Preparare i dati per l'ottimizzazione del modello foundation
Importante
Questa funzionalità è disponibile in anteprima pubblica nelle aree seguenti: centralus, eastus, eastus2, northcentralus, e westus.
Questo articolo descrive i formati accettati dei file di dati per l'addestramento e la valutazione nell'ottimizzazione di precisione dei modelli di base (ora parte dell'addestramento modelli Mosaic AI).
Notebook: convalida dei dati per le esecuzioni di addestramento
Il notebook seguente illustra come convalidare i dati. È progettato per essere eseguito in modo indipendente prima di iniziare il training. Verifica che i dati siano nel formato corretto per l'ottimizzazione del modello foundation e includa il codice che consente di stimare i costi durante l'esecuzione del training tramite tokenizzazione del set di dati non elaborato.
Convalidare i dati per i notebook delle esecuzioni di training
Preparare i dati per il completamento della chat
Per le attività di completamento della chat, i dati in formato chat devono trovarsi in un file jsonl, dove ogni riga è un oggetto JSON separato che rappresenta una singola sessione di chat. Ogni sessione di chat è rappresentata come oggetto JSON con una singola chiave, messages, che esegue il mapping a una matrice di oggetti messaggio. Per eseguire il training sui dati della chat, specificare il task_type = 'CHAT_COMPLETION' quando crei il run di allenamento.
I messaggi in formato chat vengono formattati automaticamente in base al modello di chat , quindi non è necessario aggiungere token di chat speciali per segnalare manualmente l'inizio o la fine di un turno di chat. Un esempio di modello che usa un modello di chat personalizzato è Meta Llama 3.1 8B Instruct.
Ogni oggetto messaggio nella matrice rappresenta un singolo messaggio nella conversazione e ha la struttura seguente:
-
role: Una stringa che indica l'autore del messaggio. I valori possibili sonosystem,usereassistant. Se il ruolo èsystem, deve essere la prima chat nell'elenco dei messaggi. Deve essere presente almeno un messaggio con il ruoloassistante tutti i messaggi dopo la richiesta di sistema (facoltativa) devono alternare ruoli tra utente/assistente. Non devono essere presenti due messaggi adiacenti con lo stesso ruolo. L'ultimo messaggio nella matrice dimessagesdeve avere il ruoloassistant. -
content: Una stringa che contiene il testo del messaggio di errore.
Nota
I modelli Mistral non accettano system ruoli nei formati di dati.
Di seguito è riportato un esempio di dati formattati in chat:
{"messages": [
{"role": "system", "content": "A conversation between a user and a helpful assistant."},
{"role": "user", "content": "Hi there. What's the capital of the moon?"},
{"role": "assistant", "content": "This question doesn't make sense as nobody currently lives on the moon, meaning it would have no government or political institutions. Furthermore, international treaties prohibit any nation from asserting sovereignty over the moon and other celestial bodies."},
]
}
Preparare i dati per il pre-training continuo
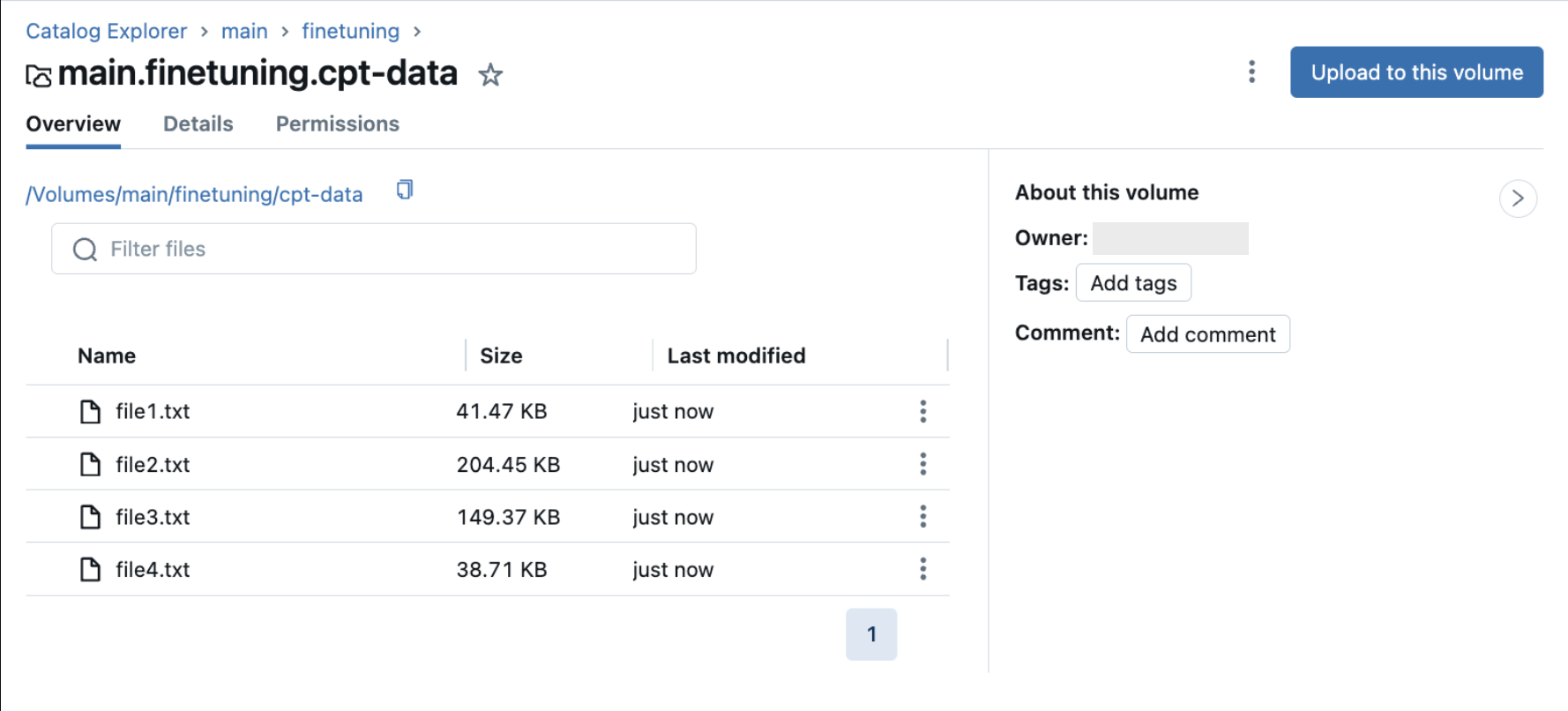
