Luglio 2019
Queste funzionalità e i miglioramenti della piattaforma Azure Databricks sono stati rilasciati a luglio 2019.
Nota
Le versioni vengono gestite in staging. L'account Azure Databricks potrebbe non essere aggiornato fino a una settimana dopo la data di rilascio iniziale.
Prossimamente: Databricks 6.0 non supporterà Python 2
In previsione della prossima fine del ciclo di vita di Python 2, annunciata per il 2020, Python 2 non sarà supportato in Databricks Runtime 6.0. Le versioni precedenti di Databricks Runtime continueranno a supportare Python 2. Prevediamo di rilasciare Databricks Runtime 6.0 più avanti nel 2019.
Precaricare la versione di Databricks Runtime in istanze inattive del pool
30 luglio - 6 agosto 2019: versione 2.103
Adesso è possibile velocizzare l'avvio del cluster supportato dal pool selezionando una versione di Databricks Runtime da caricare nelle istanze inattive nel pool. Il campo nell'interfaccia utente del pool è denominato Versione di Spark precaricata.

I tag di cluster e di pool personalizzati funzionano in modo ottimale se usati insieme
30 luglio - 6 agosto 2019: versione 2.103
All'inizio di questo mese, Azure Databricks ha introdotto i pool, un set di istanze inattive che consentono di avviare rapidamente i cluster. Nella versione originale, i cluster supportati dal pool hanno ereditato i tag predefiniti e personalizzati dalla configurazione del pool e non è stato possibile modificare questi tag a livello di cluster. Adesso è possibile configurare tag personalizzati specifici di un cluster supportato dal pool e tale cluster applicherà tutti i tag personalizzati, sia ereditati dal pool che assegnati a tale cluster in modo specifico. Non è possibile aggiungere un tag personalizzato specifico del cluster con lo stesso nome di chiave di un tag personalizzato ereditato da un pool, ovvero non è possibile eseguire l'override di un tag personalizzato ereditato dal pool. Per informazioni dettagliate, vedere Tag dei pool.
