Supporto temporizzato con le tabelle delle caratteristiche delle serie temporali
Questo articolo descrive come usare la correttezza temporizzato per creare un set di dati di training che riflette in modo accurato i valori delle caratteristiche a partire dal momento in cui è stata registrata un'osservazione dell'etichetta. Questo è importante per evitare la perdita di dati, che si verifica quando si usano valori di funzionalità per il training del modello che non erano disponibili al momento della registrazione dell'etichetta. Questo tipo di errore può essere difficile da rilevare e può influire negativamente sulle prestazioni del modello.
Le tabelle delle funzionalità delle serie temporali includono una colonna chiave timestamp che garantisce che ogni riga nel set di dati di training rappresenti i valori delle funzionalità note più recenti a partire dal timestamp della riga. È consigliabile usare le tabelle delle funzionalità delle serie temporali ogni volta che i valori delle funzionalità cambiano nel tempo, ad esempio con i dati delle serie temporali, i dati basati su eventi o i dati aggregati nel tempo.
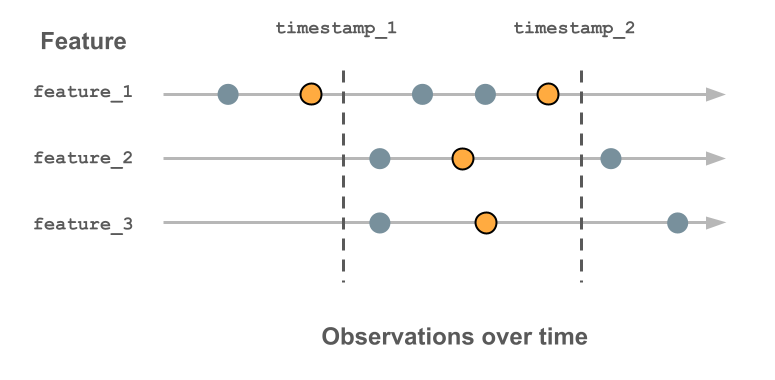
Il diagramma seguente mostra come viene usata la chiave timestamp. Il valore della funzionalità registrato per ogni timestamp è il valore più recente prima di tale timestamp, indicato dal cerchio arancione evidenziato. Se non sono stati registrati valori, il valore della funzionalità è Null. Per altri dettagli, vedere Funzionamento delle tabelle delle funzionalità delle serie temporali.
Nota
- Con Databricks Runtime 13.3 LTS e versioni successive, qualsiasi tabella Delta di Unity Catalog con chiavi primarie e chiavi timestamp può essere utilizzata come tabella delle funzionalità di serie temporali.
- Per prestazioni migliori nelle ricerche temporizzate, Databricks consiglia di applicare Liquid Clustering (per
databricks-feature-engineering0.6.0 e versioni successive) o Z-Ordering (perdatabricks-feature-engineering0.6.0 e versioni precedenti) nelle tabelle delle serie temporali. - La funzionalità di ricerca temporizzata viene talvolta definita "viaggio temporale". La funzionalità temporizzata in Databricks Feature Store non è correlata al viaggio temporale di Delta Lake.
Funzionamento delle tabelle delle funzionalità delle serie temporali
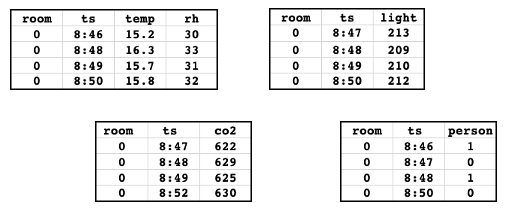
Si supponga di avere le seguenti tabelle di funzionalità. Questi dati vengono ricavati dal notebook di esempio.
Le tabelle contengono dati del sensore che misurano la temperatura, l'umidità relativa, la luce ambientale e l'anidride carbonica in una stanza. La tabella della verità di base indica se una persona era presente nella stanza. Ognuna delle tabelle ha una chiave primaria ('room') e una chiave timestamp ('ts'). Per semplicità, vengono visualizzati solo i dati per un singolo valore della chiave primaria ('0').
La seguente figura illustra come viene usata la chiave timestamp per garantire la correzione temporizzata in un set di dati di training. I valori delle funzionalità vengono confrontati in base alla chiave primaria (non illustrata nel diagramma) e alla chiave timestamp, usando un operatore AS OF. L’operatore AS OF garantisce che il valore più recente della funzionalità al momento del timestamp venga utilizzato nel set di training.
