Acquisire e visualizzare la derivazione dei dati con Unity Catalog
Questo articolo descrive come acquisire e visualizzare la derivazione dei dati usando esplora Catalog, il sistema di derivazione dei dati tablese l'API REST.
È possibile usare Unity Catalog per acquisire la derivazione dei dati di runtime tra query eseguite in Azure Databricks. La derivazione è supportata per tutte le lingue e viene acquisita fino al livello di column. I dati di derivazione includono notebook, processi e dashboard correlati alla query. La derivazione può essere visualizzata in Catalog Explorer quasi in tempo reale e recuperata a livello di codice usando il sistema di derivazione tables e l'API REST di Databricks.
La lineage dei dati viene aggregata in tutti gli spazi di lavoro collegati a un metastore Catalog Unity. Ciò significa che la derivazione acquisita in un'area di lavoro è visibile in qualsiasi altra area di lavoro che shares tale metastore. In particolare, tables e altri oggetti dati registrati nel metastore sono visibili agli utenti che hanno almeno l'autorizzazione BROWSE per tali oggetti, in tutte le aree di lavoro collegate al metastore. Tuttavia, vengono mascherate informazioni dettagliate sugli oggetti a livello di area di lavoro, come notebook e dashboard in altre aree di lavoro (vedere Limitazioni e autorizzazioni di tracciabilità).
I dati di derivazione vengono conservati per un anno.
La seguente immagine seguente è un grafico di derivazione di esempio. Le funzionalità e gli esempi specifici di derivazione dei dati vengono trattati più avanti in questo articolo.
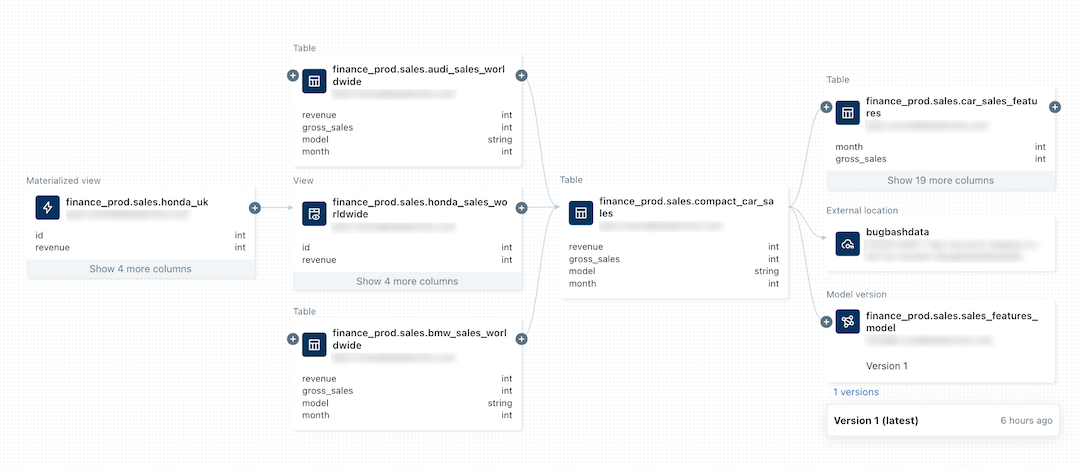
Per informazioni sul rilevamento della derivazione di un modello di Machine Learning, vedere Tenere traccia della derivazione dei dati di un modello in Unity Catalog.
Requisiti
Per acquisire la tracciabilità dei dati tramite Unity Catalog, sono necessari i seguenti elementi:
L'area di lavoro deve avere Unity Catalog abilitato.
Tables deve essere registrato in un metastore Catalog Unity.
Le query devono usare il dataframe Spark (ad esempio, le funzioni SPARK SQL che restituiscono un dataframe) o le interfacce SQL di Databricks. Per esempi di query SQL e PySpark di Databricks, vedere Esempi.
