CI/CD con Jenkins su Azure Databricks
Nota
Questo articolo tratta di Jenkins, che non è nè fornito né supportato da Databricks. Per contattare il provider, consultare la Guida a Jenkins.
Sono disponibili numerosi strumenti CI/CD che è possibile usare per la gestione ed esecuzione delle pipeline CI/CD. Questo articolo illustra come usare il server di automazione Jenkins. CI/CD è un schema progettuale, quindi i passaggi e le fasi descritti in questo articolo devono essere trasferiti con alcune modifiche al linguaggio di definizione della pipeline in ogni strumento. Inoltre, gran parte del codice in questa pipeline di esempio esegue codice Python standard, che è possibile richiamare in altri strumenti. Per una panoramica di CI/CD su Azure Databricks, consultare Che cos'è CI/CD su Azure Databricks?.
Per informazioni su come usare Azure DevOps con Azure Databricks, consultare Integrazione e recapito continuo su Azure Databricks usando Azure DevOps.
Flusso di lavoro di sviluppo CI/CD
Per lo sviluppo CI/CD con Jenkins, Databricks suggerisce il seguente flusso di lavoro:
- Creare un repository o usare un repository esistente con il provider Git di terze parti.
- Connettere il computer di sviluppo locale allo stesso repository di terze parti. Per istruzioni, consultare la documentazione del provider Git di terze parti.
- Eseguire il pull di tutti gli artefatti aggiornati esistenti, (come i notebook, file di codice e script di compilazione), dal repository di terze parti nel computer di sviluppo locale.
- Creare, aggiornare e testare gli artefatti nel computer di sviluppo locale come desiderato. Eseguire quindi il push di tutti gli artefatti nuovi e modificati dal computer di sviluppo locale nel repository di terze parti. Per istruzioni, consultare la documentazione del provider Git di terze parti.
- Ripetere i passaggi 3 e 4 come necessario.
- Usare periodicamente Jenkins come approccio integrato per eseguire automaticamente il pull degli artefatti dal repository di terze parti nel computer di sviluppo locale o nell'area di lavoro di Azure Databricks; compilazione, test ed esecuzione di codice nel computer di sviluppo locale o nell'area di lavoro di Azure Databricks; e segnalare i risultati del test e dell'esecuzione. Anche se è possibile eseguire Jenkins manualmente, nelle implementazioni reali è consigliabile indicare al provider Git di terze parti di eseguire Jenkins ogni volta che si verifica un evento specifico, per esempio una richiesta pull del repository.
Il resto di questo articolo usa un progetto di esempio per descrivere un modo di usare Jenkins per implementare il flusso di lavoro di sviluppo CI/CD precedente.
Per informazioni su come usare Azure DevOps invece di Jenkins, consultare Integrazione e recapito continuo su Azure Databricks usando Azure DevOps.
Configurazione del computer di sviluppo locale
Questo esempio di articolo usa Jenkins per istruire il Databricks CLI e Databricks Asset Bundles a eseguire le seguenti operazioni:
- Creare un file wheel Python nel computer di sviluppo locale.
- Distribuire il file wheel Python compilato insieme ad altri file Python e notebook Python dal computer di sviluppo locale a un'area di lavoro di Azure Databricks.
- Testare ed eseguire il file wheel e i notebook Python caricati nell'area di lavoro.
Per configurare il computer di sviluppo locale per indicare all'area di lavoro di Azure Databricks di eseguire le fasi di compilazione e caricamento per questo esempio, eseguire le seguenti operazioni nel computer di sviluppo locale:
Passaggio 1: Installare gli strumenti necessari
In questo passaggio si installano il Databricks CLI, Jenkins, jq, e gli strumenti di built Python wheel nel computer di sviluppo locale. Questi strumenti sono necessari per eseguire questo esempio.
Se non è già stato fatto, installare Databricks CLI versione 0.205 o superiore. Jenkins usa il Databricks CLI per passare il test di questo esempio ed eseguire le istruzioni sull'area di lavoro. Consultare Installare o aggiornare il Databricks CLI.
Se non è già stato fatto, installare e avviare Jenkins. Consultare Installazione di Jenkins per Linux, macOS o Windows.