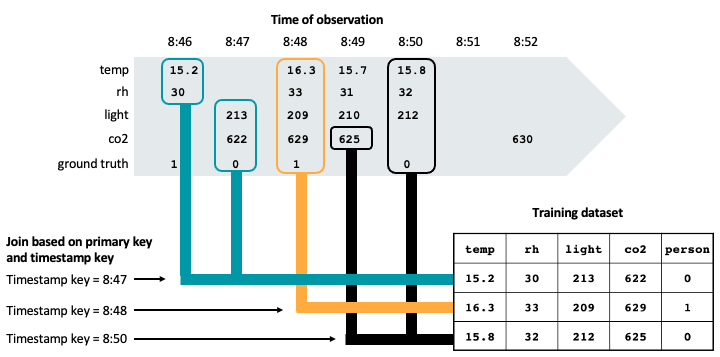
Come mostrato nella figura, il dataset di training comprende gli ultimi valori delle funzionalità per ogni sensore prima del timestamp sulla verità di base osservata.
Se è stato creato un set di dati di training senza prendere in considerazione la chiave timestamp, è possibile che sia presente una riga con questi valori di funzionalità e la verità di base osservata:
| temp | rh | light | co2 | verità di base |
|---|---|---|---|---|
| 15.8 | 32 | 212 | 630 | 0 |
Tuttavia, questa non è un'osservazione valida per il training, perché la lettura co2 di 630 è stata presa alle 8:52, dopo l'osservazione della verità di base alle 8:50. I dati futuri sono "perdite" nel set di training, che compromettono le prestazioni del modello.
Requisiti
- Per progettazione di funzionalità in Unity Catalog: progettazione delle funzionalità nel client di Unity Catalog (qualsiasi versione).
- Per il Workspace Feature Store (legacy): client Feature Store v0.3.7 e versioni successive.
Come specificare chiavi correlate al tempo
Per usare la funzionalità temporizzata, è necessario specificare chiavi relative al tempo usando l'argomento timeseries_columns (per progettazione delle funzionalità in Unity Catalog) o l'argomento timestamp_keys (per l'archivio delle funzionalità dell'area di lavoro). Ciò indica che le righe della tabella delle funzionalità devono essere unite associando il valore più recente per una determinata chiave primaria che non è successiva al valore della colonna timestamps_keys, anziché con associazione in base a una corrispondenza temporale esatta.
Se non si usa timeseries_columns o timestamp_keys e si designa solo una colonna timeseries come colonna chiave primaria, l'archivio funzionalità non applica la logica temporizzata alla colonna timeseries durante le associazioni. Al contrario, abbina solo le righe con una corrispondenza temporale esatta, invece di abbinare tutte le righe precedenti al timestamp.
Creare una tabella delle funzionalità della serie temporale in Unity Catalog
In Unity Catalog qualsiasi tabella con una chiave primaria TIMESERIES è una tabella delle funzionalità della serie temporale. Per informazioni su come crearne una, si veda Creare una tabella delle funzionalità in Unity Catalog .
Creare una tabella di funzionalità delle serie temporali nell'area di lavoro locale
Per creare una tabella delle funzionalità della serie temporale nel Feature Store dell'area di lavoro locale, il dataframe o lo schema devono contenere una colonna designata come chiave timestamp.
A partire dal client di Feature Store v0.13.4, le colonne chiave timestamp devono essere specificate nell'argomento primary_keys. Le chiavi timestamp fanno parte delle "chiavi primarie" che identificano in modo univoco ogni riga nella tabella delle funzionalità. Analogamente ad altre colonne chiave primaria, le colonne chiave timestamp non possono contenere valori NULL.
Progettazione delle funzionalità nel catalogo Unity
fe = FeatureEngineeringClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.create_table(
name="ml.ads_team.user_features",
primary_keys=["user_id", "ts"],
timeseries_columns="ts",
features_df=user_features_df,
)
Client di Feature Store v0.13.4 e versioni successive
fs = FeatureStoreClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.create_table(
name="ads_team.user_features",
primary_keys=["user_id", "ts"],
timestamp_keys="ts",
features_df=user_features_df,
)
Client di Feature Store v0.13.3 e versioni precedenti
fs = FeatureStoreClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.create_table(
name="ads_team.user_features",
primary_keys="user_id",
timestamp_keys="ts",
features_df=user_features_df,
)
Una tabella delle funzionalità della serie temporale deve avere una chiave timestamp e non può avere colonne di partizione. La colonna chiave timestamp deve essere di TimestampType o DateType.
Databricks raccomanda che le tabelle delle funzionalità delle serie temporali non dispongano di più di due colonne chiave primaria per garantire scritture e ricerche efficienti.
Aggiornare una tabella delle funzionalità della serie temporale
Quando si scrivono funzionalità nelle tabelle delle funzionalità delle serie temporali, il dataframe deve fornire valori per tutte le funzionalità della tabella, a differenza di quanto accade con le normali tabelle delle funzionalità. Questo vincolo riduce la densità dei valori delle funzionalità tra i timestamp nella tabella delle funzionalità della serie temporale.