Per visualizzare la provenienza di un table o di una vista, gli utenti devono avere almeno il privilegio
BROWSEsul catalog principale del table o della vista. Il catalog padre deve essere accessibile anche dall'area di lavoro. Vedere Limitcatalog l'accesso a aree di lavoro specifiche.Per visualizzare le informazioni sulla derivazione per notebook, processi o dashboard, gli utenti devono disporre delle autorizzazioni per questi oggetti, come definito dalle impostazioni di controllo di accesso nell'area di lavoro. Vedere Autorizzazioni di derivazione.
Per visualizzare la derivazione per una pipeline abilitata per Unity -Catalog, è necessario disporre delle autorizzazioni
CAN_VIEWper la pipeline.Il tracciamento della provenienza dello streaming tra Delta tables richiede Databricks Runtime 11.3 LTS o una versione successiva.
Column il rilevamento della derivazione per i carichi di lavoro Delta Live Tables richiede Databricks Runtime 13.3 LTS o versione successiva.
Potrebbe essere necessario update regole del firewall in uscita per consentire la connettività all'endpoint di Hub eventi nel piano di controllo di Azure Databricks. In genere questo vale se l'area di lavoro di Azure Databricks viene implementata nella propria rete virtuale (nota anche come inserimento reti virtuali). Per get l'endpoint di Hub eventi per l'area di lavoro, vedere Metastore, l'archiviazione BLOB degli artefatti, l'archiviazione tables di sistema, l'archiviazione BLOB di log e gli indirizzi IP degli endpoint di Hub eventi. Per informazioni sulla configurazione di percorsi definiti dall'utente per Azure Databricks, vedere Impostazioni di percorsi definiti dall'utente per Azure Databricks.
Esempi:
Nota
Gli esempi seguenti usano il nome catalog
lineage_datae il nome schemalineagedemo. Per usare un catalog e un schemadiversi, modificare i nomi usati negli esempi.Per completare questo esempio, è necessario disporre dei privilegi
CREATEeUSE SCHEMAsu un schema. Un amministratore del metastore, catalog proprietario, schema proprietario o utente con il privilegio diMANAGEsul schema può grant questi privilegi. Ad esempio, per concedere a tutti gli utenti nel gruppo 'data_engineers' l'autorizzazione per creare tables nellineagedemoschema nellalineage_datacatalog, un utente con uno dei privilegi o ruoli precedenti può eseguire le query seguenti:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
Acquisire ed esplorare la derivazione
Per acquisire dati di derivazione:
Passare alla pagina di destinazione di Azure Databricks, fare clic su
 Nuovo nella barra laterale e selectnotebook dal menu.
Nuovo nella barra laterale e selectnotebook dal menu.Immettere un nome per il notebook e selectSQL in Lingua Predefinita.
In Cluster, select, un cluster con accesso a Unity Catalog.
Cliccare su Crea.
Nella prima cella del notebook immettere le seguenti query:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menuPer eseguire le query, fare clic nella cella e premere MAIUSC+INVIO oppure fare clic su
 e selectEsegui cella.
e selectEsegui cella.
Per usare Catalog Explorer per visualizzare la derivazione generata da queste query:
Nella casella ricerca
nella barra superiore dell'area di lavoro di Azure Databricks cercare il e . Select la scheda Lineage . Viene visualizzato il pannello di derivazione e viene visualizzato il tables correlato (per questo esempio è il
menutable).Per visualizzare un grafico interattivo della derivazione dei dati, fare clic su Visualizza grafico di derivazione. Per impostazione predefinita, nel grafico viene visualizzato un livello. Fare clic sull'icona
 su un nodo per visualizzare altri connections, se disponibili.
su un nodo per visualizzare altri connections, se disponibili.Fare clic su una freccia che connette i nodi nel grafico di derivazione per aprire il pannello Connessione derivazione. Il pannello linea di derivazione mostra i dettagli sulla connessione, tra cui origine e destinazione tables, notebook e attività.
