Introduzione a RAG per lo sviluppo AI
Questo articolo è un'introduzione al recupero della generazione aumentata (RAG): che cos'è, come funziona e concetti chiave.
Che cos'è Retrieval Augmented Generation?
RAG è una tecnica che consente a un modello di linguaggio di grandi dimensioni (LLM) di generare risposte arricchite aumentando la richiesta di un utente con i dati di supporto recuperati da un'origine informazioni esterna. Incorporando queste informazioni recuperate, RAG consente all'LLM di generare risposte più accurate e di qualità superiore rispetto a non aumentare il prompt con un contesto aggiuntivo.
Si supponga, ad esempio, di creare un chatbot di domande e risposte per aiutare i dipendenti a rispondere alle domande sui documenti proprietari della società. Un LLM autonomo non sarà in grado di rispondere con precisione alle domande sul contenuto di questi documenti se non è stato sottoposto a training specifico su di essi. LLM potrebbe rifiutare di rispondere a causa di una mancanza di informazioni o, ancora peggio, potrebbe generare una risposta errata.
RAG risolve questo problema recuperando prima le informazioni rilevanti dai documenti aziendali in base alla query di un utente e quindi fornendo le informazioni recuperate all'LLM come contesto aggiuntivo. In questo modo l'LLM può generare una risposta più accurata disegnando i dettagli specifici trovati nei documenti pertinenti. In sostanza, RAG consente all'LLM di "consultare" le informazioni recuperate per formulare la sua risposta.
Componenti di base di un'applicazione RAG
Un'applicazione RAG è un esempio di sistema di intelligenza artificiale composto: si espande sulle funzionalità del linguaggio del solo modello combinandola con altri strumenti e procedure.
Quando si usa un LLM autonomo, un utente invia una richiesta, ad esempio una domanda, all'LLM e l'LLM risponde con una risposta basata esclusivamente sui dati di training.
Nella sua forma più semplice, i passaggi seguenti vengono eseguiti in un'applicazione RAG:
- Recupero: la richiesta dell'utente viene usata per eseguire query su alcune origini esterne alle informazioni. Ciò potrebbe significare l'esecuzione di query su un archivio vettoriale, l'esecuzione di una ricerca di parole chiave su testo o l'esecuzione di query su un database SQL. L'obiettivo del passaggio di recupero è ottenere dati di supporto che consentono all'LLM di fornire una risposta utile.
- Aumento: i dati di supporto del passaggio di recupero vengono combinati con la richiesta dell'utente, spesso usando un modello con formattazione e istruzioni aggiuntive all’LLM, per creare un prompt.
- Generazione: il prompt risultante viene passato a LLM e LLM genera una risposta alla richiesta dell'utente.
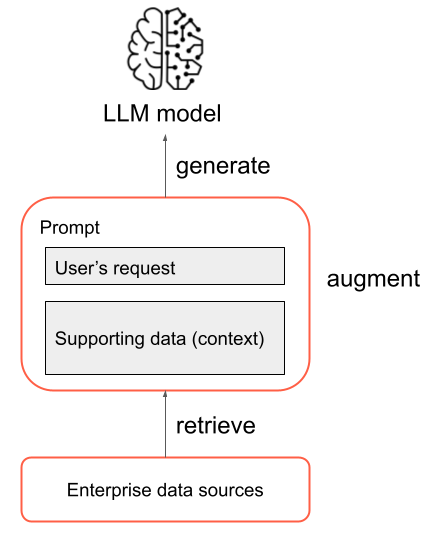
Si tratta di una panoramica semplificata del processo RAG, ma è importante notare che l'implementazione di un'applicazione RAG comporta molte attività complesse. La pre-elaborazione dei dati di origine per renderli adatti all'uso in RAG, il recupero efficace dei dati, la formattazione della richiesta aumentata e la valutazione delle risposte generate richiedono un'attenta considerazione e impegno. Questi argomenti verranno trattati in modo più dettagliato nelle sezioni successive di questa guida.
Perché usare RAG?
La tabella seguente illustra i vantaggi dell'uso di RAG rispetto a un LLM autonomo:
| Con un LLM da solo | Uso di LLM con RAG |
|---|---|
| Nessuna conoscenza proprietaria: i LLM in genere vengono sottoposti a training sui dati disponibili pubblicamente, quindi non possono rispondere con precisione alle domande sui dati interni o proprietari di un'azienda. | Le applicazioni RAG possono incorporare dati proprietari: un'applicazione RAG può fornire documenti proprietari, ad esempio memo, messaggi di posta elettronica e progettare documenti a un LLM, consentendogli di rispondere a domande su tali documenti. |
| Le informazioni non vengono aggiornate in tempo reale: LLM non hanno accesso alle informazioni sugli eventi che si sono verificati dopo il training. Ad esempio, un LLM autonomo non può indicare nulla sui movimenti azionari oggi. | Le applicazioni RAG possono accedere ai dati in tempo reale: un'applicazione RAG può fornire all'LLM informazioni tempestive da un'origine dati aggiornata, consentendogli di fornire risposte utili sugli eventi oltre la data di scadenza del training. |
| Mancanza di citazioni: LLM non può citare fonti specifiche di informazioni quando risponde, lasciando l'utente incapace di verificare se la risposta è effettivamente corretta o un'allucinazione. | RAG può citare le origini: se usato come parte di un'applicazione RAG, è possibile chiedere a un LLM di citare le relative origini. |
| Mancanza di controlli di accesso ai dati (ACL): i LLM da soli non possono fornire risposte diverse a utenti diversi in base a autorizzazioni utente specifiche. | RAG consente la sicurezza dei dati/ACL: il passaggio di recupero può essere progettato per trovare solo le informazioni a cui l'utente ha le credenziali di accesso, consentendo a un'applicazione RAG di recuperare in modo selettivo informazioni personali o proprietarie. |
Tipi di RAG
L'architettura RAG può funzionare con due tipi di dati di supporto:
| Dati strutturati | Dati non strutturati | |
|---|---|---|
| Definizione | dati tabulari disposti in righe e colonne con uno schema specifico, ad esempio tabelle in un database. | Dati senza una struttura o un'organizzazione specifica, ad esempio documenti che includono testo e immagini o contenuti multimediali, ad esempio audio o video. |
| Origini dati di esempio | - Record dei clienti in un sistema BI o data warehouse - Dati transazione da un database SQL - Dati dalle API dell'applicazione (ad esempio SAP, Salesforce e così via) |
- Record dei clienti in un sistema BI o data warehouse - Dati transazione da un database SQL - Dati dalle API dell'applicazione (ad esempio SAP, Salesforce e così via) - Documenti di Google o Microsoft Office - Wiki - Immagini - Video |
La scelta dei dati per RAG dipende dal caso d'uso. Il resto del libro di cucina è incentrato su RAG per i dati non strutturati.