Come eseguire una valutazione e visualizzare i risultati
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Questo articolo descrive come eseguire una valutazione e visualizzare i risultati durante lo sviluppo dell'applicazione di intelligenza artificiale. Per informazioni su come monitorare la qualità degli agenti distribuiti nel traffico di produzione, vedere Come monitorare la qualità dell'agente nel traffico di produzione.
Per usare La valutazione dell'agente durante lo sviluppo di app, è necessario specificare un set di valutazione. Un set di valutazione è un set di richieste tipiche che un utente effettuerebbe all'applicazione. Il set di valutazione può includere anche la risposta prevista (verità di base) per ogni richiesta di input. Se viene fornita la risposta prevista, Agent Evaluation può calcolare metriche di qualità aggiuntive, ad esempio correttezza e sufficienza del contesto. Lo scopo del set di valutazione è misurare e prevedere le prestazioni dell'applicazione agentic testandola su domande rappresentative.
Per altre informazioni sui set di valutazione, vedere Set di valutazione. Per lo schema richiesto, vedere Schema di input di valutazione dell'agente.
Per iniziare la valutazione, usare il metodo mlflow.evaluate() dell'API MLflow. mlflow.evaluate() calcola valutazioni della qualità insieme alla latenza e alle metriche dei costi per ogni input nel set di valutazione e aggrega questi risultati in tutti gli input. Questi risultati sono detti anche risultati della valutazione. Nel seguente codice viene illustrato un esempio di chiamata di mlflow.evaluate():
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
In questo esempio registra mlflow.evaluate() i risultati della valutazione nell'esecuzione contenitore di MLflow, insieme alle informazioni registrate da altri comandi , ad esempio i parametri del modello. Se si chiama mlflow.evaluate() all'esterno di un'esecuzione MLflow, avvia una nuova esecuzione e registra i risultati della valutazione in tale esecuzione. Per altre informazioni su mlflow.evaluate(), inclusi i dettagli sui risultati della valutazione registrati nell'esecuzione, si veda la documentazione di MLflow.
Requisiti
Per l'area di lavoro è necessario abilitare le funzionalità di assistenza AI di Azure basato su intelligenza artificiale.
Come fornire input all’esecuzione di una valutazione
Esistono due modi per fornire input a un'esecuzione di valutazione:
Fornire output generati in precedenza da confrontare con il set di valutazione. Questa opzione è consigliata se si vogliono valutare gli output di un'applicazione già implementata nell'ambiente di produzione o se si vogliono confrontare i risultati della valutazione tra configurazioni di valutazione.
Con questa opzione, si specifica un set di valutazione come illustrato nel codice seguente. Il set di valutazione deve includere output generati in precedenza. Per esempi più dettagliati, vedere Esempio: Come passare output generati in precedenza alla valutazione dell'agente.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Passare l'applicazione come argomento di input.
mlflow.evaluate()chiama l'applicazione per ogni input nel set di valutazione e segnala valutazioni della qualità e altre metriche per ogni output generato. Questa opzione è consigliata se l'applicazione è stata registrata usando MLflow con MLflow Tracing abilitato o se l'applicazione viene implementata come funzione Python in un notebook. Questa opzione non è consigliata se l'applicazione è stata sviluppata all'esterno di Databricks o viene implementata all'esterno di Databricks.Con questa opzione, è possibile specificare il set di valutazione e l'applicazione nella chiamata di funzione, come illustrato nel codice seguente. Per esempi più dettagliati, vedere Esempio: Come passare un'applicazione alla valutazione dell'agente.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Per informazioni dettagliate sullo schema del set di valutazione, vedere Schema di input di valutazione dell'agente.
Output di valutazione
Agent Evaluation restituisce gli output da mlflow.evaluate() come dataframe e registra anche questi output nell'esecuzione di MLflow. È possibile esaminare gli output nel notebook o nella pagina dell'esecuzione MLflow corrispondente.
Esaminare l'output nel notebook
Il seguente codice illustra alcuni esempi di come esaminare i risultati di un'esecuzione di valutazione nel notebook.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Il per_question_results_df dataframe include tutte le colonne nello schema di input e tutti i risultati di valutazione specifici per ogni richiesta. Per altri dettagli sui risultati calcolati, vedere Come vengono valutati la qualità, i costi e la latenza dalla valutazione dell'agente.