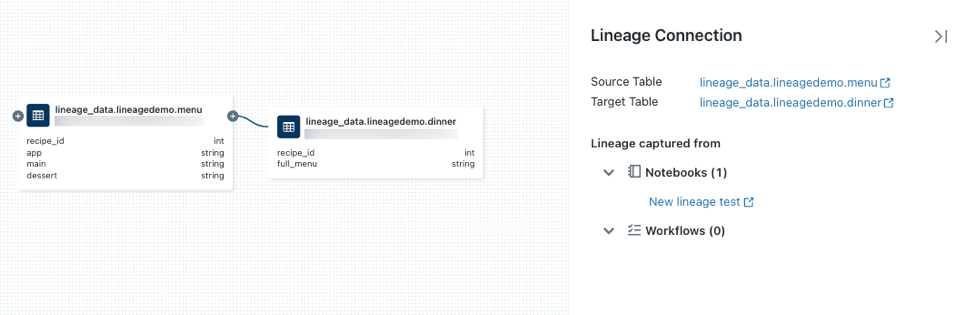
Per visualizzare il notebook associato al
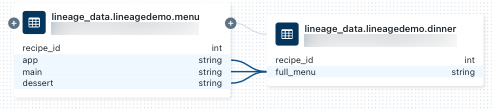
, il notebook nel pannello connessione derivazione o chiudere il grafico di derivazione e fare clic su Notebook . Per aprire il notebook in una nuova scheda, fare clic sul nome del notebook.Per visualizzare la derivazione a livello di column, fare clic su una column nel grafico per mostrare i collegamenti alle columnscorrelate. Ad esempio, facendo clic sul column 'full_menu' viene visualizzato il columns upstream da cui è stato derivato il column:
Per visualizzare la derivazione usando un linguaggio diverso, ad esempio Python:
Aprire il notebook creato in precedenza, creare una nuova cella e immettere il codice Python seguente:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")Eseguire la cella facendo clic nella cella e premendo MAIUSC+INVIO oppure facendo clic su
e selezionando Esegui cella.Nella casella di ricerca nella barra superiore dell'area di lavoro di Azure Databricks, cercare il
lineage_data.lineagedemo.pricetable e select.Andare alla scheda Derivazione e fare clic su Visualizza grafico di derivazione. Fare clic sulle icone
per esplorare la derivazione dei dati generata dalle query.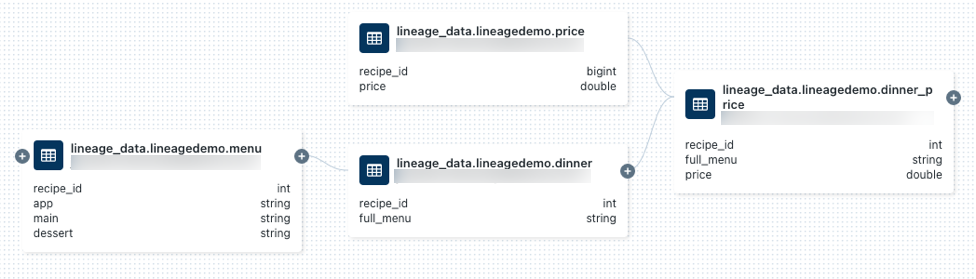
Fare clic su una freccia che connette i nodi nel grafico di derivazione per aprire il pannello Connessione derivazione. Il pannello connessione di linee di derivazione mostra i dettagli sulla connessione, tra cui l'origine e la destinazione tables, i notebook e i processi.
Acquisire e visualizzare la derivazione del flusso di lavoro
La derivazione viene acquisita anche per qualsiasi flusso di lavoro che legge o scrive in Unity Catalog. Per visualizzare la derivazione per un flusso di lavoro di Azure Databricks:
Fare clic su
Nuovo sulla barra laterale e selectNotebook dal menu.Immettere un nome per il notebook e selectSQL nella lingua predefinita .
Cliccare su Crea.
Nella prima cella del notebook immettere la seguente query:
SELECT * FROM lineage_data.lineagedemo.menuFare clic su Pianifica nella barra superiore. Nella finestra di dialogo di pianificazione selectManuale, seleziona select un cluster con accesso a Unity Cataloge fai clic su Crea.
