Informazioni su Apache Hadoop in Azure HDInsight
Apache Hadoop era il framework open source originale per l'elaborazione distribuita e l'analisi di set di Big Data in cluster. L'ecosistema Hadoop include software e utilità correlate, tra cui Apache Hive, Apache HBase, Spark, Kafka e molti altri.
Azure HDInsight è un servizio di analisi open source completamente gestito e ad ampio spettro nel cloud per le aziende. Il tipo di cluster Apache Hadoop in Azure HDInsight consente di usare Apache HDFS (Hadoop Distributed File System), la gestione delle risorse Apache Hadoop YARN e un semplice modello di programmazione MapReduce per elaborare e analizzare i dati batch in parallelo. I cluster Hadoop in HDInsight sono compatibili con Azure Data Lake Storage Gen2.
Per i componenti dello stack di tecnologie Hadoop disponibili in HDInsight, vedere Componenti e versioni disponibili con HDInsight. Per altre informazioni su Hadoop in HDInsight, vedere la pagina delle funzionalità di Azure per HDInsight.
Informazioni su MapReduce
Apache Hadoop MapReduce è un framework software per la scrittura di processi in grado di elaborare grandi quantità di dati. I dati di input sono suddivisi in blocchi indipendenti. Ogni blocco viene elaborato in parallelo attraverso i nodi del cluster. Un processo MapReduce è costituito da due funzioni:
Mapper: usa i dati di input, li analizza (in genere mediante operazioni di filtro e ordinamento) e quindi genera tuple (coppie chiave-valore)
Reducer: usa le tuple generate dal Mapper ed esegue un'operazione di riepilogo che crea un risultato combinato più piccolo a partire dai dati del Mapper
La figura seguente illustra un esempio di processo di base di conteggio parole in MapReduce.
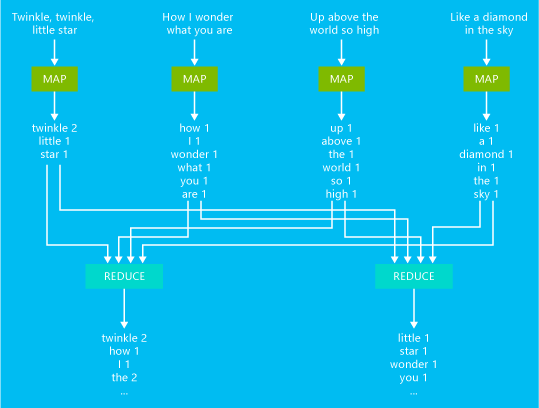
L'output del processo consentirà di conoscere il numero totale di occorrenze di ogni parola presente nel testo.
- Il mapper accetta come input ciascuna riga del testo di input e la suddivide in parole. Emette quindi una coppia chiave-valore ogni volta che viene riscontrata un'occorrenza della parola seguita da 1. L'output viene ordinato e inviato al reducer.
- Il reducer somma i singoli conteggi relativi a ciascuna parola ed emette una sola coppia chiave-valore contenente la parola seguita dal numero di occorrenze.
MapReduce può essere implementato in vari tipi di linguaggio. A scopo dimostrativo, in questo esempio si userà l'implementazione più comune: Java.
Linguaggi di sviluppo
I linguaggi o i framework basati su Java e Java Virtual Machine possono essere eseguiti direttamente come processo MapReduce. Nell'esempio in questo documento viene usata un'applicazione Java MapReduce. I linguaggi diversi da Java, ad esempio C# o Python, o file eseguibili autonomi devono usare lo streaming di Hadoop.
Lo streaming di Hadoop comunica con il mapper e il riduttore tramite STDIN e STDOUT. Il mapper e il riduttore leggono i dati di una riga alla volta da STDIN e scrivono l'output in STDOUT. Ogni riga letta o generata dal mapper e dal riduttore deve essere in formato coppia chiave/valore, separata da un carattere di tabulazione:
[key]\t[value]
Per altre informazioni, vedere l'argomento relativo a Hadoop Streaming.
Per alcuni esempi sull'uso dello streaming di Hadoop con HDInsight, vedere il documento seguente:
Da dove iniziare
- Avvio rapido: Creare cluster Apache Hadoop in Azure HDInsight usando il portale di Azure
- Esercitazione: Inviare processi Apache Hadoop in HDInsight
- Sviluppare programmi Java MapReduce per Apache Hadoop in HDInsight
- Usare Apache Hive come strumento per estrazione, trasformazione e caricamento (ETL, Extract, Transform, and Load)
- Estrarre, trasformare e caricare (ETL) su larga scala
- Rendere operativa una pipeline di analisi dei dati