Esaminare l'output usando l'interfaccia utente di MLflow
I risultati della valutazione sono disponibili anche nell’interfaccia utente di MLflow. Per accedere all'interfaccia utente di MLflow, fare clic sull'icona Esperimento ![]() nella barra laterale destra del notebook e poi sull'esecuzione corrispondente oppure fare clic sui collegamenti visualizzati nei risultati della cella per la cella del notebook in cui è stato eseguito
nella barra laterale destra del notebook e poi sull'esecuzione corrispondente oppure fare clic sui collegamenti visualizzati nei risultati della cella per la cella del notebook in cui è stato eseguito mlflow.evaluate().
Esaminare i risultati della valutazione per una singola esecuzione
Questa sezione descrive come esaminare i risultati della valutazione per una singola esecuzione. Per confrontare i risultati tra le esecuzioni, vedere Confrontare i risultati della valutazione tra le esecuzioni.
Panoramica delle valutazioni di qualità dei giudici LLM
Le valutazioni dei giudici per richiesta sono disponibili nella databricks-agents versione 0.3.0 e successive.
Per visualizzare una panoramica della qualità giudicata LLM di ogni richiesta nel set di valutazione, fare clic sulla scheda Risultati valutazione nella pagina Esecuzione MLflow. Questa pagina mostra una tabella di riepilogo per ciascuna esecuzione di valutazione. Per altri dettagli, fare clic sull'ID di valutazione di un'esecuzione.
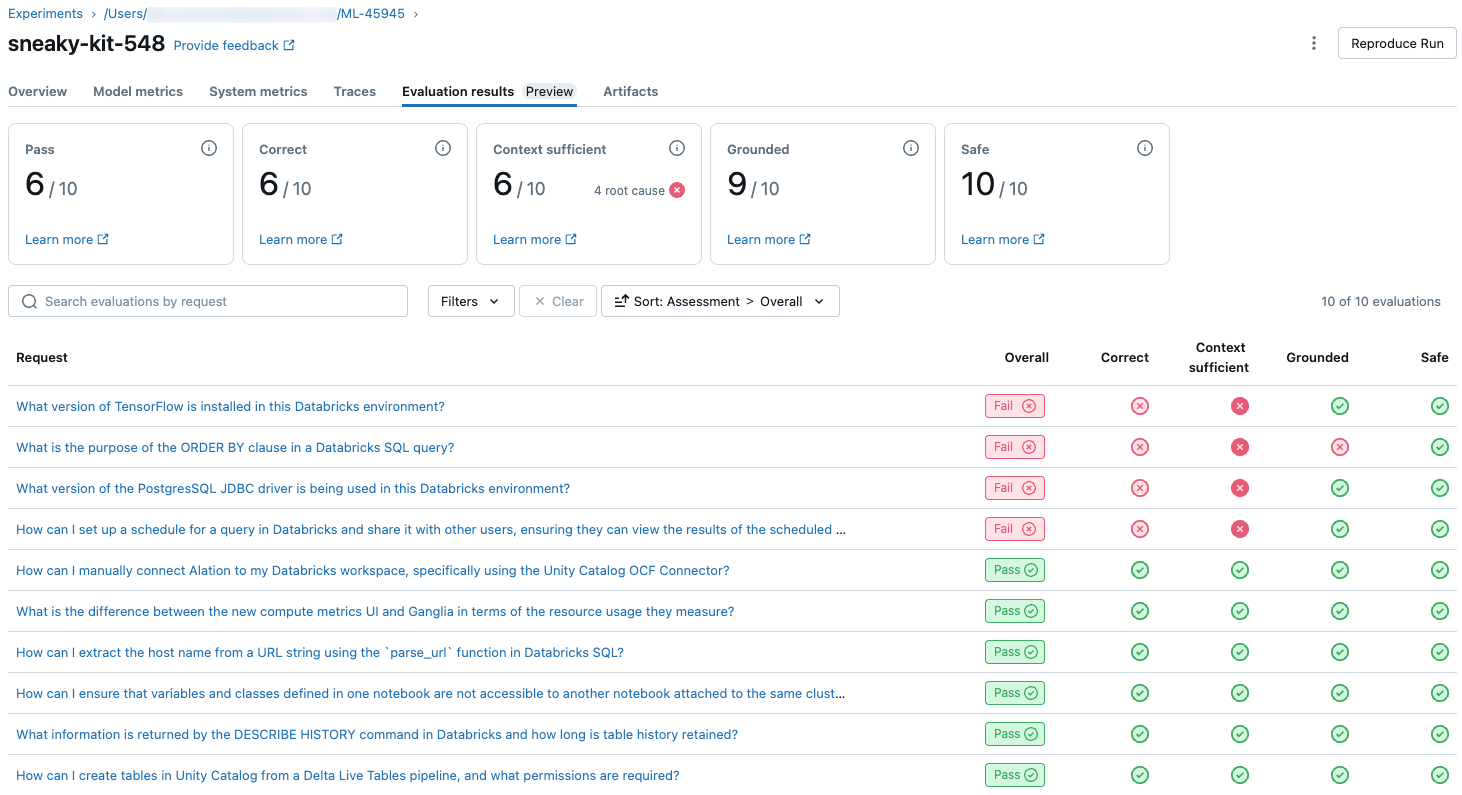
Questa panoramica mostra le valutazioni di giudici diversi per ogni richiesta, lo stato di qualità pass/fail di ogni richiesta in base a queste valutazioni e la causa radice delle richieste non riuscite. Facendo clic su una riga nella tabella si passerà alla pagina dei dettagli per la richiesta che include quanto segue:
- Output del modello: risposta generata dall'app agentic e dalla relativa traccia, se inclusa.
