Prerequisito: raccogliere i requisiti
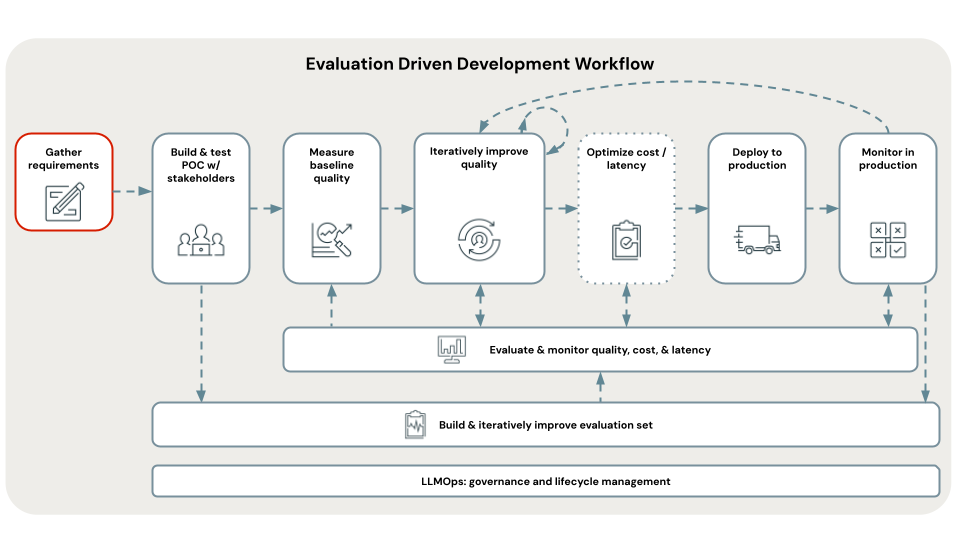
La definizione di requisiti chiari e completi per i casi d'uso è un primo passaggio fondamentale per lo sviluppo di un'applicazione RAG riuscita. Questi requisiti servono due scopi principali. In primo luogo, aiutano a determinare se RAG è l'approccio più adatto per il caso d'uso specificato. Se RAG è effettivamente una buona scelta, questi requisiti guidano la progettazione, l'implementazione e le decisioni di valutazione della soluzione. Investire tempo all'inizio di un progetto per raccogliere requisiti dettagliati può impedire sfide e setback significativi più avanti nel processo di sviluppo e assicura che la soluzione risultante soddisfi le esigenze degli utenti finali e degli stakeholder. I requisiti ben definiti forniscono le basi per le fasi successive del ciclo di vita di sviluppo che verrà illustrato.
Per il codice di esempio in questa sezione, vedere il repository GitHub. È anche possibile usare il codice del repository come modello con cui creare applicazioni di intelligenza artificiale personalizzate.
Il caso d'uso è adatto per RAG?
La prima cosa da stabilire è se RAG è anche l'approccio corretto per il caso d'uso. Dato l'hype intorno a RAG, è tentata di vederla come una possibile soluzione per qualsiasi problema. Tuttavia, ci sono sfumature da quando RAG è adatto rispetto a non.
RAG è una soluzione ottimale quando:
- Ragionamento sulle informazioni recuperate (sia non strutturate che strutturate) che non rientrano interamente nella finestra di contesto dell'LLM
- Sintesi delle informazioni da più origini (ad esempio, generazione di un riepilogo di punti chiave da articoli diversi su un argomento)
- Il recupero dinamico basato su una query utente è necessario (ad esempio, data una query utente, determinare l'origine dati da cui recuperare)
- Il caso d'uso richiede la generazione di nuovi contenuti in base alle informazioni recuperate (ad esempio, rispondere a domande, fornire spiegazioni, offrire raccomandazioni)
RAG potrebbe non essere la scelta migliore quando:
- L'attività non richiede il recupero specifico della query. Ad esempio, la generazione di riepiloghi delle trascrizioni delle chiamate; anche se le singole trascrizioni vengono fornite come contesto nel prompt LLM, le informazioni recuperate rimangono invariate per ogni riepilogo.
