Usare funzioni C# definite dall'utente con Apache Hive e Apache Pig in Apache Hadoop in HDInsight
Informazioni su come usare funzioni definite dall'utente C# con Apache Hive e Apache Pig in HDInsight.
Importante
I passaggi descritti in questo documento funzionano con i cluster HDInsight basati su Linux. Linux è l'unico sistema operativo usato in HDInsight versione 3.4 o successiva. Per altre informazioni, vedere l'articolo sul controllo delle versioni del componente di HDInsight.
Sia Hive sia Pig sono in grado di passare i dati alle applicazioni esterne per l'elaborazione. Questo processo è noto come streaming. Quando si usa un'applicazione .NET, i dati vengono passati all'applicazione in STDIN e l'applicazione restituisce i risultati in STDOUT. Per leggere e scrivere da STDIN e STDOUT, è possibile usare Console.ReadLine() e Console.WriteLine() da un'applicazione console.
Prerequisiti
Una familiarità nello scrivere e nel compilare il codice C# destinato a .NET Framework 4.5.
Usare qualsiasi IDE desiderato. È consigliabile usare Visual Studio o Visual Studio Code. I passaggi descritti in questo documento usano Visual Studio 2019.
Un modo per caricare i file con estensione exe nel cluster ed eseguire i processi Pig e Hive. È consigliabile usare Strumenti Data Lake per Visual Studio, Azure PowerShell e l'interfaccia della riga di comando di Azure. La procedura in questo documento usa gli strumenti Data Lake per Visual Studio per caricare i file ed eseguire l'esempio di query Hive.
Per informazioni su altri modi per eseguire query Hive, vedere Che cos'è Apache Hive e HiveQL in Azure HDInsight?.
Un cluster Hadoop in HDInsight. Per altre informazioni sulla creazione di un cluster, vedere Creare cluster HDInsight.
.NET su HDInsight
Per eseguire applicazioni .NET, i cluster HDInsight basati su Linux usano Mono (https://mono-project.com)). La versione Mono 4.2.1 è inclusa nella versione 3.6 di HDInsight.
Per altre informazioni sulla compatibilità Mono con le versioni di .NET Framework, vedere il documento relativo alla compatibilità Mono.
Per altre informazioni sulla versione di .NET Framework e Mono incluse nelle versioni di HDInsight, vedere Versioni dei componenti HDInsight.
Creare i progetti C#
Le sezioni seguenti descrivono come creare un progetto C# in Visual Studio per una funzione definita dall'utente Apache Hive e una funzione definita dall'utente Apache Pig.
UDF Apache Hive
Per creare un progetto C# per una funzione definita dall'utente Apache Hive:
Avviare Visual Studio.
Selezionare Crea un nuovo progetto.
Nella finestra Crea un nuovo progetto scegliere il modello App console (.NET Framework) (versione C#). Quindi seleziona Avanti.
Nella finestra Configura il nuovo progetto immettere un nome progetto HiveCSharp e passare a o creare un percorso in cui salvare il nuovo progetto. Selezionare Crea.
Nell'IDE di Visual Studio sostituire il contenuto di Program.cs con il codice seguente:
using System; using System.Security.Cryptography; using System.Text; using System.Threading.Tasks; namespace HiveCSharp { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Parse the string, trimming line feeds // and splitting fields at tabs line = line.TrimEnd('\n'); string[] field = line.Split('\t'); string phoneLabel = field[1] + ' ' + field[2]; // Emit new data to stdout, delimited by tabs Console.WriteLine("{0}\t{1}\t{2}", field[0], phoneLabel, GetMD5Hash(phoneLabel)); } } /// <summary> /// Returns an MD5 hash for the given string /// </summary> /// <param name="input">string value</param> /// <returns>an MD5 hash</returns> static string GetMD5Hash(string input) { // Step 1, calculate MD5 hash from input MD5 md5 = System.Security.Cryptography.MD5.Create(); byte[] inputBytes = System.Text.Encoding.ASCII.GetBytes(input); byte[] hash = md5.ComputeHash(inputBytes); // Step 2, convert byte array to hex string StringBuilder sb = new StringBuilder(); for (int i = 0; i < hash.Length; i++) { sb.Append(hash[i].ToString("x2")); } return sb.ToString(); } } }Nella barra dei menu selezionare Compila>soluzione di compilazione per compilare il progetto.
