management pip-extra-index-urls
databricks secrets delete-secret databricks-package-management pip-cert
# delete scope
databricks secrets delete-scope databricks-package-management
Nota
Le modifiche o le eliminazioni ai segreti vengono applicate dopo che un utente ricollega le risorse di calcolo serverless ai notebook o esegue nuovamente i processi serverless.