- L'intero set di informazioni da recuperare può rientrare nella finestra di contesto di LLM
- Sono necessarie risposte a bassa latenza estremamente bassa (ad esempio, quando le risposte sono necessarie in millisecondi)
- Le risposte semplici basate su regole o basate su modelli sono sufficienti (ad esempio, un chatbot di supporto clienti che fornisce risposte predefinite basate su parole chiave)
Requisiti da individuare
Dopo aver stabilito che RAG è una buona soluzione per il caso d'uso, prendere in considerazione le domande seguenti per acquisire requisiti concreti. È necessario prioritizzare i requisiti seguenti:
🟢 P0: deve definire questo requisito prima di avviare il modello di verifica.
🟡 P1: deve definire prima di passare alla produzione, ma può perfezionare in modo iterativo durante il modello di verifica.
⚪ P2: requisiti utili da avere.
Questo non è un elenco completo delle domande. Tuttavia, deve fornire una solida base per acquisire i requisiti chiave per la soluzione RAG.
Esperienza utente
Definire il modo in cui gli utenti interagiranno con il sistema RAG e il tipo di risposte previste
🟢 [P0] Quale sarà l'aspetto di una richiesta tipica alla catena RAG? Chiedere agli stakeholder esempi di potenziali query utente.
🟢 [P0] Che tipo di risposte gli utenti si aspettano (risposte brevi, spiegazioni in formato lungo, una combinazione o qualcos'altro)?
🟡 [P1] In che modo gli utenti interagiscono con il sistema? Tramite un'interfaccia di chat, una barra di ricerca o un'altra modalità?
🟡 [P1] il tono o lo stile del cappello devono avere risposte generate? (formale, colloquiale, tecnico?)
🟡 [P1] In che modo l'applicazione deve gestire query ambigue, incomplete o irrilevanti? In questi casi è necessario fornire una forma di feedback o indicazioni?
⚪ [P2] Esistono requisiti di formattazione o presentazione specifici per l'output generato? L'output deve includere metadati oltre alla risposta della catena?
Dati
Determinare la natura, le origini e la qualità dei dati che verranno usati nella soluzione RAG.
🟢 [P0] Quali sono le origini disponibili da usare?
Per ogni origine dati:
- 🟢 [P0] Dati strutturati e non strutturati?
- 🟢 [P0] Qual è il formato di origine dei dati di recupero (ad esempio PDF, documentazione con immagini/tabelle, risposte API strutturate)?
- 🟢 [P0] Dove risiedono i dati?
- 🟢 [P0] Quanti dati storici sono disponibili?
- 🟡 [P1] Con quale frequenza vengono aggiornati i dati? Come devono essere gestiti questi aggiornamenti?
- 🟡 [P1] Esistono problemi noti di qualità dei dati o incoerenze per ogni origine dati?
Prendere in considerazione la creazione di una tabella di inventario per consolidare queste informazioni, ad esempio:
| Origine dati | Origine | Tipo/i di file | Dimensione | Frequenza di aggiornamento |
|---|---|---|---|---|
| Origine dati 1 | Volume del catalogo Unity | JSON | 10 GB | Giornaliero |
| Origine dati 2 | API pubblica | XML | NA (API) | In tempo reale |
| Origine dati 3 | SharePoint | PDF, .docx | 500 MB | Mensile |
Vincoli di prestazioni
Acquisire i requisiti di prestazioni e risorse per l'applicazione RAG.
🟡 [P1] Qual è la latenza massima accettabile per la generazione delle risposte?
🟡 [P1] Qual è il tempo massimo accettabile per il primo token?
🟡 [P1] Se l'output viene trasmesso, è accettabile una latenza totale più elevata?
🟡 [P1] Esistono limitazioni dei costi per le risorse di calcolo disponibili per l'inferenza?
🟡 [P1] Quali sono i modelli di utilizzo previsti e i carichi di picco?
🟡 [P1] Quanti utenti o richieste simultanee devono essere in grado di gestire il sistema? Databricks gestisce in modo nativo tali requisiti di scalabilità, grazie alla possibilità di ridimensionare automaticamente con Model Serving.
Valutazione
Stabilire come la soluzione RAG verrà valutata e migliorata nel tempo.
🟢 [P0] Qual è l'obiettivo aziendale o l'indicatore KPI che si vuole influire? Qual è il valore di base e qual è la destinazione?
🟢 [P0] Quali utenti o stakeholder forniranno feedback iniziale e continuativo?
🟢 [P0] Quali metriche devono essere usate per valutare la qualità delle risposte generate? Mosaic AI Agent Evaluation offre un set consigliato di metriche da usare.