MLflow 1.1 presenta diversi miglioramenti dell’interfaccia utente e delle API
30 luglio - 6 agosto 2019: versione 2.103
MLflow 1.1 introduce diverse nuove funzionalità per migliorare l'usabilità dell'interfaccia utente e delle API:
L'interfaccia utente della panoramica delle esecuzioni consente ora di esplorare più pagine di esecuzioni se il numero di esecuzioni supera 100. Dopo la centesima esecuzione, fare clic sul pulsante Carica altro per caricare le 100 esecuzioni successive.
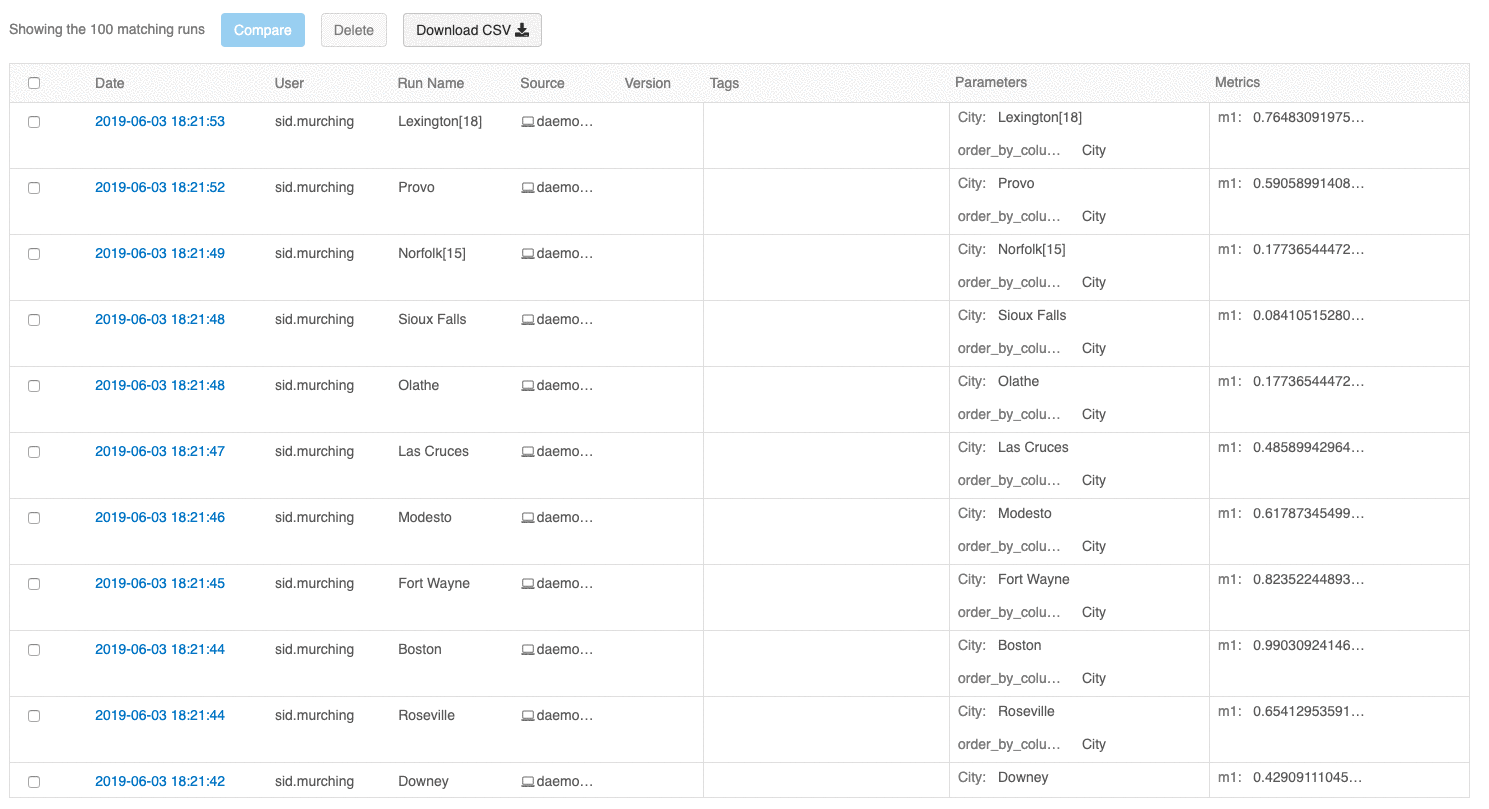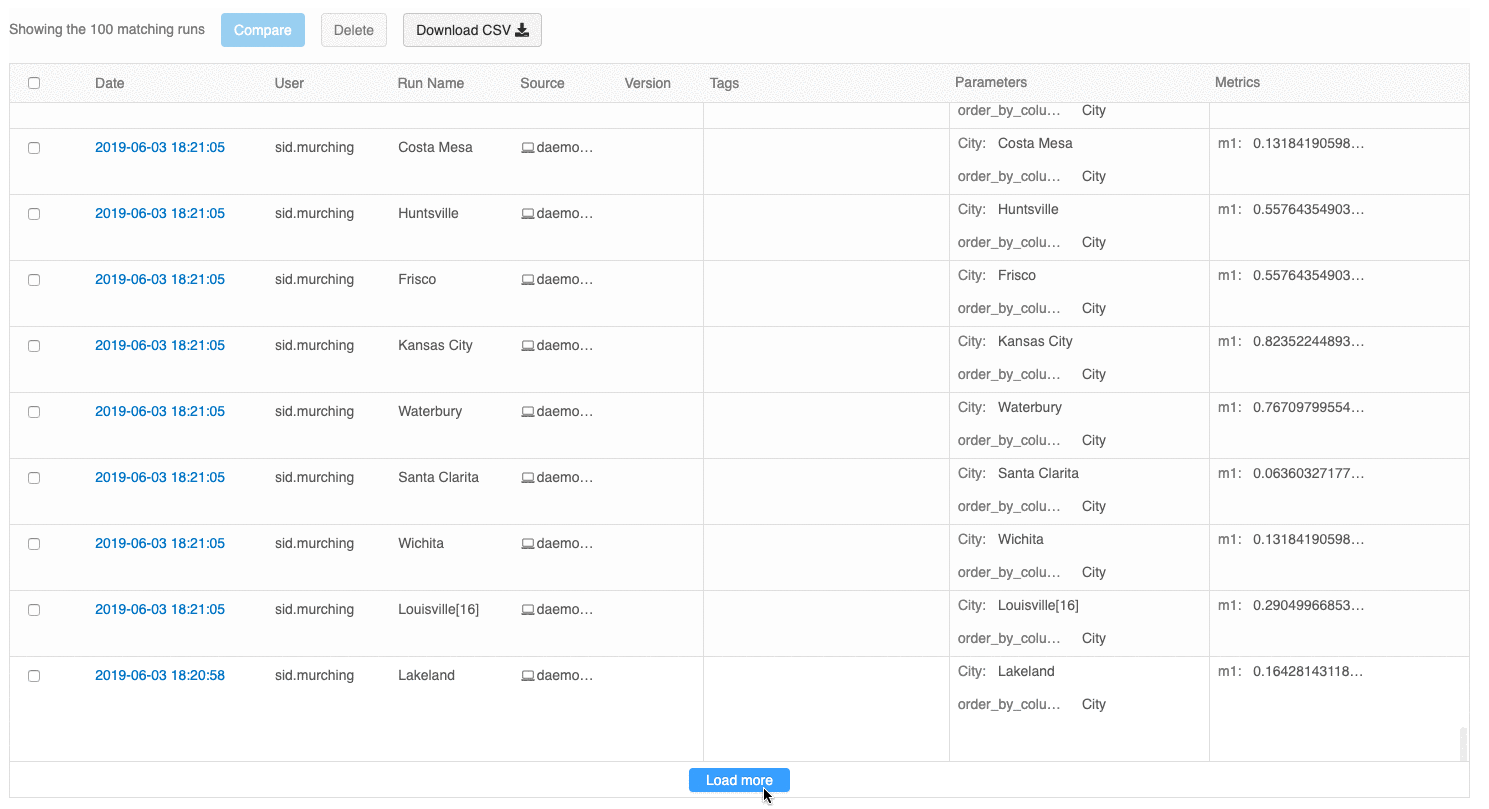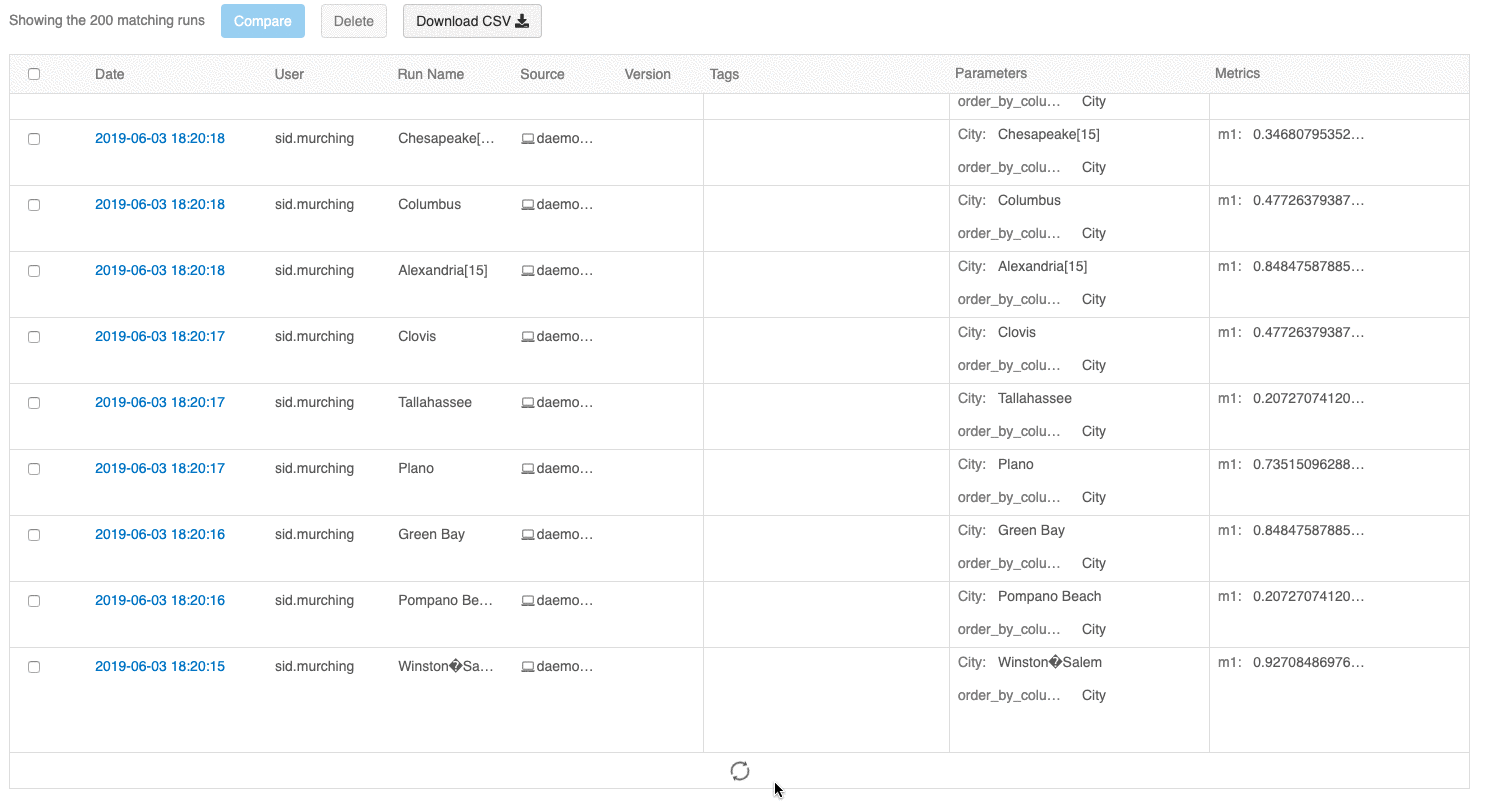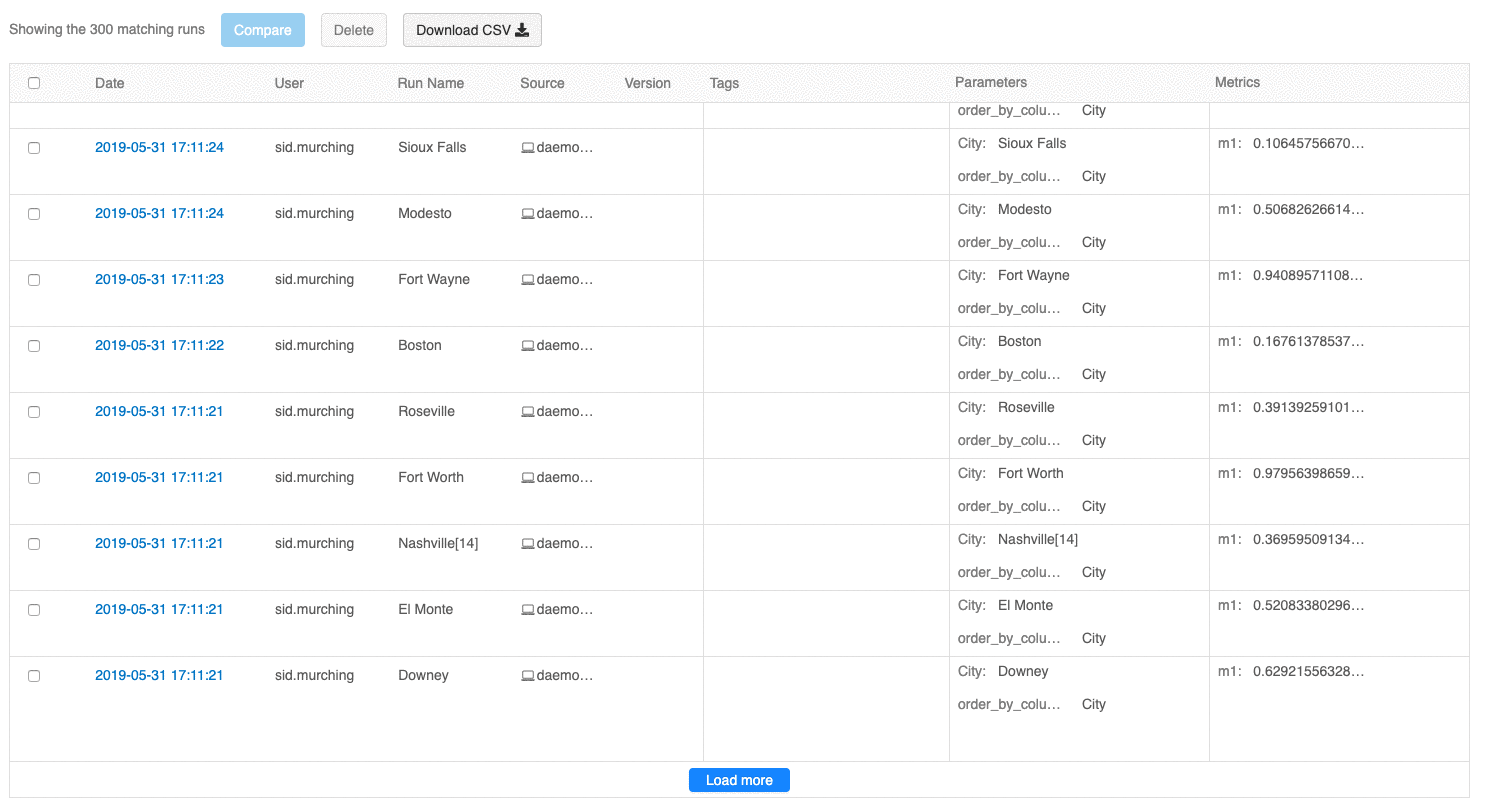
L'interfaccia utente di confronto delle esecuzioni fornisce ora un tracciato di coordinate parallele. Il tracciato consente di osservare le relazioni tra un set n-dimensionale di parametri