Installa jq. Questo esempio usa
jqper analizzare l'output di un comando in formato JSON.Usare
pipper installare gli strumenti build Python wheel con il seguente comando (alcuni sistemi potrebbero richiedere l'uso dipip3invece dipip):pip install --upgrade wheel
Passaggio 2: Creare una Pipeline Jenkins
In questo passaggio si usa Jenkins per creare una pipeline per l’esempio di questo articolo. Jenkins fornisce alcuni tipi di progetto diversi per creare pipeline CI/CD. Le Pipeline Jenkins forniscono un'interfaccia per definire le fasi in una pipeline usando il codice Groovy per chiamare e configurare i plug-in Jenkins.
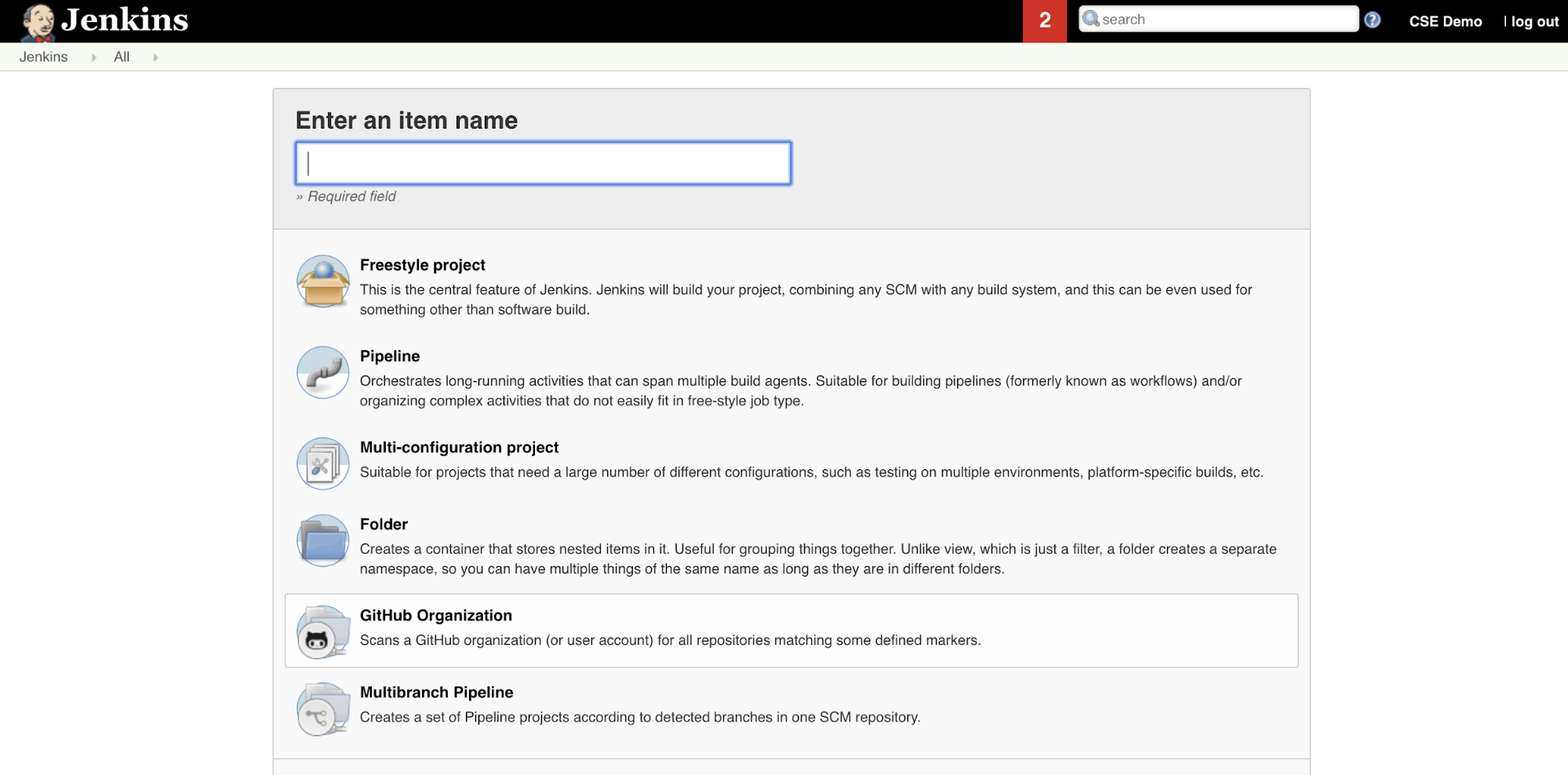
Per creare la Pipeline Jenkins all’interno di Jenkins:
- Dopo aver avviato Jenkins, dal Dashboard fare clic su Nuovo elemento.