🟡 [P1] Qual è il set di domande che l'app RAG deve essere utile per passare alla produzione?
🟡 [P1] Esiste un [set di valutazione]? È possibile ottenere un set di valutazione di query utente, insieme alle risposte alla verità di base e (facoltativamente) ai documenti di supporto corretti che devono essere recuperati?
🟡 [P1] In che modo i commenti e i suggerimenti degli utenti verranno raccolti e incorporati nel sistema?
Sicurezza
Identificare qualsiasi considerazione sulla privacy e sulla sicurezza.
🟢 [P0] Sono presenti dati sensibili/riservati che devono essere gestiti con attenzione?
🟡 [P1] È necessario implementare i controlli di accesso nella soluzione ( ad esempio, un determinato utente può recuperare solo da un set limitato di documenti)?
Distribuzione
Informazioni su come verrà integrata, distribuita e gestita la soluzione RAG.
🟡 In che modo la soluzione RAG deve integrarsi con i sistemi e i flussi di lavoro esistenti?
🟡 Come deve essere distribuito, ridimensionato e con controllo delle versioni del modello? Questa esercitazione illustra come gestire il ciclo di vita end-to-end in Databricks usando MLflow, catalogo Unity, Agent SDK e Model Serving.
Esempio
Si consideri ad esempio come queste domande si applicano a questa applicazione RAG di esempio usata da un team di supporto clienti di Databricks:
| Area | Considerazioni | Requisiti |
|---|---|---|
| Esperienza utente | - Modalità di interazione. - Esempi di query utente tipici. - Formato e stile di risposta previsti. - Gestione di query ambigue o irrilevanti. |
- Interfaccia chat integrata con Slack. - Query di esempio: "Ricerca per categorie ridurre il tempo di avvio del cluster?" "Che tipo di piano di supporto ho?" - Risposte tecniche chiare con frammenti di codice e collegamenti alla documentazione pertinente, se appropriato. - Fornire suggerimenti contestuali ed eseguire l'escalation per supportare i tecnici quando necessario. |
| Dati | - Numero e tipo di origini dati. - Formato e posizione dei dati. - Dimensioni dei dati e frequenza di aggiornamento. - Qualità e coerenza dei dati. |
- Tre origini dati. - Documentazione aziendale (HTML, PDF). - Ticket di supporto risolti (JSON). - Post del forum della community (tabella Delta). - Dati archiviati in Unity Catalog e aggiornati settimanalmente. - Dimensioni totali dati: 5GB. - Struttura dei dati coerente e qualità gestite da documenti dedicati e team di supporto. |
| Prestazioni | - Latenza massima accettabile. - Vincoli relativi ai costi. - Utilizzo previsto e concorrenza. |
- Requisito di latenza massima. - Vincoli relativi ai costi. - Carico di picco previsto. |
| Valutazione | - Disponibilità del set di dati di valutazione. - Metriche di qualità. - Raccolta di commenti e suggerimenti degli utenti. |
- Esperti in materia di ogni area del prodotto aiutano a esaminare gli output e modificare risposte errate per creare il set di dati di valutazione. - KPI per il business. - Aumento della frequenza di risoluzione dei ticket di supporto. - Ridurre il tempo impiegato dall'utente per ogni ticket di supporto. - Metriche di qualità. - Risposta giudicata LLM correttezza e rilevanza. - LLM giudica la precisione di recupero. - Richiamare o disattivare l'utente. - Raccogliere feedback. - Slack verrà instrumentato per fornire un pollice su/giù. |
| Sicurezza | - Gestione dei dati sensibili. - Requisiti di controllo di accesso. |
- Nessun dato dei clienti sensibili deve trovarsi nell'origine di recupero. - Autenticazione utente tramite l'accesso SSO di Databricks Community. |
| Distribuzione | - Integrazione con i sistemi esistenti. - Distribuzione e controllo delle versioni. |
- Integrazione con il sistema di ticket di supporto. - Catena distribuita come endpoint di gestione del modello di Databricks. |
Passaggio successivo
Introduzione al Passaggio 1. Clonare il repository di codice e creare il calcolo.
< Precedente: Sviluppo basato sulla valutazione
Successivo: Passaggio 1. Clonare il repository e creare il calcolo >