Chiudere la soluzione.
UDF Apache Pig
Per creare un progetto C# per una funzione definita dall'utente Apache Hive:
Aprire Visual Studio.
Nella finestra iniziale selezionare Crea un nuovo progetto.
Nella finestra Crea un nuovo progetto scegliere il modello App console (.NET Framework) (versione C#). Quindi seleziona Avanti.
Nella finestra Configura il nuovo progetto immettere un nome di progetto PigUDF e passare a o creare un percorso in cui salvare il nuovo progetto. Selezionare Crea.
Nell'IDE di Visual Studio sostituire il contenuto di Program.cs con il codice seguente:
using System; namespace PigUDF { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Fix formatting on lines that begin with an exception if(line.StartsWith("java.lang.Exception")) { // Trim the error info off the beginning and add a note to the end of the line line = line.Remove(0, 21) + " - java.lang.Exception"; } // Split the fields apart at tab characters string[] field = line.Split('\t'); // Put fields back together for writing Console.WriteLine(String.Join("\t",field)); } } } }Questo codice analizza le righe inviate da Pig e riformatta quelle che iniziano con
java.lang.Exception.Nella barra dei menu scegliere Compila>soluzione di compilazione per compilare il progetto.
Lasciare aperta la soluzione.
Caricare nella risorsa di archiviazione
Caricare quindi le applicazioni Hive e Pig UDF nell'archiviazione in un cluster HDInsight.
In Visual Studio passare a Visualizza>Esplora server.
In Esplora server fare clic con il pulsante destro del mouse su Azure, scegliere Connetti alla sottoscrizione di Microsoft Azure e completare il processo di accesso.
Espandere il cluster HDInsight in cui si desidera distribuire l'applicazione. Viene elencata una voce con il testo (Account di archiviazione predefinito).
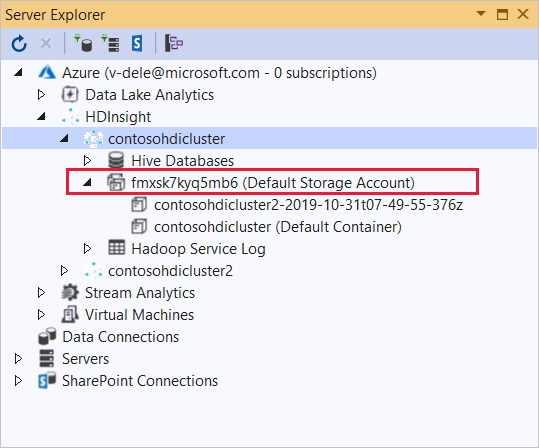
Se questa voce può essere espansa, si usa un account Archiviazione di Azure come risorsa di archiviazione predefinita per il cluster. Per visualizzare i file nel percorso di archiviazione predefinito per il cluster, espandere la voce e quindi fare doppio clic su (Contenitore predefinito).
Se questa voce non può essere espansa, si usa Azure Data Lake Storage come risorsa di archiviazione predefinita per il cluster. Per visualizzare i file nel percorso di archiviazione predefinito per il cluster, fare doppio clic sulla voce (Account di archiviazione predefinito).
Per caricare i file con estensione .exe, usare uno dei metodi seguenti:
Se si utilizza un account di archiviazione di Azure, selezionare l'icona Carica BLOB.

Nella finestra di dialogo Carica nuovo file, in Nome file, selezionare Sfoglia. Nella finestra di dialogo Carica BLOB passare alla
bin\debugcartella per il progetto HiveCSharp e quindi scegliere il file HiveCSharp.exe. Infine, selezionare Apri e quindi OK per completare il caricamento.Se si usa Azure Data Lake Storage, fare clic con il pulsante destro del mouse su un'area vuota nell'elenco di file e quindi scegliere Carica. Infine, scegliere il file HiveCSharp.exe e selezionare Apri.