- Output previsto: risposta prevista per ciascuna richiesta.
- Valutazioni dettagliate: le valutazioni dei giudici LLM su questi dati. Fare clic su Visualizza dettagli per visualizzare le motivazioni fornite dai giudici.
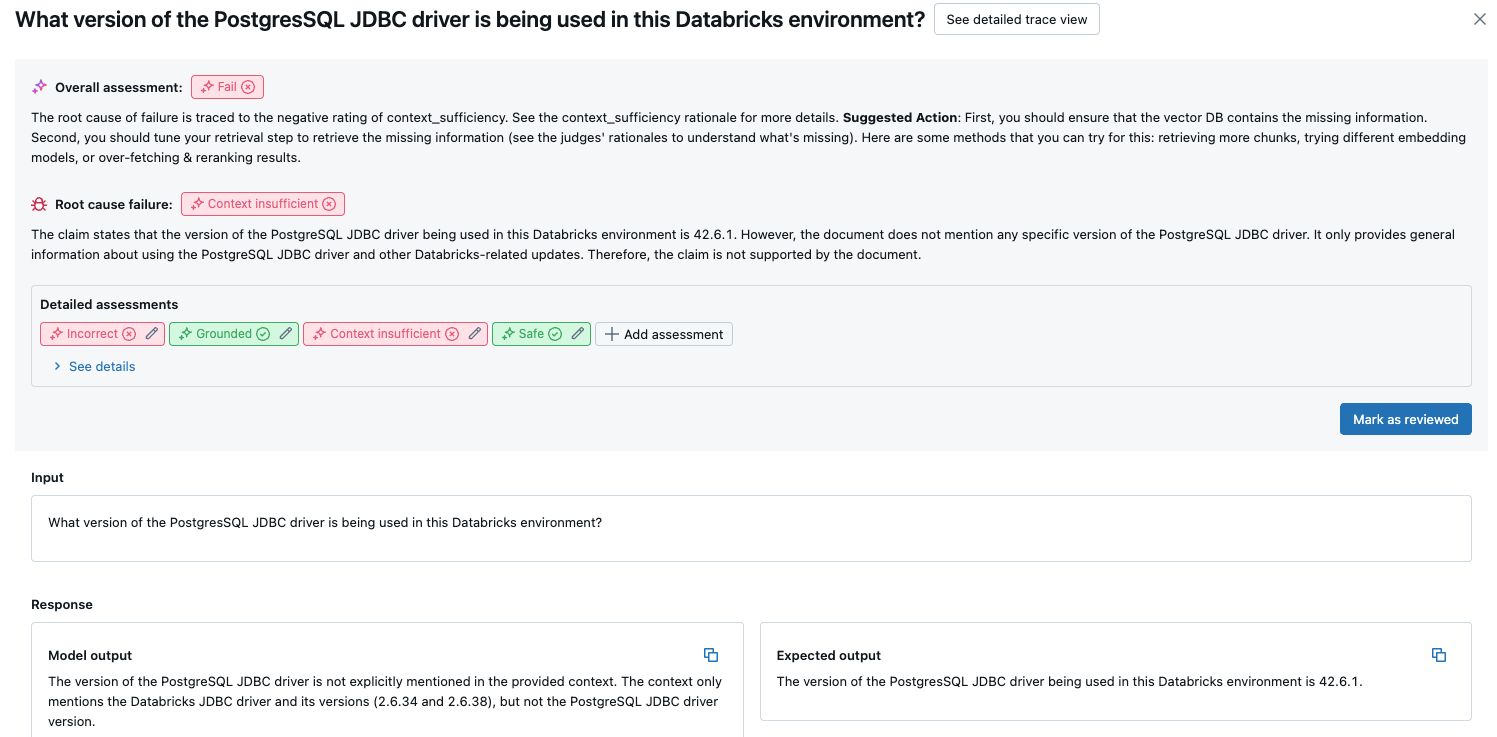
Risultati aggregati nel set di valutazione completo
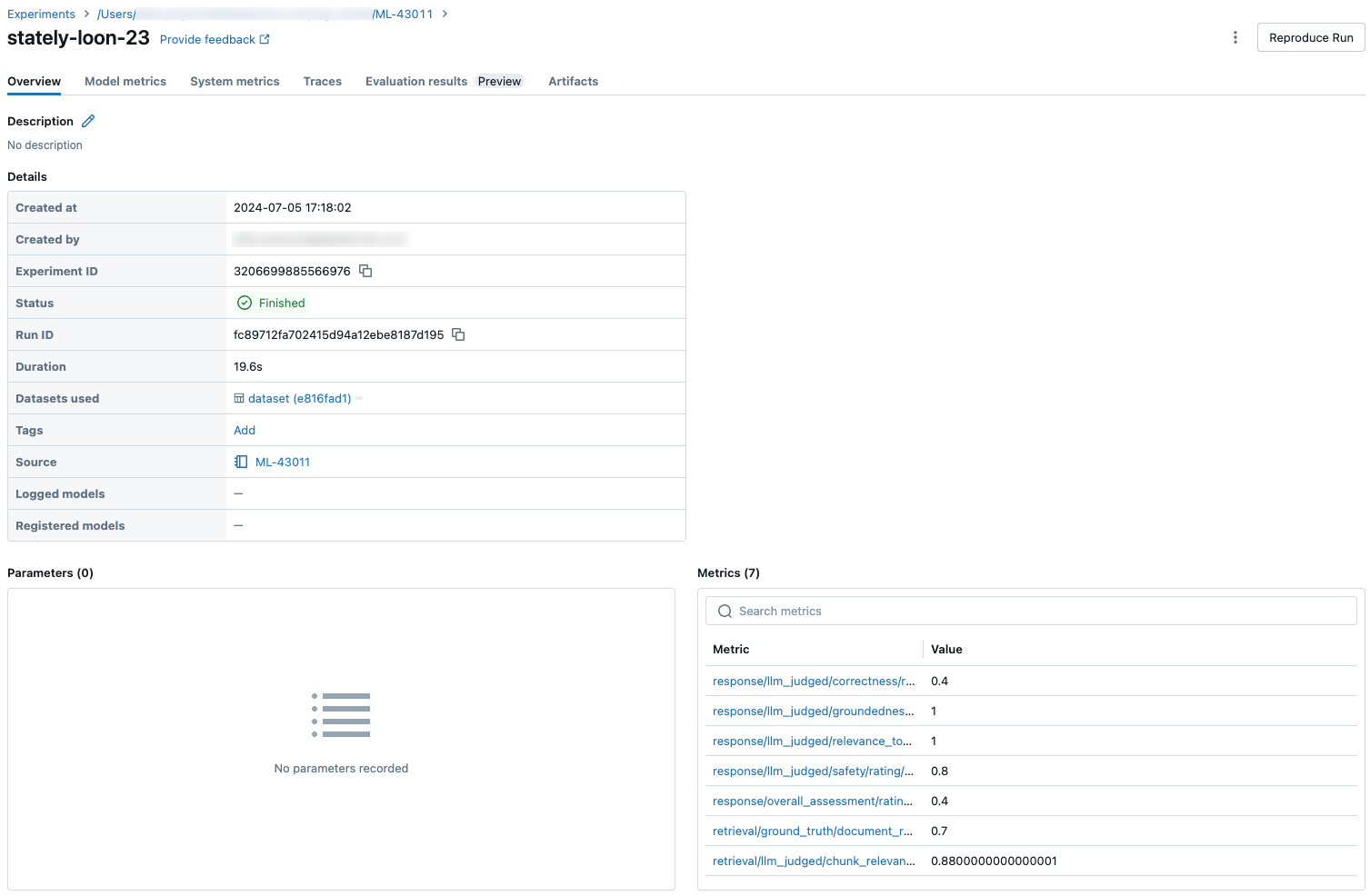
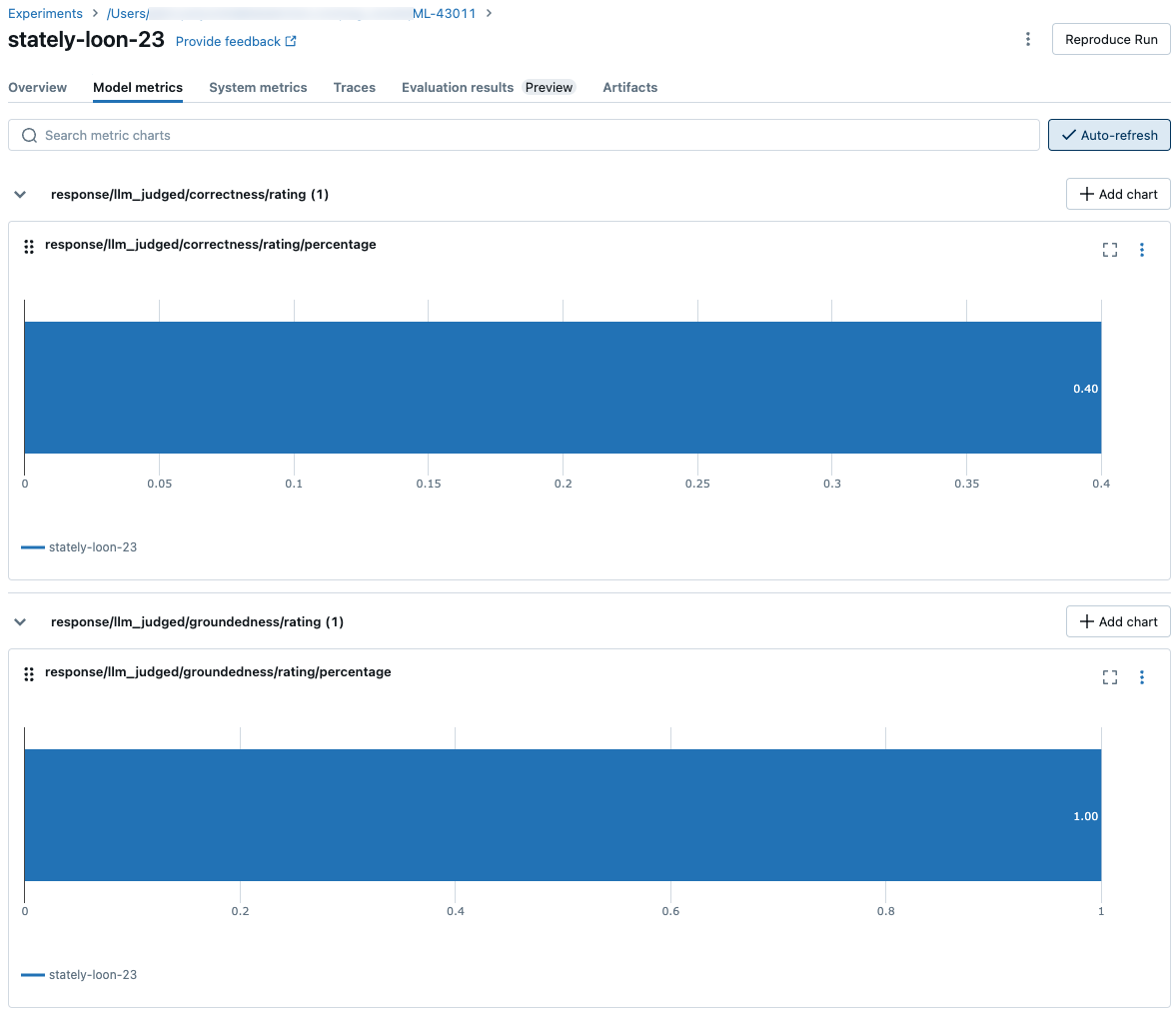
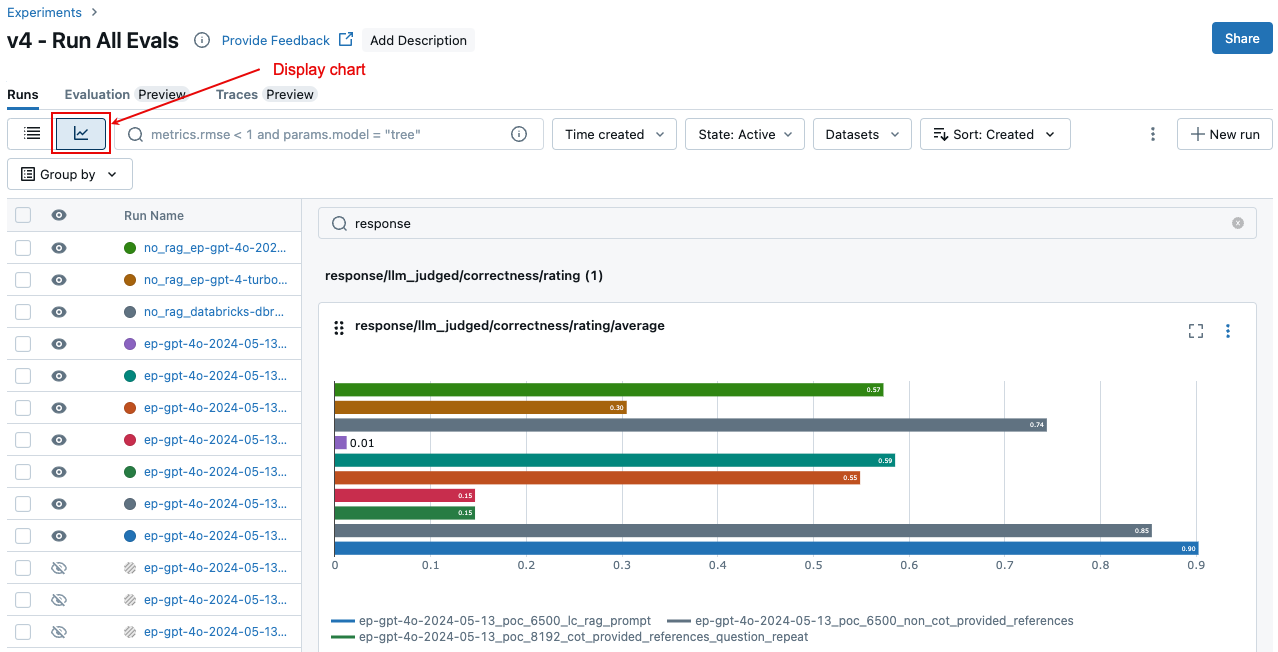
Per visualizzare i risultati aggregati nel set di valutazione completo, fare clic sulla scheda Panoramica (per i valori numerici) o sulla scheda Metriche modello (per i grafici).
Confrontare i risultati della valutazione tra le esecuzioni
È importante confrontare i risultati della valutazione tra le esecuzioni per vedere in che modo l'applicazione agentic risponde alle modifiche. Il confronto dei risultati consente di comprendere se le modifiche influiscono positivamente sulla qualità o se consentono di risolvere i problemi di modifica del comportamento.