Per le task di pre-training continue, i dati di training sono i dati di testo non strutturati. I dati di training devono trovarsi in un volume di Unity Catalog contenente .txt file. Ogni .txt file viene considerato come un singolo esempio. Se i file .txt si trovano in una cartella del volume di Unity Catalog, tali file vengono ottenuti anche per i dati di training. Tutti i file non txt nel volume vengono ignorati. Vedere Caricamento file in un volume del catalogo Unity.
L'immagine seguente mostra i file di esempio .txt in un volume del catalogo Unity. Per utilizzare questi dati nella configurazione continua di pre-allenamento, impostare train_data_path = "dbfs:/Volumes/main/finetuning/cpt-data" e task_type = 'CONTINUED_PRETRAIN'.
Formatta i dati da te stesso
Avvertimento
Le indicazioni contenute in questa sezione non sono consigliate, ma sono disponibili per gli scenari in cui è necessaria la formattazione dei dati personalizzata.
Databricks consiglia vivamente di utilizzare dati formattati per chat, affinché la formattazione corretta venga applicata automaticamente ai tuoi dati in base al modello che stai utilizzando.
L'ottimizzazione del modello di base consente di eseguire manualmente la formattazione dei dati. È necessario applicare qualsiasi formattazione dei dati durante il training e la gestione del modello. Per eseguire il training del modello usando i dati formattati, imposta il valore task_type = 'INSTRUCTION_FINETUNE' quando avvii il processo di training.
I dati di training e valutazione devono trovarsi in uno degli schemi seguenti:
Coppie Richiesta e risposta.
{"prompt": "your-custom-prompt", "response": "your-custom-response"}Coppie Richiesta e completamento.
{"prompt": "your-custom-prompt", "completion": "your-custom-response"}
Importante
Richiesta-risposta e richiesta-completamento non sonomodellati, quindi qualsiasi templating specifico del modello, ad esempio la formattazione dei comandi di Mistral deve essere eseguita come passaggio di pre-elaborazione.
Formati di dati supportati
Di seguito sono riportati i formati di dati supportati:
Volume del catalogo Unity con un
.jsonlfile. I dati di training devono essere in formato JSONL, dove ogni linea è un oggetto JSON valido. L'esempio seguente mostra un esempio di coppia di richieste e risposte:{"prompt": "What is Databricks?","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."}Una tabella Delta conforme a uno degli schemi accettati indicati sopra. Per le tabelle Delta, è necessario specificare un
data_prep_cluster_idparametro per l'elaborazione dati. Vedere Configurare un'esecuzione di training.Set di dati pubblico Hugging Face.
Se si usa un set di dati pubblico Hugging Face come dati di training, specificare il percorso completo con la divisione,
mosaicml/instruct-v3/train and mosaicml/instruct-v3/testad esempio . Questo vale per i set di dati con schemi di divisione diversi. I set di dati annidati da Hugging Face non sono supportati.Per un esempio più completo, vedere il
mosaicml/dolly_hhrlhfset di dati in Hugging Face.Le righe di dati di esempio seguenti provengono dal
mosaicml/dolly_hhrlhfset di dati.{"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: what is Databricks? ### Response: ","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."} {"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Van Halen famously banned what color M&Ms in their rider? ### Response: ","response": "Brown."}