Cliccare Run now (Esegui adesso).
Nella casella ricerca
nella barra superiore dell'area di lavoro di Azure Databricks cercare il e . Nella scheda
derivazione fare clic su flussi di lavoroe scheda downstream . Il nome del processo viene visualizzato in nome processo come consumer del.
Acquisire e visualizzare la derivazione del dashboard
Per creare un dashboard e visualizzarne la derivazione dei dati:
Vai alla pagina di destinazione di Azure Databricks e apri Esplora Catalog facendo clic su Catalog nella barra laterale.
Fare clic sul nome catalog, fare clic su lineagedemoe select il
menutable. È anche possibile usare la casella ricercanella barra superiore per cercare il . Fare clic su Apri in un dashboard.
Select il columns da aggiungere al dashboard e fare clic su Crea.
Pubblicare il dashboard.
Solo i dashboard pubblicati vengono rilevati nella derivazione dei dati.
Nella casella cerca
nella barra superiore cercare il e . Nella scheda Derivazione fare clic su Dashboard. Il dashboard appare in Nome Dashboard come utente del menu table.
Autorizzazioni di derivazione.
I grafici di lineage condividono lo stesso modello di autorizzazione di Unity Catalog.
Tables e altri oggetti dati registrati nel metastore Catalog Unity sono visibili solo agli utenti che dispongono di almeno le autorizzazioni BROWSE per quegli oggetti. Se un utente non dispone del privilegio BROWSE o SELECT per un table, non può esplorarne la provenienza. I grafici di derivazione visualizzano Unity Catalog oggetti in tutte le aree di lavoro collegate al metastore, purché l'utente disponga di autorizzazioni adeguate sugli oggetti.
Ad esempio, eseguire i comandi seguenti per userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Quando userAviews il grafico di derivazione per l'lineage_data.lineagedemo.menutable, vedranno il menutable. Non saranno in grado di visualizzare informazioni sulle tablesassociate, come ad esempio il lineage_data.lineagedemo.dinnertablea valle. Il dinnertable viene visualizzato come nodo masked nella visualizzazione a userA, e userA non è in grado di espandere il grafico per visualizzare tables a valle da tables a cui non ha il permesso di accedere.
Eseguendo il comando seguente per grant l'autorizzazione BROWSE a userB, quell'utente può visualizzare il grafico di derivazione per qualsiasi table nel lineage_dataschema.
GRANT BROWSE on lineage_data to `userB@company.com`;
Analogamente, gli utenti di derivazione devono disporre di autorizzazioni specifiche per visualizzare oggetti dell'area di lavoro come notebook, processi e dashboard. Inoltre, possono visualizzare solo informazioni dettagliate sugli oggetti dell'area di lavoro quando vengono connessi all'area di lavoro in cui sono stati creati tali oggetti. Le informazioni dettagliate sugli oggetti a livello di area di lavoro in altre aree di lavoro sono mascherate nel grafico di derivazione.
Per ulteriori informazioni sulla gestione dell'accesso a oggetti protetti in Unity Catalog, consultare Gestione dei privilegi in Unity Catalog. Per altre informazioni sulla gestione dell'accesso agli oggetti dell'area di lavoro, ad esempio notebook, processi e dashboard, si veda Elenchi di controllo di accesso.
Eliminare i dati di derivazione
Avviso
Le istruzioni seguenti eliminano tutti gli oggetti archiviati in Unity Catalog. Seguire queste istruzioni solo se necessario. Ad esempio, per soddisfare i requisiti di conformità.
Per eliminare i dati di derivazione, è necessario eliminare il metastore che gestisce gli oggetti Catalog Unity. Per altre informazioni sull'eliminazione del metastore, vedere Eliminare un metastore. I dati verranno eliminati entro 90 giorni.