e metriche. Visualizza tutte le esecuzioni come righe codificate a colori in base al valore di una metrica (ad esempio, accuratezza) e mostra i valori dei parametri su cui è stata eseguita ogni esecuzione.

Adesso è possibile aggiungere e modificare tag dall'interfaccia utente della panoramica dell'esecuzione e visualizzare i tag nella visualizzazione di ricerca dell'esperimento.
La nuova API MLflowContext consente di creare e registrare le esecuzioni in modo simile all'API Python. Questa API è in contrasto con l'API
MlflowClientdi basso livello esistente, che esegue semplicemente il wrapping delle API REST.Adesso è possibile eliminare i tag dalle esecuzioni di MLflow usando l'API DeleteTag.
Per informazioni dettagliate, vedere il post di blog su MLflow 1.1. Per l'elenco completo delle funzionalità e delle correzioni, vedere il log delle modifiche di MLflow.
Il rendering dei dataframe Pandas viene eseguito come in Jupyter
30 luglio - 6 agosto 2019: versione 2.103
Adesso, quando un dataframe pandas viene chiamato, eseguirà il rendering come in Jupyter.
Nuove aree
30 luglio 2019
Azure Databricks è ora disponibile nelle seguenti aree aggiuntive:
- Corea centrale
- Sudafrica settentrionale
Limite di connessione al metastore aggiornato
16 luglio - 23 luglio 2019: versione 2.102
Le nuove aree di lavoro di Azure Databricks in eastus, eastus2, centralus, westus, westus2, westeurope, northeurope avranno un limite di connessione metastore più elevato di 250. Le aree di lavoro esistenti continueranno a usare il metastore corrente senza interruzioni e continueranno ad avere un limite di connessione pari a 100.
Impostare le autorizzazioni per i pool (anteprima pubblica)
16 luglio - 23 luglio 2019: versione 2.102
L'interfaccia utente del pool adesso supporta l'impostazione delle autorizzazioni per chi può gestire i pool e chi può collegare i cluster ai pool.
