Come usare Flink/Delta Connector
Nota
Azure HDInsight su AKS verrà ritirato il 31 gennaio 2025. Prima del 31 gennaio 2025, sarà necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare interruzioni improvvise dei carichi di lavoro. I cluster rimanenti nella sottoscrizione verranno arrestati e rimossi dall’host.
Solo il supporto di base sarà disponibile fino alla data di ritiro.
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le Condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti nella Community di Azure HDInsight.
Usando Apache Flink e Delta Lake insieme, è possibile creare un'architettura data lakehouse affidabile e scalabile. Flink/Delta Connector consente di scrivere dati in tabelle Delta con transazioni ACID ed elaborazione di tipo "Exactly-Once". Ciò significa che i flussi di dati sono coerenti e senza errori, anche se si riavvia la pipeline Flink da un checkpoint. Flink/Delta Connector garantisce che i dati non siano persi o duplicati e che corrispondano alla semantica Flink.
Questo articolo illustra come usare Flink-Delta Connector.
- Leggere i dati dalla tabella delta.
- Scrivere i dati in una tabella delta.
- Eseguirne una query in Power BI.
Informazioni su Flink/Delta Connector
Flink/Delta Connector è una libreria JVM per leggere e scrivere dati dalle applicazioni Apache Flink alle tabelle Delta che usano la libreria JVM autonoma Delta. Il connettore fornisce garanzie di recapito "Exactly-Once".
Flink/Delta Connector include:
DeltaSink per la scrittura di dati da Apache Flink a una tabella Delta. DeltaSource per la lettura di tabelle Delta tramite Apache Flink.
Apache Flink-Delta Connector include:
A seconda della versione del connettore, è possibile usarlo con le versioni di Apache Flink seguenti:
Connector's version Flink's version
0.4.x (Sink Only) 1.12.0 <= X <= 1.14.5
0.5.0 1.13.0 <= X <= 1.13.6
0.6.0 X >= 1.15.3
0.7.0 X >= 1.16.1 --- We use this in Flink 1.17.0
Prerequisiti
- Cluster HDInsight Flink 1.17.0 nel servizio Azure Kubernetes
- Flink-Delta Connector 0.7.0
- Usare MSI per accedere ad ADLS Gen2
- IntelliJ per lo sviluppo
Leggere i dati dalla tabella delta
L'origine delta può funzionare in una delle due modalità descritte di seguito.
Modalità delimitata adatta per i processi batch, in cui si vuole leggere il contenuto della tabella Delta solo per una versione di tabella specifica. Creare un'origine di questa modalità usando l'API DeltaSource.forBoundedRowData.
Modalità continua adatta per i processi di streaming, in cui si vuole controllare continuamente la tabella Delta per rilevare le nuove modifiche e versioni. Creare un'origine di questa modalità usando l'API DeltaSource.forContinuousRowData.
Esempio: creazione di origine per la tabella Delta per leggere tutte le colonne in modalità delimitata. Adatto per i processi batch. In questo esempio viene caricata la versione più recente della tabella.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
Scrittura nel sink Delta
Il sink delta espone attualmente le metriche di Flink seguenti:

Creazione del sink per tabelle non partizionate
In questo esempio viene illustrato come creare un oggetto DeltaSink e collegarlo a un org.apache.flink.streaming.api.datastream.DataStreamesistente.
import io.delta.flink.sink.DeltaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
Codice completo
Legge i dati da una tabella delta e un sink in un'altra tabella delta.
package contoso.example;
import io.delta.flink.sink.DeltaSink;
import io.delta.flink.source.DeltaSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
public class DeltaSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
// Execute the Flink job
env.execute("Delta datasource and sink Example");
}
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}
Maven Pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkDeltaDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop-version>3.3.4</hadoop-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-standalone_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-flink</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Creare il pacchetto per il file JAR e inviarlo al cluster Flink per l'esecuzione
Caricare il file JAR in ABFS.