Una volta terminato il caricamento di HiveCSharp.exe, ripetere il processo di caricamento per il file PigUDF.exe.
Eseguire una query Apache Hive
A questo punto è possibile eseguire una query Hive che usa l'applicazione UDF Hive.
In Visual Studio passare a Visualizza>Esplora server.
Espandere Azure e quindi HDInsight.
Fare clic con il pulsante destro del mouse sul cluster in cui è stata distribuita l'applicazione HiveCSharp, quindi selezionare Scrivi una query Hive.
Per la query Hive usare il testo seguente:
-- Uncomment the following if you are using Azure Storage -- add file wasbs:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen1 -- add file adl:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen2 -- add file abfs:///HiveCSharp.exe; SELECT TRANSFORM (clientid, devicemake, devicemodel) USING 'HiveCSharp.exe' AS (clientid string, phoneLabel string, phoneHash string) FROM hivesampletable ORDER BY clientid LIMIT 50;Importante
Rimuovere il commento dell'istruzione
add fileche corrisponde al tipo di archiviazione predefinita usata per il cluster.Questa query seleziona i
clientidcampi ,devicemakeedevicemodeldahivesampletablee quindi passa i campi all'applicazione HiveCSharp.exe . La query si aspetta che l'applicazione restituisca tre campi, che vengono archiviati comeclientid,phoneLabelephoneHash. La query prevede anche di trovare HiveCSharp.exe nella radice del contenitore di archiviazione predefinito.Impostare l'opzione interattiva predefinita su Batch e quindi selezionare Invia per inviare il processo al cluster HDInsight. Viene visualizzata la finestra Hive Job Summary (Riepilogo processo Hive).
Selezionare Aggiorna per aggiornare il riepilogo fino a quando lo stato del processo non viene modificato in Completato. Per visualizzare l'output del processo, selezionare Output processo.
Eseguire un processo Apache Pig
È anche possibile eseguire un processo Pig che usa l'applicazione Pig UDF.
Connettersi al cluster HDInsight usando SSH. Ad esempio, eseguire il comando
ssh sshuser@<clustername>-ssh.azurehdinsight.net. Per altre informazioni, vedere Usare SSH conHDInsight.Usare il comando seguente per avviare la riga di comando Pig:
pigViene visualizzato un prompt
grunt>.Immettere il codice seguente per eseguire un processo Pig che usa l'applicazione .NET Framework:
DEFINE streamer `PigUDF.exe` CACHE('/PigUDF.exe'); LOGS = LOAD '/example/data/sample.log' as (LINE:chararray); LOG = FILTER LOGS by LINE is not null; DETAILS = STREAM LOG through streamer as (col1, col2, col3, col4, col5); DUMP DETAILS;L'istruzione
DEFINEcrea un alias distreamerper l'applicazione PigUDF.exe eCACHElo carica dalla risorsa di archiviazione predefinita per il cluster. Successivamente,streamerviene usato con l'operatoreSTREAMper elaborare le singole righe contenute inLOGe restituire i dati come una serie di colonne.Nota
Il nome dell'applicazione usato per lo streaming deve essere racchiuso tra il
`carattere (backtick) quando viene eseguito l'alias e il'carattere (virgoletta singola) quando viene usato conSHIP.Dopo aver immesso l'ultima riga, il processo dovrebbe iniziare. L'output restituito è simile al testo seguente:
(2019-07-15 16:43:25 SampleClass5 [WARN] problem finding id 1358451042 - java.lang.Exception) (2019-07-15 16:43:25 SampleClass5 [DEBUG] detail for id 1976092771) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1317358561) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1737534798) (2019-07-15 16:43:25 SampleClass7 [DEBUG] detail for id 1475865947)Usare
exitper uscire da pig.
Passaggi successivi
In questo documento si è appreso come usare un'applicazione .NET Framework da Hive e Pig in HDInsight. Per informazioni su come usare Python con Hive e Pig, vedere Usare Python con Apache Hive e Apache Pig in HDInsight.
Per altri modi per usare Hive e per informazioni sull'uso di MapReduce, vedere gli articoli seguenti: