Eseguire un file in un cluster o in un file o un notebook come processo in Azure Databricks usando l'estensione Databricks per Visual Studio Code
L'estensione Databricks per Visual Studio Code consente di eseguire il codice Python in un cluster o nel codice Python, R, Scala o SQL come processo in Azure Databricks.
Queste informazioni presuppongono che l'utente abbia già installato e set l'estensione Databricks per Visual Studio Code. Vedere Installare l'estensione Databricks per Visual Studio Code.
Nota
Per eseguire il debug di codice o notebook da Visual Studio Code, usare Databricks Connect. Vedere Eseguire il debug del codice usando Databricks Connect per l'estensione Databricks per Visual Studio Code ed eseguire ed eseguire il debug delle celle del notebook con Databricks Connect usando l'estensione Databricks per Visual Studio Code.
Eseguire un file Python in un cluster
Per eseguire un file Python in un cluster Azure Databricks usando l'estensione Databricks per Visual Studio Code, con l'estensione e il progetto aperto:
- Aprire il file Python da eseguire nel cluster.
- Eseguire una delle operazioni seguenti:
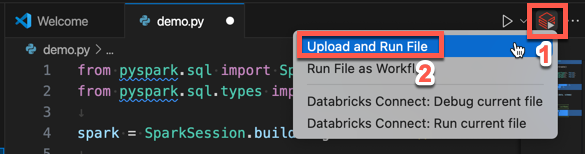
Nella barra del titolo dell'editor di file fare clic sull'icona Esegui in Databricks e quindi fare clic su Carica ed esegui file.
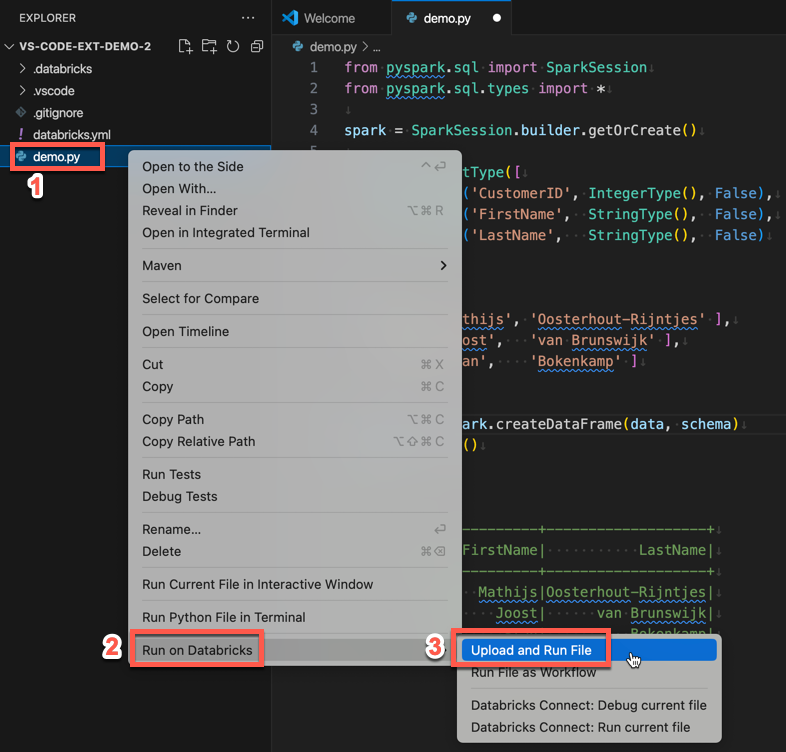
In vista Esplora (Visualizza > Explorer), fare clic con il pulsante destro del mouse sul file e quindi selectEsegui su Databricks>Carica ed Esegui File dal menu di scelta rapida.
Il file viene eseguito nel cluster e l'output è disponibile nella console di debug (Visualizza > console di debug).
Eseguire un file Python come processo
Per eseguire un file Python come processo di Azure Databricks usando l'estensione Databricks per Visual Studio Code, con l'estensione e il progetto aperto:
- Aprire il file Python da eseguire come processo.
- Eseguire una delle operazioni seguenti:
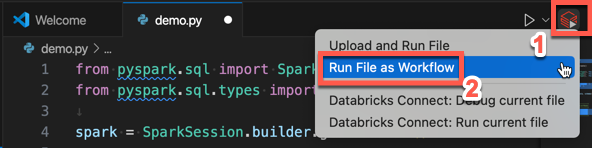
Nella barra del titolo dell'editor di file fare clic sull'icona Esegui in Databricks e quindi fare clic su Esegui file come flusso di lavoro.
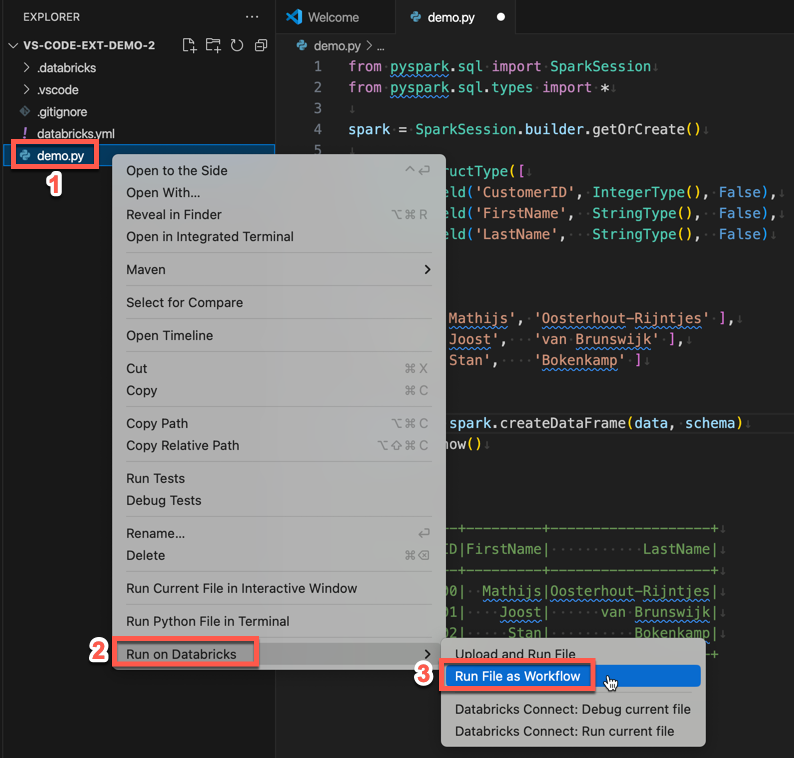
In Explorer view (View > Explorer), clicca con il tasto destro sul file e poi selectEsegui in Databricks>Esegui file come flusso di lavoro dal menu di scelta rapida.
Viene visualizzata una nuova scheda dell'editor denominata Databricks Job Run (Esecuzione processo Databricks). Il file viene eseguito come processo nell'area di lavoro e qualsiasi output viene stampato nell'area output della nuova scheda dell'editor.
Per visualizzare informazioni sull'esecuzione del processo, fare clic sul collegamento ID esecuzione attività nella nuova scheda Editor di esecuzione processo di Databricks. L'area di lavoro viene aperta e i dettagli dell'esecuzione del processo vengono visualizzati nell'area di lavoro.
Eseguire un notebook Python, R, Scala o SQL come processo
Per eseguire un notebook come processo di Azure Databricks usando l'estensione Databricks per Visual Studio Code, con l'estensione e il progetto aperto:
Aprire il notebook da eseguire come processo.
Suggerimento
Per trasformare un file Python, R, Scala o SQL in un notebook di Azure Databricks, aggiungere il commento
# Databricks notebook sourceall'inizio del file e aggiungere il commento# COMMAND ----------prima di ogni cella. Per altre informazioni, vedere Importare un file e convertirlo in un notebook.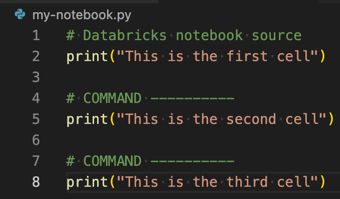
Esegui una delle operazioni seguenti:
- Nella barra del titolo dell'editor di file del notebook fare clic sull'icona Esegui in Databricks e quindi fare clic su Esegui file come flusso di lavoro.
Nota
Se l'esecuzione in Databricks come flusso di lavoro non è disponibile, vedere Creare una configurazione di esecuzione personalizzata.
- In visualizzazione (Visualizza > Explorer), fare clic con il pulsante destro del mouse sul file del notebook e quindi selectEsegui in Databricks>Esegui file come flusso di lavoro dal menu di scelta rapida.
Viene visualizzata una nuova scheda dell'editor denominata Databricks Job Run (Esecuzione processo Databricks). Il notebook viene eseguito come processo nell'area di lavoro. Il notebook e il relativo output vengono visualizzati nell'area Output della nuova scheda dell'editor.
Per visualizzare informazioni sull'esecuzione del processo, fare clic sul collegamento ID esecuzione attività nella scheda Editor esecuzione processo Databricks. L'area di lavoro viene aperta e i dettagli dell'esecuzione del processo vengono visualizzati nell'area di lavoro.
Creare una configurazione di esecuzione personalizzata
Una configurazione di esecuzione personalizzata per l'estensione Databricks per Visual Studio Code consente di passare argomenti personalizzati a un processo o a un notebook o di creare impostazioni di esecuzione diverse per file diversi.
Per creare una configurazione di esecuzione personalizzata, fare clic su Esegui > aggiungi configurazione dal menu principale in Visual Studio Code. Quindi selectDatabricks per una configurazione di esecuzione basata su cluster o Databricks: Workflow per una configurazione di esecuzione basata su attività.
Ad esempio, la configurazione di esecuzione personalizzata seguente modifica il comando Esegui file come flusso di lavoro per passare l'argomento --prod al processo:
{
"version": "0.2.0",
"configurations": [
{
"type": "databricks-workflow",
"request": "launch",
"name": "Run on Databricks as Workflow",
"program": "${file}",
"parameters": {},
"args": ["--prod"]
}
]
}
Suggerimento
Aggiungere "databricks": true alla "type": "python" configurazione se si vuole usare la configurazione python, ma sfruttare l'autenticazione databricks Connect che fa parte della configurazione dell'estensione.
Usando configurazioni di esecuzione personalizzate, è anche possibile passare argomenti della riga di comando ed eseguire il codice semplicemente premendo F5. Per altre informazioni, vedere Avviare configurazioni nella documentazione di Visual Studio Code.