- Per Immettere un nome digitarne uno per la Pipeline Jenkins, ad esempio
jenkins-demo. - Fare clic sull'icona del progetto Pipeline.
- Fare clic su OK. Viene visualizzata la pagina Configura della Pipeline Jenkins.
- Nell'area Pipeline, nell’elenco a discesa Definizione selezionare Script pipeline da SCM.
- Nell'elenco a discesa SCM selezionare Git.
- Per gli URL del repository digitare l'URL del repository ospitato dal provider Git di terze parti.
- Per l’identificatore di ramo digitare
*/<branch-name>, dove<branch-name>è il nome del ramo nel repository che si vuole usare, ad esempio*/main. - Se non è già impostato, peril percorso dello script digitare
Jenkinsfile.Jenkinsfileverrà creato più avanti in questo articolo. - Deselezionare la casella denominata Lightweight checkout, se è già selezionata.
- Fare clic su Salva.
Passaggio 3: Aggiungere variabili d’ambiente globali a Jenkins
In questo passaggio si aggiungono tre variabili d’ambiente globali a Jenkins. Jenkins passa queste variabili d’ambiente al Databricks CLI. Il Databricks CLI richiede i valori per queste variabili d’ambiente per l'autenticazione con l'area di lavoro di Azure Databricks. Questo esempio usa l'autenticazione da computer a computer (M2M) OAuth per un'entità servizio (anche se sono disponibili anche altri tipi di autenticazione). Per configurare l'autenticazione OAuth M2M per l'area di lavoro di Azure Databricks, consultare Autenticare l'accesso ad Azure Databricks con un'entità servizio usando OAuth (OAuth M2M).
Le tre variabili di ambiente globali per questo esempio sono:
DATABRICKS_HOST, impostare l'URL dell'area di lavoro di Azure Databricks, a partire dahttps://. Consultare URL, ID e nomi di istanza dell'area di lavoro.DATABRICKS_CLIENT_ID, impostato sul client ID dell'entità servizio, noto anche come ID dell'applicazione.DATABRICKS_CLIENT_SECRET, impostato sul segreto OAuth dell'entità servizio di Azure Databricks.
Per impostare le variabili d’ambiente globali in Jenkins, dal Dashboard di Jenkins:
- Nella barra laterale, fare clic su Gestisci Jenkins.
- Nella sezione Configurazione di sistema fare clic su Sistema.
- Nella sezione Proprietà globali selezionare la casella Variabili d’ambiente.
- Fare clic su Aggiungi e quindi immettere il nome e il valore della variabile d’ambiente. Ripetere questa operazione per ogni variabile d’ambiente aggiuntiva.
- Al termine dell'aggiunta di variabili d’ambiente, per tornare al Dashboard di Jenkins fare clic su Salva.
Progettare la Pipeline Jenkins
Jenkins fornisce alcuni tipi di progetto diversi per creare pipeline CI/CD. Questo esempio implementa una Pipeline Jenkins. Le Pipeline Jenkins forniscono un'interfaccia per definire le fasi in una pipeline usando il codice Groovy per chiamare e configurare i plug-in Jenkins.
Si scrive una definizione della Pipeline Jenkins in un file di testo denominato Jenkinsfile, che a sua volta viene archiviata nel repository del controllo del codice sorgente di un progetto. Per altre informazioni, consultare Pipeline Jenkins. Di seguito è riportato l'esempio di Pipeline Jenkins per questo articolo. Nell’esempio Jenkinsfile, sostituire i seguenti valori segnaposto:
- Sostituire
<user-name>e<repo-name>con il nome utente e il nome del repository per l'ospitato dal provider Git di terze parti. Questo articolo usa un URL di GitHub come esempio. - Sostituire
<release-branch-name>con il nome del ramo di versione nel repository. Ad esempio, potrebbe esseremain. - Sostituire
<databricks-cli-installation-path>con il percorso nel computer di sviluppo locale in cui è installato il Databricks CLI. Ad esempio, su macOS potrebbe essere/usr/local/bin. - Sostituire
<jq-installation-path>con il percorso nel computer di sviluppo locale in cui èjqinstallato. Ad esempio, su macOS potrebbe essere/usr/local/bin. - Sostituire
<job-prefix-name>con una stringa per identificare in modo univoco i processi di Azure Databricks creati nell'area di lavoro per questo esempio. Ad esempio, potrebbe esserejenkins-demo. - Si noti che
BUNDLETARGETè impostato sudev, ovvero il nome della destinazione del Databricks Asset Bundle definita più avanti in questo articolo. Nelle implementazioni reali, si cambierà il nome con quello del proprio obiettivo di bundle. Più avanti, nell’articolo, verranno forniti altri dettagli sugli obiettivi dei bundle.
