sparklyr
Azure Databricks supporta sparklyr in notebook, processi e RStudio Desktop. Questo articolo descrive come usare sparklyr e fornisce script di esempio che è possibile eseguire. Per altre informazioni, vedere Interfaccia R in Apache Spark .
Requisiti
Azure Databricks distribuisce la versione stabile più recente di sparklyr con ogni versione di Databricks Runtime. È possibile usare sparklyr nei notebook di Azure Databricks R o all'interno di RStudio Server ospitato in Azure Databricks importando la versione installata di sparklyr.
In RStudio Desktop, Databricks Connect consente di connettere sparklyr dal computer locale ai cluster Azure Databricks ed eseguire codice Apache Spark. Usare sparklyr e RStudio Desktop con Databricks Connect.
Connettere sparklyr ai cluster di Azure Databricks
Per stabilire una connessione sparklyr, è possibile usare "databricks" come metodo di connessione in spark_connect().
Non sono necessari parametri aggiuntivi spark_connect(), né è necessario chiamare spark_install() perché Spark è già installato in un cluster di Azure Databricks.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
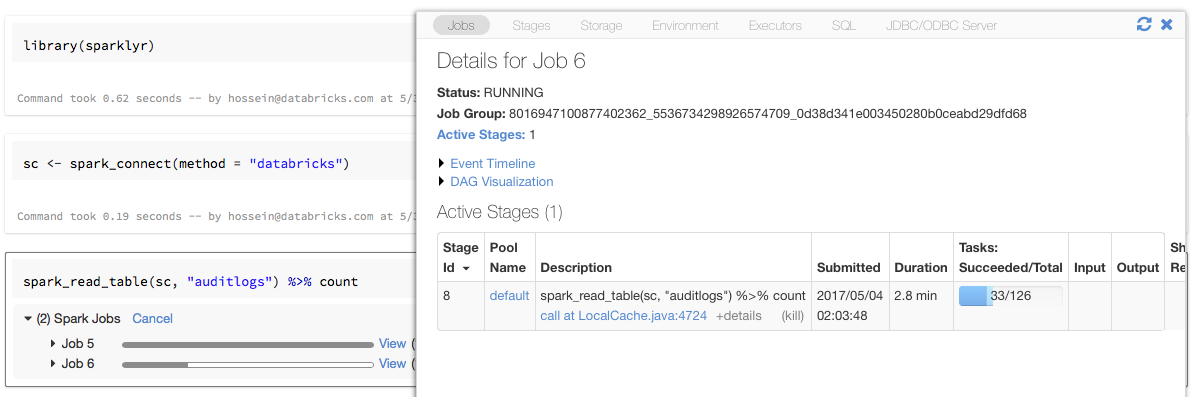
Indicatori di stato e interfaccia utente spark con sparklyr
Se si assegna l'oggetto connessione sparklyr a una variabile denominata sc come nell'esempio precedente, nel notebook verranno visualizzate barre di stato Spark dopo ogni comando che attiva i processi Spark.
È anche possibile fare clic sul collegamento accanto all'indicatore di stato per visualizzare l'interfaccia utente Spark associata al processo Spark specificato.
Usare sparklyr
Dopo aver installato sparklyr e stabilito la connessione, tutte le altre API sparklyr funzionano normalmente. Per alcuni esempi, vedere il notebook di esempio.
sparklyr viene in genere usato insieme ad altri pacchetti tidyverse, ad esempio dplyr. La maggior parte di questi pacchetti è preinstallata in Databricks per praticità. È sufficiente importarli e iniziare a usare l'API.
Usare sparklyr e SparkR insieme
SparkR e sparklyr possono essere usati insieme in un singolo notebook o processo. È possibile importare SparkR insieme a sparklyr e usare la relativa funzionalità. Nei notebook di Azure Databricks, la connessione SparkR è preconfigurata.
Alcune delle funzioni in SparkR mascherano una serie di funzioni in dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Se si importa SparkR dopo aver importato dplyr, è possibile fare riferimento alle funzioni in dplyr usando i nomi completi, ad esempio dplyr::arrange().
Analogamente, se si importa dplyr dopo SparkR, le funzioni in SparkR vengono mascherate da dplyr.
In alternativa, è possibile scollegare in modo selettivo uno dei due pacchetti mentre non è indispensabile.
detach("package:dplyr")
Vedere anche Confronto tra SparkR e sparklyr.
Usare sparklyr nei processi spark-submit
È possibile eseguire script che usano sparklyr in Azure Databricks come processi spark-submit, con modifiche minime al codice. Alcune delle istruzioni precedenti non si applicano all'uso di sparklyr nei processi spark-submit in Azure Databricks. In particolare, è necessario fornire l'URL master Spark a spark_connect. Ad esempio:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Funzionalità non supportate
Azure Databricks non supporta metodi sparklyr come spark_web() e spark_log() che richiedono un browser locale. Tuttavia, poiché l'interfaccia utente di Spark è incorporata in Azure Databricks, è possibile esaminare facilmente processi e log Spark.
Vedere Driver di calcolo e log dei ruoli di lavoro.