Confrontare i risultati per richiesta tra esecuzioni
Per confrontare i dati per ogni singola richiesta nelle varie esecuzioni, fare clic sulla scheda Valutazione nella pagina Esperimento. Una tabella mostra le singole domande nel set di valutazione. Usare i menu a discesa per selezionare le colonne da visualizzare.
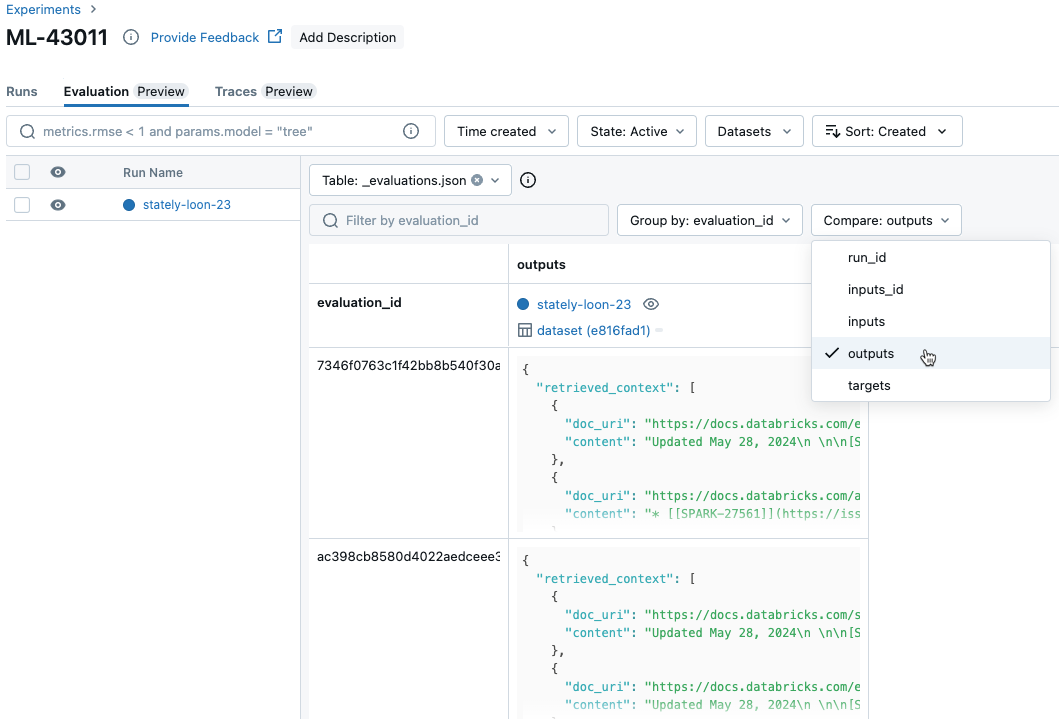
Confrontare i risultati aggregati tra le esecuzioni
È possibile accedere agli stessi risultati aggregati dalla pagina Esperimento, che consente anche di confrontare i risultati tra esecuzioni diverse. Per accedere alla pagina Esperimento, fare clic sull'icona Esperimento ![]() nella barra laterale destra del notebook oppure fare clic sui collegamenti visualizzati nei risultati per la cella del notebook in cui è stato eseguito
