Catena RAG per l'inferenza
Questo articolo descrive il processo che si verifica quando l'utente invia una richiesta all'applicazione RAG in un'impostazione online. Dopo aver elaborato i dati dalla pipeline di dati, è adatto per l'uso nell'applicazione RAG. La serie o la catena di passaggi richiamati in fase di inferenza viene comunemente definita catena RAG.
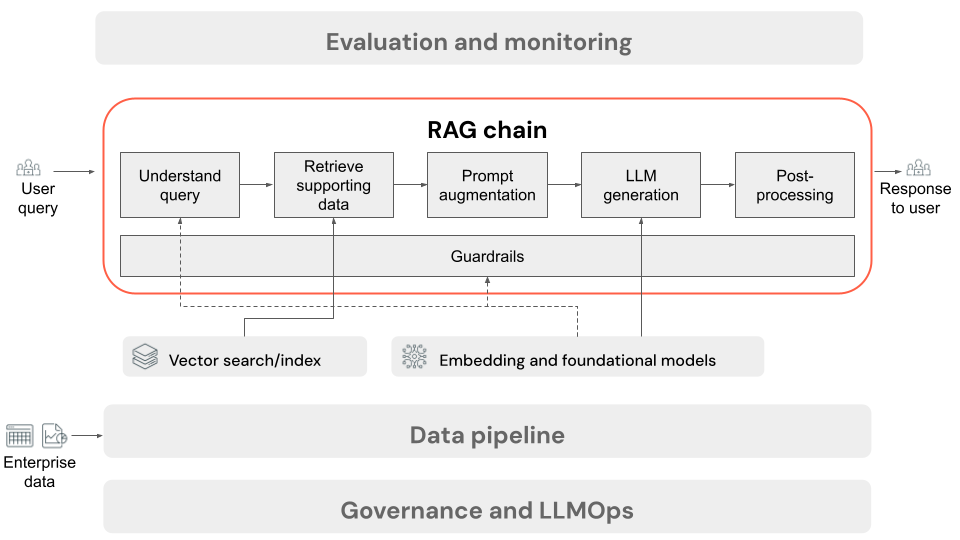
- (Facoltativo) Pre-elaborazione delle query utente: in alcuni casi, la query dell'utente viene pre-elaborata per renderla più adatta per l'esecuzione di query sul database vettoriale. Ciò può comportare la formattazione della query all'interno di un modello, l'uso di un altro modello per riscrivere la richiesta o l'estrazione di parole chiave per facilitare il recupero. L'output di questo passaggio è una query di recupero che verrà usata nel passaggio di recupero successivo.
- Recupero: per recuperare informazioni di supporto dal database vettoriale, la query di recupero viene convertita in un incorporamento usando lo stesso modello di incorporamento usato per incorporare i blocchi di documento durante la preparazione dei dati. Questi incorporamenti consentono il confronto della somiglianza semantica tra la query di recupero e i blocchi di testo non strutturati, usando misure come la somiglianza del coseno. Successivamente, i blocchi vengono recuperati dal database vettoriale e classificati in base al modo in cui sono simili alla richiesta incorporata. Vengono restituiti i risultati principali (più simili).
- Aumento della richiesta: il prompt che verrà inviato all'LLM viene formato aumentando la query dell'utente con il contesto recuperato, in un modello che indica al modello come usare ogni componente, spesso con istruzioni aggiuntive per controllare il formato di risposta. Il processo di iterazione sul modello di richiesta corretto da usare viene definito progettazione prompt.
- Generazione LLM: LLM accetta la richiesta aumentata, che include la query dell'utente e i dati di supporto recuperati, come input. Genera quindi una risposta che viene inserita nel contesto aggiuntivo.
- (Facoltativo) Post-elaborazione: la risposta dell'LLM può essere elaborata ulteriormente per applicare logica di business aggiuntiva, aggiungere citazioni o perfezionare il testo generato in base a regole o vincoli predefiniti.
Come per la pipeline di dati dell'applicazione RAG, esistono molte decisioni di progettazione consequenziali che possono influire sulla qualità della catena RAG. Ad esempio, determinare il numero di blocchi da recuperare nel passaggio 2 e come combinarli con la query dell'utente nel passaggio 3 può influire significativamente sulla capacità del modello di generare risposte di qualità.
In tutta la catena possono essere applicate varie protezioni per garantire la conformità ai criteri aziendali. Ciò potrebbe comportare l'applicazione di filtri per le richieste appropriate, il controllo delle autorizzazioni utente prima di accedere alle origini dati e l'applicazione di tecniche di con modalità tenda ration alle risposte generate.