Passare le informazioni sul file JAR del processo nel cluster AppMode.
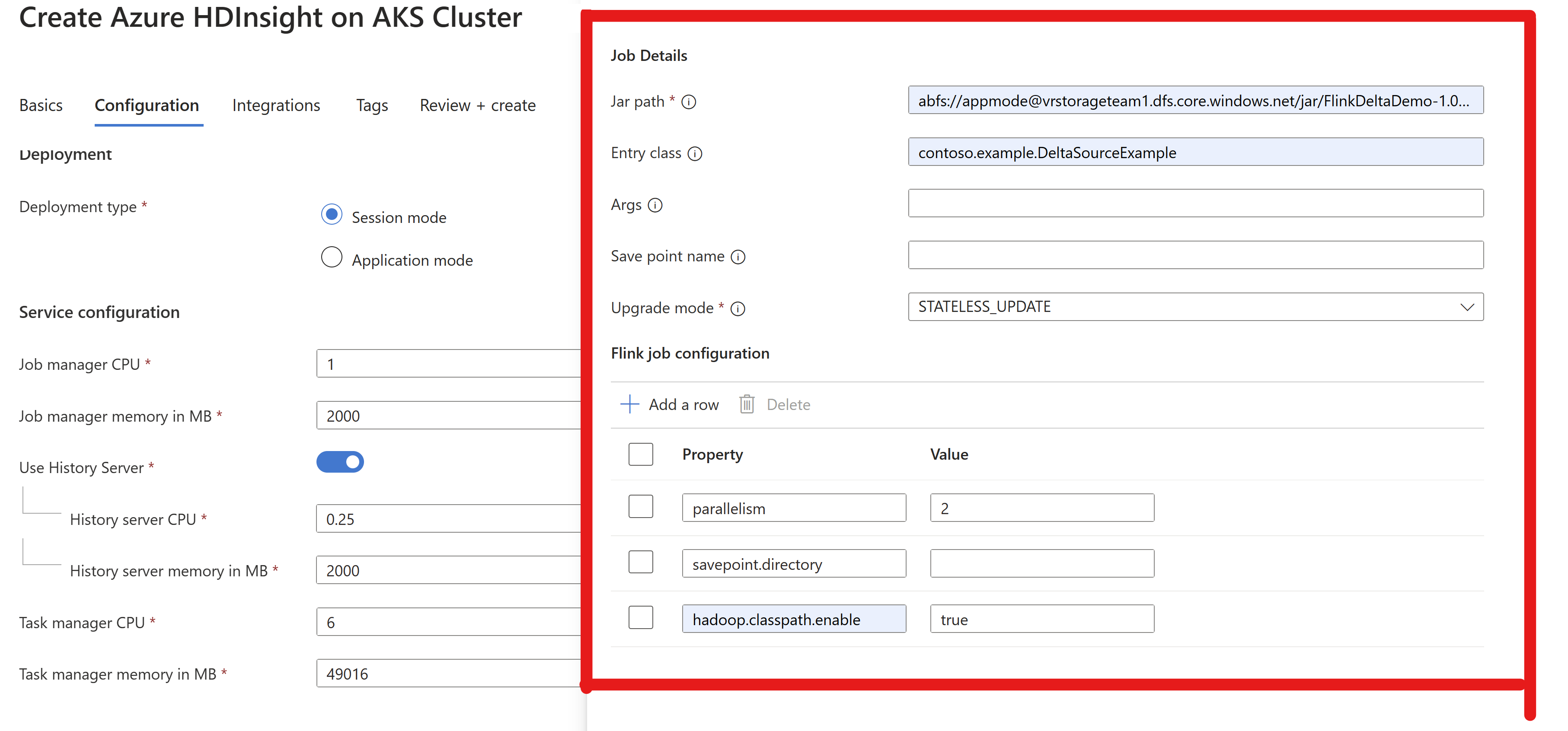
Nota
Abilitare sempre
hadoop.classpath.enabledurante la lettura/scrittura in ADLS.Inviare il cluster. Dovrebbe essere possibile visualizzare il processo nell'interfaccia utente di Flink.

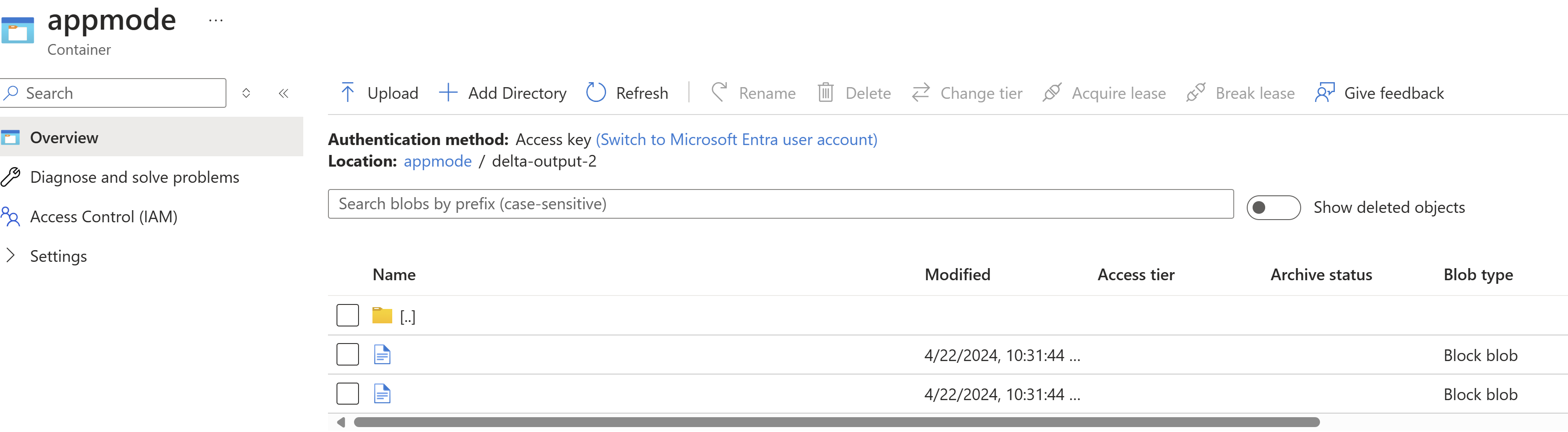
Trovare i risultati in ADLS.