Per informazioni dettagliate, vedere Autorizzazioni dei pool.
Databricks Runtime 5.5 per Machine Learning
15 luglio 2019
Databricks Runtime 5.5 ML è basato su Databricks Runtime 5.5 LTS (EoS). Contiene molte delle più diffuse librerie di Machine Learning, tra cui TensorFlow, PyTorch, Keras e XGBoost, e fornisce il training di TensorFlow distribuito usando Horovod.
Questa versione include le seguenti nuove funzionalità e migliorie:
- Aggiunta del pacchetto Python MLflow 1.0
- Librerie di apprendimento automatico aggiornate
- Aggiornamento di Tensorflow da 1.12.0 a 1.13.1
- PyTorch aggiornato dalla versione 0.4.1 alla versione 1.1.0
- scikit-learn aggiornato dalla versione 0.19.1 alla versione 0.20.3
- Operazione a nodo singolo per HorovodRunner
Per informazioni dettagliate, vedere Databricks Runtime 5.5 LTS for ML (EoS).
Databricks Runtime 5.5
15 luglio 2019
Databricks Runtime 5.5 è ora disponibile. Databricks Runtime 5.5 include Apache Spark 2.4.3, le librerie aggiornate di Python, R, Java e Scala e le seguenti nuove funzionalità:
- Ottimizzazione automatica della disponibilità generale di Delta Lake su Azure Databricks
- Delta Lake su Azure Databricks ha migliorato le prestazioni delle query di aggregazione min, max e count
- Pipeline di inferenza del modello più veloci con un'origine dati di file binari migliorata e un funzione UDF pandas con iteratore scalare (anteprima pubblica).
- API dei segreti nei notebook R
Per informazioni dettagliate, vedere Databricks Runtime 5.5 LTS (EoS).
Mantenere un pool di istanze in standby per l’avvio rapido del cluster (anteprima pubblica)
9 luglio - 11 luglio 2019: versione 2.101
Per ridurre il tempo di avvio del cluster, Azure Databricks adesso supporta il collegamento di un cluster a un pool predefinito di istanze inattive. Quando è collegato a un pool, un cluster alloca i relativi nodi driver e di lavoro dal pool. Se il pool non ha alcuna istanza inattiva, si espande allocando una nuova istanza dal provider cloud per accogliere la richiesta del cluster. Quando un cluster collegato viene terminato, le istanze usate vengono restituite al pool e possono essere riutilizzate da un cluster diverso.
Azure Databricks non addebita unità DBU quando le istanze sono inattive nel pool. Viene applicata la fatturazione del provider di istanze. Vedere Prezzi.
Per informazioni dettagliate, vedere Guida di riferimento per la configurazione del pool.
Metriche Ganglia
9 luglio - 11 luglio 2019: versione 2.101
Ganglia è un sistema di monitoraggio distribuito scalabile, ora disponibile nei cluster di Azure Databricks. Le metriche Ganglia aiutano a monitorare le prestazioni e l'integrità del cluster. È possibile accedere alle metriche Ganglia dalla pagina dei dettagli del cluster:
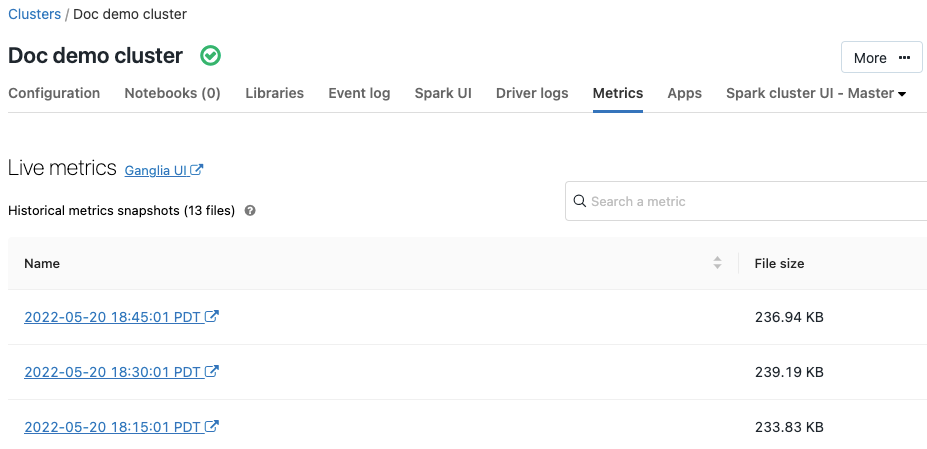
Per informazioni dettagliate sull'uso e sulla configurazione delle metriche, vedere Metriche Ganglia.
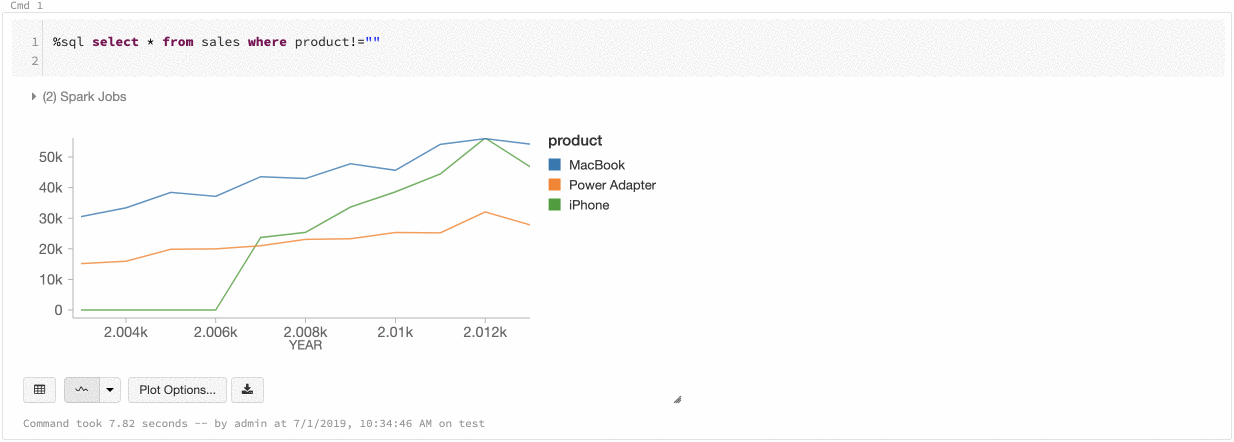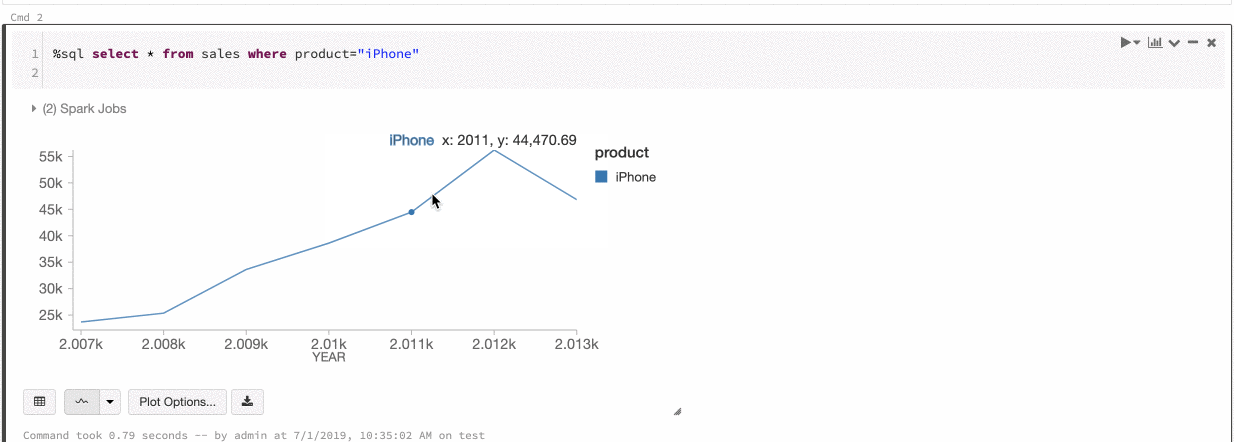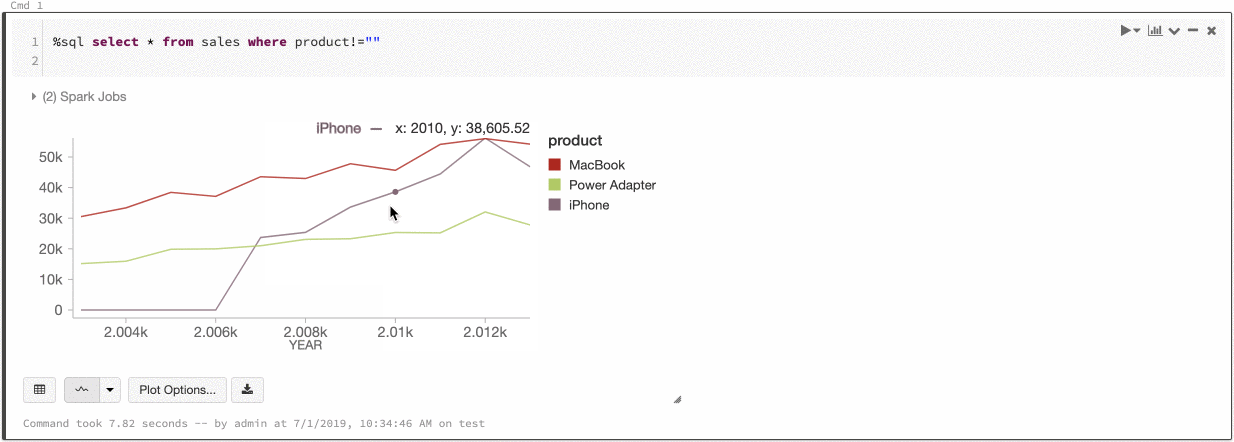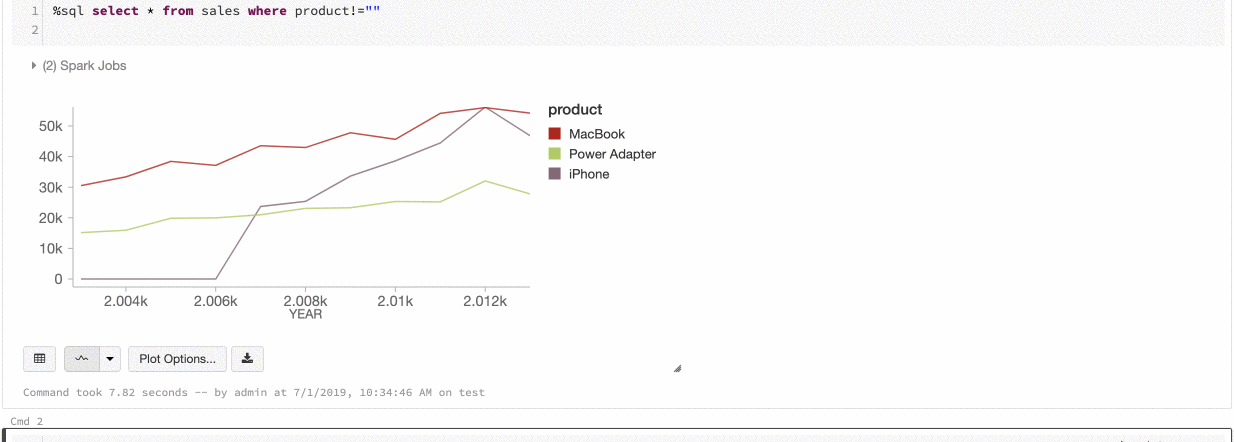
Colore di una serie globale
9 luglio - 11 luglio 2019: versione 2.101
È ora possibile specificare che i colori di una serie devono essere coerenti in tutti i grafici del notebook. Vedere Coerenza dei colori tra grafici.