nella barra laterale destra del notebook oppure fare clic sui collegamenti visualizzati nei risultati per la cella del notebook in cui è stato eseguito mlflow.evaluate().
Nella pagina Esperimento fare clic su ![]() . In questo modo è possibile visualizzare i risultati aggregati per l'esecuzione selezionata e confrontarsi con le esecuzioni precedenti.
. In questo modo è possibile visualizzare i risultati aggregati per l'esecuzione selezionata e confrontarsi con le esecuzioni precedenti.
Quali giudici sono eseguiti
Per impostazione predefinita, per ogni record di valutazione, Mosaic AI Agent Evaluation applica il subset di giudici che meglio corrisponde alle informazioni presenti nel record. In particolare:
- Se il record include una risposta alla verità, Agent Evaluation applica i
context_sufficiencygiudici ,groundedness,correctnessesafety. - Se il record non include una risposta alla verità, Agent Evaluation applica i
chunk_relevancegiudici ,groundednessrelevance_to_query, esafety.
È anche possibile specificare in modo esplicito i giudici da applicare a ogni richiesta usando l'argomento evaluator_config di come indicato di mlflow.evaluate() seguito:
# Complete list of built-in LLM judges
# "chunk_relevance", "context_sufficiency", "correctness", "groundedness", "relevance_to_query", "safety"
evaluation_results = mlflow.evaluate(
data=eval_df,
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
# Run only LLM judges that don't require ground-truth. Use an empty list to not run any built-in judge.
"metrics": ["groundedness", "relevance_to_query", "chunk_relevance", "safety"]
}
}
)
Nota
Non è possibile disabilitare le metriche del giudice non LLM per il recupero di blocchi, il conteggio dei token di catena o la latenza.
Oltre ai giudici predefiniti, è possibile definire un giudice LLM personalizzato per valutare i criteri specifici del caso d'uso. Vedere Personalizzare i giudici LLM.
Vedere Informazioni sui modelli che alimentano i giudici LLM per informazioni sulla fiducia e sulla sicurezza dei giudici LLM.
Per altri dettagli sui risultati e sulle metriche di valutazione, vedere Come vengono valutati la qualità, i costi e la latenza dalla valutazione dell'agente.
Esempio: Come passare un'applicazione alla valutazione dell'agente
Per passare un'applicazione a mlflow_evaluate(), usare l'argomento model . Sono disponibili 5 opzioni per passare un'applicazione nell'argomento model .
- Modello registrato in Unity Catalog.
- Modello registrato MLflow nell'esperimento MLflow corrente.
- Modello PyFunc caricato nel notebook.
- Funzione locale nel notebook.
- Endpoint dell'agente distribuito.
Vedere le sezioni seguenti per esempi di codice che illustrano ogni opzione.