Progettazione delle funzionalità nel catalogo Unity
fe = FeatureEngineeringClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.write_table(
"ml.ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
Client di Feature Store v0.13.4 e versioni successive
fs = FeatureStoreClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.write_table(
"ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
Le scritture di streaming nelle tabelle delle funzionalità delle serie temporali sono supportate.
Creare un set di training con una tabella delle funzionalità delle serie temporali
Per eseguire una ricerca temporizzato per i valori delle funzionalità di una tabella delle funzionalità di una serie temporale, è necessario specificare un timestamp_lookup_key nel FeatureLookup della funzionalità, che indica il nome della colonna DataFrame che contiene timestamp in base ai quali cercare le funzionalità della serie temporale. Databricks Feature Store recupera i valori delle funzionalità più recenti prima dei timestamp specificati nella colonna timestamp_lookup_key del dataframe e le cui chiavi primarie (escluse le chiavi timestamp) corrispondono ai valori nelle colonne lookup_key del dataframe o null se non esiste alcun valore di funzionalità di questo tipo.
Progettazione delle funzionalità nel catalogo Unity
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ml.ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fe.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
Suggerimento
Per prestazioni di ricerca più rapide quando Photon è abilitato, passare use_spark_native_join=True a FeatureEngineeringClient.create_training_set. Questa operazione richiede databricks-feature-engineering nella versione 0.6.0 o successive.
Feature Store dell'area di lavoro
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fs.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
Qualsiasi FeatureLookup in una tabella delle funzionalità di serie temporali deve essere una ricerca temporizzata, pertanto deve specificare una colonna timestamp_lookup_key da usare nel dataframe. La ricerca temporizzata non ignora le righe con valori null di funzionalità archiviati nella tabella delle funzionalità della serie temporale.
Impostare un limite di tempo per la cronologia dei valori delle funzionalità
Con il client Feature Store v0.13.0 o versione successiva, o con qualsiasi versione di Feature Engineering nel client Unity Catalog, è possibile escludere dal set di training i valori delle funzionalità con timestamp più vecchi. A tale scopo, usare il parametro lookback_window in FeatureLookup.
Il tipo di dati di lookback_window deve essere datetime.timedelta e il valore predefinito è None (vengono usati tutti i valori di funzionalità, indipendentemente dal tempo).
Ad esempio, il seguente codice esclude tutti i valori di funzionalità che hanno più di 7 giorni:
Progettazione delle funzionalità nel catalogo Unity
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
Feature Store dell'area di lavoro
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
Quando si chiama create_training_set con l'oggetto precedente FeatureLookup, esegue automaticamente l’associazione temporizzata ed esclude i valori di funzionalità precedenti a 7 giorni.
La finestra di lookback viene applicata durante il training e l'inferenza batch. Durante l'inferenza online, il valore della funzionalità più recente viene sempre usato, indipendentemente dalla finestra di lookback.
Assegnare punteggi ai modelli con tabelle delle funzionalità delle serie temporali
Quando si assegna un punteggio a un modello addestrato con funzionalità provenienti da tabelle di funzionalità di serie temporali, Databricks Feature Store recupera le funzionalità appropriate utilizzando lookup temporizzati con i metadati forniti con il modello durante il training. Il dataframe specificato con FeatureEngineeringClient.score_batch (per progettazione delle funzionalità nel catalogo Unity) o FeatureStoreClient.score_batch (per l'archivio funzionalità dell'area di lavoro) deve contenere una colonna timestamp con lo stesso nome e DataType come timestamp_lookup_key dell'oggetto FeatureLookup fornito a FeatureEngineeringClient.create_training_set o FeatureStoreClient.create_training_set.
Suggerimento
Per prestazioni di ricerca più rapide quando Photon è abilitato, passare use_spark_native_join=True a FeatureEngineeringClient.score_batch. Questa operazione richiede databricks-feature-engineering nella versione 0.6.0 o successive.
Pubblicare le funzionalità delle serie temporali in uno store online
È possibile usare FeatureEngineeringClient.publish_table (per progettazione di funzionalità nel catalogo Unity) o FeatureStoreClient.publish_table (per l'archivio delle funzionalità dell'area di lavoro) per pubblicare tabelle delle funzionalità delle serie temporali negli store online. Databricks Feature Store pubblica uno snapshot dei valori delle funzionalità più recenti per ogni chiave primaria nella tabella delle funzionalità nell'archivio online. L'archivio online supporta la ricerca della chiave primaria, ma non la ricerca temporizzata.
Esempio di notebook: tabella delle funzionalità di serie temporali
Questi notebook di esempio illustrano le ricerche temporizzate nelle tabelle delle funzionalità di serie temporali.
Usare questo notebook nelle aree di lavoro abilitate per il catalogo Unity.
Esempio di notebook: tabella delle funzionalità di serie temporali (catalogo Unity)
Il seguente notebook è progettato per le aree di lavoro non abilitate per il catalogo Unity. Utilizza l'archivio delle funzionalità dell'area di lavoro.