Di seguito è riportato il Jenkinsfile, che deve essere aggiunto alla radice del repository:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
La parte restante di questo articolo descrive ogni fase di questa Pipeline Jenkins e come configurare gli artefatti e i comandi che Jenkins deve eseguire in tale fase.
Eseguire il pull degli elementi più recenti dal repository di terze parti
La prima fase di questa Pipeline Jenkins, la Checkout fase, è definita come segue:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Questa fase assicura che la directory di lavoro usata da Jenkins nel computer di sviluppo locale disponga degli elementi più recenti del repository Git di terze parti. In genere, Jenkins imposta questa directory di lavoro su <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. In questo modo è possibile usare lo stesso computer di sviluppo locale per mantenere la propria copia degli artefatti in sviluppo separati dagli artefatti usati da Jenkins dal repository Git di terze parti.
Convalidare il Databricks Asset Bundle
La seconda fase di questa Pipeline Jenkins, la Validate Bundle fase, è definita come segue:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Questa fase assicura che il Databricks Asset Bundle, che definisce i flussi di lavoro per il test e l'esecuzione degli artefatti, sia sintatticamente corretto. I Databricks Asset Bundle, noti semplicemente come bundle, consentono di esprimere i progetti di machine learning, analisi e dati completi come raccolta di file di origine. Consultare Che cosa sono i Databricks Asset Bundle?.
Per definire il bundle per questo articolo, creare un file denominato databricks.yml nella radice del repository clonato nel computer locale. In questo file di esempio databricks.yml, sostituire i segnaposto seguenti:
- Sostituire
<bundle-name>con un nome programmatico univoco per il bundle. Ad esempio, potrebbe esserejenkins-demo. - Sostituire
<job-prefix-name>con una stringa per identificare in modo univoco i processi di Azure Databricks creati nell'area di lavoro per questo esempio. Ad esempio, potrebbe esserejenkins-demo. Deve corrispondere alJOBPREFIXvalore nel Jenkinsfile. - Sostituire
<spark-version-id>con l'ID della versione del Databricks Runtime per i tuoi cluster di lavoro, ad esempio13.3.x-scala2.12. - Sostituire
<cluster-node-type-id>con l'ID del tipo di nodo per i tuoi cluster di lavoro, ad esempioStandard_DS3_v2. - Si noti che
devnel mappingtargetsè uguale aBUNDLETARGETin Jenkinsfile. Un obiettivo di bundle specifica l'host e i comportamenti di distribuzione correlati.
Di seguito è riportato il databricks.yml file che deve essere aggiunto alla radice del repository per il corretto funzionamento di questo esempio:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Per altre informazioni sul databricks.yml file, consultare Configurazione dei Databricks Asset Bundle.
Distribuire il bundle nell'area di lavoro
La terza fase della Pipeline di Jenkins, denominata Deploy Bundle, è definita come segue:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Questa fase si occupa di due cose:
- Poiché il
artifactmapping neldatabricks.ymlfile è impostato suwhl, indica al Databricks CLI di compilare il file wheel Python usando ilsetup.pyfile nel percorso specificato. - Dopo aver creato il file wheel Python nel computer di sviluppo locale, il Databricks CLI distribuisce il file wheel Python compilato insieme ai file e ai notebook Python specificati nell'area di lavoro di Azure Databricks. Per impostazione predefinita, i Databricks Asset Bundle distribuiscono il file wheel Python e altri file in
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Per consentire la compilazione del file wheel Python come specificato nel databricks.yml file, creare le cartelle e i file seguenti nella radice del repository clonato nel computer locale.