Opzione 1. Modello registrato nel catalogo unity
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Opzione 2. Modello registrato MLflow nell'esperimento MLflow corrente
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Opzione 3. Modello PyFunc caricato nel notebook
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Opzione 4. Funzione locale nel notebook
La funzione riceve un input formattato come segue:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
La funzione deve restituire un valore in uno dei tre formati supportati seguenti:
Stringa normale contenente la risposta del modello.
Dizionario in
ChatCompletionResponseformato. Ad esempio:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }Dizionario in
StringResponseformato, ad esempio{ "content": "MLflow is a machine learning toolkit.", ... }.
L'esempio seguente usa una funzione locale per eseguire il wrapping di un endpoint del modello di base e valutarlo:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Opzione 5. Endpoint agente distribuito
Questa opzione funziona solo quando si usano gli endpoint agente distribuiti con databricks.agents.deploy e con databricks-agents la versione 0.8.0 dell'SDK o versioni successive. Per i modelli di base o le versioni precedenti dell'SDK, usare l'opzione 4 per eseguire il wrapping del modello in una funzione locale.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Come passare il set di valutazione quando l'applicazione viene inclusa nella mlflow_evaluate() chiamata
Nel codice data seguente è un dataframe pandas con il set di valutazione. Questi sono semplici esempi. Per informazioni dettagliate, vedere lo schema di input.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Esempio: Come passare output generati in precedenza alla valutazione dell'agente
Questa sezione descrive come passare gli output generati in precedenza nella mlflow_evaluate() chiamata. Per lo schema del set di valutazione richiesto, vedere Schema di input di valutazione dell'agente.
Nel codice seguente è data un dataframe pandas con il set di valutazione e gli output generati dall'applicazione. Questi sono semplici esempi. Per informazioni dettagliate, vedere lo schema di input.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Esempio: usare una funzione personalizzata per elaborare le risposte da LangGraph
Gli agenti LangGraph, in particolare quelli con funzionalità di chat, possono restituire più messaggi per una singola chiamata di inferenza. È responsabilità dell'utente convertire la risposta dell'agente in un formato supportato da Agent Evaluation.
Un approccio consiste nell'usare una funzione personalizzata per elaborare la risposta. L'esempio seguente mostra una funzione personalizzata che estrae l'ultimo messaggio di chat da un modello LangGraph. Questa funzione viene quindi usata in mlflow.evaluate() per restituire una singola risposta stringa, che può essere confrontata con la ground_truth colonna.
Il codice di esempio presuppone quanto segue:
- Il modello accetta input nel formato {"messages": [{"role": "user", "content": "hello"}]}.
- Il modello restituisce un elenco di stringhe nel formato ["response 1", "response 2"].
Il codice seguente invia le risposte concatenate al giudice in questo formato: "risposta 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Creare un dashboard con le metriche
Quando si esegue l'iterazione sulla qualità dell'agente, è possibile condividere un dashboard con gli stakeholder che illustrano come la qualità è migliorata nel tempo. È possibile estrarre le metriche dalle esecuzioni di valutazione di MLflow, salvare i valori in una tabella Delta e creare un dashboard.
L'esempio seguente illustra come estrarre e salvare i valori delle metriche dall'esecuzione della valutazione più recente nel notebook:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
L'esempio seguente illustra come estrarre e salvare i valori delle metriche per le esecuzioni precedenti salvate nell'esperimento MLflow.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
È ora possibile creare un dashboard usando questi dati.
Il codice seguente definisce la funzione append_metrics_to_table usata negli esempi precedenti.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Limitazione
Per le conversazioni a più turni, l'output della valutazione registra solo l'ultima voce della conversazione.
Informazioni sui modelli che alimentano i giudici LLM
- I giudici LLM possono usare servizi di terze parti per valutare le applicazioni GenAI, tra cui Azure OpenAI gestito da Microsoft.
- Per Azure OpenAI, Databricks ha rifiutato esplicitamente il monitoraggio degli abusi, quindi non vengono archiviate richieste o risposte con Azure OpenAI.
- Per le aree di lavoro dell'Unione europea (UE), i giudici LLM usano modelli ospitati nell'UE. Tutte le altre aree usano modelli ospitati negli Stati Uniti.
- La disabilitazione delle funzioni di assistenza intelligenza artificiale di Azure basato su intelligenza artificiale impedisce al giudice LLM di richiamare i modelli AI di Azure.
- I dati inviati al giudice LLM non vengono usati per il training del modello.
- I giudici LLM hanno lo scopo di aiutare i clienti a valutare le proprie applicazioni RAG e i loro output non devono essere usati per formare, migliorare o ottimizzare un LLM.