Eseguire query sui dati di derivazione usando il sistema tables
È possibile usare il sistema di derivazione tables per eseguire query sui dati di derivazione a livello di codice. Per istruzioni dettagliate, vedere Monitorare l'attività dell'account con il sistema tables e il sistema Lineage riferimento tables.
Se l'area di lavoro si trova in un'area che non supporta il sistema di derivazione tables, in alternativa è possibile usare l'API REST Derivazione dati per recuperare i dati di derivazione a livello di codice.
Recuperare la derivazione usando l'API REST Derivazione dei dati
L'API di tracciabilità dei dati consente di recuperare la tracciabilità di table e column. Tuttavia, se l'area di lavoro si trova in un'area che supporta il sistema di derivazione tables, è consigliabile usare query di sistema table anziché l'API REST. Il Sistema tables è un'opzione migliore per il recupero programmatico dei dati di lineage. La maggior parte delle aree supporta il sistema di derivazione tables.
Importante
Per accedere alle API REST di Databricks, è necessario eseguire l'autenticazione.
Recuperare table derivazione
In questo esempio vengono recuperati i dati di derivazione per il dinnertable.
Richiedi
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Sostituire <workspace-instance>.
In questo esempio viene usato un file .netrc.
Response
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Recuperare linea column
In questo esempio si recuperano i dati column per l'dinnertable.
Richiedi
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Sostituire <workspace-instance>.
In questo esempio viene usato un file .netrc.
Response
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Limiti
Sebbene il lineage sia aggregato per tutte le aree di lavoro collegate allo stesso metastore di Unity Catalog, i dettagli degli oggetti dell'area di lavoro, come notebook e dashboard, sono visibili solo nell'area di lavoro in cui sono stati creati.
Poiché la derivazione viene calcolata in un windowin sequenza di un anno, la derivazione raccolta più di un anno fa non viene visualizzata. Ad esempio, se un lavoro o una query legge i dati da table A e scrive in table B, il collegamento tra table A e table B viene visualizzato solo per un anno. È possibile filtrare i dati di derivazione in base all'intervallo di tempo entro l'windowdi un anno.
I processi che usano la richiesta dell'API Processi
runs submitnon sono disponibili durante la visualizzazione della derivazione. La derivazione a livello Table e column viene ancora acquisita quando si utilizza la richiestaruns submit, ma il collegamento al processo di esecuzione non viene acquisito.Unity Catalog acquisisce il lineaggio fino al livello column il più possibile. Tuttavia, esistono alcuni casi in cui non è possibile catturare la derivazione a livello wherecolumn.
Column derivazione è supportata solo quando viene fatto riferimento sia all'origine che alla destinazione in base al nome table (esempio:
select * from <catalog>.<schema>.<table>). Column lineage non può essere acquisito se l'origine o la destinazione è individuata tramite il percorso (ad esempio:select * from delta."s3://<bucket>/<path>").Se viene rinominata una table o una vista, la derivazione non viene acquisita per la table o la vista rinominata.
Se un schema o un catalog viene rinominato, la derivazione non viene acquisita per tables e views sotto il catalog o schemarinominato.
Se si usa il checkpoint del set di dati Spark SQL, la derivazione non viene acquisita.
Unity Catalog rileva la derivazione dalle pipeline di Delta Live Tables nella maggior parte dei casi. In alcuni casi, tuttavia, non si può garantire una copertura di tracciamento completa, ad esempio quando le pipeline usano l'API APPLY CHANGES
o TEMPORARY .La derivazione non acquisisce le funzioni stack.
Le variabili temporanee globali views non vengono tracciate nell'eredità.
Tables in
system.information_schemanon vengono acquisiti in derivazione.La derivazione completa a livello di columnnon viene acquisita per impostazione predefinita per le operazioni di
MERGE.È possibile attivare l'acquisizione della derivazione per
MERGEle operazioni impostando la proprietàspark.databricks.dataLineage.mergeIntoV2EnabledSpark sutrue. L'abilitazione di questo flag può rallentare le prestazioni delle query, in particolare nei carichi di lavoro che coinvolgono un tablesmolto ampio.