Per definire la logica e gli unit test per il file wheel Python in cui verrà eseguito il notebook, creare due file denominati addcol.py e test_addcol.py, e aggiungerli a una struttura di cartelle denominata python/dabdemo/dabdemo all'interno della cartella del Libraries repository, visualizzata come indicato di seguito (i puntini di sospensione indicano le cartelle omesse nel repository, per brevità):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Il addcol.py file contiene una funzione di libreria che verrà costruita in un secondo momento in un file wheel Python e quindi installata in un cluster Azure Databricks. Si tratta di una funzione semplice che aggiunge una nuova colonna, popolata da un valore letterale, a un DataFrame Apache Spark:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Il file test_addcol.py contiene test per passare un oggetto DataFrame fittizio alla funzione with_status, definito in addcol.py. Il risultato viene quindi confrontato con un oggetto DataFrame contenente i valori previsti. Se i valori corrispondono, come in questo caso, il test viene superato:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Per consentire all'interfaccia della riga di comando di Databricks di creare correttamente il pacchetto di questo codice di libreria in un file wheel Python, creare due file denominati __init__.py e __main__.py nella stessa cartella dei due file precedenti. Creare anche un file denominato setup.py nella cartella python/dabdemo, visualizzato come indicato di seguito (i puntini di sospensione indicano cartelle omesse, per brevità):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Il file __init__.py contiene il numero di versione e l'autore della libreria. Sostituire <my-author-name> con il proprio nome:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Il file __main__.py contiene il punto di ingresso della libreria:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Il file setup.py contiene impostazioni aggiuntive per la compilazione della libreria in un file wheel di Python. Sostituire <my-url>, <my-author-name>@<my-organization> e <my-package-description> con valori significativi:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Testare la logica dei componenti della wheel Python
La Run Unit Tests fase, la quarta di questa Pipeline Jenkins, usa pytest per testare la logica di una libreria per assicurarsi che funzioni come da built. La fase è definita come segue:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Questa fase usa il Databricks CLI per eseguire un processo notebook. Questo processo esegue il notebook Python con il nome del file run-unit-test.py. Questo notebook esegue pytest andando contro la logica della libreria.
Per eseguire gli unit test per questo esempio, aggiungere un file di notebook Python denominato run_unit_tests.py con il seguente contenuto alla radice del repository clonato nel computer locale:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Usare la wheel di Python creata