Integrazione di Power BI
Quando i dati si trovano nel sink delta, è possibile eseguire la query in Power BI Desktop e creare un report.
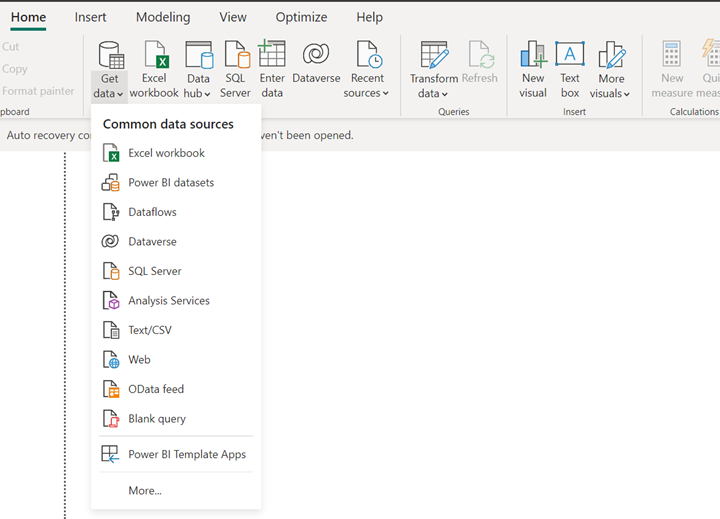
Aprire Power BI Desktop per ottenere i dati usando il connettore ADLS Gen2.
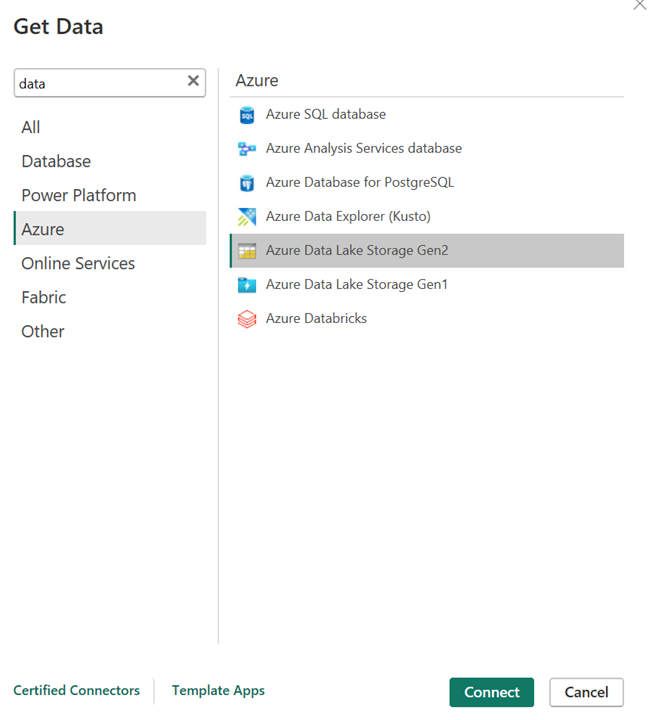
URL dell'account di archiviazione.

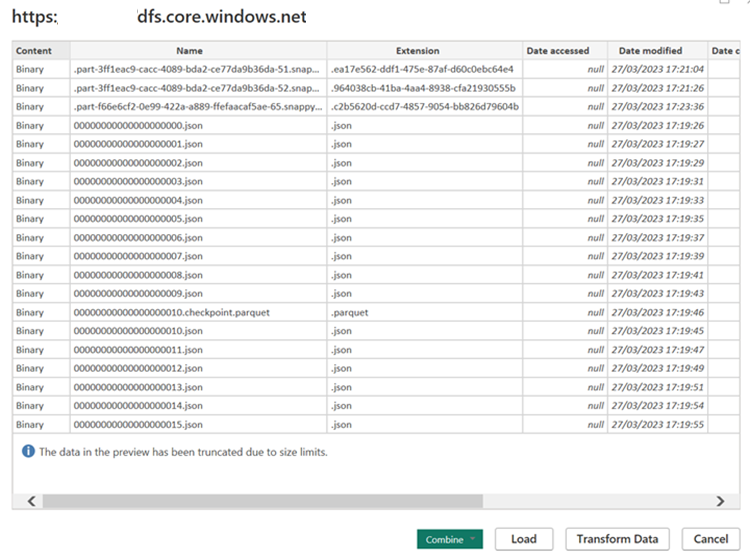
Creare una query M per l'origine e richiamare la funzione, che esegue query sui dati dall'account di archiviazione.
Quando i dati sono immediatamente disponibili, è possibile creare report.
Riferimenti
- Apache, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi di Apache Software Foundation (ASF).