Luglio 2018
Queste funzionalità e i miglioramenti della piattaforma Azure Databricks sono stati rilasciati a luglio 2018.
L’API Librerie supporta le librerie wheel di Python
31 luglio 7 agosto 2018: versione 2.77
È ora possibile installare librerie wheel usando l'API Librerie. Quando si installa una libreria wheel in un cluster che esegue Databricks Runtime 4.2 o versione successiva, vengono incluse tutte le dipendenze specificate nel file di libreria setup.py . Quando si installa una libreria wheel in un cluster che esegue Databricks Runtime 4.1 o versione successiva, il file viene aggiunto alla PYTHONPATH variabile senza installare le dipendenze.
Esportazione di notebook IPython
31 luglio 7 agosto 2018: versione 2.77
Quando si esporta un notebook di Azure Databricks nel formato del notebook IPython, i risultati vengono ora inclusi nell'esportazione.
Ambiti dei segreti con basati su Azure Key Vault
19-24 luglio 2018: versione 2.76
I segreti ora supportano gli ambiti supportati da un insieme di credenziali delle chiavi di Azure. Dopo aver creato l'ambito, è possibile accedere a tutti i segreti nell'insieme di credenziali delle chiavi corrispondente da tale ambito. Per informazioni dettagliate, vedere Gestire gli ambiti dei segreti.
Nota
L'ambito del segreto supportato da Azure Key Vault è un'interfaccia di sola lettura per Key Vault. Per gestire i segreti in Azure Key Vault, è necessario usare l'API REST di Azure Set Secret o l'interfaccia utente del portale di Azure.
Aree di lavoro Premium di valutazione
20-24 luglio 2018: versione 2.76
Azure Databricks offre ora aree di lavoro Premium di valutazione. Durante una versione di valutazione di 14 giorni è possibile accedere alle UR di Azure Databricks gratuite. Per altre informazioni, vedere Creare un'area di lavoro.
Modalità cluster e cluster a concorrenza elevata
19-24 luglio 2018: versione 2.76
Quando si crea un cluster, l'opzione Tipo di cluster è stata rinominata in Modalità cluster. L'opzione Pool serverless è stata sostituita dalla modalità cluster a concorrenza elevata. I cluster con concorrenza elevata sono ottimizzati per offrire un utilizzo efficiente delle risorse, isolamento, sicurezza e prestazioni ottimali quando condiviso da più utenti contemporaneamente attivi. Un cluster con concorrenza elevata supporta solo linguaggi SQL, Python e R. I cluster con concorrenza elevata offrono tutti i vantaggi dei pool serverless, consentendo allo stesso tempo flessibilità nella configurazione di Spark e delle risorse. Per altre informazioni, vedere Cluster a concorrenza elevata.
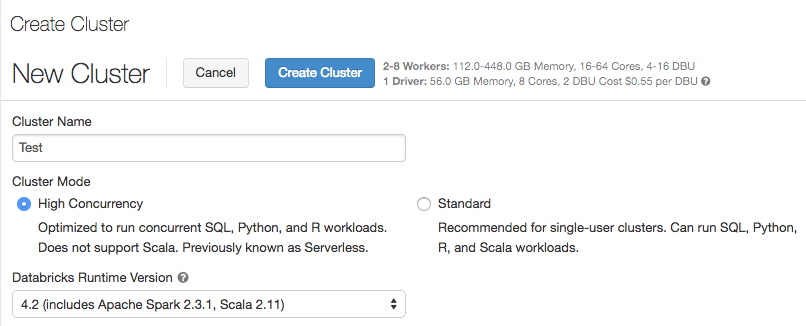
Table controllo di accesso
19-24 luglio 2018: versione 2.76
La casella di controllo di Access Control Table è disponibile solo per i cluster a concorrenza elevata.

Tipi di nodo di cluster non disponibili disattivati
3-10 luglio 2018: versione 2.75
I tipi di nodo del cluster che non sono disponibili per la tua sottoscrizione e regione sono ora disattivati e non è possibile select durante la creazione di un cluster.
Supporto di R Markdown
3-10 luglio 2018: versione 2.75
I notebook R di Azure Databricks possono essere esportati in formato R Markdown e i documenti R Markdown possono essere importati come notebook di Azure Databricks.
Riprogettazione della home page, con la possibilità di rilasciare i file per importare i dati
3-10 luglio 2018: versione 2.75
La nuova home page aggiunge un'interfaccia più pulita e più semplice, con collegamenti a un'esercitazione introduttiva migliorata e la possibilità di trascinare i file per importare i dati. Visualizzare , esplorare e creare tables in DBFS.
Comportamento predefinito dei widget
3-10 luglio 2018: versione 2.75
Il comportamento di esecuzione predefinito quando viene selezionato un nuovo valore per un widget è ora Do Nothing.The default execution behavior when a new value is selected for a widget is now to Do Nothing. È necessario update le impostazioni del widget se si vuole rieseguire un notebook completo o solo i comandi correlati al valore quando si modifica un valore del widget. Vedere Configurare le impostazioni di widget.
Table interfaccia utente di creazione
3-10 luglio 2018: versione 2.75
Quando si crea un table nell'interfaccia utente, è ora selectAggiungi dati dalla pagina Dati.
![]()
Vedere Esplorare e creare tables in DBFS.
Importazione di dati JSON a più righe
3-10 luglio 2018: versione 2.75
È ora possibile importare file di dati JSON su più righe durante la creazione di tables. In precedenza, i file di dati JSON dovevano essere appiattiti a una riga. Vedi esplora e crea tables in DBFS.