La quinta fase di questa Pipeline Jenkins, denominata Run Notebook, esegue un notebook Python che chiama la logica nel file wheel di Python creato, come segue:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Questa fase esegue il Databricks CLI, che a sua volta indica all'area di lavoro di eseguire un processo notebook. Questo notebook crea un oggetto DataFrame, lo passa alla funzione della with_status libreria, stampa il risultato e segnala i risultati dell'esecuzione del processo. Creare il notebook aggiungendo un file di notebook Python denominato dabdaddemo_notebook.py con il seguente contenuto nella radice del repository clonato nel computer di sviluppo locale:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Valutare i risultati dell'esecuzione del processo del notebook
La Evaluate Notebook Runs fase, la sesta di questa Pipeline Jenkins, valuta i risultati dell'esecuzione del processo notebook precedente. La fase è definita come segue:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Questa fase esegue il Databricks CLI, che a sua volta indica all'area di lavoro di eseguire un processo di file Python. Questo file Python determina l'errore e i criteri di esito positivo per l'esecuzione del processo del notebook e segnala il fallimento o il risultato positivo. Creare un file denominato evaluate_notebook_runs.py con il seguente contenuto nella radice del repository clonato nel computer di sviluppo locale:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importare e segnalare i risultati dei test
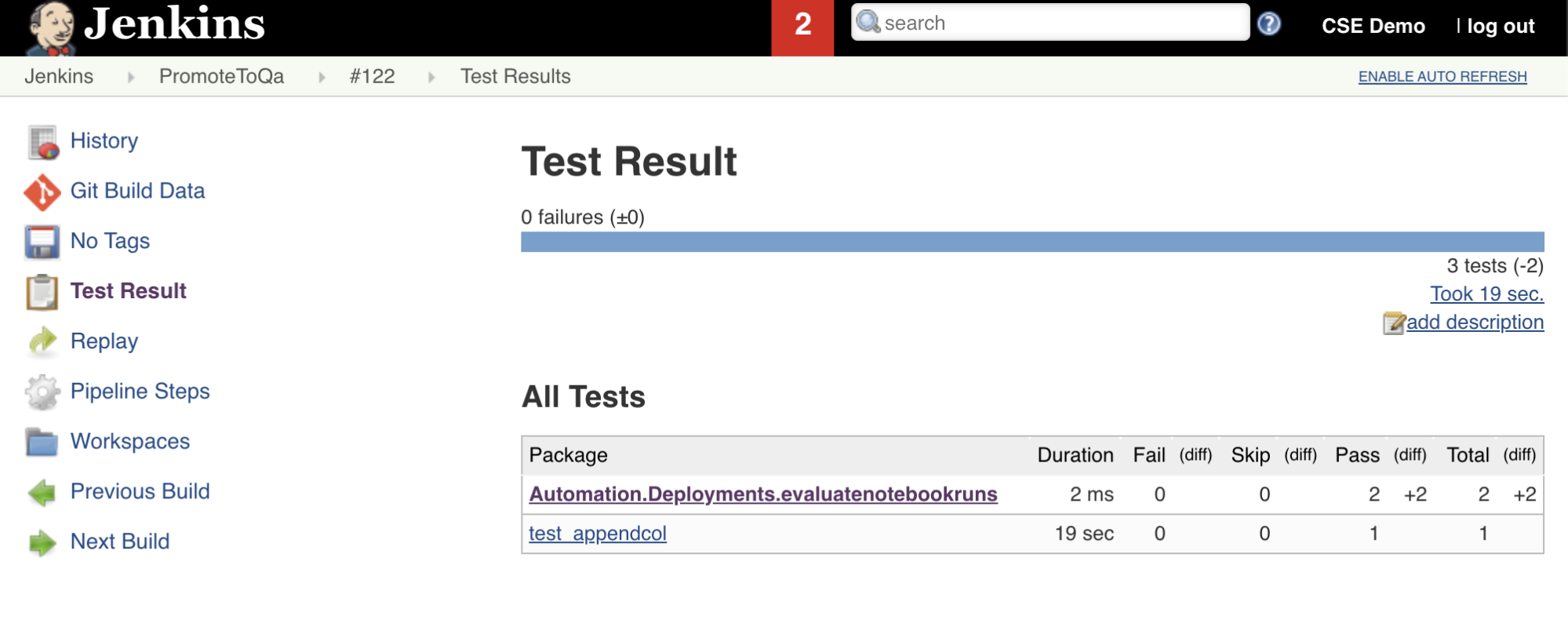
La settima fase della Pipeline Jenkins, denominata Import Test Results, usa il Databricks CLI per inviare i risultati dei test dall'area di lavoro al computer di sviluppo locale. L'ottava e ultima fase, intitolata Publish Test Results, pubblica i risultati del test in Jenkins usando il junit plug-in Jenkins. In questo modo è possibile visualizzare report e dashboard correlati allo stato dei risultati del test. Queste fasi sono definite come segue:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Eseguire il push di tutte le modifiche al codice nel repository di terze parti
È ora necessario eseguire il push del contenuto del repository clonato nel computer di sviluppo locale nel repository di terze parti. Prima di eseguire il push, è necessario aggiungere le seguenti voci al .gitignore file nel repository clonato, perché probabilmente non è consigliabile eseguire il push dei file di lavoro interni di Databricks Asset Bundle, dei report di convalida, dei file di compilazione Python e delle cache Python nel repository di terze parti. In genere, è consigliabile rigenerare i nuovi report di convalida e le build della wheel Python più recenti nell'area di lavoro di Azure Databricks, anziché usare report di convalida potenzialmente obsoleti e build wheel Python:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Eseguire la Pipeline Jenkins
È ora possibile eseguire manualmente la Pipeline Jenkins. A tale scopo, recarsi sul Dashboard di Jenkins:
- Fare clic sul nome della Pipeline Jenkins.
- Sulla barra laterale fare clic su Build Now.
- Per visualizzare i risultati, fare clic sull'ultima esecuzione della pipeline (ad esempio,
#1) e poi su Output della console.
A questo punto, la pipeline CI/CD ha completato un ciclo di integrazione e distribuzione. Automatizzando questo processo, è possibile assicurarsi che il codice sia stato testato e distribuito da un processo efficiente, coerente e ripetibile. Per indicare al provider Git di terze parti di eseguire Jenkins ogni volta che si verifica un evento specifico, ad esempio una richiesta pull del repository, consultare la documentazione del provider Git di terze parti.